はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。pandasista という名前でXをやっております。普段はデータをねりねりしたりCEOをしたりしています。

本記事は4年前に勉強会で用いた記事になります!
ぜひいいねを押してってください🙌
導入
本記事の構成は4部となっており
- Titanicデータセットと探索的データ分析(EDA)
- 探索的データ分析(EDA)の続きと特徴量エンジニアリング
- 特徴量エンジニアリングの続きとAIモデルへの適用
- djangoを用いた簡単なTitanic乗客生死予測アプリケーションの作成
という内容でお届けしています。
本記事は2章目!探索的データ分析と特徴量エンジニアリングを紹介します!
以下の記事を読んだ後に本Titanicシリーズを読むと段階的に理解ができます。
EDA(7) ~SibSp~
SibSpの意味はカラム名から推測できないです。Siblings+Spouces(兄弟+配偶者)という意味です。分かりにくいので、例を示して見ます。アンドリューさんには弟が二人、妻が一人いました。弟の一人は妻がいました。このときのSibSpの値は「弟+妻+弟の妻」なので2+1+1=4になります。これが重要な特徴量になるのか見ていきましょう。
died_sibsp = train_data[train_data['Survived']==0]['SibSp']
survived_sibsp = train_data[train_data['Survived']==1]['SibSp']
plt.hist(survived_sibsp, alpha=0.5, label='survived', bins=8)
plt.hist(died_sibsp, alpha=0.5, label='died', bins=16)
plt.xlabel('SibSp')
plt.ylabel('num_passenger')
plt.legend(title='state')
OUTPUt
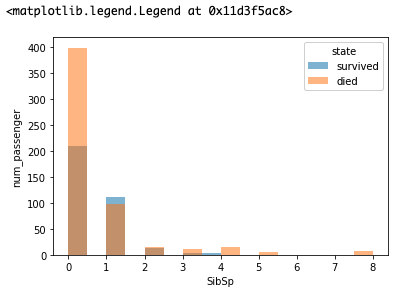
これを見るとSibSpが1であるものに限り生存者数の方が多いです。このように2値分類問題の時は、その値別にデータを分けてグラフを重ねて見る方法はEDAとしてよく用いられる手法です。
これは欠損がなく、カテゴリ変数ではないことから特別な処理は必要ありません。ということで削除しないでそのままで置いておきましょう。
EDA(8) ~Parch~
このカラムの意味は「乗船した親子の人数(Parents/Children)」です。このデータが実際に重要なのかを可視化によって見ていきましょう。先ほどと同じ可視化方法を用います。
plt.hist(train_data[train_data['Survived']==0]['Parch'], alpha=0.5, label='Died')
plt.hist(train_data[train_data['Survived']==1]['Parch'], alpha=0.5, label='Survived')
plt.xlabel('Parch')
plt.ylabel('num')
plt.title('ParchEDA')
plt.legend(title='state')
OUTPUT
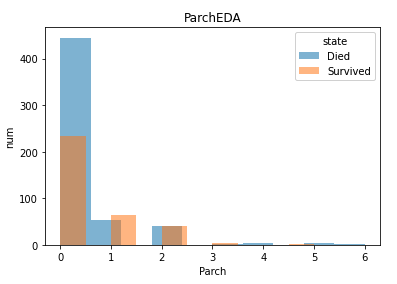
この特徴量も1の時だけ生存者の人数が亡くなった人数を上回っています。これらのEDAから自分以外の身内は1人いた方が生き残りやすいと言えます。一応この特徴量も欠損なしで数字カラムと言うことで何も処理せずに置いておきましょう。
EDA(9) ~Ticket~
train_data['Ticket']
0 A/5 21171
1 PC 17599
2 STON/O2. 3101282
3 113803
4 373450
...
886 211536
887 112053
888 W./C. 6607
889 111369
890 370376
Name: Ticket, Length: 891, dtype: object
チケット名、乗客の生死に関係なさそうですよね。チケット番号が乗客のクラスを表していたとしてもPclassがあれば十分です。削除、と言う方針でいきましょう。
EDA(10) ~Fare~
Fare(料金)ですね。乗客の生死に関係あるのでしょうか。EDAしていきましょう。
die_train_data = train_data[train_data['Survived']==0]
survived_train_data = train_data[train_data['Survived']==1]
plt.boxplot([die_train_data['Fare'], survived_train_data['Fare']], labels=['die', 'survived'])
OUTPUT
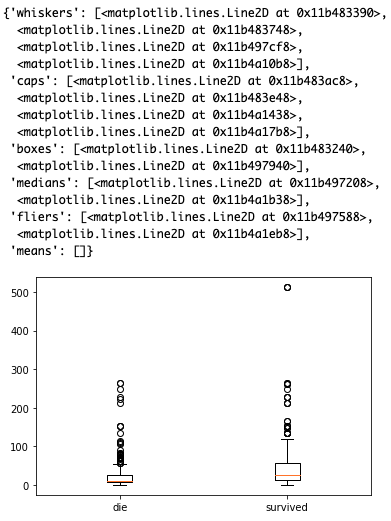
これを見ると、生き残っている人の方が幅が広いです。特に300以上のFareなら必ず生き残ると断言できる特徴量なので、かなり重要な特徴量です。そのまま特徴量として加えておきましょう。
EDA(11) ~Cabin~
乗客が止まった船室番号です。欠損を改めて確認していきましょう。
train_data['Cabin'].count()/len(train_data)
0.22895622895622897
非欠損率が約23%と非常に多くの欠損があります。欠損率はここまでくると無理に穴埋めしない方がよく、今回はカラムを丸々削除と言う方針でいきましょう。
EDA(12) ~Embarked~
乗船した港です。タイタニック号は出発した港意外にも他二港に寄港しています。どんな分け方をしているか見ていきましょう。
train_data['Embarked'].value_counts()
S 644
C 168
Q 77
Name: Embarked, dtype: int64
S:サウサンプトン、C:シェルブール、Q:クイーンズタウン、となっています。サウサンプトンから乗船した人が一番多いみたいです。さて、ここで乗船した港って、乗客の生死に関係あるでしょうか。EDAで少し見ていきます。
S_train_data = train_data[train_data['Embarked']=='S']
C_train_data = train_data[train_data['Embarked']=='C']
Q_train_data = train_data[train_data['Embarked']=='Q']
ratio_S = S_train_data['Survived'].sum()/len(S_train_data)
ratio_C = C_train_data['Survived'].sum()/len(C_train_data)
ratio_Q = Q_train_data['Survived'].sum()/len(Q_train_data)
x_name = ['S', 'C', 'Q']
plt.bar(x_name, [ratio_S, ratio_C, ratio_Q])
OUTPUT
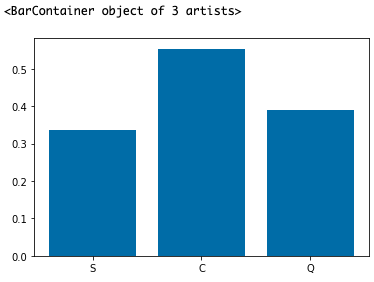
これを見ると、クイーンズタウンから乗船している乗客は他の二港から乗船している乗客に比べて生存率が高いことがわかりました。これは特徴量として組み込みたいところです。ただ
train_data['Embarked'].count()/len(train_data)
0.9977553310886644
少しだけ欠損があります。またカテゴリ特徴量なのでワンホットエンコーディングも必要です。欠損値埋めは欠損率が極端に低いので放置してワンホットエンコーディングしていきましょう。
encoded_Embarked = pd.get_dummies(train_data['Embarked'])
encoded_Embarked = encoded_Embarked.add_prefix('Embarked')
encoded_Embarked
OUTPUT
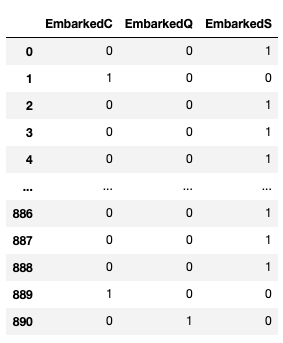
うまくエンコーディングできたみたいです。
処理関数の実装
ここまでで全カラムのEDAを一通りやってきました。テーブルをどう処理するかをまとめると、
・PClass…ワンホットエンコーディング
・Name…削除
・Sex…数字化(0or1)
・Age…中央値で欠損値埋め
・SibSp…そのまま
・Parch…そのまま
・Ticket…削除
・Fare…そのまま
・Cabin…削除
・Embarked…ワンホットエンコーディング
です。これらの処理を関数化していきましょう。基本的に前処理はすべて関数化します。
def pretreatment(_df):
_df = _df.drop(['Name', 'Ticket', 'Cabin'], axis=1) # 不要カラムの削除
_df['Age'] = _df['Age'].fillna(_df['Age'].median()) # Ageカラムの欠損値埋め
_df.loc[_df['Sex']=='male', 'Sex']=0 # Sexがmaleであるものを0に変換
_df.loc[_df['Sex']=='female', 'Sex']=1 # Sexがfemaleであるものを1に変換
_df = pd.get_dummies(_df, columns=['Pclass', 'Embarked']) #ワンホットエンコーディング
return _df
pretreatment(train_data)
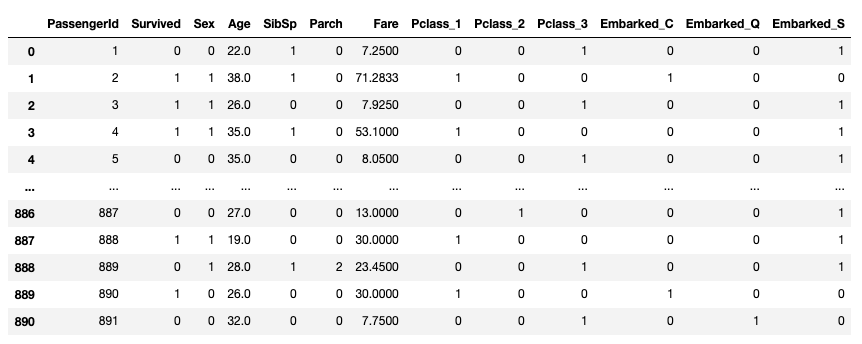
しっかり処理できていますね。
続き
以下の記事をご覧ください!
【入門】Titanic号乗客の生死を予想しよう!(3)
紹介
株式会社 Panta Rheiでは「Everything Analysable」を標榜とし、世の中にあるあらゆる定性的な対象をAIによって定量化する事業をおこなっております。
AIに召し上がっていただく綺麗なデータを作る、データフローを整形するなどの課題や、そもそものAIの内製化等、挑戦したい試みがあればぜひご一報ください!