はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。pandasista という名前でXをやっております。普段はデータをねりねりしたりCEOをしたりしています。

本記事は4年前に勉強会で用いた記事になります!
ぜひいいねを押してってください🙌
導入
本記事の構成は4部となっており
- Titanicデータセットと探索的データ分析(EDA)
- 探索的データ分析(EDA)の続きと特徴量エンジニアリング
- 特徴量エンジニアリングの続きとAIモデルへの適用
- djangoを用いた簡単なTitanic乗客生死予測アプリケーションの作成
という内容でお届けしています。
以下の記事を読んだ後に本Titanicシリーズを読むと段階的に理解ができます。
最初に
ボストン住宅価格データセットなど、綺麗に整形されているデータセットは欠損がなかったり、全て数字だったりと、かなり練習向けなデータセットです。今記事では、欠損あり、文字列特徴量ありのデータセットを扱って、より実際的なAI実装をしていきたいと思います。
今回扱うデータセットは「タイタニックデータセット」という有名データセットで、乗客の性質(性別や階級、乗船した港など)から、その乗客が生き残ったかを予測するタスクになっています。sklearn.datasetsに所属しているデータに比べて前処理が大変なものになっているので、本講座を終えたあとは基本的にどんなデータセットに対しても対応ができるようになっていると思います!頑張って実装していきましょう!
また、最後に予測結果をKaggleに提出します!Kaggleの雰囲気を味わっていただければと思います。
データダウンロード
早速Kaggleにアクセスしてデータセットを回収してきましょう。
タイタニックデータセットはリンクを踏んだ後に、data→Download Outputをクリックするとタイタニックデータセットが入ったCSVファイルが取得できると思います。(zipは解凍してください)
titanicフォルダに「gender_submission.csv」「test.csv」「train.csv」が入っていればダウンロード成功です。では実際にどんなデータなのかをそれぞれ見ていきましょう。
gender_submission.csvを見てみる
エクセルでもなんでもいいので、まず最初にgender_submission.csvを見てみましょう。jupyter notebookで実装すると以下のようになります。
(一旦titanicフォルダをipynbのあるディレクトリに移しておきましょう)
import pandas as pd
submission = pd.read_csv('titanic/gender_submission.csv')
submission
OUTPUT
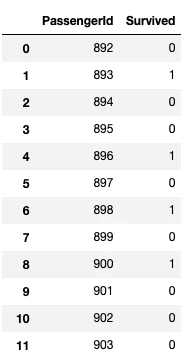
カラムが「PassengerId」「Survived」であるテーブルが得られました。実はこれ、「Kaggleに提出するときはこんなフォーマットで提出してね」というサンプルのデータフレームで、このままKaggleに提出することができます。
PassengerId(乗客を識別するID番号)とその生死(Survived)の予測結果を並べて縦書きにして2列のcsvファイルにして提出してねと言った感じです。
早速このサンプルを提出してみましょう。
このページから、submit predictionsを押すと、提出画面になるので、そこにgender_submission.csvをアップロードして、submitを押します。
点数計算(Scoring)画面が出てきて、正解率を計算しています。しばらくすると、提出したファイルの特典が表示されると思います。
こんな感じの画面が表示されたら成功です。Scoreは0.76555となりました。これにてあなたも今日からKagglerです!!
EDA(1) ~train_dataとtest_dataの比較~
まずは、データをpandasで読み込んでみてtest_dataとtrain_dataを見てみましょう。
train_data = pd.read_csv('titanic/train.csv')
test_data = pd.read_csv('titanic/test.csv')
print(train_data.columns)
print(test_data.columns)
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
Index(['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
4行目は「train_dataの列一覧を表示したよ」
5行目は「test_dataの列一覧を表示したよ」
これらを見てみると、train_dataの方にある「Survived」がtest_dataにはありません。今回は、test_dataの「Survived」を予測すると言ったタスクになります。次にtrain_dataを見てみて、どのようにテーブルを整形していくかの方針を立てましょう。
EDA(2) ~train_dataの概観~
train_dataを見ていきましょう。
train_data.head()
OUTPUT

テーブルに「.head()」で最初の5行を取得してきてくれます。データサイズが大きいと全部の表示には時間がかかる場合があるので、最初にテーブルを見るときは.head()をつけた方が良いです。
数字データもあれば、文字列のデータもありますね。こんな感じでデータを見ていきます。
まずPassengerIdが1の人を見てみましょう。Surveviedが0で亡くなってしまったようです。Pclassが3となっています。これは「三等客室」の乗客ということですが、そもそも何等客室まであるんでしょうか。
train_data.describe()
OUTPUT
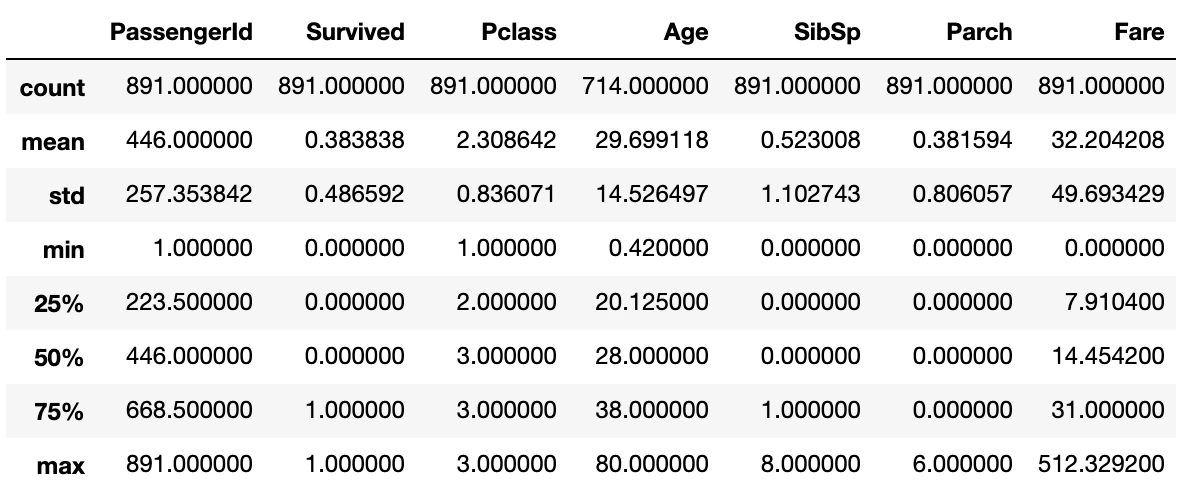
データフレームに.describe()をつけると、そのデータフレームの数字の列だけの記述統計量を取得してきます。これを見ると、Pclassのmaxが3、minが1になっていて、一等客室から三等客室まであるということが分かります。また、PassengerIdのcountが891で他のカラムのcountもだいたい891になっています。ただAgeを見るとcountが714しかなく、177個の欠損があることが分かりました(データの欠損具合を見るのはEDAにおいて非常に重要な分析です)。
「.describe()」は自動的に文字列カラムを排除してくれ、数字カラムのみの記述統計量を出力してくれるので、最初にデータを見たいときに使うことが多いです。
これを見ると、平均年齢が(train_dataの中だと)だいたい29~30歳なんだなーとかデータセットに対するイメージが湧いてきます。
これで客室のクラス情報が分かったところで次のNameカラムのデータを見ていきます。まず欠損具合を見ていきましょう。
train_data.count()/len(train_data)
PassengerId 1.000000
Survived 1.000000
Pclass 1.000000
Name 1.000000
Sex 1.000000
Age 0.801347
SibSp 1.000000
Parch 1.000000
Ticket 1.000000
Fare 1.000000
Cabin 0.228956
Embarked 0.997755
dtype: float64
ここでは「train_data.count()で各カラムのデータの量(欠損していないデータの量)を数えて、テーブルの行数len(train_data)で割っているよ」と言った操作をしています。これは非欠損割合を示していて、1であれば欠損がないことになります。Nameの部分を見てみると、しっかりと1になっていて欠損がないことが分かりました。次に見るSexについても欠損がないことが分かります。ただし先ほど判明した通りAgeは少し欠損が見られます。他の欠損カラムはCabinとEmbarkedです。
次にそれぞれのカラムに対する処理を考えていきましょう。
EDA(3) ~Pclass~
欠損もなく全て 1~3の整数で表されている綺麗なカラムですが、この特徴量は乗客の生死にどれくらい重要なんでしょうか。ここで参考になるのは「データ外の情報」です。映画タイタニックを見た方なら「一等客室の乗客が優先的に救命ボートに乗っていた」と思い出して、乗客の生死にPclassが重要になってくることがイメージできると思います。これはデータセットから調べて得た情報ではなく、前もって知っていたことです。
補足になりますが、このようにAIの実装の時にデータ外の知識が重要になることは非常に多くあります。自分の専門の知識、すなわち「ドメイン知識」を参考にしてAI実装を行えば、その領域でない人が実装するより圧倒的なアドバンテージになります。例えば、筆者はケーキを作ることができませんが、ケーキ屋さんはケーキの専門家です。ケーキの売り上げ予測のAIを実装する時に、筆者が実装するよりも、どんなケーキが売れるのかを肌感覚で分かっているケーキ屋さんの人が、多少AIを実装する方がスキルがなくても精度の高い有用なAIを作ることができます。
実際に三等客室の人よりも一等客室の人の方が生き残りやすかったのかをmatplotlibで検証していきます。
from matplotlib import pyplot as plt
first_class_passenger_data = train_data[train_data['Pclass']==1]
second_class_passenger_data = train_data[train_data['Pclass']==2]
third_class_passenger_data = train_data[train_data['Pclass']==3]
num_survived_1 = first_class_passenger_data['Survived'].sum()
num_survived_2 = second_class_passenger_data['Survived'].sum()
num_survived_3 = third_class_passenger_data['Survived'].sum()
x_name = ['first', 'second', 'third']
plt.bar(x_name,[num_survived_1, num_survived_2, num_survived_3])
plt.ylabel('num_survived')
OUTPUT
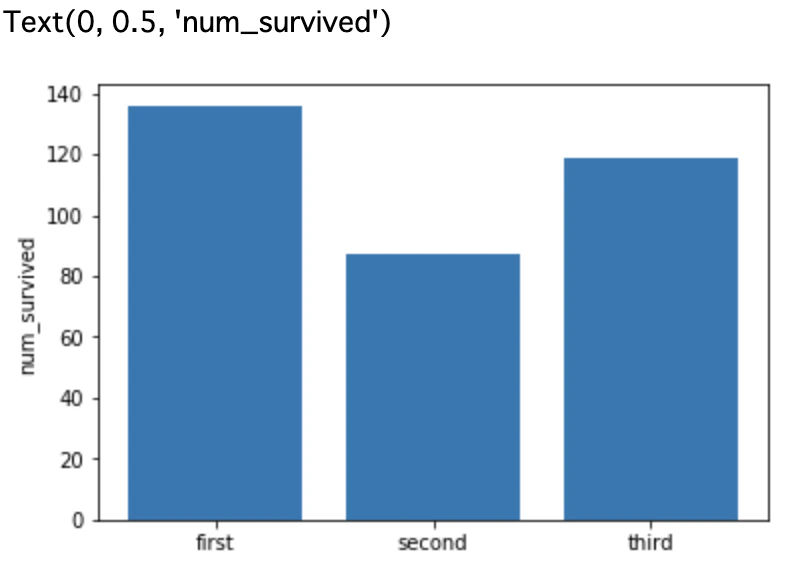
想定と異なり三等客室の乗客も一等客室の乗客と同じくらい生き残っていました。
コードの解説です。
1行目は「matplotlibのpyplot機能をpltという名前で使えるようにしたよ」
3~5行目は「Pcalssがそれぞれ1, 2, 3である人だけのテーブルを作ったよ。」
7~9行目は「PclassごとのテーブルからSurvivedカラムを抜き出し各Pclassごとの合計値を計算したよ」
11~13行目は「棒グラフを描いたよ」
まずpandasのデータフレームにおいて、「テーブル名[条件]」という書き方をすれば、そのテーブルから条件に合致した行だけを抜き出すことができます。今回は条件文が「train_data['Pclass']==1」、すなわち「train_dataのPclassが1である」ということで、これを満たす行をtrani_dataから抜き出してfirst_class_passenger_dataに代入しています。他の~_class_passenger_dataも同様です。
さて、この想定と異なったという考えは本当に正しいのでしょうか。実はEDAをする時は、実数の比較よりも、割合の比較を行うことがほとんどです。すなわち「一等客室の乗客が何人生き残ったか」ではなく「一等客室の乗客は何%生き残ったか」を比較します。以下にコードを書いていきます。
num_survived_1_ratio = num_survived_1/len(first_class_passenger_data['Survived'])
num_survived_2_ratio = num_survived_2/len(second_class_passenger_data['Survived'])
num_survived_3_ratio = num_survived_3/len(third_class_passenger_data['Survived'])
plt.bar(x_name, [num_survived_1_ratio, num_survived_2_ratio, num_survived_3_ratio])
plt.ylabel('ratio_num_survived')
OUTPUT
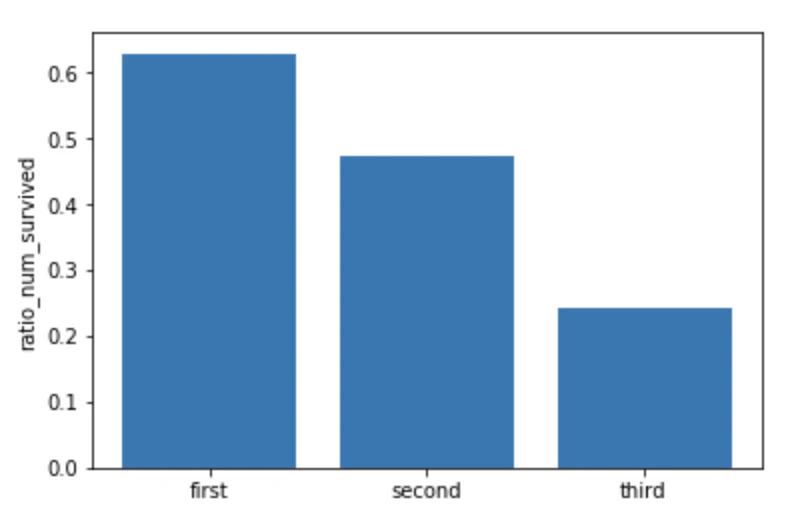
1~3行目は「各Classの生き残った人数を、各Classのテーブルの行数(各Classの人数)で割ったよ」
5~6行目は「棒グラフを書いたよ」
このグラフは客室の等級ごとに生存率が変わることをしっかりと示していますね。一等客室の乗客は60%以上生き残っているのに対し、三等客室の乗客は20%強しか生き残っていません。このカラムは重要な特徴量になるだろうということが分かりました。
Pclassの前処理
このように、離散的な値をとる特徴量のことを「カテゴリ特徴量」と言い、連続的な値をとる特徴量(例:時間や価格等)と区別されます。本データセットでは「Embarked」や「Sex」などもカテゴリ特徴量に分類されます。ここで考えたいのは、カテゴリ特徴量の数字に意味があるか、ということです。どういうことかというと、「一等客室の人の3倍は三等客室の人」と言えるのでしょうか、ということです。数字の序列に意味があるとしたら「一等客室の人は100、二等客室の人は1000、三等客室の人は5000」でもいいことになります。実は、この1, 2, 3という数字には意味がありません。ただ単にそれぞれの等級を識別できればよく、「一等客室はF、二等客室はS、三等客室はT」としてもいいわけです、数字自体に意味はありません。
しかしアルゴリズムにかけるとなるとそうはいきません。意味のない数字にも関係性を見出して「一等客室は三等客室の1/3」という意味不明な学習をしてしまいます。これは実生活でも問題で、例えば職業を例にとると「自営業:1, 会社員:2, 公務員:3, 学生:4, 無職:5」と数字が割り振られていた時に、学生の方が公務員よりも大きい」「自営業の5倍は無職」といった謎の関係性が成立してしまいます。やはり、識別子に数字を使っているだけで、数字自体に意味はありません。このようにカテゴリ特徴量の各属性に数字を割り振ることをラベルエンコーディング(もしくはオーディナルエンコーディング)と言います。実はラベルエンコーディングでも決定木系のアルゴリズムだとしっかり分岐でカテゴリをふるい分けてくれるので、このラベルエンコーディングでも大丈夫です。サポートベクターマシンやDeepLearningなどのアルゴリズムはカテゴリ特徴量についてはしっかりと前処理をしなければいけません。ただし、性別や生死など2値しか取り得ないカテゴリ特徴量ならばこの数字によるラベリングも問題ないです。
では前処理をしていきましょう。今回は「ワンホットエンコーディング」を実装します。
encoded_Pclass = pd.get_dummies(train_data['Pclass'])
encoded_Pclass = encoded_Pclass.add_prefix('Pclass')
OUTPUT

これは各属性の名前を冠したカラムを作成し、その属性に当てはまるなら1、当てはまらないなら0を当てています。例えばIndex0の人はPclassが3なので、Pclass1とPclass2は0でPclass3のところだけになっています。このように「一等客室かどうか」のカラムに「Yes:1/NO:0」とすることにより、属性間に大小関係が生まれることを防いでいます。このような処理をワンホットエンコーディングといい、よく用いられています。以下のようにコードを書き換えると、テーブル全体が得られます。
Pclass_encoded_train_data = pd.get_dummies(train_data, columns=['Pclass'])
Pclass_encoded_train_data
OUTPUT
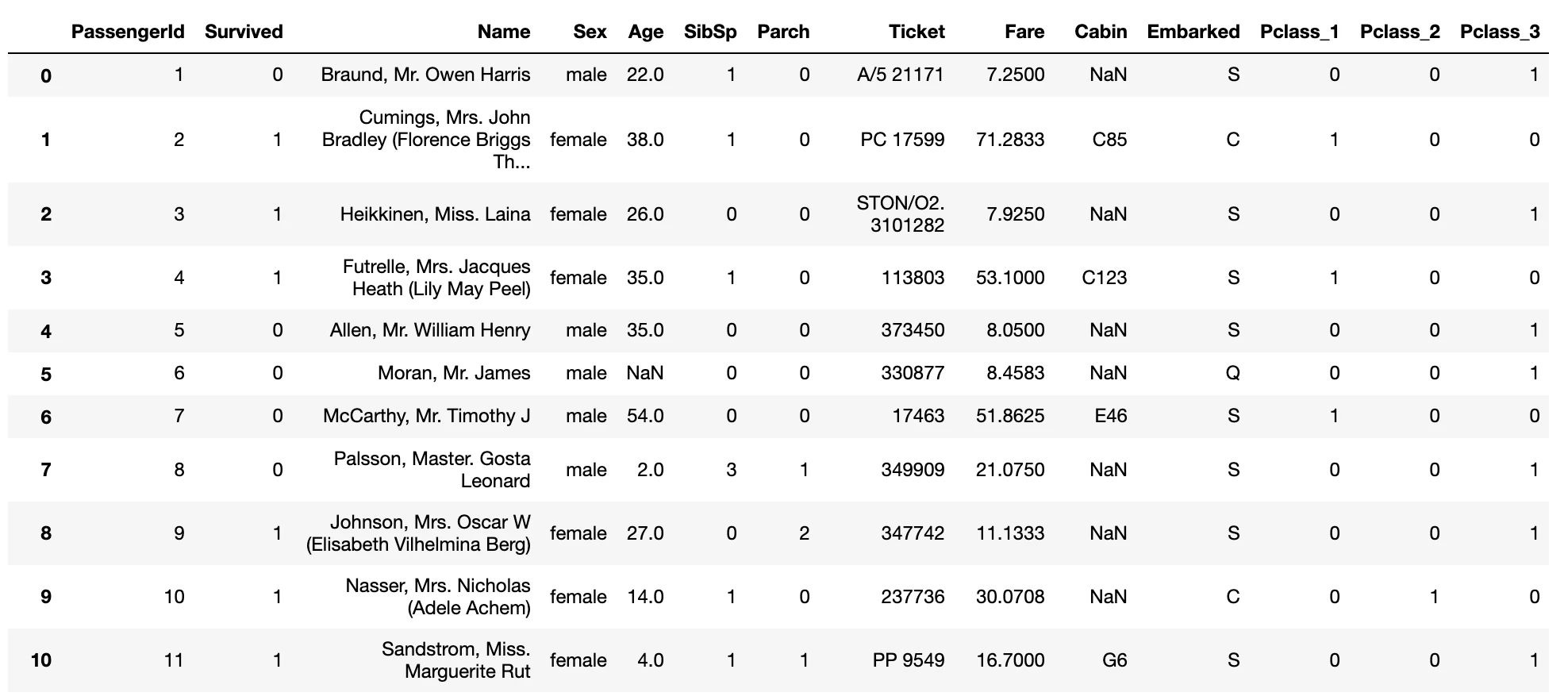
全体のテーブルを取得でき、Pclassだけワンホットエンコーディングされています。Pclassに対する処理は「ワンホットエンコーディング」ということにしましょう。
EDA(4) ~Name~
EDAをする前に、乗客の名前って生死に関係あるでしょうか…?と考えてみます。名前がローズだと生き残ってジャックだと生き残れない…といったことがあるのでしょうか。おそらくはないでしょう。これはノイズ特徴量になります。Nameに対する処理は「削除」にしましょう。
補足…実はこれはコンペにおいては重要な特徴量になるかもしれません。train_dataで生き残っていた人の兄弟がtest_dataに入っていた場合、兄弟ならば一緒に救命ボートに乗って二人とも生き残っている可能性が高いので、test_dataの人物の推測に使えます。「train_dataで生き残っていた人と同じ苗字の人」は生き残り識別に重要な情報と考えられ、これに関する特徴量を追加すれば、AIの精度に影響を及ぼすかもしれません。このようにデータセットに存在しない特徴量をデータセットの情報を用いて新しく作ることを特徴量生成と言います。今回は文字列の扱いが複雑なこと、実はNameカラムが無くても精度にそれほど影響しないことから、削除という処理にしています。
EDA(5) ~Sex~
性別カラムです。EDAしていきましょう。性別ごとの生き残り率を可視化します。
male_train_data = train_data[train_data['Sex']=='male']
female_train_data = train_data[train_data['Sex']=='female']
num_survived_male_ratio = male_train_data['Survived'].sum()/len(male_train_data)
num_survived_female_ratio = female_train_data['Survived'].sum()/len(female_train_data)
x_name = ['male', 'female']
plt.bar(x_name, [num_survived_male_ratio, num_survived_female_ratio])
plt.ylabel('ratio_num_survived')
OUTPUT

非常に明快な結果が出ました。男性の方が約20%ほどしか生き残れず、女性は70%超生き残っています。これは映画タイタニックを見たことのある方なら比較的イメージのつきやすいことで「女性子供を優先的に救命ボートに乗せていた」といった映画中の描写と一致しています。出力した結果が自分の知識と合っていると確認できることも、データ外の情報の良いところです。
Sexの前処理
これは男性を0、女性を1と数字に置き換えて処理しましょう。2値しか取らないのでワンホットエンコーディングの必要はないです。
train_data.loc[train_data['Sex']=='male', 'Sex']=0
train_data.loc[train_data['Sex']=='female', 'Sex']=1
train_data
OUTPUT
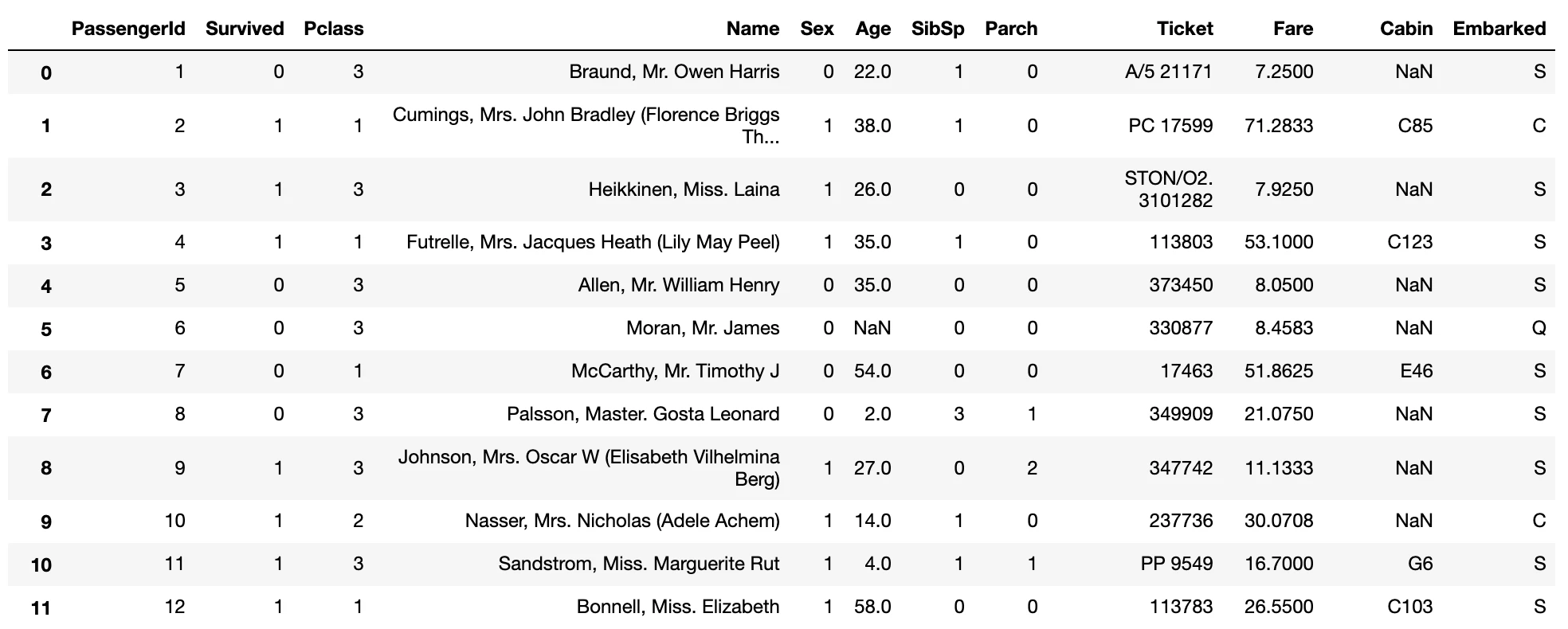
しっかりと性別が数字化されています。
EDA(6) ~Age~
ここで初めて欠損データを含むカラムを扱います。まずAgeのヒストグラムを見てみましょう。
plt.hist(train_data['Age'], bins=10)
plt.xlabel('Age')
OUTPUT
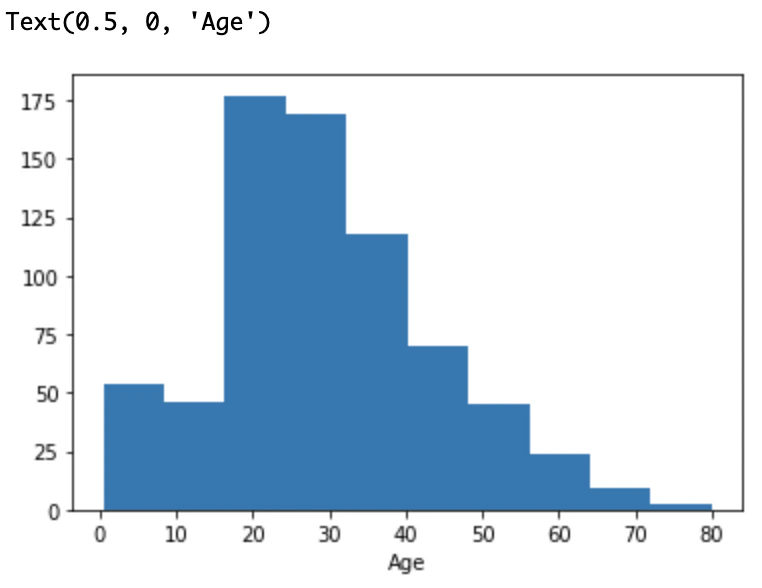
データを見る感じ、20歳30歳付近がたくさんいるようです。
ちなみに、以下のような書き方をすると、グリッドせんが表示されて視認性が上がります。
train_data['Age'].hist(bins=10)
OUTPUT
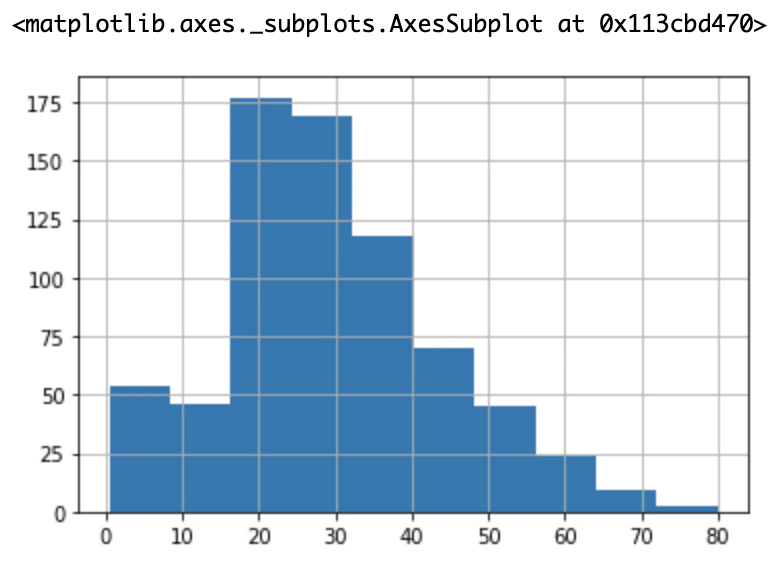
実は、「pd.Series.可視化メソッド()」でもmatplotlibの代用ができます。本家を使った方が細かい設定が可能ですが、手軽にグラフをみたい時は代用法が便利でおすすめです。ただこの代用法は内部的にmatplotlibが動いているので、どちらの方法を用いるにしてもfrom matplotlib import pyplotは必要です。
さて、では生死別に年齢のヒストグラムを見てみましょう。
train_data_0_age = train_data[train_data['Survived']==0]['Age']
train_data_1_age = train_data[train_data['Survived']==1]['Age']
plt.subplot(1, 2, 1)
plt.hist(train_data_0_age)
plt.title('died')
plt.xlabel('Age')
plt.subplot(1, 2, 2)
plt.hist(train_data_1_age)
plt.title('survived')
plt.xlabel('Age')
OUTPUT

1行目は「train_dataから亡くなった乗客だけのテーブルを作って、そのAgeの列だけ取得したよ」
2行目は「train_dataから生き残った乗客だけのテーブルを作って、そのAgeの列だけ取得したよ」
ここでのplt.subplotはグラフを複数表示するメソッドで、スライドなどに貼る時に便利です。
subplot(何行か, 何列か, 左上から数えて何番目か)という書き方をします。
亡くなった人の分布に比べて生き残った人の分布は、若い層の割合が大きく、これも重要な特徴量になりそうと考えられます。
今度はグラフを重ねてみます。
plt.hist(train_data_0_age, alpha=0.5, label='died')
plt.hist(train_data_1_age, alpha=0.5, label='survived')
plt.legend()
OUTPUT
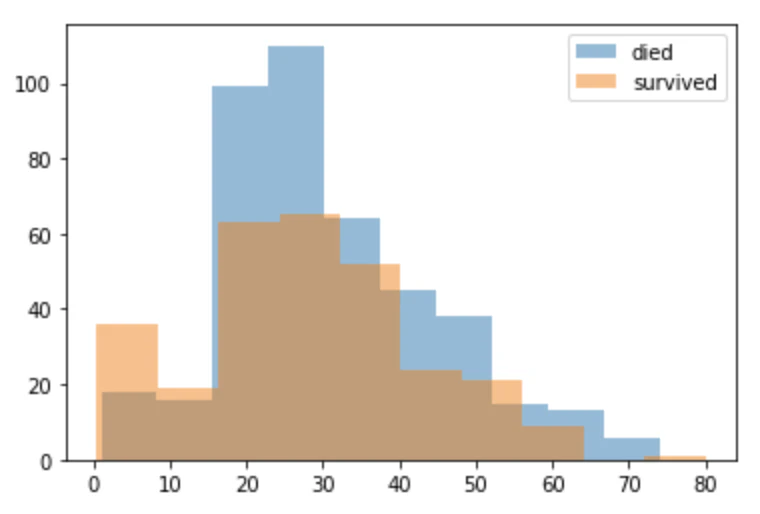
ここでのplt.legend()は凡例を表示するメソッドで、基本は右上に固定されています(細かく設定できます)。
これを見ても、全体的に生き残った人の方が少ないにもかかわらず、20歳以下だけで見れば生き残った人の方が多いです。年齢は重要な情報ということが分かりました。
Ageの前処理
Ageはカテゴリ変数ではなく連続値を取るとみなせるので、ここではエンコーディングの必要はありません。ただし、欠損値があるのでこれにはどうにか対処しなければいけません。ここで欠損に対する対処を3つ紹介します。
-
欠損している行を削除する「dropna()」
メリット…処理が楽
デメリット…レコード数が少なくなるので精度が落ちる危険性がある -
欠損を含むカラムを削除する(この場合は丸々Ageのカラムをデータから削除する)「drop(axis=1)」
メリット…処理が楽
デメリット…重要なカラムだった場合、精度が非常に落ちてしまう -
欠損値を穴埋めする「fillna()」
メリット…データ数が減らない
デメリット…上手く補完しないとノイズになる可能性がある
実務においては欠損値の補完はあまりやりません(データの改竄とも考えられるため)。ただコンペでは非常によく使います。Ageカラムは重要であるということがEDAによって分かっているので、削除する方法ではなく3)の方法で欠損値処理していきましょう。
train_data['Age'].fillna(train_data['Age'].median()).head(10)
OUTPUT
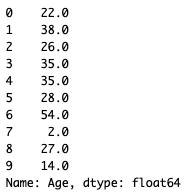
1行目は「欠損値を中央値で穴埋めしたよ」
indexが5である行を見てみましょう。元々のtrain_dataのindex5のAge部分を見てみるとNaNになっていますが、この処理後は28.0が代入されています。この28.0はAgeの中央値です。基本的に穴埋めは中央値で行うことが多いですが、データの分布を見て平均値や最頻値で埋める場合もあります。
また、こだわる人だと他のカラムと関係させたりして、行ごとに欠損値の補完の値を変えることもあります。例えば、後で見るFare(料金)カラムを参考にして、子供なら安くて大人なら高そうと仮定して、料金が安い人には欠損の補完する値を小さくして、料金が高い人は大人だろうと予見して高めのAgeで補完したりします。
続き
以下の記事をご覧ください!
【入門】Titanic号乗客の生死を予想しよう!(3)
紹介
株式会社 Panta Rheiでは「Everything Analysable」を標榜とし、世の中にあるあらゆる定性的な対象をAIによって定量化する事業をおこなっております。
AIに召し上がっていただく綺麗なデータを作る、データフローを整形するなどの課題や、そもそものAIの内製化等、挑戦したい試みがあればぜひご一報ください!