はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。pandasista という名前でXをやっております。以後お見知り置きを!
本記事は4年前に勉強会で用いた記事になります!
導入
本記事は、【実装】ボストンの住宅価格推測AIを作ろう【前編】の続きとなっております。先にそちらをお読みください!
最初に
ここではAIの専門的な知識がしばしば出てきます。平易で分かりやすいように努めたつもりですが分かりにくいところがあったらご容赦ください。専門用語も出てきますが、太字のところ以外は無理に覚えようとしなくても大丈夫です!途中までは文字が多くて退屈かもしれませんので話半分で見てみてください。
AIのアルゴリズムの種類
AIのアルゴリズムは多種多様なものがあり、そのそれぞれが一長一短という感じです。本項では数ある代表的なものを10個ほどピックアップして紹介します!(太字は中でも重要なアルゴリズム)
-
k最近傍法
- もっともシンプルなアルゴリズム。解釈性(※)が高く、アルゴリズム自体の理解も比較的簡単。ただし、シンプルなだけあってあまり精度が出るアルゴリズムではない。
-
重回帰系
- ラッソ回帰…関係ない特徴量を自動で排除してくれ、残った特徴量だけで考えられるので解釈性が高い。精度は高くなりにくい。
- リッジ回帰…得られた推定値が滑らかな曲線を描くため、数学的な考察がしやすい。関係ない特徴量も(削除していなければ)自動で推測に組み込んでしまうため、モデルが複雑になりやすい。
- ElastcNet…ラッソ回帰とリッジ回帰を合わせたもの、よく言えば良いとこ取り、悪く言えば中途半端。
- サポートベクターマシン…データの大きさが小さくても高い精度が出せる優秀なアルゴリズム。一昔前のAIアルゴリズムの主力だったが、学習に非常に時間がかかるのが難点。
-
決定木系
- 決定木…初心者にも分かりやすいアルゴリズム。精度も低くないが学習に時間がかかりがちで、再現性も低い。(同じデータで学習しても、モデルが異なることがある。
- ランダムフォレスト…決定木をたくさん作って掛け合わせたもの。精度は良いが学習の時間が鬼のようにかかる。
- 勾配ブースティング…決定木を作る、それを参考にまた新しい決定木を作る、それをまた参考に決定木を…、を繰り返すアルゴリズム。精度の良さでは決定木系でもピカイチだが時間が鬼のようにかかっていた。ただ2016年にMicroSoft社が「LightGBM」という革新的な勾配ブースティング用パッケージをリリースしてからはこの問題が解決され、現在はAIモデルとしてのファーストチョイスとなっている。
-
ニューラルネットワーク系
- 単層パーセプトロン…人間の脳に着想を得たアルゴリズム。現在ではこのアルゴリズム単体で用いられることはないが、後述のDeepLearningの基礎として大きな役割を果たした。
- DeepLearning…単層パーセプトロンを何重にも重ねた感じのアルゴリズム。恐ろしいほど学習に時間がかかっていて2000年代ごろまでは敬遠されていたが、近年のPCの計算能力の向上に伴い、一気にAIの代名詞になるまでに台頭した。精度は前述のアルゴリズムの中でもピカイチで、画像認識、言語処理など幅広く応用も効くスーパーアルゴリズム。ただ解釈性は皆無に等しく、ビジネスの現場ではあまり用いられない。
※ここでいう「解釈性」とは、AIが出力した結果に対する解釈の加えやすさ。ビジネスの現場ではかなり重視される。
決定木の概観
現在のAIの主力アルゴリズムである決定木系について掘り下げてみようと思います。と言っても決定木は理解しやすいアルゴリズムなので、あまりにも掘り下げなければ数学的なバックグラウンドを必要としません。
木構造
「アキネーター」をご存知でしょうか!ユーザーの想像している人物を数々の質問からAIが当てるアプリケーションです。あれは木構造の良い例なので実際にやってみましょう!
このようにたくさん質問をしていって分岐していくような構造を「木構造」と言います。
今回のボストン住宅価格のデータセットに木構造を適応するとこんな感じになります!
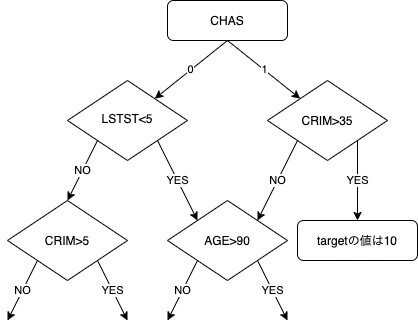
このように、様々な分岐を繰り返して値を推測するアルゴリズムが決定木系のアルゴリズムとなります。
この分岐の基準をデータセットから学習して決定します。
データ分割
では実際に決定木でAIモデルを作ってみましょう!
from sklearn.model_selection import train_test_split
train_data, test_data = train_test_split(base_data, train_size=0.8, random_state=0)
ここでは何をしているのでしょうか。train_test_splitはsklearnの機能の一つで、入力されたテーブルを分割します。分割されたテーブルのうち、一方はtrain_data, もう一方はtest_dataと名付けられています。機械学習では学習用のテーブル、そのAIの精度を評価するテーブルの2つが必要になるのでこの時点で分割しています。それぞれのテーブルがどんな感じかをみてみましょう。
train_data
OUTPUT
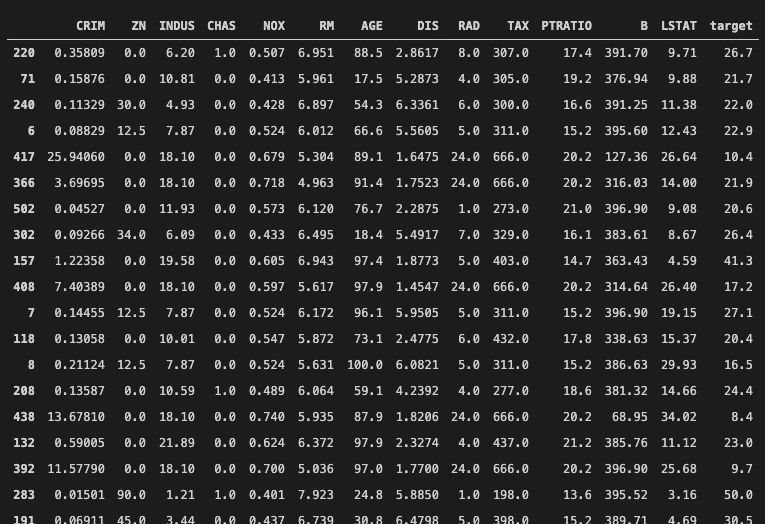
左側の行番号(インデックス)がバラバラになっているのにお気づきでしょうか。このようにもともとのテーブルをシャッフルして二つに分割するメソッドがtrain_test_splitです。ついでにtest_dataの方も見てみましょう。
test_data
OUTPUT

ここでは分割の割合をtrain : test = 8 : 2 にしています(train_size=0.8)。
次に、実際にこのtrain_dataを用いてAIモデルを学習してみましょう!
学習
from sklearn.tree import DecisionTreeRegressor
clf = DecisionTreeRegressor(criterion="mse", splitter='best', random_state=0, max_depth=10)
1行目は「sklearnのtreeアルゴリズムモデル(決定木系)からDecisionTreeRegressorの機能を使えるようにしたよ」
3行目は「clfと言う名前の学習オブジェクトを作って決定木の設定を入力したよ」
この設定(かっこの中身)の意味をちょっと解説します。
criterion, splitter…決定木の分岐の基準を設定しています。数学的な内容なのでここでは詳しい説明は割愛。
random_state…決定木は最初の分岐の質問が例えば「女性ですか?」なのか「会社員ですか?」なのかで予測結果が異なってきます。分岐での質問はランダムに決められるので、モデル作成ごとに結果が異なってしまいます。それを避けるために、random_stateを設定して分岐の仕方を統一しています。
max_depth…決定木の精度にもっとも影響を与える設定項目です。決定木の木の深さを制限して過学習を防止します。
過学習と汎化性能…AIエンジニアがいつも頭を抱える問題。学習に用いたデータ(訓練データ)に対しては良い性能を示すものの、未知のデータに対して精度が悪くなってしまう現象を過学習と言います。「犯罪率が0.5%でチャールズ川沿いで昔の建物が全体の45%あって学校の先生1人に生徒20人で…(めっちゃ条件)…ならば住宅価格はこの価格だ!」と学習してしまうことで、訓練データには非常に良い精度を示すものの、未知のデータに対しては精度が悪くなってしまいます。この条件を絞るのがmax_depthと言うわけです。訓練データに対して精度が低くても、未知のデータに対して精度が高くなることを「汎化性能が良い」といったりします。ただ闇雲にmax_depthを設定すれば良いわけでもなく、例えば日本人データベースがあるとして、それを用いてAIを作成したとします。ここでmax_depth=2で「日本人で色黒ならば松崎しげる!」と学習してしまっては日本人の結構多くが松崎しげると予想されてしまいます。少なくとも「日本人で色黒で芸能人で歌を歌って東京出身で左利きならば松崎しげる!!」とmax_depth=6ぐらいでないと正しい推論ができません(学習不足)。この汎化性能の塩梅はAIエンジニアの腕の見せ所です。
では設定した学習オブジェクトに訓練データを学習させてみます。
X_train = train_data.drop('target', axis=1)
Y_train = train_data['target']
clf.fit(X_train, Y_train)
1行目は「train_dataからtargetの列だけ取り除いたものをX_trainに代入したよ」
2行目は「train_dataからtargetの列だけをY_trainに代入したよ」
4行目は「X_trainならY_train(target)の値になるよ!とclfに学習させたよ」
次にclfが学習したことをtest_dataで調べてみましょう!
X_test = test_data.drop('target', axis=1)
clf.predict(X_test)
array([21.45 , 22.4125 , 19.84 , 9.6 , 21.5875 ,
19.61904762, 19.61904762, 19.61904762, 21.9 , 16.1 ,
7.23333333, 17.9 , 13.53571429, 7.2 , 48.5 ,
34.75 , 21.5875 , 34.75 , 24. , 19.61904762,
23.9 , 17.35 , 20.11818182, 23.9 , 19.61904762,
10.9 , 14.5 , 15.6 , 41.7 , 21.5 ,
13.53571429, 20.11818182, 18.9 , 22.94 , 19.84 ,
20.11818182, 8.5 , 22.4125 , 13.53571429, 17.2 ,
22.94 , 19.61904762, 22.2 , 13.53571429, 22. ,
18.3 , 22.4 , 15.6 , 14.75 , 22.8 ,
14.3 , 15.96666667, 19.61904762, 35.2 , 16.4 ,
18.9 , 20.63333333, 19.61904762, 10.9 , 22.4 ,
20.6 , 22.94 , 31.32 , 24. , 19.61904762,
24. , 17.4 , 23.7 , 16.3 , 24.05 ,
24.425 , 24.425 , 23.31818182, 29.92 , 25. ,
7.2 , 41.7 , 22.94 , 22.94 , 19.61904762,
27.1 , 20.11818182, 17.35 , 39.8 , 39.8 ,
24.9125 , 22.94 , 13.53571429, 24.575 , 13.25 ,
19.61904762, 11.03333333, 20.6 , 29.92 , 21.1 ,
21.5875 , 10.2 , 23.31818182, 13.25 , 19.61904762,
22.94 , 20.11818182])
1行目は「test_dataからtargetの列だけ取り除いたものをX_testに代入したよ」
3行目は「X_testからtargetを予想するよ!」
そしてOUTPUTは「予想結果だよ!」
X_testはテーブルデータなので、予測値も複数(リスト)になります。
では、この予測結果が正しいのかを検証してみます。
from sklearn.metrics import mean_squared_error
y_test = test_data['target']
y_pred = clf.predict(test_data.drop('target', axis=1))
mse = mean_squared_error(y_test, y_pred)
print(mse)
31.003506490458893
1行目は「sklearnのmetrics(評価指標)からmean_squared_errorを使えるようにしたよ。」
2行目は「テストデータの真のtargetの値をy_testに代入したよ」
3行目は「テストデータから予想したtargetの値をy_predに代入したよ」
5行目は「予想と真の値がどれくらいズレてるのかをmseと言う評価指標で比べてみたよ」
7行目は「結果を出力したよ」
となります。mean_squared_error(平均二乗誤差)は二つの値のズレを比較する指標で、この値が小さければ小さいほど精度が高いと言うことになります。今回のAIモデルの精度は「mseが31ほどだった」と言う結果になります。ここまでがAIの実装です。
最後に、この精度が良いのか悪いのかを比較してみます。
max_depthをいじってみよう
下のコードは上のclf以下のmax_depth以外はそのままです。
#max_depthを100にしたよ
clf = DecisionTreeRegressor(criterion="mse", splitter='best', random_state=0, max_depth=100)
#訓練データを特徴量と目的変数に分けたよ
X_train = train_data.drop('target', axis=1)
Y_train = train_data['target']
#学習
clf.fit(X_train, Y_train)
#テストデータの真の値と予想した値を用意したよ
y_test = test_data['target']
y_pred = clf.predict(test_data.drop('target', axis=1))
#mseの値をmse2に代入したよ
mse2 = mean_squared_error(y_test, y_pred)
print(mse2)
36.93627450980392
先ほどよりmseの値が大きくなっています。つまり精度が悪くなっているのですね。このように、AIモデルの設定を変えて精度を上げていくことをパラメーターチューニングと言います。
実際に値を投げて予測させる
こんなデータがあったとします。
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.0 | 3.24 | 1.0 | 0.460 | 6.333 | 16.2 | 5.2146 | 4.0 | 430.0 | 16.9 | 375.21 | 7.07 |
実際にこれをモデルに投げてみましょう。
data = [[0.1, 0.0, 3.24, 1.0, 0.460, 6.333, 16.2, 5.2146, 4.0, 430.0, 16.9, 375.21, 7.07]]
clf.predict(data)
array([23.7])
こんな感じになります。AIをwebで実装するときは、各フィールドから入力された値をリスト化して、学習済み(clf.fitした後)のモデルのpredictに上記の感じで投げると言う段取りになります。
最後に
本記事は前編と合わせて入門者向けに書いてみました!わからないところ、気になる所があればぜひコメントください!
追記
前編でも書きましたが、ここでも書かせてください。
現在、このボストン住宅価格のデータセットはsklearnで利用が非推奨になっています。
理由はこのQiita記事が詳しいのでご興味ある方は覗いていってください。
もし勉強会などで住宅価格データセットを用いたい場合は、「カリフォルニア住宅価格データセット」を用いましょう。
紹介
株式会社 Panta Rheiでは「Everything Analysable」を標榜とし、世の中にあるあらゆる定性的な対象をAIによって定量化する事業をおこなっております。
AIに召し上がっていただく綺麗なデータを作る、データフローを整形するなどの課題や、そもそものAIの内製化等、挑戦したい試みがあればぜひご一報ください!