はじめまして
始めまして!株式会社 Panta Rheiの「かず」と申します。pandasista という名前でXをやっております。以後お見知り置きを!
本記事は4年前に勉強会で用いた記事になります!
導入
Pythonの機械学習用パッケージ「scikit-learn」を用いてAI実装をしてみましょう!
本記事で扱うデータセットは「ボストンの住宅価格」。1970年のボストン標準都市統計地区のデータで、ボストン郊外または市内の住宅価格データとなっております。
今回は、このデータセットを用いて、ボストンの住宅価格を予想するAIを作ってみます!!
※ボストン住宅価格データセットは追記で示す理由で最新のsklearnには実装されていません。
sklearnのバージョンは1.1以下で行ってください。
用いるパッケージ
- pandas (呼び方:パンダス)
- テーブルデータを扱いやすくしたパッケージ。Pythonのエクセルみたいなもの。
- scikit-learn(sklearn) (呼び方:サイキット-ラーン)
- 元祖機械学習用pythonパッケージ。Python言語を「AIに強い」という評価に押し上げたのはこのパッケージのおかげと言っても過言ではない。後発のAI用pythonパッケージ(Keras, LightGBMなど)が続々とscikit-learn式のAI記法に習ったため、新しいAIのパッケージを実装するときも、このパッケージの使い方さえ覚えてしまえば楽に対応できる。
- numpy (呼び方:ナンパイ)
- pythonでデータを扱うときに用いるもっとも基本的なパッケージ。行列計算用のパッケージなので計算は早いものの、データの見やすさの点でpandasにおとる。本記事では扱わない。
- matplotlib (呼び方:マトプロットリブ)
- python用可視化パッケージ。グラフとかを描く。
データを取り込む
以下のようにVScodeのセルに書いてみよう。
import pandas as pd
import numpy as np
from sklearn.datasets import load_boston
data = load_boston()
1, 2行目は「pandasとnumpyを使えるようにしたよ」
3行目は「sklearn.datasetsからload_bostonを使えるようにしたよ」
※「import sklearn」でも問題ないが、sklearnはあまりに機能が多いため、importする際は「from sklearn.~ import ~」と少し絞るのが慣例。
5行目は「load_boston()に'data'という名前をつけたよ」
dataの中身を見てみる
print(data)
{'data': array([[6.3200e-03, 1.8000e+01, 2.3100e+00, ..., 1.5300e+01, 3.9690e+02,
4.9800e+00],
[2.7310e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9690e+02,
9.1400e+00],
[2.7290e-02, 0.0000e+00, 7.0700e+00, ..., 1.7800e+01, 3.9283e+02,
4.0300e+00],
...,
[6.0760e-02, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9690e+02,
5.6400e+00],
[1.0959e-01, 0.0000e+00, 1.1930e+01, ..., 2.1000e+01, 3.9345e+02,
(後略)
これを見てみると「{key1: value1 …」といった辞書型になっていますね。つまり、'data'とは辞書型のオブジェクトということになります。
次に辞書の'key'として何が含まれているかを確認してみましょう。
print(data.keys())
dict_keys(['data', 'target', 'feature_names', 'DESCR', 'filename'])
5つのkeyが確認できました。
ではそれぞれのkeyに対応するvalueを見ていきましょう。
print(data['data'])
[[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00]
[2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00]
[2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00]
...
[6.0760e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 5.6400e+00]
[1.0959e-01 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9345e+02 6.4800e+00]
[4.7410e-02 0.0000e+00 1.1930e+01 ... 2.1000e+01 3.9690e+02 7.8800e+00]]
この「辞書名['辞書のkey']」でそのkeyに対応するvalueが得られる書き方は覚えましょう。これと同様の記法をpandasで多用します。なんだかデータらしきものが書いてありますね。ただこれではなんのデータかわかりません。
print(data['feature_names'])
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
AIの世界ではテーブルデータの各列のことを「特徴量(feature)」と呼びます。例えば、地域ごとの人口などから地域の天候を予想したい場合、「人口」は特徴量の一つになります。このOUTPUTは、このデータの特徴量をまとめたリストを表示しています。
pandasで綺麗に整形
このままでは、どんなデータなのかがパッとイメージしにくい!!ここでついにpandasの登場です!
main_data = data['data']
feature_names = data['feature_names']
df = pd.DataFrame(main_data, columns=feature_names)
print(df)
OUTPUT

なんだかエクセルっぽくなりましたね!実はリストの中にリストが含まれるようなデータ(ネストしているデータと言います)をpandasに渡すと自動でエクセル風味のテーブルデータに変換してくれます!でもこのデータの列名(特徴量)はアルファベットで書いてあり、どういう意味か分からない…。以下がその特徴量の各意味になります。
| 特徴量 | 説明 | 補足 |
|---|---|---|
| CRIM | 1人当たりの犯罪数 | |
| ZN | 町別の25,000平方フィート以上の住居区画の割合 | |
| INDUS | 町別の非小売業が占める土地面積の割合 | |
| CHAS | チャールズ川沿いかどうか | 川沿い:1, 非川沿い:0 |
| NOX | 町別の窒素酸化物の濃度 | |
| RM | 住居の平均部屋数 | |
| AGE | 1940年よりも前に建てられた物件の割合 | |
| DIS | ボストンにある5つの雇用施設までの重み付きの距離 | |
| RAD | 環状高速道路へのアクセス指標 | |
| TAX | 10,000ドルあたりの固定資産税の割合 | |
| PTRATIO | 町ごとの生徒と教師の比率 | |
| B | 1000(Bk – 0.63)^2の値 | Bkは町ごとの黒人の割合 |
| LSTAT | 低所得者の割合(%) |
これらのデータから、その各地区の住宅価格を予想しようというわけです。でも肝心の住宅価格データはどこにあるのでしょうか。これは先ほどのdata(辞書型)のkeyの一つである'target'のvalueがその住宅価格データになります。
print(data['target'])
[24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4
18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8
(中略)
8.1 13.6 20.1 21.8 24.5 23.1 19.7 18.3 21.2 17.5 16.8 22.4 20.6 23.9
22. 11.9]
このようになっています。これが今回予測したい対象です。ただこれもリスト型になっていて大量のデータは扱いにくいです。pandasを使いましょう。
target_data = data['target']
target_df = pd.DataFrame(target_data, columns=['target'])
target_df
OUTPUT

やはりpandasを用いると非常に見やすくなりますね!機械学習では予測したい対象のことを「目的変数(ターゲット)」と呼びます。今回の目的変数は住宅価格ということになります。
ここまでの流れをまとめます。
AI(機械学習)の基本的な考え方は
「様々な特徴量から、目的変数を推測する」
ことになります。この特徴量からどう目的変数を推測するかというのがアルゴリズムの部分というわけです。
次にpandasのメソッド「concat」を用いて、このdfとtarget_dfを横に連結してみましょう。
base_df = pd.concat([df, target_df], axis=1)
base_df
OUTPUT

先ほどの特徴量のテーブルの右端にtargetの列が追加されていると思います。
このように、pandasはテーブルの扱いに特化したパッケージとなります。pandasを使うときはだいたい
[pd.(メソッド名)」
という書き方になります。
EDA(Explanatory Data Analysis:探索的データ分析)
どのようなAIエンジニアも、これから扱おうとしているデータがどのようなものかを分析します。この分析結果によって用いるAIのアルゴリズムを選定したり、AIの精度を落としてしまいそうな特徴量(ノイズ特徴量と言ったりします)を削除したりします(新しく特徴量を追加することも)。
ノイズ特徴量の例としては、電車の遅延を予想したいとき、電車の色というのは遅延に全く関係ないのでノイズ特徴量となります。AIアルゴリズムはどんなデータからも関係性を見出して予測しようとするので、いらないデータは削除した方がAIの精度が上がるというわけです。
このようにAIモデルを作る際にデータを見て分析することを
「EDA(探索的データ分析)」と言います。
EDAの例をボストンの住宅価格で実際に行ってみましょう。
例えば、「犯罪率が低ければ住宅価格は上がるだろう」との仮説を立てて実際に検証してみます。
from matplotlib import pyplot as plt
plt.scatter(base_df['CRIM'], base_df['target'])
plt.xlabel('CRIM')
plt.ylabel('target(Price)')
plt.show()
OUTPUT
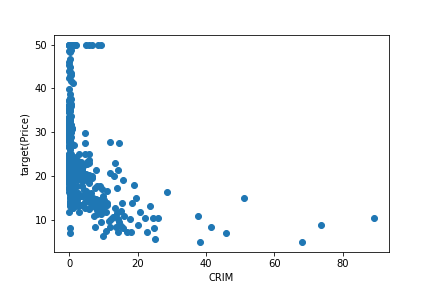
1行目は「matplotlibというパッケージのpyplot機能をpltという名前で使えるようにしたよ」
3行目は「横軸にbase_dataのCRIM、縦軸にbase_dataのtargetをとる散布図を書いてみたよ」
4行目は「横軸に'CRIM'とラベルをつけたよ」
5行目は「縦軸に'target(Price)'とラベルをつけたよ」
6行目は「今まで設定してきたグラフを表示するよ」
ここで初登場の「matplotlib」というパッケージ。これはpandasやnumpy、pythonのリスト型で表現されたテーブルなどを可視化するパッケージです。本当に多様な可視化機能を持っていて、散布図以外にもヒストグラムや棒グラフ、箱ひげ図、折れ線グラフなんかも書けてしまいます。
では先ほどの可視化コードに少し追加して、より見やすい図を書いてみましょう。
from matplotlib import pyplot as plt
plt.scatter(base_df['CRIM'], base_df['target'], s=1, c='green')
plt.xlabel('CRIM')
plt.ylabel('target(Price)')
plt.title('The relation between CRIM and Price')
plt.savefig('CRIM_Price.png')
plt.show()
OUTPUT

点が小さくなって緑色になっています。小さくなった方が点同士が被らないで見やすさが増しますね。
また、「The relation between CRIM and Price」という表題がつきました。
さらに、このファイルを実行したディレクトリの中に「CRIM_Price.png」というPNG画像ファイルが出力されていますので確認してみてください。
このように、matplotlibは「plt.(メソッド名)」という表現方法で描画を行います。他にもグリッドを追加したり、目盛り線を追加したり、一つの画像に複数のグラフを並べたりと、色々な機能があります。実際にボストンデータセットを使って試してみると面白いと思います!
データサイエンティストはこの可視化パッケージを頻繁に使います。EDA用途以外にも、図表をパワポにまとめて提案材料にしたりと、ビジネス面でも幅広く使えるのでpythonスキルとしてぜひ勉強してみてください!(エクセルよりもテーブルが多様に扱えるのでDSの人はエクセルをあまり使わないです)
さて、今回の仮説は「犯罪率が低ければ住宅価格は上がるだろう」でした。グラフを見る限り、当たっている感じがしますね!
こんな感じで「仮説→可視化して検証」のサイクルを回すことがEDAの基本的な流れになります。
まとめ
本記事では、ボストン住宅価格データを用いてpandasとmatplotlibに慣れていただくというのがテーマでした!
次の記事はいよいよ機械学習に入っていきます!お楽しみに!
追記
現在、このボストン住宅価格のデータセットはsklearnで利用が非推奨になっています。
理由はこのQiita記事が詳しいのでご興味ある方は覗いていってください。
もし勉強会などで住宅価格データセットを用いたい場合は、「カリフォルニア住宅価格データセット」を用いましょう。
紹介
株式会社 Panta Rheiでは「Everything Analysable」を標榜とし、世の中にあるあらゆる定性的な対象をAIによって定量化する事業をおこなっております。
AIに召し上がっていただく綺麗なデータを作る、データフローを整形するなどの課題や、そもそものAIの内製化等、挑戦したい試みがあればぜひご一報ください!