はじめに
私は、某大学の薬学研究科を経て、製薬メーカーの品質管理として働いております。
現場で働く中「医療×IT(AI)」という分野に興味を惹かれ、プログラミングを本格的に学び始めました。
今回はその第一歩として、
ヘーゼルナッツの不良品検知を、Python を使用した機械学習(転移学習)を
アプリとして実装してみました。
本記事の概要
- Python で画像認識等を行っている方に向けて、コードを説明しながら、アプリの実装までの過程を書いています。
- 熟練者の方が見ると、違和感があるかもしれませんが、そこは初心者が作ったものとしてご容赦ください。
- もし何かコメント等ございましたら、是非教えていただけますと幸いです。
実際のアプリケーション
まずは実際のアプリケーションを紹介します。
下記のリンクにアクセスして、ナッツの画像を送信すると、不良品を検知してくれます。
目次
- 実行環境
- 画像収集
- 機械学習モデルの作成・実行
- 精度向上のための取り組み
- HTML&CSSの作成
- 結果と考察
- 今後の展望
1. 実行環境
- Windows 11
- Visual Studio Code
- Google Colaboratory
2. 画像収集
データセットは、こちらのデータをダウンロードして使用します。
Googleドライブに zip ファイルを保存し、それを以下のコードで Google Colaboratory で解凍します。
!unzip /content/drive/MyDrive/Aidemy/成果物/Hazelnut.zip -d /content/drive/MyDrive/Aidemy/成果物/
Google Colaboratory からマイドライブの画像を扱うためにGoogleドライブをマウントする必要がありますが、それについては以下の記事を参照するとわかりやすいと思います。
参考:ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話
3. モデル作成・実行
コードの全体像を以下に示します。
コードの全体像
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from google.colab import files
# パスの指定
path_train_good = os.listdir('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/good')
path_train_crack = os.listdir("/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/crack")
path_test_good = os.listdir('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/good')
path_test_crack = os.listdir("/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/crack")
#格納場所の作成
img_train_good = []
img_train_crack = []
img_test_good = []
img_test_crack = []
#画像を格納
for i in range(len(path_train_good)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/good/' + path_train_good[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_train_good.append(img)
for i in range(len(path_train_crack)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/crack/' + path_train_crack[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_train_crack.append(img)
for i in range(len(path_test_good)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/good/' + path_test_good[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_test_good.append(img)
for i in range(len(path_train_crack)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/crack/' + path_test_crack[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_test_crack.append(img)
##学習データを水増し
# ImageDataGeneratorクラスのオブジェクト生成
datagen = ImageDataGenerator(
rotation_range=45, #±45°でランダムに回転
vertical_flip=True, #垂直方向にランダムで反転
horizontal_flip=True)#水平方向にランダムで反転
def images_gen(X_list, y_list):
X_list_add = []
y_list_add = []
for X, y in zip(X_list, y_list):
X = X.reshape((1,) + X.shape) # 元の画像を4次元に変形
i = 0
for batch in datagen.flow(X, batch_size=1):
batch = batch[0].astype(np.uint8) # バッチから画像を取り出し、データ型を揃える
X_list_add.append(batch)
y_list_add.append(y)
i += 1
if i > 9: # 1枚から10枚生成
break
X_add = np.array(X_list_add)
y_add = np.array(y_list_add)
return X_add, y_add
X_train = np.array(img_train_crack + img_train_good)
y_train = np.array([0]*len(img_train_crack) + [1]*len(img_train_good))
X_test = np.array((img_test_crack + img_test_good))
y_test = np.array([0]*len(img_test_crack) + [1]*len(img_test_good))
#画像をリサイズする(元画像は800*800)
X_train = np.array([cv2.resize(img, (100, 100)) for img in X_train])
X_test = np.array([cv2.resize(img, (100, 100)) for img in X_test])
#水増し
X_train,y_train = images_gen(X_train,y_train)
X_test,y_test = images_gen(X_test,y_test)
# 正解ラベルをone-hotの形にします(ダミー変数を用いた変換)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 転移学習のモデルにvgg16を使用
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(vgg16.inputs, top_model(vgg16.output))
# vgg16の層の重みを変更不能に
for layer in model.layers[:19]:
layer.trainable = False
# コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
model.summary()
# 学習を行います
history = model.fit(X_train, y_train, batch_size=50, epochs=5, validation_data=(X_test, y_test))
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
#以下、可視化のためのコード
train_loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
epochs =len(train_loss)
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax1 = fig.add_subplot(1,2,1)
ax1.plot(range(epochs), train_loss, marker = '.', label = 'train_loss')
ax1.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
ax1.legend(loc = 'best')
ax1.set_xlabel('epoch')
ax1.set_ylabel('loss')
ax2 = fig.add_subplot(1,2,2)
ax2.plot(range(epochs), acc, label="acc", ls="-", marker=".")
ax2.plot(range(epochs), val_acc, label="val_acc", ls="-", marker=".")
ax2.set_ylabel("accuracy")
ax2.set_xlabel("epoch")
ax2.legend(loc="best")
plt.show()
ディレクトリ構造は以下の通りです。
まずは、ライブラリをインポート。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from google.colab import files
画像の前処理
先ほど展開したzipファイルの中身を確認し、画像を学習用とテスト用に分けて格納します。
# パスの指定
path_train_good = os.listdir('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/good')
path_train_crack = os.listdir("/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/crack")
path_test_good = os.listdir('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/good')
path_test_crack = os.listdir("/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/crack")
#格納場所の作成
img_train_good = []
img_train_crack = []
img_test_good = []
img_test_crack = []
#画像を格納
for i in range(len(path_train_good)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/good/' + path_train_good[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_train_good.append(img)
for i in range(len(path_train_crack)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/train/crack/' + path_train_crack[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_train_crack.append(img)
for i in range(len(path_test_good)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/good/' + path_test_good[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_test_good.append(img)
for i in range(len(path_train_crack)):
img = cv2.imread('/content/drive/MyDrive/Aidemy/成果物/Hazelnut/test/crack/' + path_test_crack[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
img_test_crack.append(img)
ただし、これだけでは学習用データが少ないので、
ImageDataGeneratorを使用して水増しします。
参考:ImageDataGeneratorで画像を水増しする方法
##学習データを水増し
# ImageDataGeneratorクラスのオブジェクト生成
datagen = ImageDataGenerator(
rotation_range=45, #±45°でランダムに回転
vertical_flip=True, #垂直方向にランダムで反転
horizontal_flip=True)#水平方向にランダムで反転
def images_gen(X_list, y_list):
X_list_add = []
y_list_add = []
for X, y in zip(X_list, y_list):
X = X.reshape((1,) + X.shape) # 元の画像を4次元に変形
i = 0
for batch in datagen.flow(X, batch_size=1):
batch = batch[0].astype(np.uint8) # バッチから画像を取り出し、データ型を揃える
X_list_add.append(batch)
y_list_add.append(y)
i += 1
if i > 9: # 1枚から10枚生成
break
X_add = np.array(X_list_add)
y_add = np.array(y_list_add)
return X_add, y_add
X_train = np.array(img_train_crack + img_train_good)
y_train = np.array([0]*len(img_train_crack) + [1]*len(img_train_good))
X_test = np.array((img_test_crack + img_test_good))
y_test = np.array([0]*len(img_test_crack) + [1]*len(img_test_good))
#画像をリサイズする(元画像は800*800)
X_train = np.array([cv2.resize(img, (100, 100)) for img in X_train])
X_test = np.array([cv2.resize(img, (100, 100)) for img in X_test])
#水増し
X_train,y_train = images_gen(X_train,y_train)
X_test,y_test = images_gen(X_test,y_test)
機械学習のモデル作成
機械学習の構造は、以下の通りです。
今回は、VGG16という「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルを使って転移学習をします。
実際に作成されたモデルを確認するには
model.summary()
で確認できます。
実際に確認してみると以下のように表示されます。
モデル
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) [(None, 100, 100, 3)] 0
block1_conv1 (Conv2D) (None, 100, 100, 64) 1792
block1_conv2 (Conv2D) (None, 100, 100, 64) 36928
block1_pool (MaxPooling2D) (None, 50, 50, 64) 0
block2_conv1 (Conv2D) (None, 50, 50, 128) 73856
block2_conv2 (Conv2D) (None, 50, 50, 128) 147584
block2_pool (MaxPooling2D) (None, 25, 25, 128) 0
block3_conv1 (Conv2D) (None, 25, 25, 256) 295168
block3_conv2 (Conv2D) (None, 25, 25, 256) 590080
block3_conv3 (Conv2D) (None, 25, 25, 256) 590080
block3_pool (MaxPooling2D) (None, 12, 12, 256) 0
block4_conv1 (Conv2D) (None, 12, 12, 512) 1180160
block4_conv2 (Conv2D) (None, 12, 12, 512) 2359808
block4_conv3 (Conv2D) (None, 12, 12, 512) 2359808
block4_pool (MaxPooling2D) (None, 6, 6, 512) 0
block5_conv1 (Conv2D) (None, 6, 6, 512) 2359808
block5_conv2 (Conv2D) (None, 6, 6, 512) 2359808
block5_conv3 (Conv2D) (None, 6, 6, 512) 2359808
block5_pool (MaxPooling2D) (None, 3, 3, 512) 0
sequential_3 (Sequential) (None, 2) 1180418
=================================================================
| Layer (type) | Output Shape | Param # |
|---|---|---|
| input (InputLayer) | [(None, 100, 100, 3)] | 0 |
| block1_conv1 (Conv2D) | (None, 100, 100, 64) | 1792 |
| block1_conv2 (Conv2D) | (None, 100, 100, 64) | 36928 |
| block1_pool (MaxPooling2D) | (None, 50, 50, 64) | 0 |
| block2_conv1 (Conv2D) | (None, 50, 50, 128) | 73856 |
| block2_conv2 (Conv2D) | (None, 50, 50, 128) | 147584 |
| block2_pool (MaxPooling2D) | (None, 25, 25, 128) | 0 |
| block3_conv1 (Conv2D) | (None, 25, 25, 256) | 295168 |
| block3_conv2 (Conv2D) | (None, 25, 25, 256) | 590080 |
| block3_conv3 (Conv2D) | (None, 25, 25, 256) | 590080 |
| block3_pool (MaxPooling2D) | (None, 12, 12, 256) | 0 |
| block4_conv1 (Conv2D) | (None, 12, 12, 512) | 1180160 |
| block4_conv2 (Conv2D) | (None, 12, 12, 512) | 2359808 |
| block4_conv3 (Conv2D) | (None, 12, 12, 512) | 2359808 |
| block4_pool (MaxPooling2D) | (None, 6, 6, 512) | 0 |
| block5_conv1 (Conv2D) | (None, 6, 6, 512) | 2359808 |
| block5_conv2 (Conv2D) | (None, 6, 6, 512) | 2359808 |
| block5_conv3 (Conv2D) | (None, 6, 6, 512) | 2359808 |
| block5_pool (MaxPooling2D) | (None, 3, 3, 512) | 0 |
| sequential_3 (Sequential) | (None, 2) | 1180418 |
データの整形をし、作成したモデルに学習させる
学習用データとテストデータを読み込み、ラベルのOne-hot表現などをします。
One-hot表現とは、ダミー変数を用いて正解ラベルを1、それ以外を0にすることです。
モデルの構築・学習の際に、ハイパーパラメータ(人が決める数値)である、batch_size, epochs(試行回数)等を調整してゆきます。
# 正解ラベルをone-hotの形にします(ダミー変数を用いた変換)
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# 転移学習のモデルにvgg16を使用
input_tensor = Input(shape=(100, 100, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、2クラス分類する層を定義
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation='softmax'))
# vgg16とtop_modelを連結
model = Model(vgg16.inputs, top_model(vgg16.output))
# vgg16の層の重みを変更不能に
for layer in model.layers[:19]:
layer.trainable = False
# コンパイル
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習を行います
history = model.fit(X_train, y_train, batch_size=50, epochs=5, validation_data=(X_test, y_test))
4. 精度向上に向けた取り組み
上記のハイパーパラメータを調整することで、学習の精度を上げたり過学習を抑制したりすることができます。
このモデルだから、この値!と決まったものはなく、試行錯誤して最適解を見つけてゆきます。
その際に下記のコードで精度評価をしてゆきます。
# 精度の評価
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
#以下、可視化のためのコード
train_loss = history.history['loss']
val_loss = history.history['val_loss']
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
epochs =len(train_loss)
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax1 = fig.add_subplot(1,2,1)
ax1.plot(range(epochs), train_loss, marker = '.', label = 'train_loss')
ax1.plot(range(epochs), val_loss, marker = '.', label = 'val_loss')
ax1.legend(loc = 'best')
ax1.set_xlabel('epoch')
ax1.set_ylabel('loss')
ax2 = fig.add_subplot(1,2,2)
ax2.plot(range(epochs), acc, label="acc", ls="-", marker=".")
ax2.plot(range(epochs), val_acc, label="val_acc", ls="-", marker=".")
ax2.set_ylabel("accuracy")
ax2.set_xlabel("epoch")
ax2.legend(loc="best")
plt.show()
上記の条件で学習を行った結果を、下図に示します。
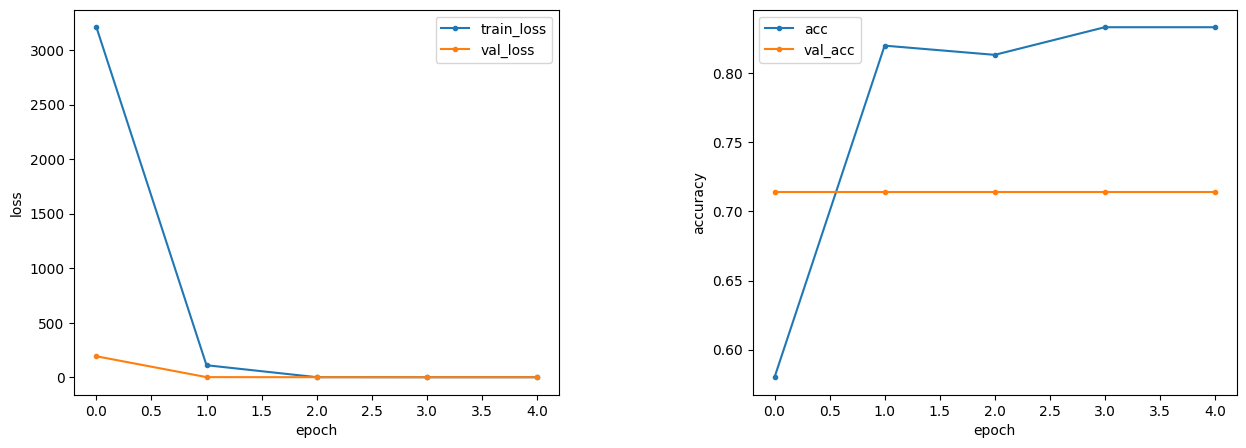
| 結果 | loss | accuracy |
|---|---|---|
| training | 0.4498 | 0.8333 |
| test(val) | 0.6277 | 0.7143 |
グラフをみると、accuracyが乖離しています。
また、テスト用データの正解率がずっと横ばいになっています。
理由として、過学習の可能性が考えられます。
そのため、どこかのパラメータを変更する必要がありますね。
画像の水増しなし、エポック数5 → 20
今度は、過学習を防ぐため、画像の水増しを無くして、
代わりに「epochs」のパラメータを増やして学習させてみます。(下図)
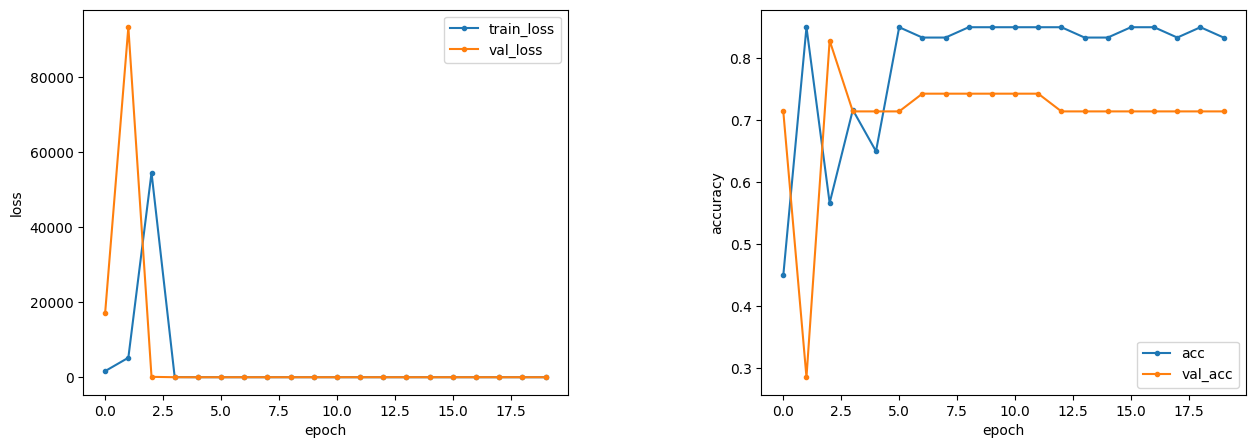
| 結果 | loss | accuracy |
|---|---|---|
| training | 0.4533 | 0.8333 |
| test(val) | 0.6521 | 0.7143 |
accuracyのグラフでは、初めの学習は乱高下しますが、
epoch=5 くらいのところで徐々に正解率が落ち着いてきています。
ただ、こちらのモデルでも、
正解率は、学習用データ、テスト用データともに、
画像の水増しの結果と変化がありませんでした。
最適化アルゴリズム(optimizer) sgd → adam、エポック数20 → 30
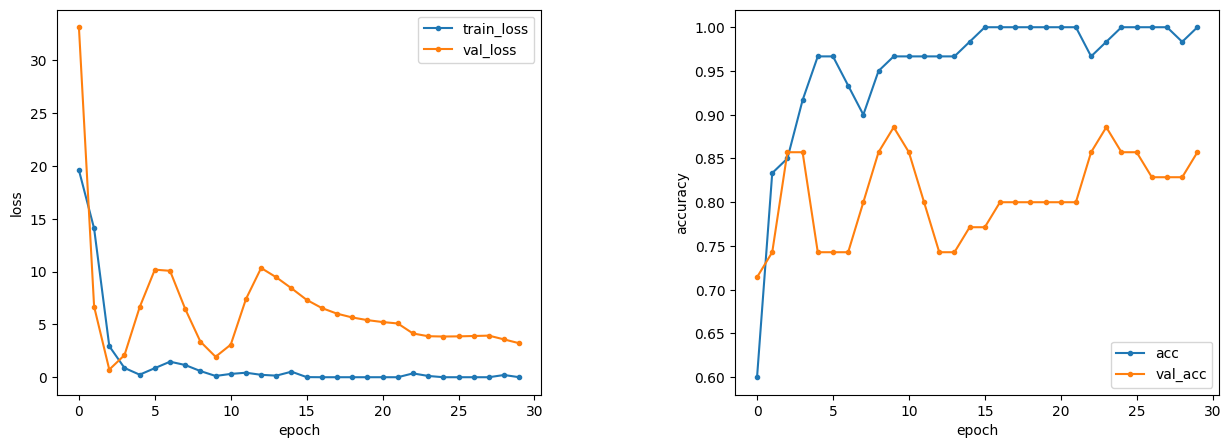
| 結果 | loss | accuracy |
|---|---|---|
| training | 1.9868e-09 | 1.0000 |
| test(val) | 3.2172 | 0.8571 |
最適化アルゴリズムを「sgd」から「adam」に変えました。
けっこう違いますね。収束が早くなっています。
また、数値を見ても、こちらの方が高い正解率を出しています。
まだ改善の余地があるかと思いますが、
ある程度の精度が出ていますので、こちらで今回は実装してみます。
5. HTML&CSSの作成
今まではローカル環境で作成・調整していたのですが、モデル構築が完了したので、
次は、全世界へ公開できるようにします。
まずは、HTMLのコードの作成。
index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Hazelnuts Anomaly Detection</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<a class="header-logo" href="#">Hazelnuts Anomaly Detection</a>
</header>
<div class="main">
<h2> AIがヘーゼルナッツの不良品を検知します</h2>
<p>画像を送信してください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://aidemyexstorage.blob.core.windows.net/aidemycontents/1621500180546399.png" alt="Aidemy">
<small>© 2019 Aidemy, inc.</small>
</footer>
</body>
</html>
CSSの作成はこんな感じ。
stylesheet.css
header {
background-color: #1c7f68;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #743939;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #5e7fab;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
そしてこれらのデータを、Render と GitHub を用いてデプロイしたら、全世界へ公開となります!(下図)
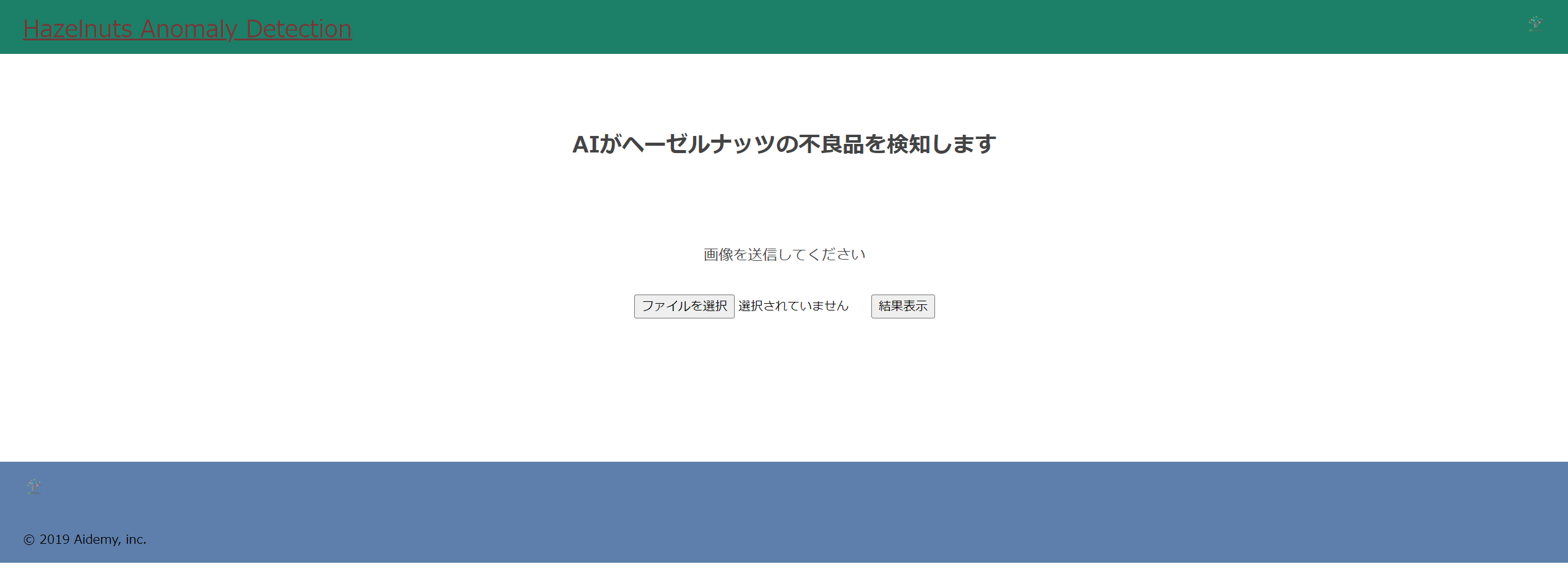
一度、テストとして試してみます。
今回は、この画像を判定してもらいます。明らかに不良品ですね。

こちらを、先ほどの画面のファイル選択に入れて、結果を表示すると…

正しく「不良品」と判定されました!
これで実装も問題なく完了していることが確認できました!
6. 結果と考察
今回、ヘーゼルナッツの不良品検知を転移学習にて実装しました。
過学習やハイパーパラメータの調整など課題は残るものの、
正解率は、8割前後とまずまずの結果を出せていたと考えています。
一方、過学習によって汎化ができなかった原因ですが、
今回用意した画像データセットが今回のモデルに適していなかった可能性が考えられます。
つまり、今回のモデル(VGG16 転移学習)で、
期待した特徴量を上手く抽出できなかった可能性があるのではないかと考えられます。
また、画像の特徴をより捉えることのできる「正規化」処理をしていなかったことも
原因の一つなのではないかと考えられます。
この辺りは、追々アップデートできればと思います。
7.今後の展望
今回、1つの AI アプリを全世界に公開する過程を、
自分1人で成し遂げられたことがとても学びになりました。
今回、転移学習ということで、ほとんどの重みづけは VGG16 に依存してしまったのですが、
今回の経験を活かして、重みの調整やモデルの層構築を行って、
最終的には社会実装できるように、学習していきたいと思います。
また、今回の画像認識による不良品検知というのは、
医薬品業界の品質管理でも活かせると思うので、
これで「医療×AI」を進められるという確信を持って、理解を深めていこうと思います。
ここまでお読みいただきありがとうございました!
参考記事
Niziuのメンバーを機械学習で分類してみた
VGG16のFine-tuningによる17種類の花の分類
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
AIによる画像認識でパンの美味しさを推測する