はじめに
はじめまして。最近機械学習を勉強している者です。
今回Niziuのメンバーを分類するアプリを作成してみたため、
アウトプットを目的として記事を作成いたします。
エンジニア経験すらない初心者ですので効率の悪いやり方をしていると思いますが、
どうか温かい目で見守ってくださると幸いです(?)
目次
- 画像の選定
- 画像の選定
- 画像から顔の部分を切り抜き
- 画像を訓練データとテストデータに分割
- 訓練データの拡張
- モデルの定義と学習
- 画像の推定
- まとめ
Niziuとは
NiziU(ニジュー、韓: 니쥬)は、9人組ガールズグループである。日本のソニーミュージックと韓国のJYPエンターテインメントによる日韓合同のグローバルオーディションプロジェクト「Nizi Project」パート2の最終順位上位9名から結成された[4][5]。
グループ名は、Nizi Projectの「Nizi(虹)」と、メンバーやファンを表す「U」に由来しており[6]、「Need you」という意味を含んでいる。プロデューサーのパク・ジニョンはメンバーに対して「人は一人では成功できない。みんなにはお互いが必要で、ファンが必要である」と語っている[7][8]。
ファンクラブ名は「WithU(ウィジュー)」で[9]、「NiziUを支えてくれるファンのみなさん(U)と一緒に(With)世界へ向けて活動していく」という思いが込められている[9]。
Wikipediaより引用
「Nizi project」というオーディションで総勢10,231人から選ばれた9人組のガールズグループで、
メンバーは「マコ」「マヤ」「マユカ」「リク」「ミイヒ」「リオ」「アヤカ」「ニナ」「リマ」の9人です。
今までK-POPに興味がなかったのですが、
友達に「Nizi Project」を勧められてからどっぷりハマりました。
メンバーが全員日本人なのでKPOPか否か論争があるみたいですが、正直どっちでもいいです。
とにかく若い子達が厳しいオーディションに挑戦する姿に感動して何度も泣きました。
アイドルとかKPOPに興味がない人にもぜひ見てもらいたいです。
1. 画像の収集
まずは、画像分類に必要な画像をGoogle画像検索から収集します。
Google Custom Search APIを使えば画像を集められるそうですが、
初心者すぎてそんなこと知りませんでした。
なのでSeleniumを使ってメンバー1人当たり300枚程度の画像を集めました。
流れとしては
⑴. 画像のURLを取得し、CSVファイルに保存
⑵. CSVファイルに保存したURLから画像を保存
です。
回りくどいことをしていますが、勉強のためにしました。
Seleniumの使い方に関しては以下の記事を参考にしました。
参考: Python + Selenium で Chrome の自動操作を一通り
⑴. 画像のURLを取得
コードの全体像は以下です。
get_images_url.py
# インポート
import os
from time import sleep
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
# シークレットモードでChromeを表示ために設定
options = Options()
options.add_argument("--incognito") # シークレットウィンドウでChromeを起動
# options.add_argument('--headless') # headlessモードで実行する際に使用
driver = webdriver.Chrome(executable_path="./chromedriver", options=options)
# 指定したURLを表示
url = "https://www.google.co.jp/imghp?hl=ja&tab=ri&ogbl" # google画像検索ページのURL
driver.get(url)
sleep(2)
# キーワードを入力し、検索
member_name = "取得したいメンバーの名前"
query = "niziu " + member_name
search_box = driver.find_element_by_class_name("gLFyf")
search_box.send_keys(query)
search_box.submit()
sleep(2)
# スクロール操作
height = 1000
while height < 50000:
driver.execute_script("window.scrollTo(0, {});".format(height))
height += 3000
sleep(1)
# サムネイルのURLを取得
thumnail_urls = driver.find_elements_by_class_name("rg_i")
thumnail_urls_len = len(thumnail_urls)
print("thumnail_urls_len :{}".format(thumnail_urls_len))
# サムネイルをクリックして各画像URLを取得
image_urls = set()
for img in thumnail_urls[:300]:
try:
img.click()
sleep(2)
except Exception:
continue
try:
url_xpath = driver.find_element_by_xpath('//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div/div[2]/a/img')
url = url_xpath.get_attribute("src")
if url and "https:" in url:
image_urls.add(url)
print(url)
print()
except Exception as e:
print("no such element")
# csvファイルに保存
image_urls = list(image_urls)
df = pd.DataFrame(image_urls, columns=["url"])
df.to_csv("{}_image_url.csv".format(member_name))
# 画面終了
driver.quit()
まずは、ライブラリをインポート。
import os
from time import sleep
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pandas as pd
Chromeをシークレットウィンドウで起動し、 今回は「niziu 〇〇(メンバーの名前)」という形で検索をした画像を取得していきます。
options = Options()
options.add_argument("--incognito") # シークレットウィンドウでChromeを起動
# options.add_argument('--headless') # headlessモードで実行する際に使用
driver = webdriver.Chrome(executable_path="./chromedriver", options=options)
url = "https://www.google.co.jp/imghp?hl=ja&tab=ri&ogbl" # google画像検索ページのURL
driver.get(url)
sleep(2)
# キーワードを入力し、検索する
member_name = "取得したいメンバーの名前"
query = "niziu " + member_name
search_box = driver.find_element_by_class_name("gLFyf")
search_box.send_keys(query)
search_box.submit()
sleep(2)
Google画像検索ページで大量の画像を取得する場合はある程度画面をスクロールして画面更新しないといけないので、 自動でスクロールさせた後に画像のURLを取得していきます。
# スクロール操作
height = 1000
while height < 50000:
driver.execute_script("window.scrollTo(0, {});".format(height))
height += 3000
sleep(1)
# サムネイルのURLを取得
thumnail_urls = driver.find_elements_by_class_name("rg_i")
thumnail_urls_len = len(thumnail_urls)
print("thumnail_urls_len :{}".format(thumnail_urls_len))
# サムネイルをクリックして各画像URLを取得
image_urls = set()
for img in thumnail_urls[:300]:
try:
img.click()
sleep(2)
except Exception:
continue
try:
url_xpath = driver.find_element_by_xpath('//*[@id="Sva75c"]/div/div/div[3]/div[2]/c-wiz/div/div[1]/div[1]/div/div[2]/a/img')
url = url_xpath.get_attribute("src")
if url and "https:" in url:
image_urls.add(url)
except Exception as e:
print("no such element")
image_urlsに格納した画像のURLをCSVに保存。
# csvファイルに保存
image_urls = list(image_urls)
df = pd.DataFrame(image_urls, columns=["url"])
df.to_csv("{}_image_url.csv".format(member_name))
# 画面終了
driver.quit()
⑵. 画像のURLから画像を保存していく
コードの全体像は以下です。
get_images.py
# インポート
import os
import requests
import pandas as pd
members_name = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
for member_name in members_name:
# CSVの読み込み
df = pd.read_csv("{}_image_url.csv".format(member_name))
# 各メンバーのディレクトリがない場合は作成
IMAGE_DIR = "images/{}/".format(member_name)
if not os.path.exists(IMAGE_DIR):
os.mkdir(IMAGE_DIR)
# URLから画像をダウンロード
for i, url in enumerate(df.url):
try:
image = requests.get(url)
with open(IMAGE_DIR + "{}_{}".format(member_name, str(i).zfill(3)) + ".jpg", "wb") as f:
f.write(image.content)
except Exception as e:
print(member_name, i, "error!!")
ディレクトリ構造は以下です。
root/
┠ get_images.py
┠ csvファイル
┗ images/
├ mako/
├ maya/
...
└ rima/
まずはライブラリをインポート。
# インポート
import os
from time import sleep
import requests
import pandas as pd
各メンバーのCSVファイルを読み込んで、URLから画像を保存していきます。
members_name = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
for member_name in members_name:
# CSVの読み込み
df = pd.read_csv("{}_image_url.csv".format(member_name))
# 各メンバーのディレクトリがない場合は作成
IMAGE_DIR = "images/{}/".format(member_name)
if not os.path.exists(IMAGE_DIR):
os.mkdir(IMAGE_DIR)
# URLから画像をダウンロード
for i, url in enumerate(df.url):
try:
image = requests.get(url)
with open(IMAGE_DIR + "{}_{}".format(member_name, str(i).zfill(3)) + ".jpg", "wb") as f:
f.write(image.content)
except Exception as e:
print(member_name, i, "error!!")
2. 画像の選定
メンバー1人あたり300枚の画像を取得しました。
本来なら1人あたり数千枚ほどあるのが理想なのですが、Niziu自体デビューしてまだ間もなくあまり画像がないのでとりあえず300枚取得しました。
ただ、取得した画像を見てみると同じ画像が保存されていたり、メンバー名で取得したのにメンバー全員が映っている画像が取得されていたりしたので画像を以下の手順で選定しました。
- 複数人が写っている画像は顔を切り取って分ける
- 同じ画像は削除する
- 不要な画像や学習に使いづらい画像も削除する
結果1人あたり100枚程度しか集まりませんでした。
圧倒的に少ないのは承知の上ですが、とりあえずやっていくしかないですね。。
3. 画像から顔の部分を切り抜き
画像から顔の部分を切り抜くのはOpenCVを使用しました。
OpenCVの顔の切り抜き方は以下の記事を参考にしました。
顔をトリミングして保存
コードの全体像は以下です。
get_images_face.py
import os
import sys
import glob
import time
import cv2
import numpy as np
image_size = 150
members_name = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
HAAR_FILE = "/Users/moto/Desktop/Niziu_images/haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(HAAR_FILE)
for member_name in members_name:
# 入力する画像ファイルのディレクトリ
IMAGE_DIR = "images/{}/".format(member_name)
# 顔の切り抜きが成功した時に出力するディレクトリ
file_path_1 = "image_face/{}/".format(member_name)
# 顔の切り抜きが失敗した時に出力するディレクトリ
file_path_2 = "image_face_false/{}/".format(member_name)
# 画像の読み込み
file_list = glob.glob("{}*.jpg".format(IMAGE_DIR))
for i, filename in enumerate(file_list):
img = cv2.imread(filename)
img_gray = cv2.imread(filename, 0)
# 画像が読み込めない場合
if img is None:
print(filename)
print()
# 顔の切り抜きを実行し、画像ファイルを保存
try:
face = cascade.detectMultiScale(img_gray)
j = 0
for x, y, w, h in face:
face_cut = img[y:y+h, x:x+w]
face_cut = cv2.resize(face_cut, (image_size, image_size))
os.makedirs(file_path_1, exist_ok=True)
cv2.imwrite(file_path_1 + "{}_{}_{}.jpg".format(member_name, str(i).zfill(3), str(j).zfill(3)), face_cut)
j += 1
# 顔の切り抜きができなかった時はそのまま保存
except Exception:
os.makedirs(file_path_2, exist_ok=True)
cv2.imwrite(file_path_2 + "{}_{}.jpg".format(member_name, str(i).zfill(3)), filename)
ディレクトリ構造は以下です。
root/
├ get_images_face.py
├ images/
│ ├ mako/
│ ├ maya/
│ ├ ... /
│ └ rima/
│
├ image_face/
│ ├ mako/
│ ├ maya/
│ ├ ... /
│ └ rima/
│
└ image_face_false/
├ mako/
├ maya/
├ ... /
└ rima/
まずはライブラリをインポート
import os
import sys
import glob
import time
import cv2
import numpy as np
顔の部分を切り抜いて、150 × 150にリサイズして保存します。 カスケード分類器には"haarcascade_frontalface_default.xml"を使用していますが、正面を向いていないと顔をちゃんと切り抜けないことが多いので、
- 顔の切り抜きが成功した場合 → image_faceディレクトリに保存
- 顔の切り抜きが失敗した場合 → image_face_falseディレクトリにそのまま保存
として、切り抜きが失敗した場合は手動で顔の部分を切り抜いて行きました。
# 画像サイズ
image_size = 150
# カスケード分類器
HAAR_FILE = "/Users/moto/Desktop/Niziu_images/haarcascade_frontalface_default.xml"
cascade = cv2.CascadeClassifier(HAAR_FILE)
members_name = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
for member_name in members_name:
# 入力する画像ファイルのディレクトリ
IMAGE_DIR = "images/{}/".format(member_name)
# 顔の切り抜きが成功した時に出力するディレクトリ
file_path_1 = "image_face/{}/".format(member_name)
# 顔の切り抜きが失敗した時に出力するディレクトリ
file_path_2 = "image_face_false/{}/".format(member_name)
# 画像の読み込み
file_list = glob.glob("{}*.jpg".format(IMAGE_DIR))
for i, filename in enumerate(file_list):
img = cv2.imread(filename)
img_gray = cv2.imread(filename, 0)
# 画像が読み込めない場合
if img is None:
print(filename)
print()
# 顔の切り抜きを実行し、画像ファイルを保存
try:
face = cascade.detectMultiScale(img_gray)
j = 0
for x, y, w, h in face:
face_cut = img[y:y+h, x:x+w]
face_cut = cv2.resize(face_cut, (image_size, image_size))
os.makedirs(file_path_1, exist_ok=True)
cv2.imwrite(file_path_1 + "{}_{}_{}.jpg".format(member_name, str(i).zfill(3), str(j).zfill(3)), face_cut)
j += 1
# 顔の切り抜きができなかった時はそのまま保存
except Exception:
os.makedirs(file_path_2, exist_ok=True)
cv2.imwrite(file_path_2 + "{}_{}.jpg".format(member_name, str(i).zfill(3)), filename)
4. 画像を訓練データとテストデータに分割
ここからはGoogle Colaboratoryで作業するために、まずは取得したメンバーの顔画像をGoogleマイドライブにアップロードします。
全てGoogle Colaboratoryで作業したかったのですが、Javascriptで生成されているサイトからスクレイピングをする際に問題が発生するケースがあるみたいなのでローカルで作業していました。
※以下の記事を参考にすればGoogle Colaboratoryでも問題なくスクレイピングできるみたいなのでまた別の機会に試したいと思います。
参考:ColaboratoryでSeleniumが使えた:JavaScriptで生成されるページも簡単スクレイピング
ファイルをマイドライブにアップロード
マイドライブにNiziuappディレクトリを作成し、その中にfaceディレクトリを作成。
faceディレクトリの中にメンバー毎のディレクトリを作成してその中に画像を格納している状態にしました。
ディレクトリ構造をまとめると以下のようになります。
content/
└ MyDrive/
└ Niziuapp/
└ face/
├ mako/
│ ├ 〇〇.jpg
│ ├ ...
│ └ 〇〇.jpg
│
├ maya/
│ ├ 〇〇.jpg
│ ├ ...
│ └ 〇〇.jpg
│
├ ...
│
└ rima/
├ 〇〇.jpg
├ ...
└ 〇〇.jpg
訓練データとテストデータに分割
今回は各メンバー100枚中70枚を訓練データに、30枚をテストデータに分割します。
同じ階層にtest_imagesディレクトリを作成し、faceディレクトリの中の各メンバーのディレクトリから画像をランダムで30枚test_imagesディレクトリに保存していきます。
Google Colaboratoryからマイドライブの画像を扱うためにGoogleドライブをマウントする必要がありますが、それについては以下の記事がとてもわかりやすいのでご参照ください。
参考:ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話
まず、Google Coraboratoryを使う際は最初contentディレクトリにいるはずなので、
Niziuappディレクトリに移動します。
cd /content/drive/MyDrive/NiziuApp
その後、訓練データとテストデータを分割していきます。
import os, glob
import random
members = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
# 30枚をtest_imagesに移行
IMAGE_DIR = "face"
os.makedirs("./test_images", exist_ok=True)
for member in members:
files = glob.glob(os.path.join(IMAGE_DIR, member + "/*.jpg"))
random.shuffle(files)
os.makedirs('./test_images/' + member, exist_ok=True)
for i in range(30):
shutil.move(str(files[i]), "./test_images/" + member)
5. 訓練データの拡張
コードの全体像は以下です。
Data_Augmentation.ipynb
import os
import cv2
import numpy as np
def scratch_image(img, flip=True, blur=True, rotate=True):
methods = [flip, blur, rotate]
# filp は画像上下反転
# blur はぼかし
# rotate は画像回転
# 画像のサイズ(x, y)
size = np.array([img.shape[1], img.shape[0]])
# 画像の中心位置(x, y)
center = tuple([int(size[0]/2), int(size[1]/2)])
# 回転させる角度
angle = 30
# 拡大倍率
scale = 1.0
mat = cv2.getRotationMatrix2D(center, angle, scale)
# 画像処理をする手法をNumpy配列に格納
scratch = np.array([
lambda x: cv2.flip(x, 0), # flip
lambda x: cv2.GaussianBlur(x, (15, 15), 0), # blur
lambda x: cv2.warpAffine(x, mat, img.shape[::-1][1:3]) # rotate
])
# imagesにオリジナルの画像を配列として格納
images = [img]
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
def doubling_images(func, images):
return images + [func(i) for i in images]
for func in scratch[methods]:
images = doubling_images(func, images)
return images
# faceディレクトリにあるメンバーの画像を拡張する
IMAGE_DIR = "face"
members = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
for member in members:
files = glob.glob(os.path.join(IMAGE_DIR, member + "/*.jpg"))
for index, file in enumerate(files):
member_image = cv2.imread(file)
data_aug_list = scratch_image(member_image)
# 拡張した画像を出力するディレクトリを作成
os.makedirs("train_images/{}".format(member), exist_ok=True)
output_dir = "train_images/{}".format(member)
# 保存
for j, img in enumerate(data_aug_list):
cv2.imwrite("{}/{}_{}.jpg".format(output_dir, str(index).zfill(3), str(j).zfill(2)), img)
各メンバー訓練データが70枚しかないのでデータの水増しを行いました。
水増しの方法はopenCVを使って、
- 上下反転
- ぼかし
- 画像の回転(30°)
の処理を入れて、水増ししました。
まずはライブラリをインポート。
import os
import cv2
import numpy as np
1枚の画像から上記の水増しをして、拡張データを作成する関数を定義します。 70枚の画像から560枚まで拡張したのですが、 もっと水増ししてもよかったかなと反省しているのでまた色々試してみます。
def scratch_image(img, flip=True, blur=True, rotate=True):
methods = [flip, blur, rotate]
# filp は画像上下反転
# blur はぼかし
# rotate は画像回転
# 画像のサイズ(x, y)
size = np.array([img.shape[1], img.shape[0]])
# 画像の中心位置(x, y)
center = tuple([int(size[0]/2), int(size[1]/2)])
# 回転させる角度
angle = 30
# 拡大倍率
scale = 1.0
mat = cv2.getRotationMatrix2D(center, angle, scale)
# 画像処理をする手法をNumpy配列に格納
scratch = np.array([
lambda x: cv2.flip(x, 0), # flip
lambda x: cv2.GaussianBlur(x, (15, 15), 0), # blur
lambda x: cv2.warpAffine(x, mat, img.shape[::-1][1:3]) # rotate
])
# imagesにオリジナルの画像を配列として格納
images = [img]
# 関数と画像を引数に、加工した画像を元と合わせて水増しする関数
def doubling_images(func, images):
return images + [func(i) for i in images]
for func in scratch[methods]:
images = doubling_images(func, images)
return images
train_imagesディレクトリを作成し、faceディレクトリにある各メンバーの画像を取得して元データと拡張データをtrain_imagesディレクトリに保存していきます。
# faceディレクトリにあるメンバーの画像を拡張する
IMAGE_DIR = "face"
members = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
for member in members:
files = glob.glob(os.path.join(IMAGE_DIR, member + "/*.jpg"))
for index, file in enumerate(files):
member_image = cv2.imread(file)
data_aug_list = scratch_image(member_image)
# 拡張した画像を出力するディレクトリを作成
os.makedirs("train_images/{}".format(member), exist_ok=True)
output_dir = "train_images/{}".format(member)
# 保存
for j, img in enumerate(data_aug_list):
cv2.imwrite("{}/{}_{}.jpg".format(output_dir, str(index).zfill(3), str(j).zfill(2)), img)
データの拡張方法にはKerasのImageDataGeneratorを使用するとリアルタイムに拡張しながら、学習が行えるみたいなのでこっちの方が良さそうです。
ImageDataGeneratorも今後は使いこなしていけるように勉強します。
6. モデルの定義と学習
学習データとテストデータが揃ったので、機械学習モデルを定義して実際に学習させていきます。
今回はVGG16という、「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルを使って転移学習をします。
コードの全体像は以下です。
Niziu.ipynb
import os, glob
import random
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Input, Sequential, Model
from tensorflow.keras.models import load_model, save_model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.optimizers import SGD
members = ["mako", "maya", "mayuka", "riku", "miihi", "rio", "ayaka", "nina", "rima"]
num_classes = len(members)
image_size = 150
IMAGE_DIR_TRAIN = "train_images"
IMAGE_DIR_TEST = "test_images"
# 訓練データとテストデータをわける
X_train = []
X_test = []
y_train = []
y_test = []
# 訓練データをリストに代入
for index, member in enumerate(members):
files = glob.glob(os.path.join(IMAGE_DIR_TRAIN, member + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_train.append(image)
y_train.append(index)
# テストデータをリストに代入
for index, member in enumerate(members):
files = glob.glob(os.path.join(IMAGE_DIR_TEST, member + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_test.append(image)
y_test.append(index)
# テストデータと訓練データをシャッフル
p = list(zip(X_train, y_train))
random.shuffle(p)
X_train, y_train = zip(*p)
q = list(zip(X_test, y_test))
random.shuffle(q)
X_test, y_test = zip(*q)
# Numpy配列に変換
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
# データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0
# One-hot表現
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# VGG16のインスタンスの生成
input_tensor = Input(shape=(150, 150, 3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
# モデルの生成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(num_classes, activation="softmax"))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# model.summary()
# 15層目までのパラメータを固定
for layer in model.layers[:15]:
layer.trainable = False
# モデルのコンパイル
optimizer = SGD(lr=1e-4, momentum=0.9)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])
# モデルの学習
batch_size = 32
epochs = 100
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=3,
)
history = model.fit(X_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test),
callbacks=[early_stopping]
)
scores = model.evaluate(X_test, y_test, verbose=1)
# モデルの保存
model.save("./model.h5")
# 可視化
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(history.history["accuracy"], c="b", label="acc")
ax1.plot(history.history["val_accuracy"], c="r", label="val_acc")
ax1.set_xlabel("epochs")
ax1.set_ylabel("accuracy")
plt.legend(loc="best")
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(history.history["loss"], c="b", label="loss")
ax2.plot(history.history["val_loss"], c="r", label="val_loss")
ax2.set_xlabel("epochs")
ax2.set_ylabel("loss")
plt.legend(loc="best")
fig.show()
まずはライブラリをインポート。
import os, glob
import random
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras import Input, Sequential, Model
from tensorflow.keras.models import load_model, save_model
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator, img_to_array, load_img
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.optimizers import SGD, Adam
訓練データとテストデータを読み込み、データの正規化やラベルのOne-hot表現などをします。 データの正規化をすることで精度が上がりやすくなるみたいです。 One-hot表現は簡単にいうと正解ラベルを1、それ以外を0にすることです。 例えば、今回はmakoの正解ラベルが「0」なので、[1, 0, 0, 0, 0 ,0 ,0 ,0 ,0]みたいに変更してくれるものです。
IMAGE_DIR_TRAIN = "train_images"
IMAGE_DIR_TEST = "test_images"
# 訓練データとテストデータをわける
X_train = []
X_test = []
y_train = []
y_test = []
# 訓練データをリストに代入
for index, member in enumerate(members):
files = glob.glob(os.path.join(IMAGE_DIR_TRAIN, member + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_train.append(image)
y_train.append(index)
# テストデータをリストに代入
for index, member in enumerate(members):
files = glob.glob(os.path.join(IMAGE_DIR_TEST, member + "/*.jpg"))
for file in files:
image = load_img(file)
image = image.resize((image_size, image_size))
image = img_to_array(image)
X_test.append(image)
y_test.append(index)
# テストデータと訓練データをシャッフル
p = list(zip(X_train, y_train))
random.shuffle(p)
X_train, y_train = zip(*p)
q = list(zip(X_test, y_test))
random.shuffle(q)
X_test, y_test = zip(*q)
# Numpy配列に変換
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
# データの正規化
X_train = X_train / 255.0
X_test = X_test / 255.0
# One-hot表現
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
モデルの定義
# VGG16のインスタンスの生成
input_tensor = Input(shape=(150, 150, 3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
# モデルの生成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(128, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(num_classes, activation="softmax"))
# モデルの結合
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# model.summary()
# 15層目までのパラメータを固定
for layer in model.layers[:15]:
layer.trainable = False
# モデルのコンパイル
optimizer = SGD(lr=1e-4, momentum=0.9)
model.compile(optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"])
実際に作成されたモデルを確認するには
model.summary()
で確認できます。
実際に確認してみると以下のように表示されます。
model
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
_________________________________________________________________
sequential (Sequential) (None, 9) 2099721
=================================================================
Total params: 16,814,409
Trainable params: 16,814,409
Non-trainable params: 0
_________________________________________________________________
モデルの学習
# モデルの学習
batch_size = 32
epochs = 100
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=3,
)
history = model.fit(X_train,
y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_test, y_test),
callbacks=[early_stopping]
)
scores = model.evaluate(X_test, y_test, verbose=1)
# モデルの保存
model.save("./model.h5")
# 可視化
fig = plt.figure(figsize=(15,5))
plt.subplots_adjust(wspace=0.4, hspace=0.6)
ax1 = fig.add_subplot(1, 2, 1)
ax1.plot(history.history["accuracy"], c="b", label="acc")
ax1.plot(history.history["val_accuracy"], c="r", label="val_acc")
ax1.set_xlabel("epochs")
ax1.set_ylabel("accuracy")
plt.legend(loc="best")
ax2 = fig.add_subplot(1, 2, 2)
ax2.plot(history.history["loss"], c="b", label="loss")
ax2.plot(history.history["val_loss"], c="r", label="val_loss")
ax2.set_xlabel("epochs")
ax2.set_ylabel("loss")
plt.legend(loc="best")
fig.show()
実際の結果がこちら。
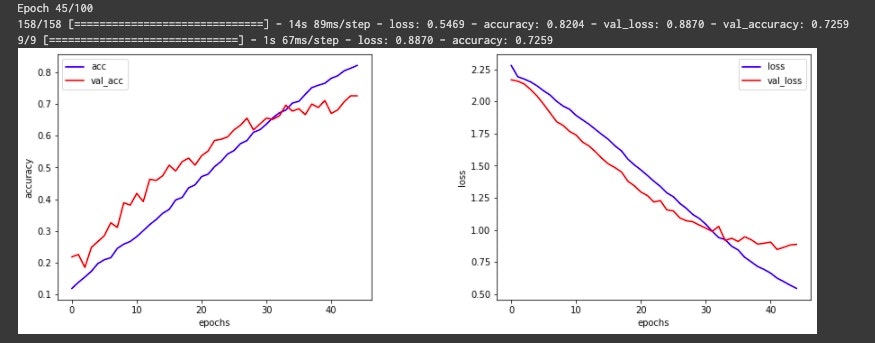
精度は72.59%と少し低めの結果となりました。
Earlystoppingで過学習を防いでいるため、Epoch数が思いのほか伸びないのが原因かと考えEarlystoppingを適用しないでやってみると、学習データは99%程度まで伸びるもののテストデータの関しては70% ~ 75%を行き来するだけでそこまで大差は見られませんでした。
なのでEarlystoppingを適用しておいた方が良さそうですね。
7. 画像の推定
精度は低めですが、とりあえずメンバーを推定させてみます。
今回は以下の画像から顔を切り抜いて推定させていきます。

file_path = "test.jpg"
img = cv2.imread(file_path)
img_gray = cv2.imread(file_path, 0)
face = cascade.detectMultiScale(
img_gray,
scaleFactor=1.11,
minNeighbors=2,
minSize=(130, 130)
)
face_cut_list = []
answer_list = []
for i, (x, y, w, h) in enumerate(face):
# 顔写真をリサイズ
face_cut = img[y:y+h, x:x+w]
face_cut = cv2.resize(face_cut, (image_size, image_size)) # 150 * 150
# 顔写真を配列に変換する
face_cut = cv2.cvtColor(face_cut, cv2.COLOR_BGR2RGB) # BGR→RGB画像に変換
data = image.img_to_array(face_cut) # 3次元配列(150, 150, 3)
data = np.array([data]) # 4次元配列(1, 150, 150, 3)
# 変換した画像を予測
result = model.predict(data)[0]
answer = members[np.argmax(result)]
face_cut_list.append(face_cut)
answer_list.append(answer)
# 可視化
fig = plt.figure(figsize=(16, 12))
for i in range(9):
ax = fig.add_subplot(3, 3, i+1)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(face_cut_list[i])
ax.set_xlabel(answer_list[i])
結果はこんな感じ。

9人中6人当たっているのでまずまずといったところではないでしょうか。
他の画像でも試してみます。
次はこちら。

結果はこんな感じ。

アヤカ以外全員ハズレという大惨事。。。
てかとりあえずアヤカと言っておけばいいくらいの感覚でアヤカと推定されていますね。
8. まとめ
学習データが圧倒的に少ないのと9クラス分類だったのでかなり難しかったのではないかなと思いました。
今回はOpenCVを使って顔の切り抜きを行っていきましたが、MicrosoftのFace APIを使えばもう少し正確に顔の切り抜きが行えるみたいです。(記事を作成している時に知りました。)
Face APIを使えばもう少し効率メンバーの顔写真を取得できると思いますので、
ここも要勉強ですね。
再度挑戦し直して、良いスコアが出たらまた記事にまとめていきたいと思います。
おわり