概要
前回書いた記事の続きです。
KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜
前回は、KerasのCNNを利用して、女優4人の分類に挑戦しました。
1から画像を識別する分類機を作成する場合、大量の画像データが必要ですが、1人400枚(水増しして1人1500~1800枚)で学習しても、精度が約80%くらいしか出せませんでした。
そこで、すでに訓練した学習済みモデルを利用するファインチューニングという手法で再挑戦します。
また、学習時間短縮のために,Google Colaboratoryを利用して、無料でGPUを使いながらファインチューニングします。
こんなことやりたい
石原さとみの可能性:99.9%!!!

用語解説
- Fine Tuning :学習済みモデルの一部を再利用して、新しいモデルを構築する手法
- VGG16 :ImageNetの一般物体認識データセットで学習済みのモデル。1000種類の画像を分類できるモデル。
- Keras :機械学習を簡単に使うためのライブラリ
- CNN :Convolutional Neural Network(畳み込みニューラルネットワーク)
- Google Colaboratory:ブラウザ上でPythonを実行できる環境を提供しているツール。Googleが機械学習の教育や研究用に提供している。
全体の流れ
【ステップ1】
画像データの準備
【ステップ2】
Google Colaboratoryの準備
【ステップ3】
モデルの構築
【ステップ4】
モデルの学習・評価
【ステップ1】 画像データの準備
スクレイピングでGoogle画像検索から画像を取得し、顔を検出して切り抜く。
また、画像の水増し処理については、前回の記事を参考にしてください。
KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜
【ステップ2】 Google Colaboratoryの準備
無料でGPUを使うために、Google Colaboratoryを利用します。
Google Colaboratoryを使ったことがない方は、下記の記事が参考になりました。
Google Colabの知っておくべき使い方 – Google Colaboratoryのメリット・デメリットや基本操作のまとめ
GPUを設定
画面上部のメニュー
編集 > ノートブックの設定>ハードウェア アクセラレータ>GPUに変更して保存する。
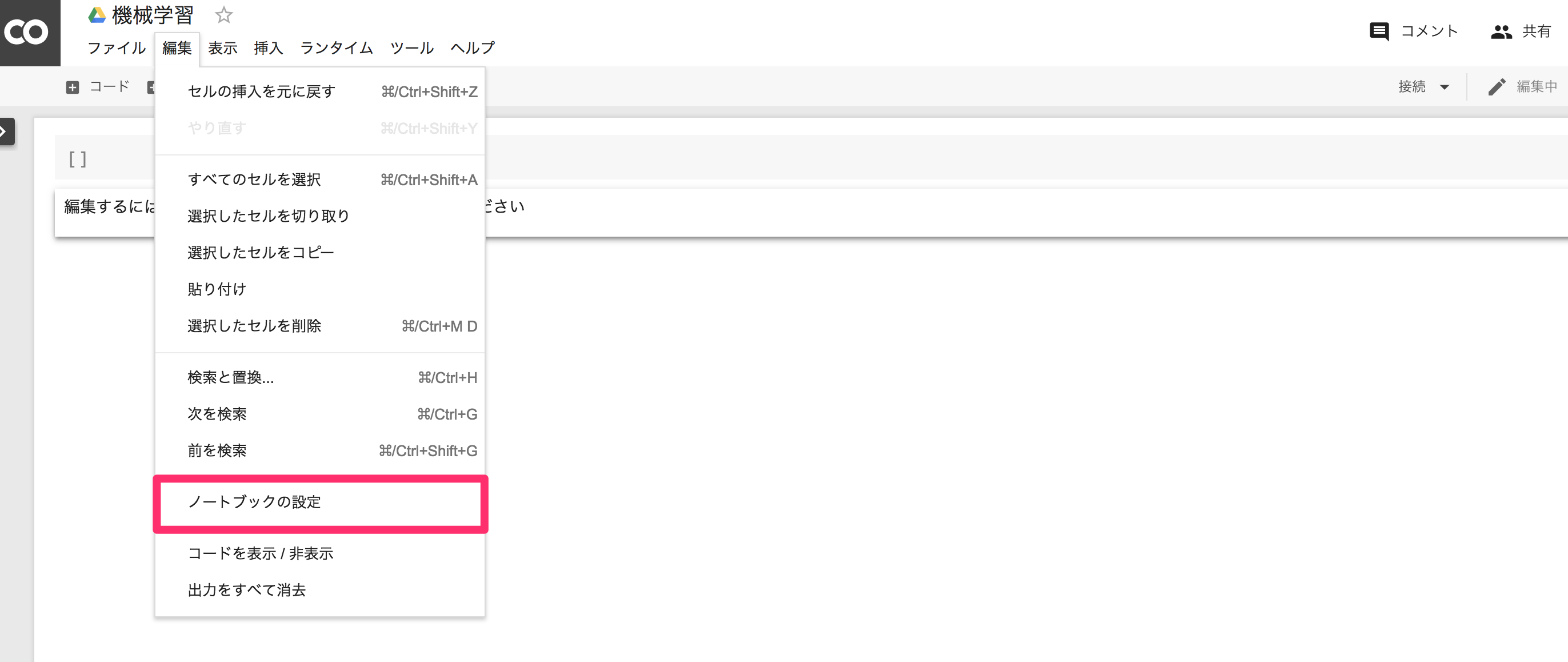

GPUの割り当てを確認
セルに下記を入力して、実行
実行はShift+Enter
import tensorflow as tf
tf.test.gpu_device_name()
下記のように出力されていれば、GPUが割り当てられています。
'/device:GPU:0'
Google Driveに画像データをあげる
colaboratoryを利用して、学習を行うには、Google driveに画像データをアップする必要があります。
そして、Google Driveへのマウントをすることで、colaboratoryからGoogle driveにあるデータを参照できるようになります。
前回の記事で書いた方法で水増しした画像を、Google driveにアップロードしてください。
※私の場合
FaceEdited トレーニングデータ用のディレクトリ(1人1500~1800枚)
test バリデーション用データ用のディレクトリ(1人約400枚)

ディレクトリ構造を下記に示します。
content
├ gdrive
└ My Drive
└ Colab Notebooks
├ FaceEdited
│ └ 広瀬すず
│ └ 新垣結衣
│ └ 石原さとみ
│ └ 武井咲
├ test
│ └ 広瀬すず
│ └ 新垣結衣
│ └ 石原さとみ
│ └ 武井咲
自分のディレクトリの確認をしたいときは、Linuxの基本コマンドを使ってください。
あとでトレーニングデータとテストデータのパスを取得する時に必要になります。
現在のディレクトリ(カレントディレクトリ)を確認
!pwd
ディレクトリの内容を表示
!ls
ディレクトリを移動
%cd
Google Driveをマウント
以下のコードで、content/gdrive/My Drive/のなかにgoogle driveのデータが入ります
content
├ gdrive
└ My Drive
from google.colab import drive
drive.mount('/content/gdrive')
実行すると、URLと認証コードの入力フォームが表示されます。
URLをクリックして、googleアカウントの認証コードを取得してください。
認証コードをコピーして、入力フォームに貼り付けると、content/gdrive/My Drive/のなかにgoogle driveのデータが入ります。
【ステップ3】モデルの構築
ライブラリの読み込み
import os
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
import numpy as np
import time
事前に設定するパラメータ
# 分類するクラス
classes = ["広瀬すず","新垣結衣","石原さとみ","武井咲"]
nb_classes = len(classes)
# 画像の大きさを設定
img_width, img_height = 150, 150
# トレーニング用とバリデーション用の画像格納先(パスは自分で設定してください)
train_data_dir = '/content/gdrive/My Drive/Colab Notebooks/FaceEdited'
validation_data_dir = '/content/gdrive/My Drive/Colab Notebooks/test'
# トレーニングデータ用の画像数
nb_train_samples = 7000
# バリデーション用の画像数
nb_validation_samples = 1000
# バッチサイズ
batch_size = 100
# エポック数
nb_epoch = 20
バッチサイズ
ディープラーニングは、データセットを幾つかのサブセットに分けて学習します。その際の、サブセットに含まれるデータの数のことです。
エポック数
1.データセットをバッチサイズに従ってN個のサブセットに分けます。
2.各サブセットを学習します。つまり、N回学習します。
1と2の手順を1回実行することを1エポックと呼びます。
トレーニングデータ用の画像数 7000
バッチサイズ 100
のとき、サブセットが7000÷100=70個できます。
エポック数 20
のとき、1と2の手順を20回実行します。
トレーンング用、バリデーション用データを生成するジェネレータ作成
画像に対して移動、回転、拡大・縮小などの操作を加えることでデータ数を水増しします。
ImageDataGenerator:画像の水増しを簡単に行えるクラス。オプションで、水増し方法を決めます。
zoom_range:画像をランダムにズームします
horizontal_flip:画像を水平方向にランダムに反転します
既に画像の水増し済みの方は、zoom_rangeとhorizontal_flipを使う必要はありません。
参考にさせていただいたサイトを載せておきます。
Kerasによるデータ拡張
# トレーンング用、バリデーション用データを生成するジェネレータ作成
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
#すでに画像の水増し済みの方は、下記2行は必要ありません。
#zoom_range=0.2,
#horizontal_flip=True
)
validation_datagen = ImageDataGenerator(rescale=1.0 / 255)
flow_from_directory :元画像が含まれるディレクトリ名を指定する
target_size:画像のサイズをリサイズする
class_mode:2クラス分類ならbinary、多クラス分類ならcategoricalを指定する
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
上記のコードを実行すると、トレーニングデータとバリデーションデータの総数が表示されます。

【ステップ3】 モデルの構築
VGG16とは
VGG16は、畳み込み13層とフル結合3層の計16層から成る畳み込みニューラルネットワークです。ImageNetと呼ばれる大規模な画像データセットを使って訓練したモデルで、1000種類の画像を分類することができます。
Kerasでは、ImageNetで事前学習した重みを利用可能なVGG16モデルを、下記のコードで簡単に使うことができます。
keras.applications.vgg16.VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000)
他にも様々なモデルが利用可能です。

詳しくはリンクを参照してください。
Keras Documentation
VGG16をFine-tuning
Fine-tuningは、学習済モデルを、重みデータを一部再学習して特徴量抽出機として利用します
転移学習は、学習済みモデルを、重みデータは変更せずに特徴量抽出機として利用します
Fine-tuningのメリットは、ニューラルネットの重みを少量のデータで再調整することができて、かつ、高い精度を出せることです。
今回は下の画像の
青い層:重みデータは変更しない(frozen)
黄色い層:重みデータを再学習(Fine-tuning)
緑の層:フル結合層(Fine-tuning)
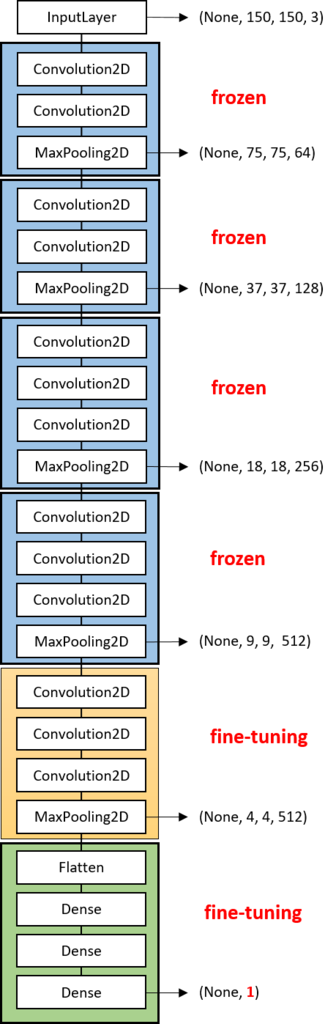
kerasでモデルを構築
# VGG16のロード。FC層は不要なので include_top=False
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# VGG16の図の緑色の部分(FC層)の作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
# VGG16とFC層を結合してモデルを作成(完成図が上の図)
vgg_model = Model(input=vgg16.input, output=top_model(vgg16.output))
# VGG16の図の青色の部分は重みを固定(frozen)
for layer in vgg_model.layers[:15]:
layer.trainable = False
# 多クラス分類を指定
vgg_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),
metrics=['accuracy'])
【ステップ4】 モデルの学習・評価
モデルの学習
# Fine-tuning
history = vgg_model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)

GPUを使って約3時間ほど学習に時間がかかりました。
なぜか毎回、1Epoch目の学習時間が遅いのですが、原因は不明です。。。
モデルの評価
学習が終わったら、下記のコードで結果を描写します。
# 学習結果を描写
import matplotlib.pyplot as plt
# acc, val_accのプロット
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
# Final.pngという名前で、結果を保存
plt.savefig('Final.png')
plt.show()

20epoch学習しました。5epochあたりから90%を超えています。最終的に98,99%あたりで落ち着きました。
前回の記事で、CNNを1から学習させたときは、80%止まりだったので、大幅に精度が上がりました!

KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜
女優の分類
ローカルにモデルを保存してから実行しました。詳しくは下記を参照してください。
Google Colaboratoryで学習したモデルをローカルに保存・モデルに読み込み・実行する
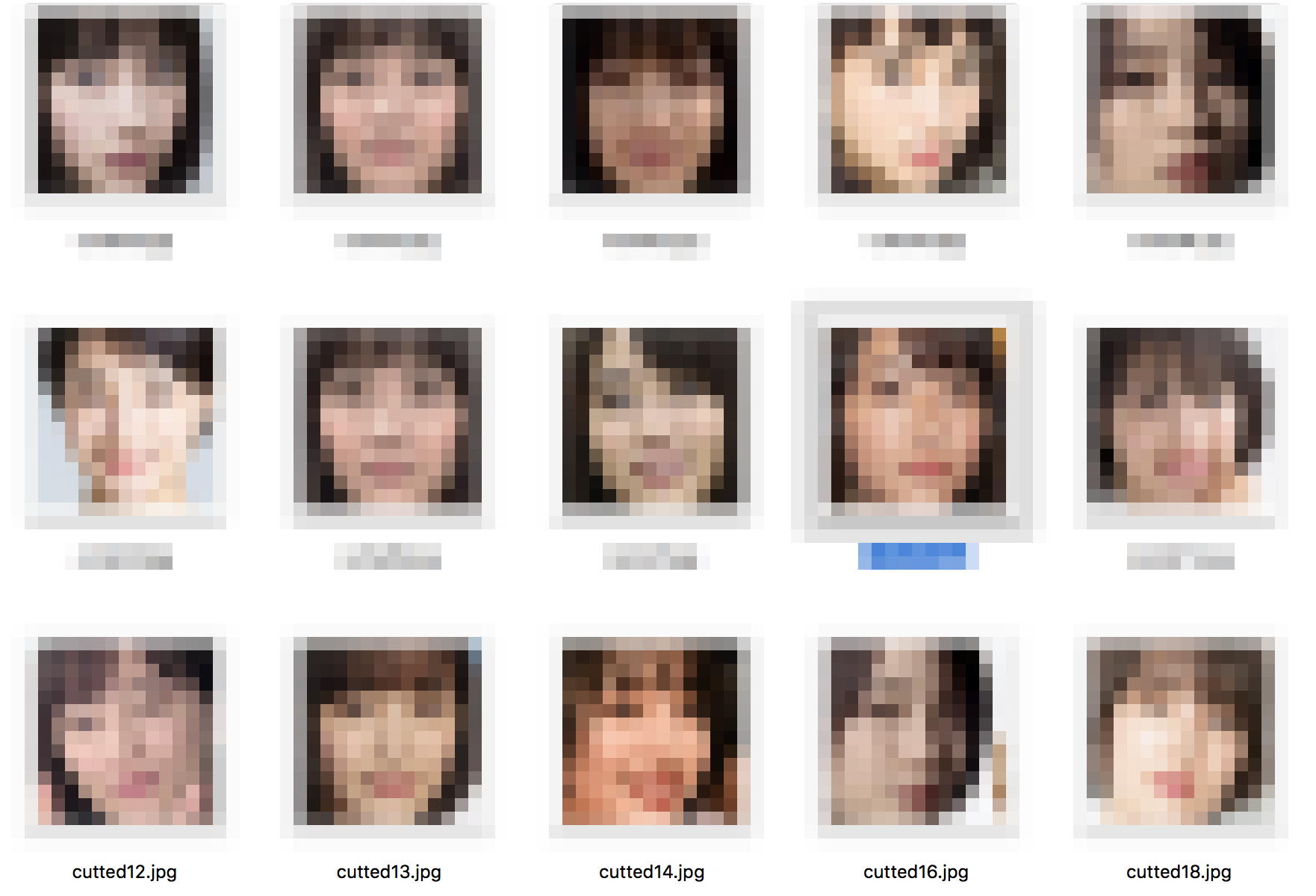
写真の下にある数字は、精度(%)を表しています。例えば下の写真なら、
[広瀬すず:99.3%, 新垣結衣:0.002%, 石原さとみ:0.07%, 武井咲:0.59%]
という意味です。



うまくいっていないケースもありました。

前回やった、CNNと比べて大幅な精度向上に成功しました。
Kerasにはファインチューニングで利用できるモデルが複数あったので、それらを利用して、顔分類だけでなく、違うことにも挑戦してみたいです。
ゼロから作るDeep Learningを読んだのがきっかけでしたが、楽しく遊べてとても良かったです。
リンク
書いた記事
KerasのCNNで、顔認識AIを作って見た〜スクレイピングからモデルまで〜
Google Colaboratoryで学習したモデルをローカルに保存・モデルに読み込み・実行する
参考文献
Keras(Tensorflow)の学習済みモデルのFine-tuningで少ない画像からごちうさのキャラクターを分類する分類モデルを作成する
VGG16のFine-tuningによる犬猫認識 (1)
VGG16のFine-tuningによる犬猫認識 (2)
VGG16のFine-tuningによる17種類の花の分類
Keras Documentation
Kerasによるデータ拡張