はじめに
前回の記事で、Google Colaboratoryを利用して、VGG16をFine Tuningして、4人の顔を分類するモデルを構築しました。そのモデルの重みを保存して、ローカルに落として実際に使うのに、色々手間取ったのでここにまとめます。
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た
使用したモデル
今回使用したモデルは、畳み込み13層とフル結合3層の計16層から成る畳み込みニューラルネットワークです。
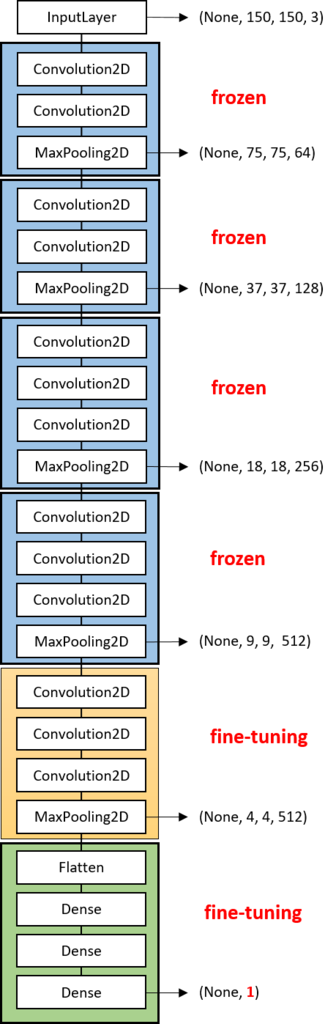
モデルの重みをColaboratoryに保存
Google ColaboratoryでGPUを借りて学習した結果をLocalに保存します。
resultsというディレクトリを作成し、そこに今回Fine-turningしたモデルの重みを保存します。
model.save_weights(filepath) :モデルの重みをHDF5形式のファイルに保存します
import os
# resultsディレクトリを作成
result_dir = 'results'
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 重みを保存
vgg_model.save_weights(os.path.join(result_dir, 'Final.h5'))
# 作成したモデルを保存
# vgg_model.save('VGGtake1.h5')
ローカルにモデルの重みをダウンロード
files.download(filepath) : localに()で示したパスのデータをダウンロードできます。
# result_dirをローカルに保存
from google.colab import files
files.download( "/content/results/Final.h5" )
ローカルで重みデータを読み込む
model.load_weights(filepath, by_name=False) : (save_weightsによって作られた) モデルの重みをHDF5形式のファイルから読み込みます。
デフォルトでは,アーキテクチャは不変であることが望まれます.
つまり、重みを保存したモデルと同じ構造のモデルを定義してから、読み込ませる必要があります。
(いくつかのレイヤーが共通した)異なるアーキテクチャに重みを読み込む場合,by_name=Trueを使うことで,同名のレイヤーにのみ読み込み可能です.
重みを保存したモデルと同じ構造のモデルを定義
詳しくは前回の記事をみてください。
# ライブラリの読み込み
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential, Model
from keras.layers import Input, Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers
# 事前に設定するパラメータ
classes = ["広瀬すず","新垣結衣","石原さとみ","武井咲"]
nb_classes = len(classes)
img_width, img_height = 150, 150
# VGG16のロード。FC層は不要なので include_top=False
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# FC層の作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
# VGG16とFC層を結合してモデルを作成
vgg_model = Model(input=vgg16.input, output=top_model(vgg16.output))
定義したモデルに重みを読み込ませる
from keras.models import load_model
vgg_model.load_weights('./results/Final.h5')
ローカルでモデルを実行する
下記はテスト用コードです。
img_predict(filename) : 引数(filename)にテスト用の画像データのpathを入力
画像を表示し、また、広瀬すず、新垣結衣、石原さとみ、武井咲である可能性を表示する。
# テスト用のコード
from keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
# 画像を読み込んで予測する
def img_predict(filename):
# 画像を読み込んで4次元テンソルへ変換
img = image.load_img(filename, target_size=(img_height, img_width))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
# 学習時にImageDataGeneratorのrescaleで正規化したので同じ処理が必要
# これを忘れると結果がおかしくなるので注意
x = x / 255.0
#表示
plt.imshow(img)
plt.show()
# 指数表記を禁止にする
np.set_printoptions(suppress=True)
#画像の人物を予測
pred = vgg_model.predict(x)[0]
#結果を表示する
print(" 広瀬すず': 0, '新垣結衣': 1, '石原さとみ': 2, '武井咲': 3")
print(pred*100)
テスト用の画像データ読み込み
test_sample_original :テスト用の画像が入っているディレクトリ
import glob
# テスト用の画像が入っているディレクトリのpathを()に入れてください
test = glob.glob('./test_sample_original/*')
実行
# 数字は各自入力
img_predict(test[0])
実行結果




最後に
Google colaboratoryでGPUを借りて学習させた重みデータをローカルに保存して使う方法でした。
あとは、colaboratoryで大きい容量のデータを学習させるとき、どうすれば一番早くて楽か知りたい。。。