はじめに
就職活動が終わり、Pythonを始めてから半年が経ちました。
いつもQiitaの記事に助けられていて、いつか記事を書きたいなーと考えていました。
最近、Pythonの機械学習をざっくり勉強して、今は深層学習を勉強してます。
ゼロから作るDeep Learning――Pythonで学ぶディープラーニングの理論と実装
これを読んだら、画像系で何かできそうと思い、Qiitaでいろんな記事を見てたら、Aidemyさんの記事を発見!
機械学習で乃木坂46を顏分類してみた
スクレイピングで画像を取得し、分類する深層学習
概要

【ステップ1】
顔認識したい人の名前を複数定義する
【ステップ2】
スクレイピングでGoogle画像検索から画像を取得
【ステップ3】
顔部分を抽出し切り抜く
【ステップ4】
不要な画像を削除(自力で)
【ステップ5】
画像処理をして、画像の水増し
【ステップ6】
トレーニングデータ、テストデータの準備
【ステップ7】
Kerasでモデルの構築、学習、評価
【+α】
Google Colaboratory → GPUを無料で利用して学習時間を短縮する
参考にさせていただいた記事
API を叩かずに Google から画像収集をする
機械学習で乃木坂46を顏分類してみた
乃木坂メンバーの顔をCNNで分類
【ステップ1】 顔認識したい人の名前を複数定義する
SearchNameの名前1〜4に、顔認識をしたい人の名前を入れてください。
好きな女優4人でやりました。
名前1〜4が、スクレイピングをするときに、Google画像検索の検索ワードとなります。
# 顔認識する対象を決定(検索ワードを入力)
SearchName = ["名前1","名前2","名前3","名前4"]
# 画像の取得枚数の上限
ImgNumber =600
# CNNで学習するときの画像のサイズを設定(サイズが大きいと学習に時間がかかる)
ImgSize=(250,250)
input_shape=(250,250,3)
次に、取得した画像を保存しておくようのフォルダをあらかじめ作っておきます。
import os
# オリジナル画像用のフォルダ
os.makedirs("./Original", exist_ok=True)
# 顔の画像用のフォルダ
os.makedirs("./Face", exist_ok=True)
# ImgSizeで設定したサイズに編集された顔画像用のフォルダ
os.makedirs("./FaceEdited", exist_ok=True)
# テストデータを入れる用のフォルダ
os.makedirs("./test", exist_ok=True)
【ステップ2】 スクレイピングでGoogle画像検索から画像を取得
画像収集するのに、GoogleやYahoo,BingのAPIを利用する手段もありますが、枚数制限などがあるようです。
API を叩かずに Google から画像収集をする
この記事を参考にさせていただきながら、Google画像検索でスクレイピングをすることにしました。
検索ワードにもよりますが、400~600枚ほどの画像を取得できます。もっと多くの画像を取得できる方法がわかる方がいたら御教示お願い致します。
Googleというclassを定義します。
import json
from urllib import parse
import requests
from bs4 import BeautifulSoup
class Google:
def __init__(self):
self.GOOGLE_SEARCH_URL = 'https://www.google.co.jp/search'
self.session = requests.session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64; rv:57.0) Gecko/20100101 Firefox/57.0'})
def Search(self, keyword, type='text', maximum=1000):
'''Google検索'''
print('Google', type.capitalize(), 'Search :', keyword)
result, total = [], 0
query = self.query_gen(keyword, type)
while True:
# 検索
html = self.session.get(next(query)).text
links = self.get_links(html, type)
# 検索結果の追加
if not len(links):
print('-> No more links')
break
elif len(links) > maximum - total:
result += links[:maximum - total]
break
else:
result += links
total += len(links)
print('-> 結果', str(len(result)), 'のlinksを取得しました')
return result
def query_gen(self, keyword, type):
'''検索クエリジェネレータ'''
page = 0
while True:
if type == 'text':
params = parse.urlencode({
'q': keyword,
'num': '100',
'filter': '0',
'start': str(page * 100)})
elif type == 'image':
params = parse.urlencode({
'q': keyword,
'tbm': 'isch',
'filter': '0',
'ijn': str(page)})
yield self.GOOGLE_SEARCH_URL + '?' + params
page += 1
def get_links(self, html, type):
'''リンク取得'''
soup = BeautifulSoup(html, 'lxml')
if type == 'text':
elements = soup.select('.rc > .r > a')
links = [e['href'] for e in elements]
elif type == 'image':
elements = soup.select('.rg_meta.notranslate')
jsons = [json.loads(e.get_text()) for e in elements]
links = [js['ou'] for js in jsons]
return links
インスタンスを作成し、画像のURLをgoogle検索から取得する。
そのままOriginalファイルに画像を保存します。
# 画像のURLをgoogle検索から取得する
# インスタンス作成
google = Google()
for name in SearchName:
# 画像検索
ImgURLs = google.Search(name, type='image', maximum=ImgNumber)
# 保存先のディレクトリ作成
os.makedirs("./Original/"+str(name), exist_ok=True)
#Originalファイルに画像を保存する
for i,target in enumerate(ImgURLs): # ImgURLsからtargetに入れる
try:
re = requests.get(target, allow_redirects=False)
with open("./Original/"+str(name)+'/' + str(i)+'.jpg', 'wb') as f: # imgフォルダに格納
f.write(re.content) # .contentにて画像データとして書き込む
except requests.exceptions.ConnectionError:
continue
except UnicodeEncodeError:
continue
except UnicodeError:
continue
except IsADirectoryError:
continue
print("保存完了しました") # 確認
Originalフォルダに写真が保存されているか確認します。
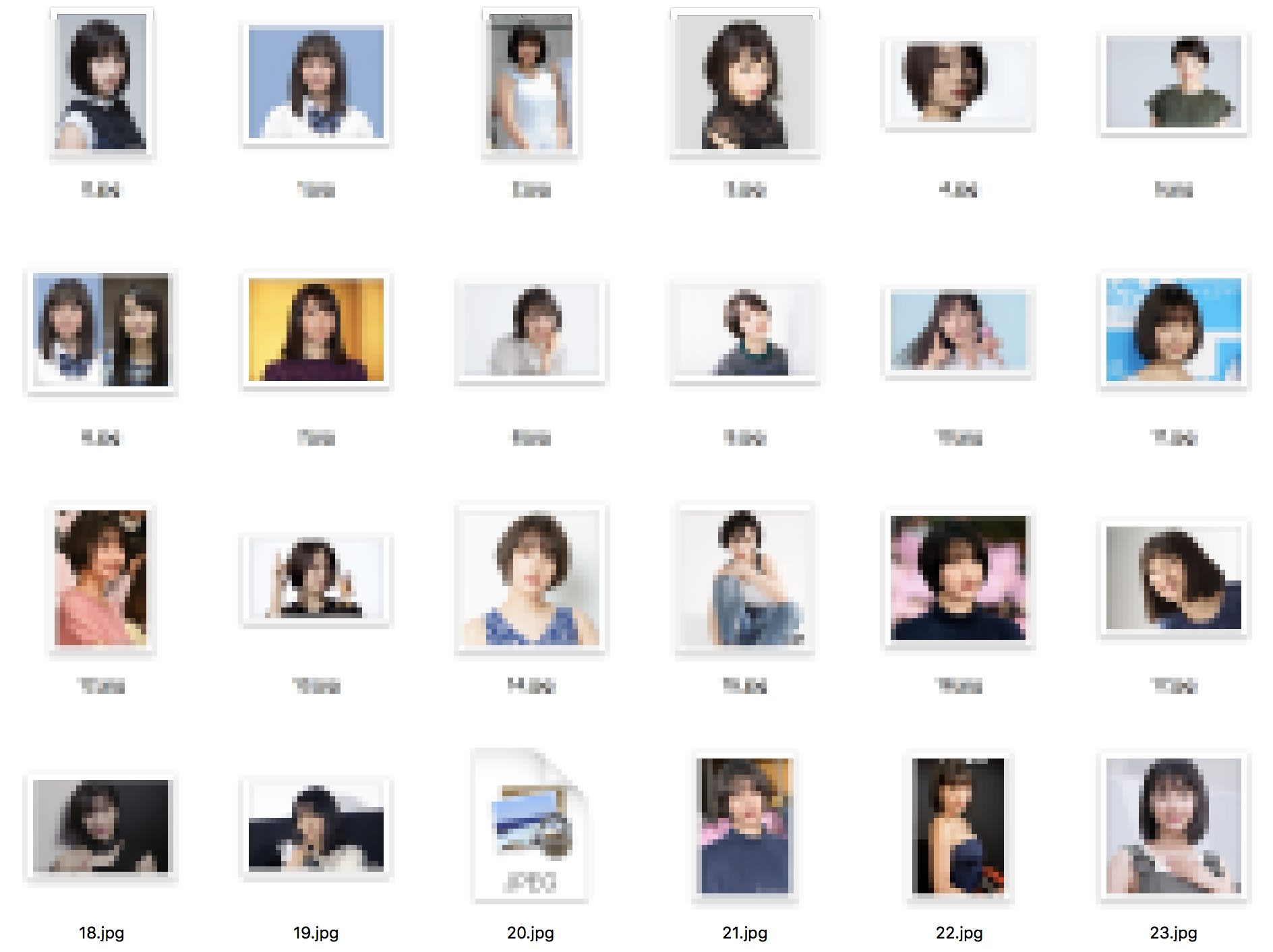
【ステップ3】 顔部分を抽出し切り抜く
顔部分を抽出するのに、OpneCVを利用します。
下記のgithubから、OpneCVをダウンロードしてください。
OpenCV
 ご自身でパスを入力してください。
cascade_path = '自分のパスを入力'
ご自身でパスを入力してください。
cascade_path = '自分のパスを入力'
# -*- coding:utf-8 -*-
import cv2
import numpy as np
# OpenCVのデフォルトの分類器のpath。(https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xmlのファイルを使う)
cascade_path = ' 自分のhaarcascade_frontalface_default.xmlのパスを入力'
# 例
# cascade_path = './opencv-master/data/haarcascades/haarcascade_frontalface_default.xml'
faceCascade = cv2.CascadeClassifier(cascade_path)
Originalフォルダにある画像から、OpenCVを利用して、顔を検出する。
検出した顔を切り取り、Faceフォルダに保存します。
for name in SearchName:
# 画像データのあるディレクトリ
input_data_path = "./Original/"+str(name)
# 切り抜いた画像の保存先ディレクトリを作成
os.makedirs("./Face/"+str(name)+"_face", exist_ok=True)
save_path = "./Face/"+str(name)+"_face/"
# 収集した画像の枚数(任意で変更)
image_count = ImgNumber
# 顔検知に成功した数(デフォルトで0を指定)
face_detect_count = 0
print("{}の顔を検出し切り取りを開始します。".format(name))
# 集めた画像データから顔が検知されたら、切り取り、保存する。
for i in range(image_count):
img = cv2.imread(input_data_path + '/'+ str(i) + '.jpg', cv2.IMREAD_COLOR)
if img is None:
print('image' + str(i) + ':NoFace')
else:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
face = faceCascade.detectMultiScale(gray, 1.1, 3)
if len(face) > 0:
for rect in face:
# 顔認識部分を赤線で囲み保存(今はこの部分は必要ない)
# cv2.rectangle(img, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (0, 0,255), thickness=1)
# cv2.imwrite('detected.jpg', img)
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.imwrite(save_path + 'cutted' + str(face_detect_count) + '.jpg',img[y:y+h, x:x+w])
face_detect_count = face_detect_count + 1
else:
print('image' + str(i) + ':NoFace')
print("顔画像の切り取り作業、正常に動作しました。")
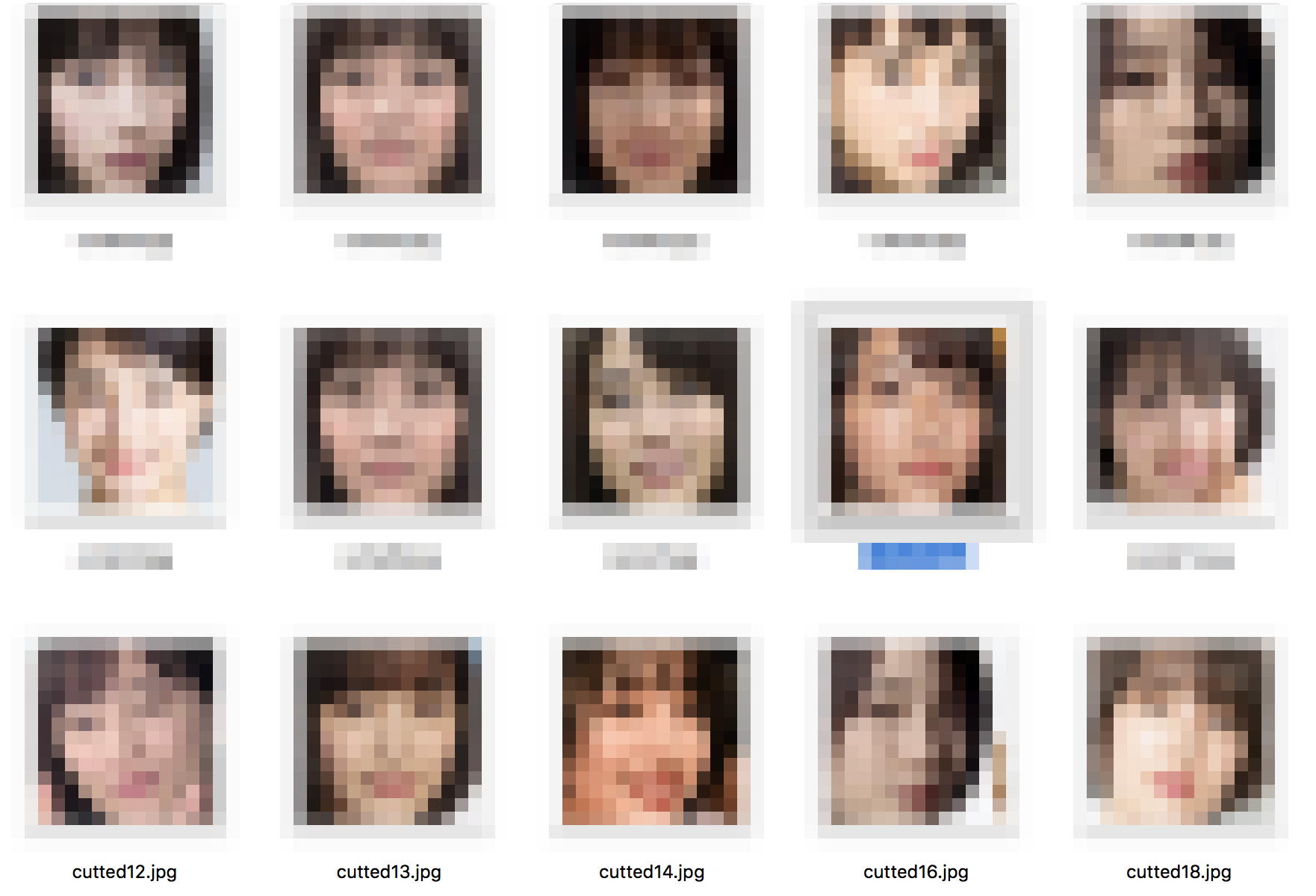
【ステップ4】 不要な画像を削除(自力で)
Faceフォルダにある画像を確認します。
Google画像検索の上から画像を取得しているので、関係のない写真や、関係ない人の顔画像があります。
また、顔でない部分の写真もあるので、全て削除します。(正直ここが一番めんどくさい)
【ステップ5】 画像処理をして、画像の水増し
ここまでで、Originalフォルダに写真を保存して、Faceフォルダに顔写真を保存できました。
また、不要な写真も除去できました。
ここから、画像を閾値処理、ぼかし処理、回転処理をして水増しを行います。
import os
import cv2
import glob
from scipy import ndimage
"""
Faceディレクトリから画像を読み込んで回転、ぼかし、閾値処理をしてFaceEditedディレクトリに保存する.
"""
for name in SearchName:
print("{}の写真を増やします。".format(name))
in_dir = "./Face/"+name+"_face/*"
out_dir = "./FaceEdited/"+name
os.makedirs(out_dir, exist_ok=True)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./Face/"+name+"_face/")
for i in range(len(in_jpg)):
#print(str(in_jpg[i]))
img = cv2.imread(str(in_jpg[i]))
# 回転
for ang in [-10,0,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,ImgSize)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
# 閾値
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
# ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
print("画像の水増しに大成功しました!")
【ステップ6】 トレーニングデータ、テストデータの準備
FaceEditedフォルダにある画像の2割をテストフォルダに移行します。
# 2割をテストデータに移行
import shutil
import random
import glob
import os
for name in SearchName:
in_dir = "./FaceEdited/"+name+"/*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./FaceEdited/"+name+"/")
#img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_jpg)
os.makedirs('./test/' + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "./test/"+name)
教師データとテストデータのラベル付け
from keras.utils.np_utils import to_categorical
# 教師データのラベル付け
X_train = []
Y_train = []
for i in range(len(SearchName)):
img_file_name_list=os.listdir("./FaceEdited/"+SearchName[i])
print("{}:トレーニング用の写真の数は{}枚です。".format(SearchName[i],len(img_file_name_list)))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./FaceEdited/"+SearchName[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
if img is None:
print('image' + str(j) + ':NoImage')
continue
else:
r,g,b = cv2.split(img)
img = cv2.merge([r,g,b])
X_train.append(img)
Y_train.append(i)
print("")
# テストデータのラベル付け
X_test = [] # 画像データ読み込み
Y_test = [] # ラベル(名前)
for i in range(len(SearchName)):
img_file_name_list=os.listdir("./test/"+SearchName[i])
print("{}:テスト用の写真の数は{}枚です。".format(SearchName[i],len(img_file_name_list)))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./test/"+SearchName[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
if img is None:
print('image' + str(j) + ':NoImage')
continue
else:
r,g,b = cv2.split(img)
img = cv2.merge([r,g,b])
X_test.append(img)
Y_test.append(i)
X_train=np.array(X_train)
X_test=np.array(X_test)
y_train = to_categorical(Y_train)
y_test = to_categorical(Y_test)
【ステップ7】Kerasでモデルの構築、学習、評価
モデルの定義
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
from keras.models import Sequential
# モデルの定義
model = Sequential()
model.add(Conv2D(input_shape=input_shape, filters=32,kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
# 分類したい人数を入れる
model.add(Dense(len(SearchName)))
model.add(Activation('softmax'))
# コンパイル
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
学習
# 学習
history = model.fit(X_train, y_train, batch_size=70,
epochs=50, verbose=1, validation_data=(X_test, y_test))
教師データは250×250の画像サイズで、50epochsで学習を行なっています。
ローカルのCPUで行なっていて、1epochあたり約10分かかっています。
単純計算で、500分も時間がかかるのは課題ですね。。。GPU使いたい。。。

汎化性能の評価・表示
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# モデルを保存
model.save("MyModel.h5")
結果です。

最初50%未満の精度が順調に上がっていっています。
40epoch付近で、最大81%の精度になっています。
45epochあたりから精度が下がっている理由はわからないです。(過学習??)
【+α】 Google Colaboratory → GPUを無料で利用して学習時間を短縮する
GPUを使ってVGG16をFine Tuningして、顔認識AIを作って見た
感想
モデルの構築のところで、層の組み合わせや、入力画像の大きさ、エポック数などハイパーパラメータをどのように決めるかが難しいですね。
もう一回「ゼロから作るDeep Learning」を読んで、理解を深めてから挑戦したいと思ってます。
とりあえず、めちゃめちゃ面白かったので、もう少し試行錯誤していきたいと思ってます。
この記事の改善したらいいところや、オススメの記事等ありましたら、教えていただけると嬉しいです!