乃木坂46のメンバー5人を分類する機械学習
夏休みに作っていたもののまとめです。
Aidemyさんのブログの記事
機械学習で乃木坂46を顔分類してみた
のほとんど丸パクりです。他の題材考えてようかと思ったけど乃木坂にハマり始めていたのでそのままやることにしました。
自分のローカル環境でも同じことができるようにコードを直したり、ちょっとだけやり方変えてみた部分があります。
違う部分は次の3つです。
- 画像の枚数
参考記事ではメンバー1人につき50~70枚ほどなんですが、別のスクレイピングで170~230枚ほどの画像枚数に増やしました。
- 画像の水増し方法
参考記事では反転処理、閾値処理、ぼかしを採用していましたが、人間の顔を左右反転するのはどうなんだろうかと思ったので(実際まいやんのほくろとか左右非対称だし)、反転処理はやめました。
代わりに、顔の画像って左右にちょっと傾いてるものとかがあるので、画像を左右に10度ずつ回転させるという処理をしました。
回転処理することで分類する時もちょっと精度あがらないかなとか思ったり。
- クロス・バリデーション (K-fold)の追加
画像を増やしたといったところで、教師データとテストデータに分けるとテストデータ40枚前後しかないし、これでは偏りがでるんじゃないかと思い、クロスバリデーションで5分割×5回の学習により全ての画像がテストデータの場合で検証しようと思い採用しました。
手順
やったことは以下の通りです。
- 画像のスクレイピング
- 顔領域の検出
- 画像の水増し
- 学習
- テスト
- クロスバリデーション
ディレクトリ構造はこんな風になってます。
/nogizaka
/data
/asuka
/mai
/nanami
/nanase
/ikuta
/face
/asuka
...
/test
/asuka
...
/train
/asuka
...
# 以下はスクリプトファイル
get_image.py
detect_face.py
devide_test_train.py
inflation.py
learn.py
predict.py
kfold.py
開発環境は途中までjupyterでやっていましたがkfoldのところからspyderに移行しました。MATLABと似た使用感で気に入ってます。
画像のスクレイピング
こちらの記事のスクレイピングを使って画像収集をしました。
python get_image.py 橋本奈々未 500
といった感じでGoogle画像検索から約500枚の画像をスクレイピング。しかしこの中には関係ない画像、他の人も写ってる画像、横顔しか写ってない画像、学習には向いてなさそうな画像など色々ありますのでこれを手動で消していきました。
余談ですが、これメンバー10人分やったんですけど推しや割と好きなメンバーなら楽しい作業だけどそれ以外のメンバーやるのはちょっと面倒だった...
結果はこんな感じ。

乃木坂46ハマったのは最近ですが推しはななみんです。卒業コンの映像見て泣きました。
顔領域の検出
import glob
import os
"""
dataディレクトリから画像を読み込んで顔を切り取ってfaceディレクトリに保存.
"""
names = ["asuka","nanami","mai","nanase","ikuta"]
out_dir = "./face"
os.makedirs(out_dir, exist_ok=True)
for i in range(len(names)):
#元画像を取り出して顔部分を正方形で囲み、64×64pにリサイズ、別のファイルにどんどん入れてく
in_dir = "./data/"+names[i]+"/*.jpg"
in_jpg = glob.glob(in_dir)
os.makedirs(out_dir + names[i], exist_ok=True)
# print(in_jpg)
print(len(in_jpg))
for num in range(len(in_jpg)):
image=cv2.imread(str(in_jpg[num]))
if image is None:
print("Not open:",num)
continue
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt.xml")
# 顔認識の実行
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
#顔が1つ以上検出された時
if len(face_list) > 0:
for rect in face_list:
x,y,width,height=rect
image = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0]<64:
continue
image = cv2.resize(image,(64,64))
#保存
fileName=os.path.join(out_dir+"/"+names[i],str(num)+".jpg")
cv2.imwrite(str(fileName),image)
print(str(num)+".jpgを保存しました.")
#顔が検出されなかった時
else:
print("no face")
continue
print(image.shape)
カスケード分類器を使って顔領域の検出。検出した顔の画像を64×64にリサイズしてfaceディレクトリに保存。ここでも顔じゃない部分を顔として検出してるものがあるのでそれを削除。角度や大きさによっては顔が検出できなかった画像もあった。

こんな感じです。
さらに次の画像の水増しに入る前に教師データとテストデータをわけておきます。
# 2割をテストデータに移行
import shutil
import random
import glob
import os
names = ["asuka","nanami","mai","nanase","ikuta"]
os.makedirs("./test", exist_ok=True)
for name in names:
in_dir = "./face/"+name+"/*"
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./face/"+name+"/")
#img_file_name_listをシャッフル、そのうち2割をtest_imageディテクトリに入れる
random.shuffle(in_jpg)
os.makedirs('./test/' + name, exist_ok=True)
for t in range(len(in_jpg)//5):
shutil.move(str(in_jpg[t]), "./test/"+name)
画像の水増し
教師データのみ、画像を閾値処理、ぼかし処理、回転処理をして水増ししました。これで教師データが9倍になりました。
- オリジナル画像(西野七瀬さん)

- 閾値処理

- ぼかし処理

- 回転処理
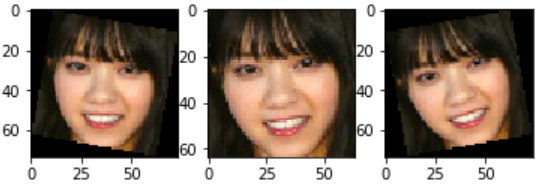
こんな感じです。
今いるメンバーでの推しはなぁちゃんだけど先日卒業発表しちゃいました。卒業ライブ行きたい。
import os
import cv2
import glob
from scipy import ndimage
"""
faceディレクトリから画像を読み込んで回転、ぼかし、閾値処理をしてtrainディレクトリに保存する.
"""
names = ["asuka","mai","nanase","nanami","ikuta"]
os.makedirs("./train", exist_ok=True)
for name in names:
in_dir = "./face/"+name+"/*"
out_dir = "./train/"+name
os.makedirs(out_dir, exist_ok=True)
in_jpg=glob.glob(in_dir)
img_file_name_list=os.listdir("./face/"+name+"/")
for i in range(len(in_jpg)):
#print(str(in_jpg[i]))
img = cv2.imread(str(in_jpg[i]))
# 回転
for ang in [-10,0,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,(64,64))
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+".jpg")
cv2.imwrite(str(fileName),img_rot)
# 閾値
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"thr.jpg")
cv2.imwrite(str(fileName),img_thr)
# ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
fileName=os.path.join(out_dir,str(i)+"_"+str(ang)+"filter.jpg")
cv2.imwrite(str(fileName),img_filter)
このコードは結構自力で書きました。

こうなります。
学習
学習モデルは参考記事とほぼ同じで次のような層構造です。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 64, 64, 32) 416
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 32, 32, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 32, 32, 32) 4128
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 16, 16, 32) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 32) 4128
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0
_________________________________________________________________
dense_1 (Dense) (None, 256) 524544
_________________________________________________________________
activation_1 (Activation) (None, 256) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 32896
_________________________________________________________________
activation_2 (Activation) (None, 128) 0
_________________________________________________________________
dense_3 (Dense) (None, 4) 516
_________________________________________________________________
activation_3 (Activation) (None, 4) 0
=================================================================
Total params: 566,628
Trainable params: 566,628
Non-trainable params: 0
_________________________________________________________________
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
name = ["asuka","mai","nanase","nanami","ikuta"]
# 教師データのラベル付け
X_train = []
Y_train = []
for i in range(len(name)):
img_file_name_list=os.listdir("./train/"+name[i])
print(len(img_file_name_list))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./train/"+name[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_train.append(img)
Y_train.append(i)
# テストデータのラベル付け
X_test = [] # 画像データ読み込み
Y_test = [] # ラベル(名前)
for i in range(len(name)):
img_file_name_list=os.listdir("./test/"+name[i])
print(len(img_file_name_list))
for j in range(0,len(img_file_name_list)-1):
n=os.path.join("./test/"+name[i]+"/",img_file_name_list[j])
img = cv2.imread(n)
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b])
X_test.append(img)
# ラベルは整数値
Y_test.append(i)
X_train=np.array(X_train)
X_test=np.array(X_test)
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
from keras.models import Sequential
from keras.utils.np_utils import to_categorical
y_train = to_categorical(Y_train)
y_test = to_categorical(Y_test)
# モデルの定義
model = Sequential()
model.add(Conv2D(input_shape=(64, 64, 3), filters=32,kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3),
strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
model.add(Dense(5))
model.add(Activation('softmax'))
# コンパイル
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 学習
history = model.fit(X_train, y_train, batch_size=32,
epochs=50, verbose=1, validation_data=(X_test, y_test))
# 汎化制度の評価・表示
score = model.evaluate(X_test, y_test, batch_size=32, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))
# acc, val_accのプロット
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
# モデルを保存
model.save("my_model.h5")
結果はこうなりました。

精度は84%ぐらい。結構高めなんじゃないかと思います。水増し方法を変えたから参考記事よりも高くなったんだと思います。モデル構造は特にいじってないのでもっと精度が高くなるモデルを構築する余地はありそうです。
テスト
import numpy as np
import matplotlib.pyplot as plt
import cv2
from keras.models import load_model
import sys
"""
spyderで実行するときは実行→ファイルごとの設定からコマンドライン引数を渡す
"""
def detect_face(image):
print(image.shape)
#opencvを使って顔抽出
image_gs = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cascade = cv2.CascadeClassifier("./haarcascades/haarcascade_frontalface_alt.xml")
# 顔認識の実行
face_list=cascade.detectMultiScale(image_gs, scaleFactor=1.1, minNeighbors=2,minSize=(64,64))
#顔が1つ以上検出された時
if len(face_list) > 0:
for rect in face_list:
x,y,width,height=rect
cv2.rectangle(image, tuple(rect[0:2]), tuple(rect[0:2]+rect[2:4]), (255, 0, 0), thickness=3)
img = image[rect[1]:rect[1]+rect[3],rect[0]:rect[0]+rect[2]]
if image.shape[0]<64:
print("too small")
continue
img = cv2.resize(image,(64,64))
img=np.expand_dims(img,axis=0)
name = detect_who(img)
cv2.putText(image,name,(x,y+height+20),cv2.FONT_HERSHEY_DUPLEX,1,(255,0,0),2)
#顔が検出されなかった時
else:
print("no face")
return image
def detect_who(img):
#予測
name=""
print(model.predict(img))
nameNumLabel=np.argmax(model.predict(img))
if nameNumLabel== 0:
name="Saito Asuka"
elif nameNumLabel==1:
name="Shiraishi Mai"
elif nameNumLabel==2:
name="Nishino Nanase"
elif nameNumLabel==3:
name="Hashimoto Nanami"
elif nameNumLabel==4:
name="Ikuta Erika"
return name
if __name__ == '__main__':
model = load_model('./my_model.h5')
if len(sys.argv) != 2:
print('invalid argment')
sys.exit()
else:
im_jpg = sys.argv[1]
image=cv2.imread("./predict/"+im_jpg)
if image is None:
print("Not open:")
b,g,r = cv2.split(image)
image = cv2.merge([r,g,b])
whoImage=detect_face(image)
plt.imshow(whoImage)
plt.show()
これは参考記事のものをコマンドライン引数から画像を指定できるように変えただけです。
とりあえずいくつか結果を載せます。





画像入れて予測してみると結構外れる...
孤独兄弟の2ショット2人とも正解になる画像めっちゃ探したけど見つからなかったorz
ここでの予測の際に顔を検出してくれないことが多々あったので画像回転して顔を探すようにしてみるのもいいかもしれません。
クロスバリデーション
クロス・バリデーション (K-fold)
簡単に言えばデータセット全体をk分割し、1つをテストデータ、残りk-1個を学習データとして学習、検証を行うもの。k回の学習&検証のスコアの平均で精度を見る。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from scipy import ndimage
from sklearn.model_selection import StratifiedKFold
from keras.layers import Activation, Conv2D, Dense, Flatten, MaxPooling2D
from keras.models import Sequential
from keras.utils.np_utils import to_categorical
import copy
names = ["asuka","mai","nanase","nanami","ikuta"]
fold_num = 5
batch_size = 32
num_classes = len(names)
epochs = 50
kfold = StratifiedKFold(n_splits=fold_num, shuffle=True)
cvscores = []
X = []
Y = []
for itr in range(len(names)):
img_file_name_list=os.listdir("./face/"+names[itr])
print(names[itr]+"の画像枚数は"+str(len(img_file_name_list)))
for j in range(0,len(img_file_name_list)):
n=os.path.join("./face/"+names[itr]+"/",img_file_name_list[j])
face = cv2.imread(n)
b,g,r = cv2.split(face)
face = cv2.merge([r,g,b])
X.append(face)
Y.append(itr)
# X = np.array(X)
Y = np.array(Y)
# Y = to_categorical(Y)
face_count = len(X)
kfold = StratifiedKFold(n_splits=fold_num, shuffle=True)
cvscores = []
for train, test in kfold.split(X, Y):
train_count = len(train)
X_array = copy.deepcopy(X)
Y = Y[0:face_count].tolist()
#水増し
for i in train:
img = X_array[i]
img_thr = cv2.threshold(img, 100, 255, cv2.THRESH_TOZERO)[1]
img_filter = cv2.GaussianBlur(img, (5, 5), 0)
X_array.append(img_thr)
Y.append(Y[i])
X_array.append(img_filter)
Y.append(Y[i])
for ang in [-10,10]:
img_rot = ndimage.rotate(img,ang)
img_rot = cv2.resize(img_rot,(64,64))
# 閾値
img_thr = cv2.threshold(img_rot, 100, 255, cv2.THRESH_TOZERO)[1]
# ぼかし
img_filter = cv2.GaussianBlur(img_rot, (5, 5), 0)
X_array.append(img_rot)
Y.append(Y[i])
X_array.append(img_thr)
Y.append(Y[i])
X_array.append(img_filter)
Y.append(Y[i])
#np.append(train,np.arange(train_count+1,len(Y)))
train = np.concatenate([train,np.arange(face_count,len(Y))], axis=0)
model = Sequential()
model.add(Conv2D(input_shape=(64, 64, 3), filters=32,kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(filters=32, kernel_size=(3, 3), strides=(1, 1), padding="same"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(256))
model.add(Activation("sigmoid"))
model.add(Dense(128))
model.add(Activation('sigmoid'))
model.add(Dense(5))
model.add(Activation('softmax'))
model.compile(optimizer='sgd', loss='categorical_crossentropy',metrics=['accuracy'])
Y = np.array(Y)
X_array = np.array(X_array)
Y_train = Y[train].tolist()
Y_train = to_categorical(Y_train)
Y_test = Y[test].tolist()
Y_test = to_categorical(Y_test)
#Fit model
history = model.fit(X_array[train], Y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(X_array[test], Y_test))
# Evaluate
scores = model.evaluate(X_array[test], Y_test, verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
cvscores.append(scores[1] * 100)
#acc, val_accのプロット
plt.subplot(5,1,len(cvscores))
plt.plot(history.history["acc"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.title("accuracy"+str(len(cvscores)))
print("%.2f%% (+/- %.2f%%)" % (np.mean(cvscores), np.std(cvscores)))
plt.show()
これはかなり自分で試行錯誤しながらコーディングしました。5個にわけたうちの学習データにのみ画像の水増しをする処理を加えるのがかなりきつかったです。
結果はこのようになりました。

めちゃくちゃ醜くて申し訳ないです。
スコアの値はこちら。
# 5回分のスコア(acurracy)
[83.17307692307693,
84.13461538461539,
80.67632856000448,
79.12621353436442,
81.4634146922972]
平均と分散
81.71% (+/- 1.78%)
どれも約80%でいい感じではないでしょうか。しかしテストデータにどのデータが選ばれるかによって精度が5%も変わるということがわかりました。もっとデータ数が多ければこんなことはないんだろうと思いますけどね。
全体としての精度は平均である81.71%という結果になりました。
感想
かなりAidemyさんのコード写経な部分も多かったですが、それらのコードを理解して自分の環境用に直すのは、なかなかに学ぶ部分も多かったと思います。水増しやクロスバリデーションの部分では自分でアルゴリズム考えてやってみたのも面白かったです。
これやってた時は友達の影響で乃木坂をよく見る程度だったんですが最近どんどん乃木オタ化が進んでます。ライブの円盤買うまでになるとは笑。そのうち現場に参戦しだすかも笑
コードに関しての質問、改良点などのアドバイス、乃木坂オタクトーク等々ありましたらコメントしてください。きっと返信します。
長々と読んでいただいてありがとうございました。