概要
Kerasで提供されているVGG16という大規模な画像で学習済みのモデルを活用して、ご注文はうさぎですか?(略称 ごちうさ)に登場する主要キャラクター5名の画像を分類するモデルを作成します。
この学習済みモデルを使用して少ないデータセットで、かつ比較的短時間で学習できる手法をFine-tuningといいます。
用語解説
- Tensorflow ・・・ Googleが開発しオープンソースで公開している、機械学習に用いるためのソフトウェアライブラリ。
- Keras ・・・ オープンソースのニューラルネットワークライブラリ。バックエンドでTensorflowも動かせる。
- VGG16 ・・・ ImageNetと呼ばれる大規模な画像データセットを使って学習された16層からなるニューラルネットワークモデル。
- ご注文はうさぎですか? ・・・ まんがタイムきららMAXで連載中の漫画。アニメ化もされた人気作品。可愛いと癒やしに溢れた素晴らしい作品です。是非アニメ見てください。

キャラクター名は左からチノ、ココア、リゼ、シャロ、千夜という。今回はこの5名を分類するモデルを作成します。
動機
- Deep Learningで画像分類をしてみたかった。
- しかし自分で大規模なデータセットを1から用意するのは面倒くさい。
- 自分のマシンがCPUでしか計算できないが、何度も試行錯誤することを考えると、なるべく学習時間をかけずにDeep Learningしたい。
- 少ないデータセットで、かつCPUの演算能力でも比較的短時間で計算が終了する手法を探る必要があった。
- そこで、Kerasの学習済みモデルをFine-tuningすることで、これを達成できるのではないかと考えた。
- どうせ画像分類するならデータセット収集段階から楽しみたい。ごちうさ画像を集めるのがモチベーションになる。
マシンスペック
| 端末 | MacBook Air (13-inch) |
|---|---|
| CPU | Intel Core i5 |
| メモリ | 8 GB |
| OS | macOS 10.13 High Sierra |
ソースコード
GitHubにて公開しています。
https://github.com/kazuki-hayakawa/fine_tuning
記事中ではライブラリのimport文など書いていないので、細かな点はこちらをご覧ください。
Fine-tuningで学習する
事前準備
今回は5つのクラスに対し、1クラスあたりトレーンング用に40枚、バリデーション用に10枚の画像を用意しました。
合計トレーニング用200枚、バリデーション用50枚のデータセットがあります。
Kerasは画像の読み込みを簡単に行ってくれる関数があるので、それに合わせたディレクトリ構造にします。
具体的には、以下のように分類クラスごとにディレクトリを作成します。
dataset
├── train
│ ├── chino
│ ├── chiya
│ ├── cocoa
│ ├── rize
│ └── syaro
└── validation
├── chino
├── chiya
├── cocoa
├── rize
└── syaro
事前に設定したパラメータはこちら
# 分類するクラス
classes = ['chino', 'cocoa', 'chiya', 'rize', 'syaro']
nb_classes = len(classes)
img_width, img_height = 150, 150
# トレーニング用とバリデーション用の画像格納先
train_data_dir = 'dataset/train'
validation_data_dir = 'dataset/validation'
# 今回はトレーニング用に200枚、バリデーション用に50枚の画像を用意した。
nb_train_samples = 200
nb_validation_samples = 50
batch_size = 16
nb_epoch = 10
トレーニング用、バリデーションデータを作成するジェネレータは以下のように作ります。
# トレーンング用、バリデーション用データを生成するジェネレータ作成
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_generator = train_datagen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
validation_generator = validation_datagen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
color_mode='rgb',
classes=classes,
class_mode='categorical',
batch_size=batch_size,
shuffle=True)
モデル作成
VGG16の学習済みモデルを用意します。ただし、FC層と呼ばれるフル結合層はデフォルトの1000クラスの分類を行う出力層なので、これは使いません。FC層のみ自分で用意して、結合させてモデルとします。
また、FC層直前までの重みは更新しないのでfreezeして余計な学習をさせないようにします。
今回は多クラス分類になるので、損失関数は categorical_crossentropy を指定します。optimizerはSGDです。adamでもうまくいくらしいですが、今回は試していません。
# VGG16のロード。FC層は不要なので include_top=False
input_tensor = Input(shape=(img_width, img_height, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# FC層の作成
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(nb_classes, activation='softmax'))
# VGG16とFC層を結合してモデルを作成
vgg_model = Model(input=vgg16.input, output=top_model(vgg16.output))
# 最後のconv層の直前までの層をfreeze
for layer in vgg_model.layers[:15]:
layer.trainable = False
# 多クラス分類を指定
vgg_model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-3, momentum=0.9),
metrics=['accuracy'])
Fine-tuningで学習実行
実際に学習を実行させてみます。CPUのみで学習させましたが、約67分で学習が終了しました。
# Fine-tuning
history = vgg_model.fit_generator(
train_generator,
samples_per_epoch=nb_train_samples,
nb_epoch=nb_epoch,
validation_data=validation_generator,
nb_val_samples=nb_validation_samples)
# 重みを保存
vgg_model.save_weights(os.path.join(result_dir, 'finetuning.h5'))
結果の確認
学習経過は以下のようになりました。
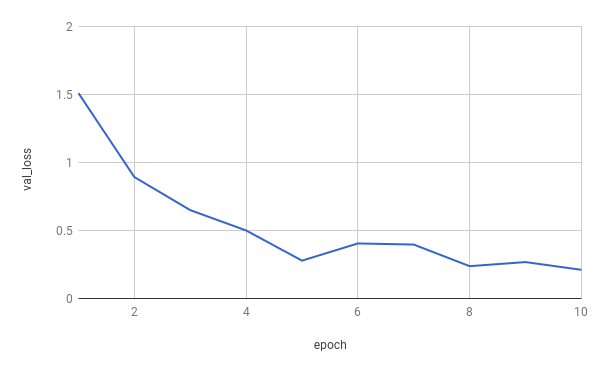
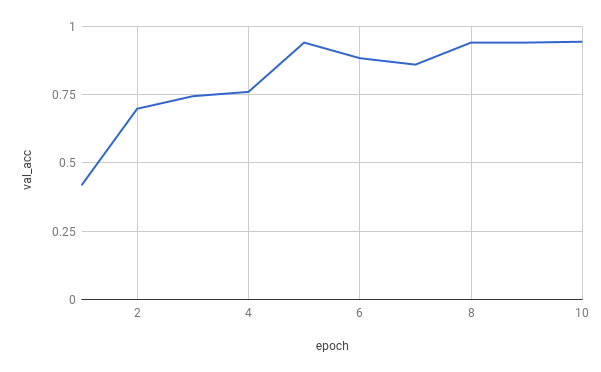
わずか10epochのみの学習ではありますが、最終的に93%程度の精度が出ています。
実際にいくつかの画像を実際に判定してみましょう。

[('chino', 0.99524927)]
99.5% チノちゃんという判定です!!

[('rize', 0.99999428)]
99.9% リゼちゃんです。これはもう完全にリゼちゃんですね。
収集してきた画像がアニメのものが多かったので、アニメ画像についてはそれなりの精度で分類できているようです。

[('cocoa', 0.76128566)]
原作絵かつ衣装も普段とは異なるものですが、なんとか76%でココアちゃんだと判定してくれました。
この辺は、様々なバリエーションのキャラクターの衣装や髪型の教師データを用意すればもっと精度が上げられそうです。
ともあれ、無事に少ないデータで、かつ短い学習時間で任意の画像分類器が作れました!
精度を追求するならGPUで大規模データセットの学習をゴリゴリ回すのがやはり良いのでしょうが、データも無く試行錯誤で精度をあげたい中では中々に実践的な手法なのではないでしょうか。
参考にしたサイト
VGG16のFine-tuningによる犬猫認識 (2) - 人工知能に関する断創録
VGG16のFine-tuningによる17種類の花の分類 - 人工知能に関する断創録