概要
自分焼いたパンが良い出来かどうかわからないという経験、ありますよね?
私もそうなんですが、先日自分で作ったフランスパンの断面を見てみると、お店で買ったパンと比べて小さい気泡ばかりでした。どうやら、発酵具合、こね方、水分の量といったものがイマイチだったみたいです。そこで、お店のパンの断面と比較して、良いか悪いか判断できるツールを作れたら良いのではと思ったわけです。
実際に私の焼いたパンの画像がこちら。全体の画像(上)と、断面の画像(下)です。


これはお店のパン。大小の気泡がキレイ。

この見た目の違いを画像認識使って判定させます。
この記事ではVGG16をつかった画像認識で、自作パン(おいしくない)とお店のパン(おいしい)を見分けることを目標にしています。
目次
- 準備
- モデル作成
- 学習
- モデル評価
準備
必要なもの
google colaboratoryを使ってモデルを学習させ、学習させたモデルをファイルとして出力します。
googleアカウントが一つあれば完璧。
('23/4/30追記)
後半に記載したWEBアプリ化はローカル環境で行っています。WEBアプリ化するためには以下も必要です。
・python (自分は3.10.10使いました)
・flaskなどのモジュール類
アプリ用クラウドにアップロードする際、必要なものをrequirements.txtにしてアップロードします。
今回のアプリでは以下を記載しています。
Flask==2.2.3
numpy==1.18.0
tensorflow-cpu==2.3.0
Werkzeug==2.2.3
protobuf==3.19.6
pillow==7.2.0
・Githubのアカウント
・Renderのアカウント(クラウド上でアプリを簡単に公開できるサービスです)
画像の準備
美味しいフランスパン(お店のパン)と、自作フランスパン(おいしくないパン)を準備して撮影します。
画像はそれぞれ100枚以上は必要。
貧乏な私はパンを切り刻んでなるべく1個のパンからたくさん写真が撮れるように努力しました。
学習では、ImageDataGeneratorを使って拡大・縮小・左右反転といった水増し処理も行っています。
自作フランスパンは「ブリティッシュ・ベイクオフ」のシーズン6でポール・ハリウッドさんが解説してくれたレシピで作っています。
モデル作成
今回利用するのはVGG16を利用した転移学習です。
- VGG16とは
オックスフォード大学の研究者が作った画像認識用のニューラルネットワーク。このモデルは性能が良くて、真似るだけで高い認識精度を得ることができます。しかも、100万枚を超える画像で事前学習させたモデルを、手軽に利用できてしまうのがよいところ。ただし、そのまま使うと1000クラス分類になってしまうので、パン画像に使うにはひと工夫必要です。
コードと解説
モデル作成部分のコードです。
# VGG16モデルを使う準備
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
# モデルを定義。weightsはimagenetで学習した重みを流用する
vgg16 = VGG16(include_top=False, weights='imagenet', input_shape=(128, 128, 3))
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
「VGG16」関数を使えば、VGG16モデルをインポートして使用できます。
(参考URL, Keras Documentation: https://keras.io/ja/applications/#vgg16)
ざっくり解説
vgg16 = VGG16(include_top=False, weights='imagenet', input_shape=(128, 128, 3))
引数を詳しくみてみましょう。
-
include_top
ネットワークの出力層側にある3つの全結合層を含むかどうか。Falseにすると含みません。今回は「おいしそう」、「おいしくなさそう」の2クラス分類にしたいので、Falseにします。 -
weights
'imagenet' (ImageNetで学習した重み) を使うかどうかを選択します。weights='imagenet'にして、事前学習の恩恵を得ましょう。使わずに自分で一から学習するより、学習の収束が早くなって良い結果が得られることが期待できます。 -
input_shape
入力画像の形状を指定します。
(128, 128, 3)は、128 x 128 画素でR/G/Bの3色のデータということです。もちろん指定した通りに画像変換して入力する必要があります。
次に出力層を作っていきます。
top_model = Sequential()
まず、Sequentialという種類のモデルを宣言します。このあとにどんどん層を追加していきます。
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
最初にFlatten層を追加します。
これは文字通り入力を「フラット」にする層で、(128, 128, 3)の3次元のデータをフラットにします。つまり128 x 128 x 3の大きさ立方体を、49152 (128 x 128 x 3 = 49152)の長さの線に変換。
top_model.add(Dense(256, activation='relu'))
次に、Dense層を追加します。Dense層は全結合層と呼ばれ、前の層とすべてのニューロンが結合して、画像から特徴的なパターンを抽出してくれます。
計算結果は、活性化関数に渡されます。
活性化関数(activation)はここでは"relu"を使っています。活性化関数はいろいろあって、テストしながら選ぶ必要があります。
top_model.add(Dropout(rate=0.5))
次の層はDropout層です。Dropout層では、ランダムに入力ユニットを0にします。なぜわざわざ0にして計算結果を捨てるのか?
どうやら、ある入力に依存してしまうと学習した画像だけに強くなって、新しい画像を判別させようとした時にうまくいかなるそうです。そこでより汎用的なモデルにするためのテクニックとしてDropoutがあるんですね。
top_model.add(Dense(2, activation='softmax'))
最後はDense層です。フィルタの数は「2」になっています。これは今回「おいしい」「おいしくない」の2種類の分類する目的のためです。活性化関数で"softmax"にすると、入力を0から1の範囲に変換し、合計が1になるようにしてくれます。例えば、おいしい確率0.3、おいしくない確率0.7といった結果が得られるというわけですね。
学習
さて、つくったモデルをつかって学習を行います。
コードを載せていきます。
画像の読み込み
# googleドライブ上に画像を置いているので、ドライブをマウントする
from google.colab import drive
drive.mount('/content/drive')
google colabは長時間操作しないとファイルのアップロードからやり直しになるのが嫌なので、googleアカウントのドライブに画像ファイルを保存しておいて、そこから画像データを読み込むようにしています。
(ただし、これを行うとcolabからGoogle Driveにアクセスを許可することになります。Drive内への不正アクセスのリスクを考慮の上、自己責任で!)。載せておいてなんですが、他人のコードでは実行しないのが良いです。ドライブにマウントしなくても、google colabにファイルをドラッグ&ドロップすれば同じことができます。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# ファイル一覧を取得
path_myBread = os.listdir("/content/drive/MyDrive/Bread_Picture/my_bread/")
path_goodBread = os.listdir("/content/drive/MyDrive/Bread_Picture/good_bread/")
# 画像を置くための空リストを作成
img_myBread = []
img_goodBread = []
# リサイズする時のサイズを変数に代入しておく
imgSize = (128,128)
vgg_input_shape = (128, 128, 3)
# 自作パンの断面画像を取得する
for i in range(len(path_myBread)):
img = cv2.imread("/content/drive/MyDrive/Bread_Picture/my_bread/" + path_myBread[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b]) #RGBの並びになるように修正(OpenCVの関数imread()で画像ファイルを読み込むと色の順番がBGR(青、緑、赤)になる)
img = cv2.resize(img, imgSize)
img_myBread.append(img)
画像の一覧を os.listdir をつかって取得し、画像の枚数分 cv2.imread で画像を読み込みます。
cv2.imread をつかって画像を読み込むと、色の順番がBGR(青、緑、赤)になります。しかしこの後の処理ではRGB(赤、緑、青)の順になっている必要があるので、cv2.split をつかって色分解し、その後 cv2.merge で指定の順番に再結合しています。
最後にcv2.resize で画像を指定のサイズにそろえて、リストに追加して終わりです。
# 同様に、おいしいパンの断面画像を取得する
for i in range(len(path_goodBread)):
img = cv2.imread("/content/drive/MyDrive/Bread_Picture/good_bread/" + path_goodBread[i])
b,g,r = cv2.split(img)
img = cv2.merge([r,g,b]) #RGBの並びになるように修正
img = cv2.resize(img, imgSize)
img_goodBread.append(img)
同じ処理を美味しいパンの画像に対して行います。
画像の水増し(ImageDataGenerator)
そのまま学習に入っても良いのですが、画像が少ない場合は水増し処理をします。水増し処理とは、左右反転した画像や拡大・縮小した画像を自動的に生成して学習に用いることです。
ImagedDataGeneratorを使うと、ランダムに左右反転、画像の拡大、回転を行って学習に追加してくれて便利。
パラメータがいくつもあります。
どんなパラメーターが使用できるかは、参考URLを参照して下さい。
(参考URL, Keras Documentation:https://keras.io/ja/preprocessing/image/)
one-hotベクトルに変換
# 自作パン画像とおいしいパン画像を統合する
X = np.array(img_myBread + img_goodBread)
# 目的変数 y : 自作パン = 0, おいしいパン = 1 として y を作成
y = np.array([0]*len(img_myBread) + [1]*len(img_goodBread))
# one_hotベクトルに変換
y = to_categorical(y)
学習元とするデータを"X"、その答えを"y"として定義します。
Xは画像、
yは自作パン = 0 、美味しいパン = 1 としたベクトルです。
yは今後の処理のためにyはone_hotベクトルに変換します。
(参考URL, Keras Documentation::https://keras.io/ja/utils/#to_categorical)]
# K=5の 5-Fold Cross Validationを実装する
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
cv = KFold(n_splits=5, random_state=0, shuffle=True)
acc_list = []
models = []
for train_index, test_index in cv.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
# ImageDataGeneratorで水増しさせる
train_iter = generator.flow(x=X_train, y=y_train)
# VGG16モデルを使う準備
# 画像サイズは最初に定義した変数を使う
# weightsはimagenetで学習した重みを流用する
vgg16 = VGG16(include_top=False, weights='imagenet', input_shape=vgg_input_shape)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
# モデルをコンパイルする
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
history = model.fit(train_iter, batch_size=100, epochs=30, validation_data=(X_test, y_test))
#評価を行う
loss, acc = model.evaluate(X_test, y_test, batch_size=100)
# グラフ表示する
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.suptitle("model", fontsize=12)
plt.legend()
plt.show()
これは学習を行い、その精度をグラフ表示するコードです。このコードを実行すると、5つのグラフが表示されます。
なぜ5つも結果が出てくるのかというと、これはクロスバリデーションと呼ばれる手法を使っているためです。
(参考URL:https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.KFold.html)
データを学習用と検証用に分けて評価する場合、検証用としたデータは学習には使用できずにもったいないですね。そこで、クロスバリデーションです。
クロスバリデーションでは例えばデータを5つグループに分けます。4つ分ので学習用し、1つのグループを検証用として使います。そして検証用にするグループを交代して学習していきます。
5回の学習が必要になりますが、すべてのデータを学習に使うことが出来ています。これでデータを有効活用できる、というわけですね。
モデル評価
学習の結果をグラフに表示すると、モデルの精度が学習が進むとともに上がっていくことが分かりやすいです。
以下は学習時に表示されたグラフの一つです。
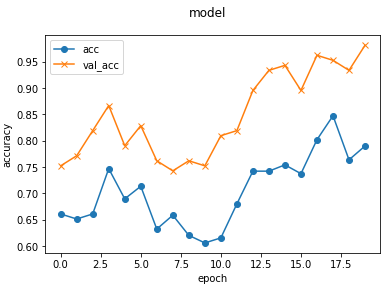
x軸はエポック数(学習の回数)
y軸は精度です。
「acc」は学習用データでの精度、「val_acc」は検証用データでの精度です。
学習が進む度に精度は右肩上がりで上がっているので学習が進んでいます。しかしエポック数を増やせばまだ精度は上がりそうです。
エポック数 20 → 50

エポック数を50まで増やしてみました。30くらいまでは精度は上昇を続けて、あとは横ばいのようです。エポック数は30にしておきます。
最適化アルゴリズム(optimizer) sgd → adam
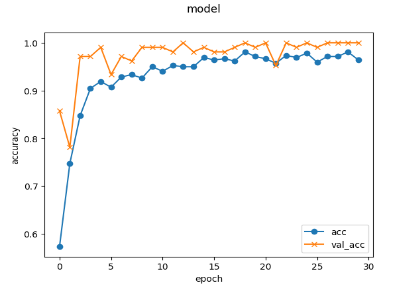
最適化アルゴリズムを「sgd」から「adam」に変えました。けっこう違いますね。収束が非常に早くなっています。
ちなみに「sgd」「adam」の詳細については以下参照ください。
(参考URL, Keras Documentation:https://keras.io/ja/optimizers/)
あとはDense層のフィルタ数、学習時のバッチ数など変更しましたが、残念ながら改善しませんでした。十分な精度も出ていることですし、パラメータはこれで決定です。
テスト
パラメータが決まった後は、テストします。
先ほどまでは学習用データをつかった学習と検証を行いましたが、最後にモデルが未知のデータに対して精度よく動作するかどうか、テストデータを用いて確かめます。
#クロスバリデーション無しで、改めてモデルを作成する
vgg16 = VGG16(include_top=False, weights='imagenet', input_shape=vgg_input_shape)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(128, activation='relu'))
top_model.add(Dropout(rate=0.5))
top_model.add(Dense(2, activation='softmax'))
# モデルの連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
# vgg16の重みの固定
for layer in model.layers[:19]:
layer.trainable = False
# モデルをコンパイルする
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
先ほどクロスバリデーションで5個のモデルを作りましたが、今回は最後のテストのために改めてモデルを作ります。パラメータは検証で確定させたものを使用します。
最終テスト用の画像の準備は、上で記載したテスト用画像の準備と同じなので省略します。
テストする際は、学習には一切使用していない画像を使用します。
# モデルの評価
finaltest_scores = model.evaluate(finaltest_X, finaltest_y, verbose=0)
print('final test loss:', finaltest_scores[0])
print('final test accuracy:', finaltest_scores[1])
最後にevaluate関数を用いて、精度を計算します。
今回の自分の結果では、以下の通り精度は99%以上の良い結果が得られました。
final test loss: 0.02665882743895054
final test accuracy: 0.9949238300323486
('23/4/30追記)
・誤判定する画像について

上の画像は、「おいしいパン」の画像ですが、AI予想は「おいしくない」でした。
パンの映り自体は悪くなさそうですが、背景に対してパンが小さめだったり、背景に別の皿が混じったりしていることが精度の落ちる一因かもしれません。
・画像背景について
パン断面の画像を撮影する際、3つの背景で撮影しました
1.緑の皿
2.白い皿
3.木のプレート
テスト画像も同様です。
例えば背景が大きく違うとどうでしょうか。

上の写真は手にもって撮影した画像です。同じような画像を4枚撮影して試してみましたが4枚中1枚は誤判定でした。背景による判定結果への影響は大きいと想定されます。背景が固定できない想定なら、もっといろいろな背景の写真で学習させるか、輪郭抽出でパン部分を抜き取って学習・判定させるといった工夫が必要でしょう。
例えば工場などで良品判定に画像判定を使うなら、なるべく背景に余分なものが入らないようにして、カメラの位置は固定するような工夫が必要かと思います。
モデルを出力する
完成したモデルをファイルとして出力します。
# モデルの調整が終わったら、モデルデータを出力
from google.colab import files
# resultディレクトリを作成
result_dir = "result"
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習したモデルを保存
model.save(os.path.join(result_dir, "model.h5"))
files.download("/content/result/model.h5")
上記のコードを実行することで、google clab内の"/content/result/" に「model.h5」というファイルが作成され、PCにダウンロードされます。
このモデルファイルが動作するか試してみましょう。
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import Sequential, load_model
# モデルに画像を適用するテスト
testModel = load_model("/content/result/model.h5")
testImage = image.load_img("/content/drive/MyDrive/Bread_Picture/good_bread/DSC_0080.JPG", target_size=(128, 128))
plt.imshow(testImage)
plt.show()
testImage = image.img_to_array(testImage)
data = np.array([testImage])
# 画像データをモデルに渡して予測結果をresultへ代入
result = testModel.predict(data)[0]
print("answer = {}".format(result.argmax()))
load_model関数を使って、引数にモデルファイルのパスを指定します。
これでモデルが読み込まれました。
テスト用の画像をNumPy配列に変換し、predict関数の引数に指定しましょう。
予測結果をresultとして受け取ります。
(predict関数の出力の1個目に結果が格納されていますので、resultに代入するのはindex=0の部分。)
resultにはおいしくないパンである確率と、おいしいパンである確率が入っています。
確率が高いほうを予測結果として採用しましょう。
result.argmax()
と書くことで大きいほうの値を得られます。
ちなみに以下のように表示されます。
自作パンの場合は answer = 0 お店のパンの場合は answer = 1 となっています。


アプリで動作を確認する
モデルを組み込んだ実際のアプリはこちら。
https://my-bread-sucks-app.onrender.com/

ファイル選択で画像を選んで、「画像を判定する!」ボタンを押します。!

すると結果が返ってきます。

おわりに
AIを使ってパンのおいしさを見分けることができました。それも99%という高精度。
「おいしさを判断できているわけではないのでは?」と言われてしまいそうですが、確かにその通りですね。しかし、不良扱いになる欠点が分かっていて、データを十分とれるならAIで見分けがつくということがこの結果からわかると思います。
今回は、対象を絞ることで高精度を出せたと思います。
「おいしいパン」のサンプルは1店のフランスパンのみ、「おいしくないパン」のサンプルは自作のもので材料や焼き時間は固定して作りました。それぞれ5,6本ずつをカットして断面撮影しています。
判定は「おいしい」「おいしくない」の2クラス分類にしましたが、もっと欠点ごとのパンのサンプルを集めることができるなら、
・「焼き色がたりない」「発酵が足りない」といった具体的な指摘をもらえるようにする
・「これはフランスパンじゃない」、という判定外分類を追加する
といった多分類ができるようになり、もっと実用性が増すかもしれません。何度作っても「おいしくなさそう」と言われ続けたら、やる気も失せますしね。
最後までお付き合いいただきありがとうございました。