画像検索で拾った画像を約80%の精度で見分けることができた。
VGG16を転移学習させたモデルで予測した画像


ちなみにキャラクターは、

homura(暁美ほむら)
かわいいよほむほむ。

kyoko(佐倉杏子)

madoka(鹿目まどか)

mami(巴マミ)

sayaka(美樹さやか)
転移学習とは
例えば、CNN(Convolutional Neural Network)で画像認識などを一からモデル構築するとなると、大量のサンプル画像を集めなければいけないですし、さらに学習にも多くの時間がかかります。
転移学習では、すでに学習済みのモデルを使って、より少ない画像、より短時間で学習モデルを構築することを目指します。
VGG16という学習モデルを例にしてみます。
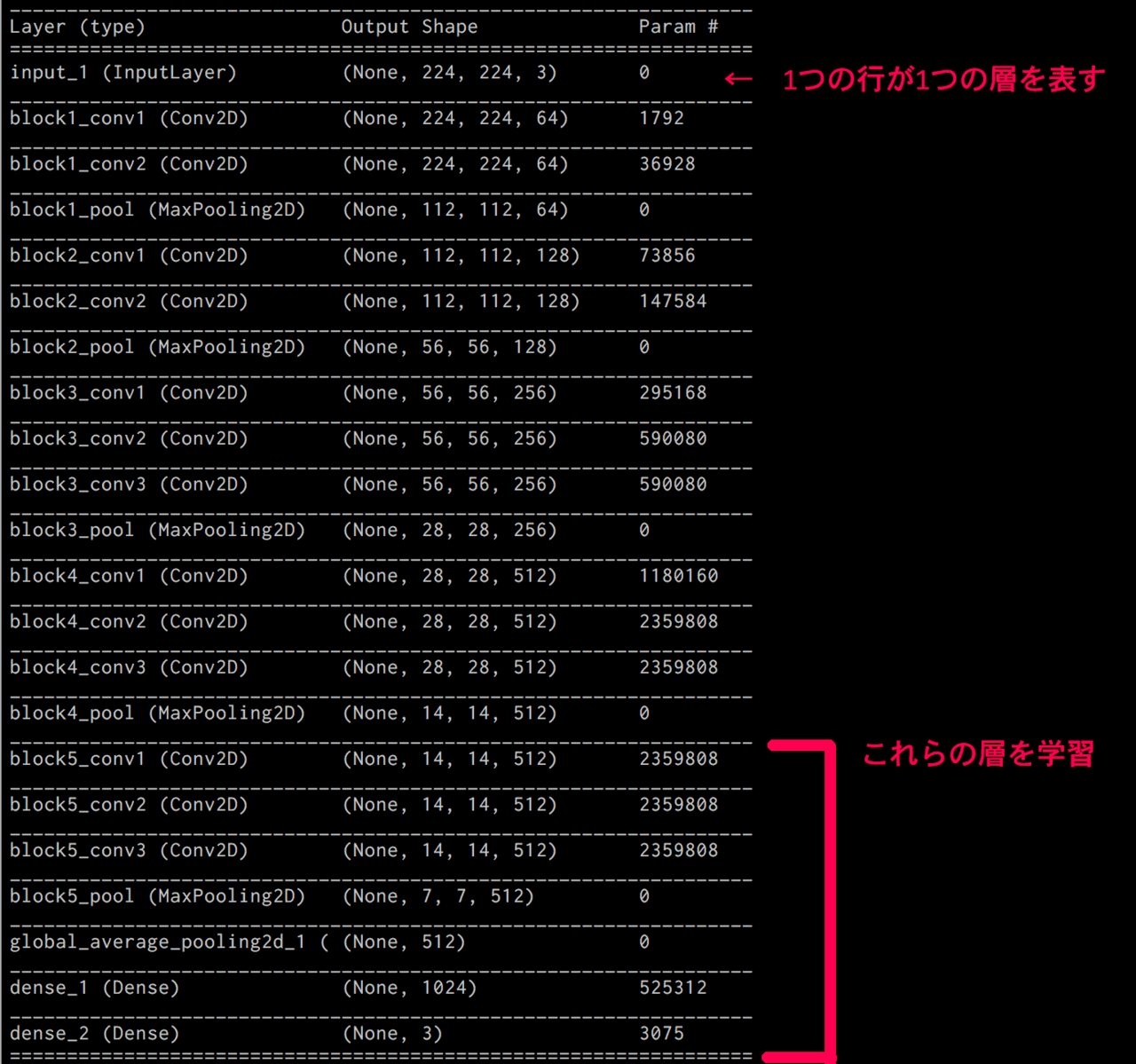
引用:少ない画像から画像分類を学習させる方法(kerasで転移学習:fine tuning)
VGG16は13層の畳み込み層と3層の全結合層の計16層からなります(Kerasで使う場合はMaxPoolingなども1層に含まれる)
ImageNetと呼ばれる大規模画像データセットで学習させたモデルです。
今回の実装では、VGG16の全結合層を外して新たに全結合層を追加し
、15層以降のみを学習させます。(14層までの重みは更新しない)
これによって、VGG16の高い特徴量抽出を継承しつつ、少サンプル・短時間で精度の高い学習モデルを構築できます。
なぜこんなことをするかというと、CNNにおいて浅い層では縦線・横線などのおおよその特徴を抽出し、深い層(VGG16の15層以降など)では、その画像特有の特徴を抽出することがわかっています。
つまり、深い層を取り外し、浅い層を再利用することで効率よく転移学習することができます。
Kerasで実装
スクリプトを実装する前にデータセットを用意します。
私のGitHubのほうにデータなどが置いてあります。GitHub
GitHubのほうにmadoka_magica_imagesというフォルダがあると思います。この中に転移学習で使うようの画像が入っています。

画像がtrain 250枚、validation 150枚、test 412枚入ってます。displayは冒頭のような画像を表示させるときに使う用です。中身はtestと同じ。
ちなみにこのデータセットは、Googleの画像検索で延々とポチポチして自作しました。いやぁ今回やってて一番楽しかったポイントですね(遠い目
ライブラリのインポートとモデル構築
madoka_magica_imagesをダウンロードしたら、同じ階層にスクリプトを実装しましょう。
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D,Input
from keras.applications.vgg16 import VGG16
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
from keras.callbacks import CSVLogger
n_categories=5
batch_size=32
train_dir='madoka_magica_images/train'
validation_dir='madoka_magica_images/validation'
file_name='vgg16_madomagi_fine'
base_model=VGG16(weights='imagenet',include_top=False,
input_tensor=Input(shape=(224,224,3)))
# add new layers instead of FC networks
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(1024,activation='relu')(x)
prediction=Dense(n_categories,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=prediction)
# fix weights before VGG16 14layers
for layer in base_model.layers[:15]:
layer.trainable=False
model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
VGG16は1000カテゴリを分類するモデルですが、今回は5人のキャラクターなので、n_categories=5です。
base_model=VGG16(weights='imagenet',include_top=False,
input_tensor=Input(shape=(224,224,3)))
ここでVGG16のモデルをインポートします。重みはImageNetを使い、全結合層はいらないので、include_top=Falseにします。
画像は224x224のRGBなのでshape=(224,224,3)
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(1024,activation='relu')(x)
prediction=Dense(n_categories,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=prediction)
さきほどのVGG16のモデルに新しく全結合層を取り付けます。
for layer in base_model.layers[:15]:
layer.trainable=False
14層目までの重みを更新しません。
画像の前処理をして学習
train_datagen=ImageDataGenerator(
rescale=1.0/255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
validation_datagen=ImageDataGenerator(rescale=1.0/255)
train_generator=train_datagen.flow_from_directory(
train_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
validation_generator=validation_datagen.flow_from_directory(
validation_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
hist=model.fit_generator(train_generator,
epochs=200,
verbose=1,
validation_data=validation_generator,
callbacks=[CSVLogger(file_name+'.csv')])
# save weights
model.save(file_name+'.h5')
ImageDataGeneratorは画像を整形したり、水増しするのに便利です。
読み込むフォルダを与えれば、自動的にそのフォルダの名前をラベルにしてくれます。
もっと詳しく知りたい方はこちらの記事が参考になると思います。Kerasによるデータ拡張
結果
test画像でモデルを評価し、画僧を並べて表示します。
from keras.models import model_from_json
import matplotlib.pyplot as plt
import numpy as np
import os,random
from keras.preprocessing.image import img_to_array, load_img
from keras.preprocessing.image import ImageDataGenerator
from keras.optimizers import SGD
batch_size=32
file_name='vgg16_madomagi_fine'
test_dir='madoka_magica_images/test'
display_dir='madoka_magica_images/display'
label=['homura','kyoko','madoka','mami','sayaka']
# load model and weights
json_string=open(file_name+'.json').read()
model=model_from_json(json_string)
model.load_weights(file_name+'.h5')
model.compile(optimizer=SGD(lr=0.0001,momentum=0.9),
loss='categorical_crossentropy',
metrics=['accuracy'])
# data generate
test_datagen=ImageDataGenerator(rescale=1.0/255)
test_generator=test_datagen.flow_from_directory(
test_dir,
target_size=(224,224),
batch_size=batch_size,
class_mode='categorical',
shuffle=True
)
# evaluate model
score=model.evaluate_generator(test_generator)
print('\n test loss:',score[0])
print('\n test_acc:',score[1])
# predict model and display images
files=os.listdir(display_dir)
img=random.sample(files,25)
plt.figure(figsize=(10,10))
for i in range(25):
temp_img=load_img(os.path.join(display_dir,img[i]),target_size=(224,224))
plt.subplot(5,5,i+1)
plt.imshow(temp_img)
#Images normalization
temp_img_array=img_to_array(temp_img)
temp_img_array=temp_img_array.astype('float32')/255.0
temp_img_array=temp_img_array.reshape((1,224,224,3))
#predict image
img_pred=model.predict(temp_img_array)
plt.title(label[np.argmax(img_pred)])
#eliminate xticks,yticks
plt.xticks([]),plt.yticks([])
plt.show()

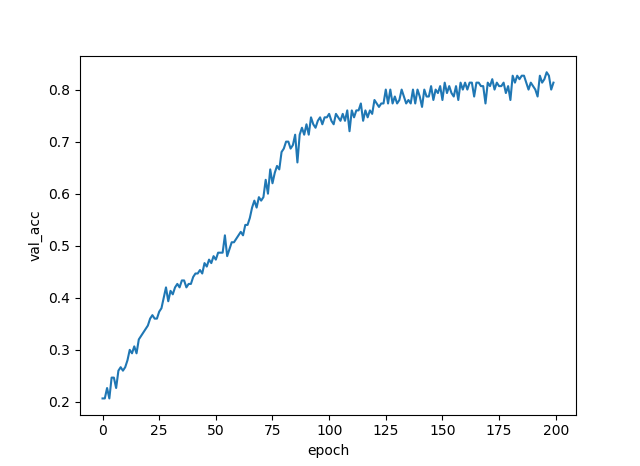

validation_accuracyは最終的に約80%になりました。
test accuracyも約80%。
訓練画像250枚(各キャラ50枚ずつ)、この短時間でこの精度までいくのはやはり転移学習のおかげだと思います。
今回のまどか☆マギカのキャラはImageNetにはない画像なので、VGG16にとっては見たことのない画像です。
それでもここまで精度を上げられたのはImageNetで学習してうまく特徴量を抽出できたおかげでしょう。
参考文献
1.少ない画像から画像分類を学習させる方法(kerasで転移学習:fine tuning)
2.Kerasによるデータ拡張
3.VGG16のFine-tuningによる犬猫認識 (1)
4.VGG16のFine-tuningによる犬猫認識 (2)
5.ImageDataGenerator
6.ModelクラスAPI