BERTは自然言語処理を勉強する上で外せなくなりつつあるモデルです。
理解を深めるために実際に実装してみました。
BERTを試すにあたりKaggleチュートリアルのタイタニックを名前(Name)だけで予測を行います。
タイトルにもある通り予測にNameしか使っていないにもかかわらず正解率が80%を超えたので驚きました。
他のスコアとの比較ですが、女性=生存とした場合の正解率は76.555%(Kaggleのサンプルファイル)、過去の記事(Kaggleのタイタニックに挑戦してみた(その2))ではかなりがんばって77.99%でした。
(私の実力がまだないだけかもしれませんが…)
また、BERTを使わないNameのみからの予測(前回)でのスコアは72.248%です。
・Kaggle関係の記事
Kaggleのタイタニックに挑戦してみた(その1)
Kaggleのタイタニックに挑戦してみた(その2)
Kaggleで書いたコードの備忘録その1~データ分析で使った手法一通り~
Kaggleで書いたコードの備忘録その2~自然言語処理まとめ~
実装コード
0.Nameだけの予測について
Nameだけで予測できるのかについて簡単に話しておきます。
まず生存者の傾向ですが、以下の乗客が生き残る傾向にあります。
・女性や子供
・位が高い人(1stクラスの客室や貴族など)
名前にこれらの情報が含まれていれば十分に予測できることが想定されます。
以下は名前をワードクラウドで表示した結果です。
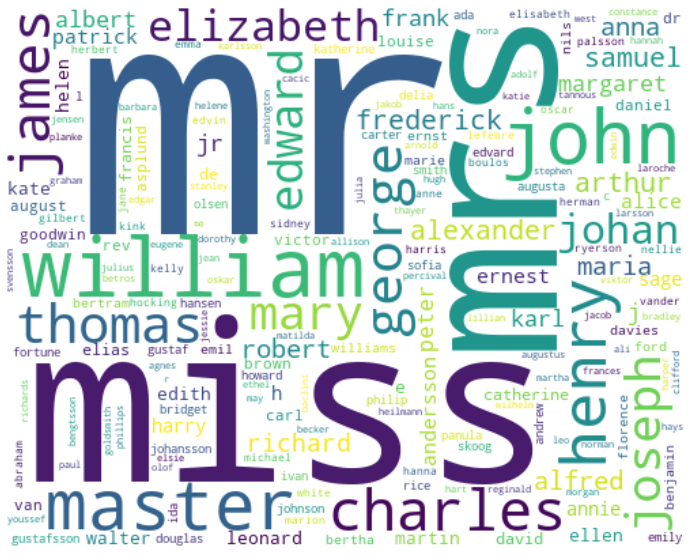
mr(男性)、miss(未婚女性)、master(支配人)など予測に必要な情報は含まれていそうです。
1.データ読み込み
google colab のドライブにマウントして読み込むコード例を記載しておきます。
from google.colab import drive, files
drive.mount('/content/drive') # drive をマウント
# 保存ディレクトリ
BASE_DIR = "/content/drive/MyDrive/kaggle/Titanic"
DATA_PATH = os.path.join(BASE_DIR, "data") # 対象データの保存ディレクトリ
MODEL_PATH = os.path.join(BASE_DIR, "model") # モデルを保存するディレクトリ
# ディレクトリがなければ作成
os.makedirs(MODEL_PATH, exist_ok=True)
タイタニックのデータは"DATA_PATH"配下にある想定です。
# import
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import time
from tqdm import tqdm
# from tqdm.notebook import tqdm # notebookの場合
from pprint import pprint
# データ読み込み
df_train = pd.read_csv(os.path.join(DATA_PATH, "train.csv"))
df_test = pd.read_csv(os.path.join(DATA_PATH, "test.csv"))
target_column = "Survived"
# データをマージ
df_test[target_column] = np.nan
df = pd.concat([df_train, df_test], ignore_index=True, sort=False)
print(df_train.shape)
print(df_test.shape)
print(df.shape)
print(df.columns)
(891, 12)
(418, 12)
(1309, 12)
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],
dtype='object')
2.前処理
BERTは前処理も含めて実装されているため基本は前処理の必要はありません。
ただ今回は記号だけ気になったので、余分な情報として事前に除外しておきます。
def str_normalize(ds):
# アルファベットと数字のみにする
ds = ds.str.replace("[^a-zA-Z0-9]+", " ", regex=True)
return ds
df["Name_normalize"] = str_normalize(df["Name"])
3.BERT
BERTはディープラーニングを利用した自然言語処理モデルです。
以下の動画が参考になりました。
参考:【深層学習】BERT - 実務家必修。実務で超応用されまくっている自然言語処理モデル【ディープラーニングの世界vol.32】#110 #VRアカデミア #DeepLearning
BERT自体はクラス分類以外のタスクにも使えますが、今回はクラス分類に限った実装を行います。
使用するライブラリは transformers/tensorflow2.0 を使います。
3-1.import関係
!pip install -q transformers
!pip install -q silence_tensorflow
# tensorflow のログが多いので silence_tensorflow を入れています
from silence_tensorflow import silence_tensorflow
silence_tensorflow()
# tensorflow
import tensorflow as tf
import tensorflow.keras.layers as kl
# transformers
import transformers
# transformerのログをエラー以上のみに
from transformers import logging
logging.set_verbosity_error()
3-2.学習済みモデルの選択
公開されている学習済みモデルは以下から検索できます。
・[transformers Docs] Pretrained models
・huggingface
casedが小文字大文字を区別し、uncasedが小文字のみとなります。
今回はドキュメントの一番上にあるの小文字のみモデルを採用しています。
pretrained_model_name = "bert-base-uncased"
以下でモデルを実際にダウンロードして使えるかどうか確認できます。
tokenizer = transformers.AutoTokenizer.from_pretrained(pretrained_model_name)
bert_model = transformers.TFAutoModel.from_pretrained(pretrained_model_name)
# bert_model = transformers.TFAutoModel.from_pretrained(pretrained_model_name, from_pt=True) # ※(1)
print(bert_model.config)
BertConfig {
"_name_or_path": "bert-base-uncased",
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"transformers_version": "4.6.1",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 30522
}
※(1)
何も指定しないとtensorflowのモデルを読み込みます。(ファイルで言うと tf_model.h5)
from_py=Trueを有効にするとpytouchのモデルを読み込みます。(ファイルで言うと pytorch_model.bin)
どちらのファイルがあるかは学習済みモデルの Files and versions から確認できます。
tokenizer の動作について
tokenizer が前処理を担当しています。
どういった処理をしているか見てみます。
tokenizerに与える引数は以下に説明があります。
Everything you always wanted to know about padding and truncation
# 適当に名前の情報を使ってみてみる
sample_name = df["Name"][0]
print(sample_name)
# Tokenizeした結果
token_words = tokenizer.tokenize(sample_name)
print(token_words)
# BERTに入力する形式に変換
encode_token = tokenizer(sample_name, padding="max_length", max_length=12, truncation=True)
pprint(encode_token)
# BERTへの入力形式をデコードした結果
print(tokenizer.decode(encode_token["input_ids"]))
# オリジナル文字列
Braund, Mr. Owen Harris
# Tokenizeした結果
['braun', '##d', ',', 'mr', '.', 'owen', 'harris']
# BERTの入力形式
{'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
'input_ids': [101, 21909, 2094, 1010, 2720, 1012, 7291, 5671, 102, 0, 0, 0],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}
# BERTへの入力形式をデコードした結果
[CLS] braund, mr. owen harris [SEP] [PAD] [PAD] [PAD]
3-3.入力単語数の確認
BERTに入力する単語数はハイパーパラメータで、最大512単語です。
(事前学習のサイズが512っぽいです)
参考:(自然言語処理モデル(BERT)を利用した日本語の文章分類 〜GoogleColab & Pytorchによるファインチューニング〜
Nameの最大単語数が何かを求めてハイパーパラメータを設定します。
# 最大単語数の確認
max_len = []
# 1文づつ処理
for sent in df["Name_normalize"]:
# Tokenizeで分割
token_words = tokenizer.tokenize(sent)
# 文章数を取得してリストへ格納
max_len.append(len(token_words))
# 最大の値を確認
print('最大単語数: ', max(max_len))
print('上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数')
# 単語数を設定
sequence_max_length = max(max_len) + 2
if sequence_max_length > 512:
sequence_max_length = 512
最大単語数: 20
上記の最大単語数にSpecial token([CLS], [SEP])の+2をした値が最大単語数
3-4. BERTモデルの作成
BERTモデルを作成します。
モデルですがタスクによりいくつか用意されているようです。
例えばクラス分類ですとTFBertForSequenceClassificationです。
ただ、いろいろ応用できそうなTFBertModelを元に作成します。
def build_model(learning_rate, is_print=False):
# BERTモデルをロード
bert_model = transformers.TFAutoModel.from_pretrained(pretrained_model_name)
#bert_model = transformers.TFAutoModel.from_pretrained(pretrained_model_name, from_pt=True) # pytorchの場合
# tfへの入力テンソルを作成
# 入力はsequence_max_lengthサイズを3つ(['input_ids', 'token_type_ids', 'attention_mask'])
inputs = [
kl.Input(shape=(sequence_max_length,), dtype=tf.int32, name=name)
for name in tokenizer.model_input_names
]
if is_print:
pprint(inputs)
# BERTモデルの出力を得る
# 出力は TFBaseModelOutputWithPooling (https://huggingface.co/transformers/main_classes/output.html#tfbasemodeloutput)
# x[0](last_hidden_state) : 最後のレイヤーの出力
# x[1](pooler_output) : 分類トークンの状態
x = bert_model(inputs)
# BERT出力の0番目がクラス分類で使う出力
x1 = x[0][:, 0, :]
# 分類用の出力層を用意
# 出力層の構成はTFBertForSequenceClassificationを参考
x1 = kl.Dropout(0.1)(x1)
x1 = kl.Dense(1, activation='sigmoid', kernel_initializer=transformers.modeling_tf_utils.get_initializer(0.02))(x1)
model_train = tf.keras.Model(inputs=inputs, outputs=x1)
# オリジナルの出力値を特徴量としたいので予測専用のモデルも別途作っておく
model_pred = tf.keras.Model(inputs=inputs, outputs=[x1, x[0][:, 0, :]])
# optimizerは AdamW を使用
optimizer = transformers.AdamWeightDecay(learning_rate=learning_rate)
model_train.compile(optimizer, loss="binary_crossentropy", metrics=["acc"])
#model_train.compile(optimizer, loss="categorical_crossentropy", metrics=["acc"]) # softmaxの場合
if is_print:
print(model_train.summary())
return model_train, model_pred
# 試しに実行
build_model(0.1, is_print=True)
[<KerasTensor: shape=(None, 22) dtype=int32 (created by layer 'input_ids')>,
<KerasTensor: shape=(None, 22) dtype=int32 (created by layer 'token_type_ids')>,
<KerasTensor: shape=(None, 22) dtype=int32 (created by layer 'attention_mask')>]
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_ids (InputLayer) [(None, 22)] 0
__________________________________________________________________________________________________
token_type_ids (InputLayer) [(None, 22)] 0
__________________________________________________________________________________________________
attention_mask (InputLayer) [(None, 22)] 0
__________________________________________________________________________________________________
tf_bert_model_4 (TFBertModel) TFBaseModelOutputWit 109482240 input_ids[0][0]
token_type_ids[0][0]
attention_mask[0][0]
__________________________________________________________________________________________________
tf.__operators__.getitem_1 (Sli (None, 768) 0 tf_bert_model_4[0][0]
__________________________________________________________________________________________________
dropout_186 (Dropout) (None, 768) 0 tf.__operators__.getitem_1[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 1) 769 dropout_186[0][0]
==================================================================================================
Total params: 109,483,009
Trainable params: 109,483,009
Non-trainable params: 0
__________________________________________________________________________________________________
3-5. BERTの学習(ファインチューニング)
TPU
BERTはモデルがかなり大きく学習に時間がかかります。
Google Colaboratory では TPU が使えるので使うためのコードを書いておきます。
import tensorflow as tf
import os
runtime_type = ""
try:
if "COLAB_TPU_ADDR" in os.environ:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver('grpc://' + os.environ['COLAB_TPU_ADDR'])
else:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
#--- TPU
print('Running on TPU ', resolver.cluster_spec().as_dict()['worker'])
runtime_type = "TPU"
# This is the TPU initialization code that has to be at the beginning.
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
tpu_strategy = tf.distribute.TPUStrategy(resolver)
tf.keras.backend.clear_session()
print("All devices: ", tf.config.list_logical_devices('TPU'))
except ValueError:
if tf.test.gpu_device_name() != "":
#--- GPU
runtime_type = "GPU"
else:
runtime_type = "CPU"
print("runtime_type: ", runtime_type)
さらにTPUではモデルを作成する時に上記で作成した tpu_strategy を使う必要があります。
if runtime_type == "TPU":
# TPU はモデル作成に tpu_strategy.scope で囲む
with tpu_strategy.scope():
model_train, model_pred = build_model(learning_rate)
else:
model_train, model_pred = build_model(learning_rate)
学習コード
ファインチューニングですが、以下の記事を参考に学習パラメータを設定しています。
参考:BERTのfine-tuning不安定性はどのように解決できるか?
ポイントは、
・epochsは20
・学習率は、最初の10%epochは0.00002まで増加、以降は0に減少
です。
また、学習に時間がかかるので一度学習したモデルはファイルに保存するコードにしています。
import sklearn.metrics
def train_bert(
df_train, # 学習用のデータ
text_column, # 対象のカラム名
target_column, # 目的変数のカラム名
df_valid=None, # 検証用データ
df_pred_list=[], # 予測用データ
model_file_prefix="", # 保存時のファイル名識別子
epochs=20,
batch_size=8,
):
#--------------------
# 学習率
#--------------------
lr0 = 0.000005
learning_rate = [
0.00001,
0.00002,
]
if epochs-len(learning_rate) > 0:
lr_list = np.linspace(0.00002, 0, epochs-len(learning_rate))
learning_rate.extend(lr_list)
def lr_scheduler(epoch):
return learning_rate[epoch]
lr_callback = tf.keras.callbacks.LearningRateScheduler(lr_scheduler)
#--------------------
# file
#--------------------
model_path = "{}_{}.h5".format(
model_file_prefix,
pretrained_model_name,
)
#--------------------
# モデル
#--------------------
if runtime_type == "TPU":
with tpu_strategy.scope():
model_train, model_pred = build_model(lr0)
else:
model_train, model_pred = build_model(lr0)
#-----------------------------
# モデル入出力用のデータ作成関数
#-----------------------------
def _build_x_from_df(df):
# Series -> list
x = df[text_column].tolist()
# tokenize
x = tokenizer(x, padding="max_length", max_length=sequence_max_length,
truncation=True, return_tensors="tf")
# BatchEncoding -> dict
return dict(x)
def _build_y_from_df(df):
return df[target_column]
#return tf.keras.utils.to_categorical(df[target_column], num_classes=2) # softmax用
#-------------------
# valid用のdatasetを作成
#-------------------
if df_valid is not None:
valid_x = _build_x_from_df(df_valid)
valid_y = _build_y_from_df(df_valid)
valid_dataset = (
tf.data.Dataset.from_tensor_slices((valid_x, valid_y))
.batch(batch_size)
.cache()
)
else:
valid_dataset = None
#-------------------
# 学習
#-------------------
if os.path.isfile(model_path):
# 学習済みモデルをload
print(model_path)
model_train.load_weights(model_path)
else:
train_x = _build_x_from_df(df_train)
train_y = _build_y_from_df(df_train)
train_dataset = (
tf.data.Dataset.from_tensor_slices((train_x, train_y))
.shuffle(len(train_x), seed=1234)
.batch(batch_size)
.prefetch(tf.data.experimental.AUTOTUNE) # GPUが計算している間にBatchデータをCPU側で用意しておく機能
)
model_train.fit(train_dataset, epochs=epochs, validation_data=valid_dataset, callbacks=[lr_callback])
model_train.save_weights(model_path)
#-------------------
# 評価
#-------------------
if df_valid is not None:
print("valid")
pred_y = model_train.predict(valid_dataset, verbose=1)
# 正解率
pred_y_label = np.where(pred_y < 0.5, 0, 1)
metric = sklearn.metrics.accuracy_score(valid_y, pred_y_label)
print("acc", metric)
else:
metric = 0
#-------------------
# 予測
#-------------------
print("pred")
pred_y_list = []
emb_list = []
for df_pred in df_pred_list:
pred_x = _build_x_from_df(df_pred)
pred_dataset = (
tf.data.Dataset.from_tensor_slices((pred_x,))
.batch(batch_size)
.cache()
)
# 予測
pred_output = model_pred.predict(pred_dataset, verbose=1)
# pred
pred_y = pred_output[0].reshape((-1,)) # (-1,1) -> (-1)
#pred_y = pred_y[0][:,1] # softmax用
pred_y_list.append(pred_y)
# emb
emb_list.append(pred_output[1])
return metric, pred_y_list, emb_list
# --- 実行例
metric, pred_y_list, emb_list = train_bert(
df_train=df[df["Survived"].notnull()][:10], # 学習データ
text_column="Name_normalize",
target_column="Survived",
df_valid=df[df["Survived"].notnull()][:10], # 検証データ(仮で学習データと同じ)
df_pred_list=[df[df["Survived"].isnull()][:10]], # 予測データ
epochs=2, # 試しなので少な目
)
print(metric)
print(pred_y_list[0].shape)
print(emb_list[0].shape)
Epoch 1/2
2/2 [==============================] - 31s 6s/step - loss: 0.6952 - acc: 0.4333 - val_loss: 0.6520 - val_acc: 0.8000
Epoch 2/2
2/2 [==============================] - 4s 2s/step - loss: 0.6455 - acc: 0.7167 - val_loss: 0.6547 - val_acc: 0.5000
valid
2/2 [==============================] - 4s 160ms/step
acc 0.5
pred
2/2 [==============================] - 4s 164ms/step
0.5
(10,)
(10, 768)
4.BERTモデルから予測結果と特徴量を取得する
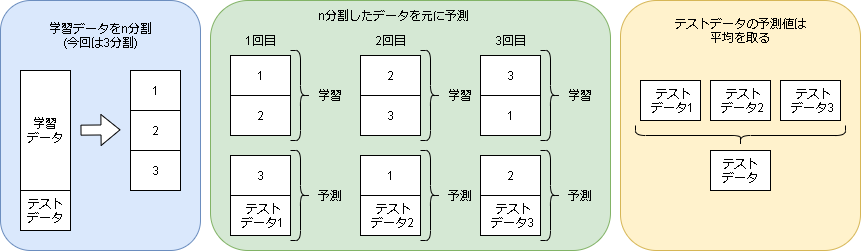
クロスバリデーションで全予測結果と特徴量を取得します。
イメージは以下です。(前記事と同じ図です)
import sklearn.model_selection
def train_cv(df, text_column, target_column, n_splits):
df_train = df[df[target_column].notnull()]
df_test = df[df[target_column].isnull()]
df_train_idx = df_train.index
# 結果用
df_pred = pd.DataFrame(df.index, columns=["index"]).set_index("index")
df_emb = pd.DataFrame(df.index, columns=["index"]).set_index("index")
df_emb_pred = None
metric_list = []
#----------------
# cross validation
#----------------
kf = sklearn.model_selection.StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=1234)
for i, (train_idx, test_idx) in enumerate(kf.split(df_train, df_train[target_column])):
df_train_sub = df_train.iloc[train_idx]
df_test_sub = df_train.iloc[test_idx]
df_pred_list = [df_test_sub]
df_pred_list.append(df_test)
model_file_prefix = "cv_{}".format(i)
# train
metric, pred_y_list, emb_list = train_bert(
df_train=df_train_sub,
text_column=text_column,
target_column=target_column,
df_valid=df_test_sub,
df_pred_list=df_pred_list,
model_file_prefix=model_file_prefix,
)
metric_list.append(metric)
# 予測結果を保存
result_name = "result_{}".format(i)
df_pred.loc[df_train_idx[test_idx], result_name] = pred_y_list[0]
df_pred.loc[df_test.index, result_name] = pred_y_list[1]
#---------
a = pd.DataFrame(emb_list[0], index=df_train_idx[test_idx])
df_emb = df_emb.combine_first(a)
if df_emb_pred is None:
df_emb_pred = pd.DataFrame(emb_list[1], index=df_test.index)
else:
df_emb_pred += emb_list[1]
pred_y = df_pred.mean(axis=1)
df_emb_pred /= n_splits
df_emb = df_emb.combine_first(df_emb_pred)
return np.mean(metric_list), pred_y.values, df_emb
# --- 結果と特徴量を取得
metric, pred_y, df_emb = train_cv(df, "Name_normalize", "Survived", n_splits=3)
print(metric)
print(pred_y.shape)
print(df_emb.shape)
**実行結果 クリックで展開**
Epoch 1/20
75/75 [==============================] - 72s 168ms/step - loss: 0.6232 - acc: 0.6738 - val_loss: 0.4911 - val_acc: 0.7845
Epoch 2/20
75/75 [==============================] - 5s 66ms/step - loss: 0.5015 - acc: 0.7881 - val_loss: 0.4903 - val_acc: 0.8249
Epoch 3/20
75/75 [==============================] - 5s 67ms/step - loss: 0.4287 - acc: 0.8344 - val_loss: 0.5410 - val_acc: 0.8081
Epoch 4/20
75/75 [==============================] - 5s 66ms/step - loss: 0.3543 - acc: 0.8761 - val_loss: 0.5543 - val_acc: 0.7980
Epoch 5/20
75/75 [==============================] - 5s 67ms/step - loss: 0.2457 - acc: 0.9094 - val_loss: 0.6346 - val_acc: 0.7946
Epoch 6/20
75/75 [==============================] - 5s 67ms/step - loss: 0.1725 - acc: 0.9361 - val_loss: 0.7133 - val_acc: 0.7845
Epoch 7/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0832 - acc: 0.9732 - val_loss: 0.9226 - val_acc: 0.7778
Epoch 8/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0563 - acc: 0.9798 - val_loss: 0.9967 - val_acc: 0.7980
Epoch 9/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0291 - acc: 0.9932 - val_loss: 0.9987 - val_acc: 0.7946
Epoch 10/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0238 - acc: 0.9928 - val_loss: 0.9397 - val_acc: 0.7912
Epoch 11/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0462 - acc: 0.9900 - val_loss: 0.9016 - val_acc: 0.7845
Epoch 12/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0156 - acc: 0.9957 - val_loss: 0.9964 - val_acc: 0.7744
Epoch 13/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0190 - acc: 0.9949 - val_loss: 1.0513 - val_acc: 0.7744
Epoch 14/20
75/75 [==============================] - 6s 76ms/step - loss: 0.0115 - acc: 0.9975 - val_loss: 1.0042 - val_acc: 0.8013
Epoch 15/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0063 - acc: 1.0000 - val_loss: 1.0379 - val_acc: 0.8047
Epoch 16/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0117 - acc: 0.9966 - val_loss: 1.0797 - val_acc: 0.7980
Epoch 17/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0066 - acc: 1.0000 - val_loss: 1.0950 - val_acc: 0.7912
Epoch 18/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0040 - acc: 1.0000 - val_loss: 1.1076 - val_acc: 0.7946
Epoch 19/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0044 - acc: 1.0000 - val_loss: 1.1138 - val_acc: 0.7946
Epoch 20/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0045 - acc: 1.0000 - val_loss: 1.1138 - val_acc: 0.7946
valid
38/38 [==============================] - 8s 105ms/step
acc 0.7946127946127947
pred
38/38 [==============================] - 8s 107ms/step
53/53 [==============================] - 2s 13ms/step
Epoch 1/20
75/75 [==============================] - 72s 163ms/step - loss: 0.6437 - acc: 0.6153 - val_loss: 0.4935 - val_acc: 0.7879
Epoch 2/20
75/75 [==============================] - 5s 66ms/step - loss: 0.5036 - acc: 0.7832 - val_loss: 0.4796 - val_acc: 0.8013
Epoch 3/20
75/75 [==============================] - 5s 73ms/step - loss: 0.4667 - acc: 0.8191 - val_loss: 0.5475 - val_acc: 0.7778
Epoch 4/20
75/75 [==============================] - 5s 67ms/step - loss: 0.4285 - acc: 0.8395 - val_loss: 0.5287 - val_acc: 0.8047
Epoch 5/20
75/75 [==============================] - 5s 66ms/step - loss: 0.3448 - acc: 0.8785 - val_loss: 0.5742 - val_acc: 0.8114
Epoch 6/20
75/75 [==============================] - 5s 66ms/step - loss: 0.2957 - acc: 0.8997 - val_loss: 0.6470 - val_acc: 0.8114
Epoch 7/20
75/75 [==============================] - 5s 68ms/step - loss: 0.2138 - acc: 0.9410 - val_loss: 0.6874 - val_acc: 0.8182
Epoch 8/20
75/75 [==============================] - 5s 67ms/step - loss: 0.2018 - acc: 0.9291 - val_loss: 0.6803 - val_acc: 0.7980
Epoch 9/20
75/75 [==============================] - 5s 68ms/step - loss: 0.1191 - acc: 0.9639 - val_loss: 0.7696 - val_acc: 0.8047
Epoch 10/20
75/75 [==============================] - 5s 68ms/step - loss: 0.0709 - acc: 0.9831 - val_loss: 0.7891 - val_acc: 0.8081
Epoch 11/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0470 - acc: 0.9802 - val_loss: 0.8624 - val_acc: 0.8148
Epoch 12/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0310 - acc: 0.9939 - val_loss: 0.9067 - val_acc: 0.8148
Epoch 13/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0127 - acc: 0.9943 - val_loss: 0.9453 - val_acc: 0.8215
Epoch 14/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0236 - acc: 0.9903 - val_loss: 0.9734 - val_acc: 0.8047
Epoch 15/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0089 - acc: 0.9999 - val_loss: 1.0278 - val_acc: 0.7879
Epoch 16/20
75/75 [==============================] - 6s 78ms/step - loss: 0.0133 - acc: 0.9946 - val_loss: 1.0168 - val_acc: 0.7912
Epoch 17/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0057 - acc: 0.9993 - val_loss: 1.0603 - val_acc: 0.8114
Epoch 18/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0045 - acc: 1.0000 - val_loss: 1.0189 - val_acc: 0.8283
Epoch 19/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0063 - acc: 1.0000 - val_loss: 1.0131 - val_acc: 0.8215
Epoch 20/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0035 - acc: 1.0000 - val_loss: 1.0131 - val_acc: 0.8215
valid
38/38 [==============================] - 8s 107ms/step
acc 0.8215488215488216
pred
38/38 [==============================] - 8s 105ms/step
53/53 [==============================] - 1s 14ms/step
Epoch 1/20
75/75 [==============================] - 72s 169ms/step - loss: 0.6213 - acc: 0.6627 - val_loss: 0.5171 - val_acc: 0.7845
Epoch 2/20
75/75 [==============================] - 5s 66ms/step - loss: 0.4798 - acc: 0.7928 - val_loss: 0.5462 - val_acc: 0.7643
Epoch 3/20
75/75 [==============================] - 5s 66ms/step - loss: 0.4163 - acc: 0.8262 - val_loss: 0.5584 - val_acc: 0.7845
Epoch 4/20
75/75 [==============================] - 5s 69ms/step - loss: 0.3644 - acc: 0.8592 - val_loss: 0.5975 - val_acc: 0.7677
Epoch 5/20
75/75 [==============================] - 5s 69ms/step - loss: 0.2189 - acc: 0.9272 - val_loss: 0.6186 - val_acc: 0.8013
Epoch 6/20
75/75 [==============================] - 5s 70ms/step - loss: 0.1510 - acc: 0.9555 - val_loss: 0.6811 - val_acc: 0.7609
Epoch 7/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0933 - acc: 0.9778 - val_loss: 0.8140 - val_acc: 0.7475
Epoch 8/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0695 - acc: 0.9865 - val_loss: 0.7720 - val_acc: 0.7912
Epoch 9/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0419 - acc: 0.9886 - val_loss: 0.9185 - val_acc: 0.7677
Epoch 10/20
75/75 [==============================] - 6s 78ms/step - loss: 0.0256 - acc: 0.9931 - val_loss: 0.8664 - val_acc: 0.7744
Epoch 11/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0185 - acc: 0.9974 - val_loss: 0.8704 - val_acc: 0.7744
Epoch 12/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0174 - acc: 0.9965 - val_loss: 0.9173 - val_acc: 0.8047
Epoch 13/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0065 - acc: 1.0000 - val_loss: 1.0711 - val_acc: 0.7744
Epoch 14/20
75/75 [==============================] - 5s 68ms/step - loss: 0.0122 - acc: 0.9954 - val_loss: 1.0262 - val_acc: 0.7879
Epoch 15/20
75/75 [==============================] - 5s 68ms/step - loss: 0.0048 - acc: 1.0000 - val_loss: 1.0226 - val_acc: 0.8013
Epoch 16/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0031 - acc: 1.0000 - val_loss: 1.0460 - val_acc: 0.7946
Epoch 17/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0032 - acc: 1.0000 - val_loss: 1.0550 - val_acc: 0.8047
Epoch 18/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0026 - acc: 1.0000 - val_loss: 1.0651 - val_acc: 0.8047
Epoch 19/20
75/75 [==============================] - 5s 66ms/step - loss: 0.0022 - acc: 1.0000 - val_loss: 1.0694 - val_acc: 0.8013
Epoch 20/20
75/75 [==============================] - 5s 67ms/step - loss: 0.0023 - acc: 1.0000 - val_loss: 1.0694 - val_acc: 0.8013
valid
38/38 [==============================] - 9s 113ms/step
acc 0.8013468013468014
pred
38/38 [==============================] - 8s 108ms/step
53/53 [==============================] - 1s 13ms/step
0.8058361391694726
(1309,)
(1309, 768)
4-1.予測結果を出力
df["BERT"] = pred_y
df["BERT_label"] = np.where(pred_y < 0.5, 0, 1)
# 学習データの正解率
_df = df[df["Survived"].notnull()]
print(sklearn.metrics.accuracy_score(_df["Survived"], _df["BERT_label"]))
# 予測結果をcsvで出力
_df = df[df["Survived"].isnull()]
df_submit = pd.DataFrame()
df_submit["PassengerId"] = _df["PassengerId"]
df_submit["Survived"] = _df["BERT_label"]
df_submit.to_csv('submit1.csv', header=True, index=False)
# 検証結果
0.8024691358024691
- 提出スコア
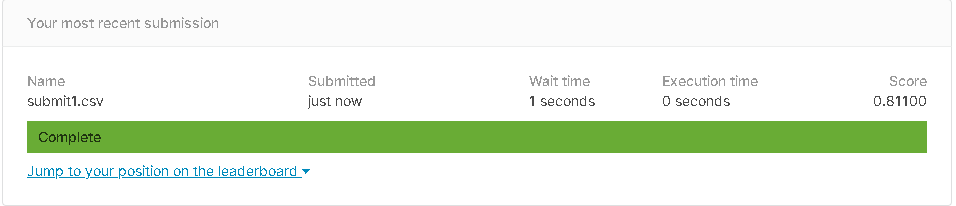
正解率81.1%です。
4-2.特徴量を元にAutoMLで予測
import pycaret.classification as pcc
# pycaret にデータを渡す
df_emb["Survived"] = df["Survived"]
r = pcc.setup(df_emb[df["Survived"].notnull()], target="Survived", silent=True, session_id=1234)
# モデルを比較
best_models = pcc.compare_models(n_select=3)
# --- 比較した結果(Acc) ---
# knn : 0.8090
# catboost: 0.8057
# lightgbm: 0.8009
# モデルのパラメータをチューニング
models = []
models.append(pcc.tune_model(best_models[0])) # acc: 0.8074
models.append(pcc.tune_model(best_models[1])) # acc: 0.8057
models.append(pcc.tune_model(best_models[2])) # acc: 0.7977
# モデルをブレンドしてチューニング
blend_model = pcc.blend_models(models)
tuned_model = pcc.tune_model(blend_model) # acc: 0.8089
# チューニング後のパラメータを表示
pcc.plot_model(tuned_model, plot='parameter')
# モデルを検証
pcc.predict_model(tuned_model) # acc: 0.8284
# 予測
x_pred = df_emb[df_emb["Survived"].isnull()]
df_pred = pcc.predict_model(tuned_model, data=x_pred)
# 予測結果をcsvで出力
df_submit = pd.DataFrame()
df_submit["PassengerId"] = df[df["Survived"].isnull()]["PassengerId"]
df_submit["Survived"] = df_pred["Label"].apply(lambda x:int(float(x)))
df_submit.to_csv('submit2.csv', header=True, index=False)
- 提出スコア
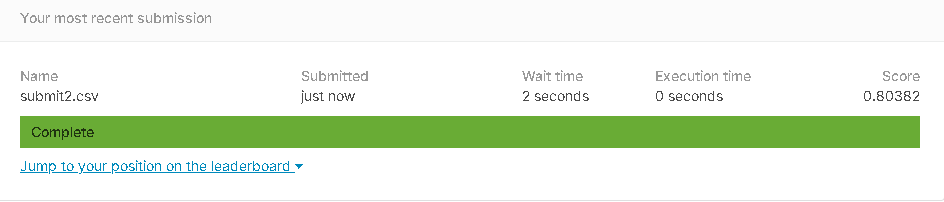
正解率80.382%です。
AutoMLで予測させたら少し下がっちゃいましたね。