初心者ながらKaggleに挑戦した時のコードを備忘録として残しておきます。
今回は自然言語編です。
また、BERT編を別記事にする予定です。
・Kaggle関係の記事
Kaggleのタイタニックに挑戦してみた(その1)
Kaggleのタイタニックに挑戦してみた(その2)
Kaggleで書いたコードの備忘録~データ分析で使った手法一通り~
Kaggleで書いたコードの備忘録その2(ここ)
KaggleタイタニックでNameだけで予測精度80%超えた話(BERT)
作成したコード
1.データ
Kaggleチュートリアルのタイタニックを使います。
# import
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
import time
from tqdm import tqdm
# from tqdm.notebook import tqdm # notebook用
from pprint import pprint
# データ読み込み
df_train = pd.read_csv("/kaggle/input/titanic/train.csv")
df_test = pd.read_csv("/kaggle/input/titanic/test.csv")
# データをマージ
df_test["Survived"] = np.nan
df = pd.concat([df_train, df_test], ignore_index=True, sort=False)
print(df.columns)
# ['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',
# 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked']
自然言語処理という事で、NameからSurvived(生存率)を予測します。
2.自然言語処理の前処理
2-1(1).文字の表記ゆれを直したい
def str_normalize(ds):
# 文字コードの正規化(Unicode正規化)
ds = ds.str.normalize("NFKC")
# 小文字化
ds = ds.apply(lambda x: x.lower())
# 特定の単語を置換
#ds = ds.str.replace("n't", " not")
# 改行を除去
ds = ds.str.replace("\r\n", " ")
ds = ds.str.replace("\n", " ")
ds = ds.str.replace("\r", " ")
ds = ds.str.replace("\u3000", " ") # 全角スペース
# アルファベットと数字のみにする
ds = ds.str.replace("[^a-zA-Z0-9]+", " ", regex=True)
# 数字を全部0にする
#ds = ds.str.replace("[0-9]+", "0", regex=True)
# 前後の空白を削除
ds = ds.apply(lambda x: x.strip())
return ds
df["Name_normalize"] = str_normalize(df["Name"])
print(df[["Name", 'Name_normalize']][:3].T)
0 \
Name Braund, Mr. Owen Harris
Name_normalize braund mr owen harris
1 \
Name Cumings, Mrs. John Bradley (Florence Briggs Th...
Name_normalize cumings mrs john bradley florence briggs thayer
2
Name Heikkinen, Miss. Laina
Name_normalize heikkinen miss laina
2-1(2).前処理(texthero編)
textheroはまだ日本語には対応していないようですが、かなり簡単に前処理ができます。
公式:https://texthero.org/
import texthero as hero
# pipelineの引数は省略時のデフォルトと同じです
df['Name_clean'] = hero.clean(df['Name'], pipeline=[
hero.preprocessing.fillna,
hero.preprocessing.lowercase,
hero.preprocessing.remove_digits,
hero.preprocessing.remove_punctuation,
hero.preprocessing.remove_diacritics,
hero.preprocessing.remove_stopwords,
hero.preprocessing.remove_whitespace,
])
print(df[["Name", 'Name_clean']][:3].T)
0 \
Name Braund, Mr. Owen Harris
Name_clean braund mr owen harris
1 \
Name Cumings, Mrs. John Bradley (Florence Briggs Th...
Name_clean cumings mrs john bradley florence briggs thayer
2
Name Heikkinen, Miss. Laina
Name_clean heikkinen miss laina
ワードクラウドを表示したい
hero.visualization.wordcloud(df["Name_clean"], colormap='viridis',
width=500, height=400, background_color='White')
plt.show()
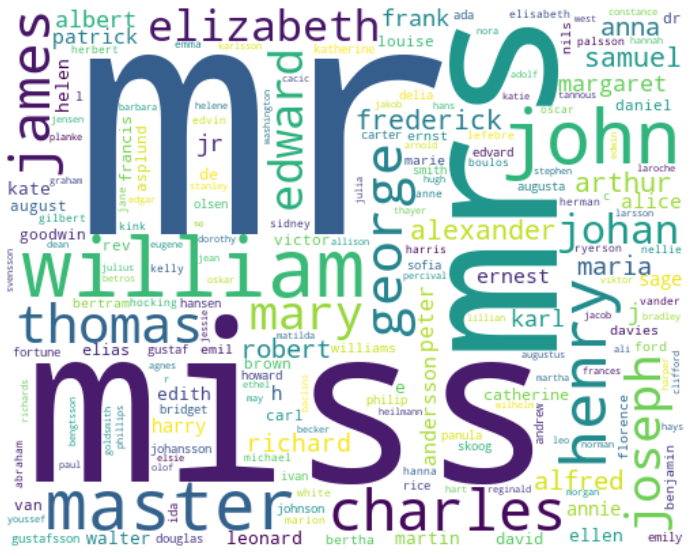
単語の出現頻度を見たい
ds_top_words = hero.top_words(df['Name_clean'])
# 高頻度TOP5
print(ds_top_words[:5])
# 低頻度TOP5
print(ds_top_words[-5:])
# 出現数が1の単語のリスト
low_words = ds_top_words[ds_top_words < 2].keys().tolist()
print(low_words[:5])
mr 763
miss 260
mrs 201
william 87
john 72
Name: Name_clean, dtype: int64
fahim 1
leeni 1
sharp 1
pentcho 1
sivertsen 1
Name: Name_clean, dtype: int64
['wizosky', 'cerin', 'kiamie', 'najib', 'balkic']
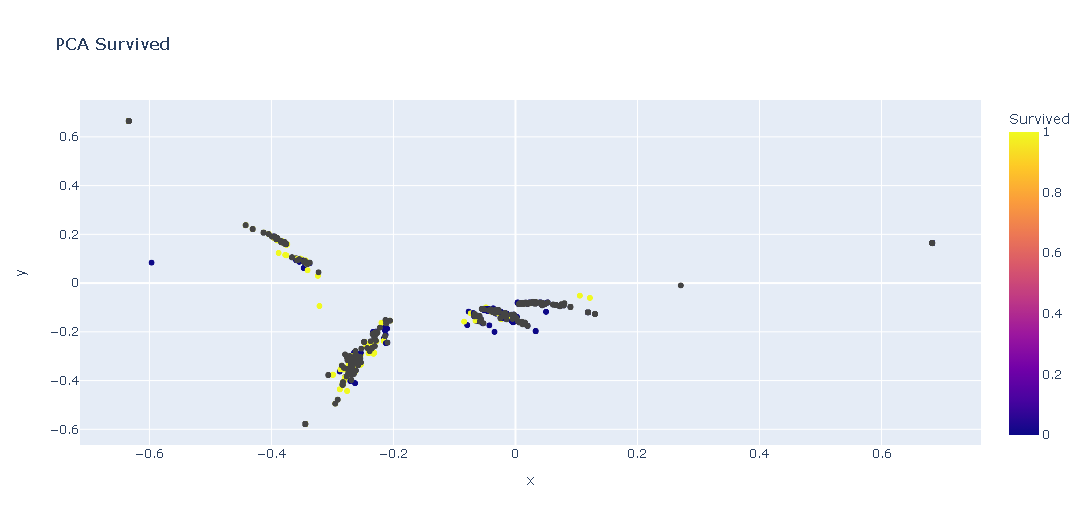
テキストの傾向を散布図で表示したい(PCAとt-SNE)
target_column = "Survived"
_df = pd.DataFrame()
_df[target_column] = df[target_column]
# textをベクトル化
_df["tfidf"] = hero.tfidf(df["Name_clean"], max_features=100)
# PCA
_df["pca"] = hero.pca(_df['tfidf'])
hero.scatterplot(
_df,
col='pca',
color=target_column,
title="PCA " + target_column
)
plt.show()
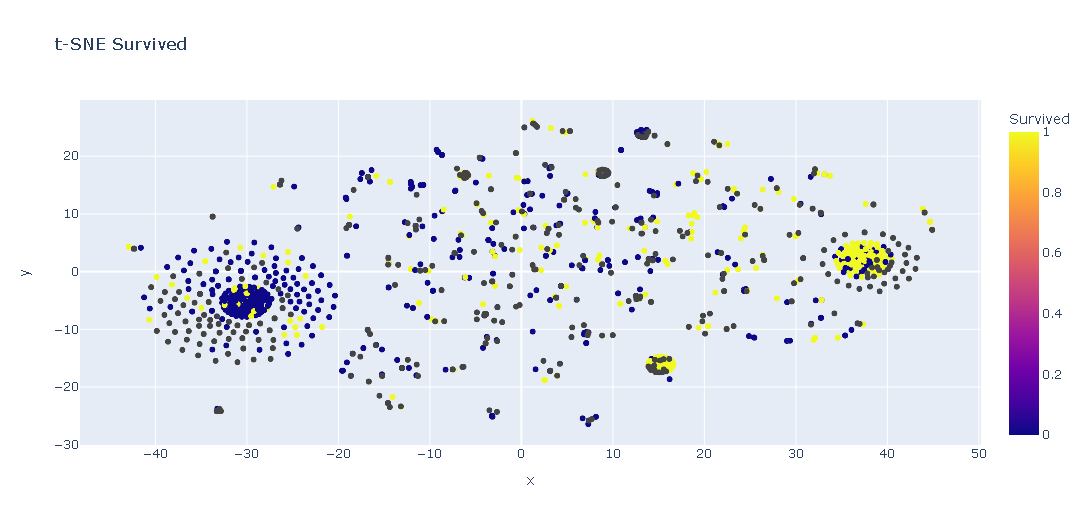
# t-SNE
_df["tsne"] = hero.tsne(_df['tfidf'])
hero.scatterplot(
_df,
col='tsne',
color=target_column,
title="t-SNE " + target_column
)
plt.show()
2-2(1).形態素解析(英語)
NLTKを使っています。
import nltk
nltk.download('punkt') # 分かち書き(word_tokenize)
nltk.download('averaged_perceptron_tagger') # 品詞(pos_tag)
nltk.download('stopwords')
nltk.download('wordnet')
lemmatizer = nltk.stem.WordNetLemmatizer() # 見出し語
stemmer = nltk.stem.PorterStemmer() # 語幹化
stopwords = nltk.corpus.stopwords.words('english') #stopword
stopwords_dict = {k:1 for k in stopwords}
# --- 形態素解析用の関数
def _morphological_analysis(text):
words = []
# 単語に分解
morph = nltk.word_tokenize(text)
for word, tag in nltk.pos_tag(morph):
# 1文字の単語は除外
if len(word) <= 1:
continue
# stopword に登録されている単語は除外
if word in stopwords_dict:
continue
# 見出し語
if tag.startswith('NN'): # 名詞
word = lemmatizer.lemmatize(word, pos="n")
elif tag.startswith('VB'): # 動詞
word = lemmatizer.lemmatize(word, pos="v")
elif tag.startswith('JJ'): # 形容詞
word = lemmatizer.lemmatize(word, pos="a")
elif tag.startswith('RB'): # 副詞
word = lemmatizer.lemmatize(word, pos="r")
# 語幹化
word = stemmer.stem(word)
words.append(word)
# スペース区切りで出力
return " ".join(words)
# 実行
df["Name_tokenized"] = [_morphological_analysis(text) for text in tqdm(df["Name_normalize"])]
print(df[:2][["Name", "Name_tokenized"]].T)
100% 1309/1309 [00:01<00:00, 1051.48it/s]
0 \
Name_normalize braund mr owen harris
Name_tokenized braund mr owen harri
1
Name_normalize cumings mrs john bradley florence briggs thayer
Name_tokenized cume mr john bradley florenc brigg thayer
2-2(2).形態素解析(日本語)
janome を使っています。
import janome.tokenizer
tokenizer = janome.tokenizer.Tokenizer(wakati=False)
# --- 形態素解析用の関数
def _morphological_analysis(text):
words = []
tokens = list(tokenizer.tokenize(text))
# 単語に分解
for i, token in enumerate(tokens):
# token.part_of_speech = "名詞,非自立,助動詞語幹,*"
partOfSpeech = token.part_of_speech.split(',')
hinsi = partOfSpeech[0] # 品詞
surface = token.surface # 表層形
base_form = token.base_form # 基本形
# 特定の品詞のみ対象
if hinsi not in [
'名詞',
'動詞',
'形容詞',
'副詞'
]:
continue
# 動詞の場合は否定かどうか確認する
if hinsi == "動詞":
is_not = False
for j in range(i+1, len(tokens)):
token2 = tokens[j]
# 助動詞以外なら見ない
if token2.part_of_speech.split(',')[0] != "助動詞":
break
# 特定の助動詞があれば否定形
if token2.base_form in ["ん", "ない", "なかっ", "ず", "ぬ"]:
is_not = True
# 否定なら"ない"を語尾につける
if is_not:
base_form += "ない"
# 基本形を追加
words.append(base_form)
# 出力はスペース区切りにする
return " ".join(words)
# 実行例
df["Name_tokenized"] = [_morphological_analysis(text) for text in tqdm(df["Name_normalize"])]
対象のデータが英語なので実行例はなしです。
単語の出現頻度によるstopword
# 全単語の個数を数える
word_count = {}
for text in df["Name_tokenized"].values:
for word in text.split(" "):
if word not in word_count:
word_count[word] = 0
word_count[word] += 1
sorted_word_count = sorted(word_count.items(), key=lambda x:x[1])
print(sorted_word_count[:5]) # 低頻度5位
print(sorted_word_count[-5:]) # 高頻度5位
# stopword
def _stopword_remove(text):
words = []
for word in text.split(" "):
# 出現回数がn回以下は除外
if word_count[word] <= 1:
continue
words.append(word)
return " ".join(words)
df["Name_tokenized_stopword"] = df["Name_tokenized"].apply(_stopword_remove)
print(df["Name_tokenized_stopword"].value_counts())
[('brigg', 1), ('heikkinen', 1), ('laina', 1), ('peel', 1), ('gosta', 1)]
[('master', 61), ('john', 72), ('william', 94), ('miss', 260), ('mr', 964)]
mr 87
miss 19
mr john 11
mr joseph 7
mr ivan 5
..
bowerman miss elsi edith 1
mr leo 1
goodwin miss lillian ami 1
danbom mr ernst gilbert anna sigrid maria brogren 1
duff gordon lucil mr morgan 1
Name: Name_tokenized_stopword, Length: 1056, dtype: int64
3.文章のベクトル化とモデル化
Bag-of-Words
Bag-of-Words(BoW)は文章をベクトル化する一番簡単な手法で、単語があれば1なければ0とする手法です。
sklearnで簡単に変換できます。
import sklearn.feature_extraction
vec_model = sklearn.feature_extraction.text.CountVectorizer()
# 入力はスペース区切りの文字列の配列
docs = [
"太郎 は りんご を 買 った",
"二郎 は ぶどう を 買 った",
]
vec_model.fit(docs)
# 学習した辞書を表示
print(vec_model.vocabulary_)
# 辞書を元にベクトル化
vec = vec_model.transform(docs)
# ベクトルはスパースな行列(疎行列)になりやすいので専用の保存形式になる
print(vec)
# 一般的な行列にはtoarrayで直せるが、場合によってはメモリ不足でエラーになる
print(vec.toarray())
# 学習した辞書
{'太郎': 4, 'りんご': 2, 'った': 0, '二郎': 3, 'ぶどう': 1}
# 疎行列
(0, 0) 1
(0, 2) 1
(0, 4) 1
(1, 0) 1
(1, 1) 1
(1, 3) 1
# 行列
[[1 0 1 0 1]
[1 1 0 1 0]]
1文字の単語はデフォルト引数だと対象外になります。
N-gram
N-gramは単語の区切りをN個の連続した単語として考える手法です。
例えば「太郎 は りんご を 買 った」という文章があった場合、
1-gram:(太郎), (は), (りんご), (を), (買), (った)
2-gram:(太郎,は), (は,りんご), (りんご,を), (を,買), (買,った)
となります。
CountVectorizerに引数を与えるだけで実現できます。
import sklearn.feature_extraction
# ngram_range を指定し、2-gram を作成
vec_model = sklearn.feature_extraction.text.CountVectorizer(
ngram_range=(2, 2)
)
# 入力はスペース区切りの文字列の配列
docs = [
"太郎 は りんご を 買 った",
"二郎 は ぶどう を 買 った",
]
vec_model.fit(docs)
print(vec_model.vocabulary_)
# ベクトル化
vec = vec_model.transform(docs)
print(vec.toarray())
# 学習した辞書
{'太郎 りんご': 3, 'りんご った': 1, '二郎 ぶどう': 2, 'ぶどう った': 0}
# 行列
[[0 1 0 1]
[1 0 1 0]]
TF-IDF
文書中に含まれる単語の重要度を評価しベクトル化する手法で、以下2点の特徴を持つ単語の評価が高くなります。
・一つの文書内で出現回数の多い単語
・複数の文書では出現頻度の少ない単語
import sklearn.feature_extraction
vec_model = sklearn.feature_extraction.text.TfidfVectorizer()
# 入力はスペース区切りの文字列の配列
docs = [
"太郎 は りんご を 買 った",
"二郎 は ぶどう を 買 った",
]
vec_model.fit(docs)
print(vec_model.vocabulary_)
# ベクトル化
vec = vec_model.transform(docs)
print(vec.toarray())
# 学習した辞書
{'太郎': 4, 'りんご': 2, 'った': 0, '二郎': 3, 'ぶどう': 1}
# 行列
[[0.44943642 0. 0.6316672 0. 0.6316672 ]
[0.44943642 0.6316672 0. 0.6316672 0. ]]
Doc2Vec
Doc2Vecは文書をベクトル化する手法で、分散表現を獲得するのが特徴です。
元は単語を分散表現するWord2Vecからきており、これを文書に応用したものとなります。
分散表現を簡単に言うと、単語をベクトル空間上にマッピングする事です。
これをすることで計算できない文字から計算できるベクトルに文字を変換する事ができます。
Word2Vecで有名な例は「"king"-"man"+"woman"」と計算したら"queen"が出力されたという内容ですね。
実装はgensimを使います。
import gensim.models
# 入力は単語の配列
docs = [
["太郎", "は", "りんご", "を", "買", "った"],
["二郎", "は", "ぶどう", "を", "買", "った"],
]
# Doc2Vecが処理できる形に変換(各テキストにtagをつける)
docs_tags = [
gensim.models.doc2vec.TaggedDocument(text, tags=[t])
for i, text in enumerate(docs)
]
# モデルを作成
# vectorサイズは5次元に(デフォルトは100)
# デフォルトだと単語の出現回数が5回以下だとエラーがでるので min_count=1 を付けて回避
vec_model = gensim.models.doc2vec.Doc2Vec(docs_tags, vector_size=5, min_count=1)
print(vec_model.docvecs[0])
print(vec_model.docvecs[1])
# 新しい文書のベクトルを推定する
new_doc = ["私", "は", "二郎", "です"]
print(vec_model.infer_vector(new_doc))
# 文書の類似度を出力(コサイン類似度:0だと似てない、1だと同じ)
print(vec_model.docvecs.similarity_unseen_docs(vec_model, docs[0], new_doc))
print(vec_model.docvecs.similarity_unseen_docs(vec_model, docs[1], new_doc))
[-0.09720472 -0.03965357 0.05079619 -0.00474522 -0.04638901]
[-0.08147919 -0.08927347 -0.07378571 -0.0654799 0.00230152]
[ 0.064001 0.08754754 -0.07557587 0.09625442 -0.08814528]
0.09603033
0.74223655 # 二郎で繋がってるので類似度が高いですね
各手法とpandas連携関数
コードをまとめてvec_typeで指定できるようにしました。
import sklearn.feature_extraction
import gensim.models
def train_text_model(
df_train, # 学習に使用するデータ
text_column, # 自然言語のカラム
target_column, # 目的変数
vec_type, # ベクトル化する方法
model_cls,
model_params,
model_pred_type, # 予測で出力する形式(label or score)
df_valid=None, # 検証に使用するデータ
df_pred_list=[], # 予測に使用するデータの配列
):
#--------------------------
# ベクトル化用のモデルを作成
#--------------------------
train_x = df_train[text_column]
if vec_type == "BoW":
vec_model = sklearn.feature_extraction.text.CountVectorizer()
vec_model.fit(train_x) # 入力はスペース区切りの文字列
elif vec_type == "ngram-2":
vec_model = sklearn.feature_extraction.text.CountVectorizer(ngram_range=(2, 2))
vec_model.fit(train_x) # 入力はスペース区切りの文字列
elif vec_type == "ngram-3":
vec_model = sklearn.feature_extraction.text.CountVectorizer(ngram_range=(3, 3))
vec_model.fit(train_x) # 入力はスペース区切りの文字列
elif vec_type == "TF-IDF":
vec_model = sklearn.feature_extraction.text.TfidfVectorizer()
vec_model.fit(train_x) # 入力はスペース区切りの文字列
elif vec_type == "Doc2Vec":
# 各テキストにtagをつけてDoc2Vecが処理できる形に
# 入力は単語の配列
docs = train_x.apply(
lambda t: gensim.models.doc2vec.TaggedDocument(
t.split(" "), tags=[t]),
)
vec_model = gensim.models.doc2vec.Doc2Vec(docs)
else:
raise ValueError()
#-------------------
# build data
#-------------------
def _build_x_from_df(df):
x = df[text_column]
if vec_type == "BoW" or "ngram" in vec_type:
x = vec_model.transform(x).astype(float)
elif vec_type == "TF-IDF":
x = vec_model.transform(x)
elif vec_type == "Doc2Vec":
# ベクトルを推定、numpy配列にする
x = np.asarray([vec_model.infer_vector(t.split(" ")) for t in x])
return x
def _build_y_from_df(df):
return df[target_column]
#---------------
# 学習
#---------------
train_x = _build_x_from_df(df_train)
train_y = _build_y_from_df(df_train)
model = model_cls(**model_params)
model.fit(train_x, train_y)
#---------------
# 評価
#---------------
if df_valid is not None:
valid_x = _build_x_from_df(df_valid)
valid_y = _build_y_from_df(df_valid)
pred_y = model.predict(valid_x)
# 正解率
metric = sklearn.metrics.accuracy_score(valid_y, pred_y)
#---------------
# 予測
#---------------
pred_y_list = []
for df_pred in df_pred_list:
pred_x = _build_x_from_df(df_pred)
if model_pred_type == "label":
pred_y = model.predict(pred_x)
elif model_pred_type == "score":
if model.classes_[0] == 0:
pred_y = model.predict_proba(pred_x)[:,1]
else:
pred_y = model.predict_proba(pred_x)[:,0]
pred_y_list.append(pred_y)
return metric, pred_y_list
# ----------
# 実行例
# ----------
import lightgbm as lgb
params = {
"df_train": df[df["Survived"].notnull()], # 学習データ
"df_valid": df[df["Survived"].notnull()], # 検証データ(仮で学習データと同じ)
"df_pred_list": [df[df["Survived"].isnull()]], # 予測データ
"vec_type": "TF-IDF", # ベクトル化の方法
"text_column": "Name",
"target_column": "Survived",
# 使うモデル
"model_cls": lgb.LGBMClassifier,
"model_params": {"random_state": 1234},
"model_pred_type": "score",
}
metric, pred_y_list = train_text_model(**params)
pred_y = pred_y_list[0]
print(metric)
# pred_y には予測結果が入っているので、以下のように提出データが作れます。
df_submit = pd.DataFrame()
df_submit["PassengerId"] = df[df["Survived"].isnull()]["PassengerId"]
df_submit["Survived"] = np.where(pred_y < 0.5, 0, 1)
df_submit.to_csv('submit.csv', header=True, index=False)
0.813692480359147
実行例は学習データと検証データが同じなので正解率が高めです。
5.自然言語のモデルから特徴量を取得する
モデルから特徴量を抽出してさらにモデルを重ねる事をスタッキングといい、アンサンブル学習の1つとなります。
特徴量の作り方はいろいろありますが、今回は予測結果をそのまま特徴量としています。
予測結果を特徴量とするには全データを予測する必要があります。
予測するうえで気を付ける点は、学習モデルに予測するデータが入っているとリーク(予測結果が分かっているモデル)になるので以下のように予測結果を出力します。
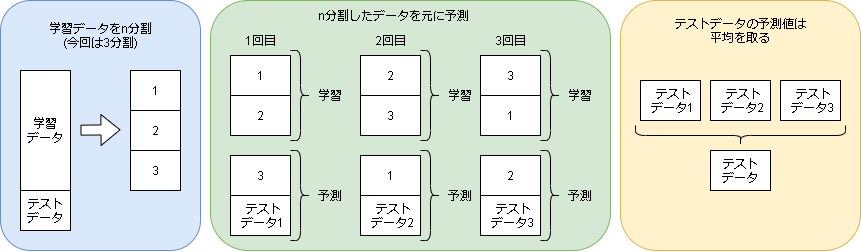
import sklearn.model_selection
def train_cross_validation_text(
df,
text_column,
target_column,
n_splits, # 交差検証の分割数
vec_type, # ベクトル化する方法
model_cls,
model_params,
model_pred_type,
is_pred=False,
):
df_train = df[df[target_column].notnull()]
df_test = df[df[target_column].isnull()]
df_train_idx = df_train.index
# 結果用
df_pred = pd.DataFrame(df.index, columns=["index"]).set_index("index")
metric_list = []
# クロスバリデーション(n foldに分ける)
kf = sklearn.model_selection.StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=1234)
for i, (train_idx, test_idx) in enumerate(kf.split(df_train, y=df_train[target_column])):
df_train_sub = df_train.iloc[train_idx]
df_test_sub = df_train.iloc[test_idx]
# 予測する場合は予測用のデータを作成
if is_pred:
df_pred_list = [df_test_sub]
if len(df_test) > 0:
df_pred_list.append(df_test)
else:
df_pred_list = []
# train
metric, pred_y_list = train_text_model(
df_train=df_train_sub,
text_column=text_column,
target_column=target_column,
vec_type=vec_type,
model_cls=model_cls,
model_params=model_params,
model_pred_type=model_pred_type,
df_valid=df_test_sub,
df_pred_list=df_pred_list,
)
metric_list.append(metric)
# 予測結果を保存
if is_pred:
result_name = "result_{}".format(i)
df_pred.loc[df_train_idx[test_idx], result_name] = pred_y_list[0]
if len(df_test) > 0:
df_pred.loc[df_test.index, result_name] = pred_y_list[1]
if is_pred:
pred_y = df_pred.mean(axis=1)
# 全データを埋めれたか念のため確認
assert len(pred_y) == len(df)
assert pred_y.isnull().sum() == 0
return np.mean(metric_list), pred_y.values
else:
return np.mean(metric_list)
# ----------
# 実行例
# ----------
metric, pred_y = train_cross_validation_text(
df,
"Name_tokenized_stopword",
"Survived",
n_splits=5, # 分割数
vec_type="TF-IDF", # ベクトル化方法
model_cls=lgb.LGBMClassifier,
model_params={"random_state": 1234},
model_pred_type="score",
is_pred=True,
)
print("交差検証の結果: ", metric)
# pred_y には予測結果が入っているので、以下のように提出データが作れます。
df_submit = pd.DataFrame()
df_submit["PassengerId"] = df["PassengerId"]
df_submit["Survived"] = np.where(pred_y < 0.5, 0, 1)
df_submit[df["Survived"].isnull()].to_csv('submit.csv', header=True, index=False)
print("予測値の検証結果: ", sklearn.metrics.accuracy_score(
df[df["Survived"].notnull()]["Survived"], df_submit[df["Survived"].notnull()]["Survived"]))
交差検証の結果: 0.7104575983930701
予測値の検証結果: 0.7104377104377104
交差検証もしているのでおまけで評価値もでてきます。
6.モデル作成例
実際に予測する例です。
1.特徴量作成
全モデルと全ベクトル手法に対して、全組み合わせで特徴量を作っています。
import sklearn.ensemble
import sklearn.gaussian_process
import sklearn.linear_model
import sklearn.naive_bayes
import sklearn.neighbors
import sklearn.tree
import sklearn.svm
import sklearn.discriminant_analysis
import sklearn.neural_network
import xgboost as xgb
import lightgbm as lgb
import catboost
def get_models_classifier(random_seed):
models = [
#Ensemble Methods
[sklearn.ensemble.AdaBoostClassifier, {"random_state": random_seed}, "score"],
[sklearn.ensemble.BaggingClassifier, {"random_state": random_seed}, "score"],
[sklearn.ensemble.ExtraTreesClassifier, {"random_state": random_seed}, "score"],
[sklearn.ensemble.GradientBoostingClassifier, {"random_state": random_seed}, "score"],
[sklearn.ensemble.RandomForestClassifier, {"random_state": random_seed}, "score"],
#Gaussian Processes
#[sklearn.gaussian_process.GaussianProcessClassifier, {"random_state": random_seed}, "label"],
#GLM
[sklearn.linear_model.RidgeClassifier, {}, "label"],
#Navies Bayes
[sklearn.naive_bayes.BernoulliNB, {}, "score"],
#[sklearn.naive_bayes.GaussianNB, {}, "score"],
#Nearest Neighbor
[sklearn.neighbors.KNeighborsClassifier, {}, "score"],
#Trees
[sklearn.tree.DecisionTreeClassifier, {"random_state": random_seed}, "score"],
[sklearn.tree.ExtraTreeClassifier, {"random_state": random_seed}, "score"],
# SVM
[sklearn.svm.SVC, {}, "label"],
[sklearn.svm.NuSVC, {}, "label"],
[sklearn.svm.LinearSVC, {}, "label"],
# NN
[sklearn.neural_network.MLPClassifier, {"random_state": random_seed}, "score"],
#xgboost
[xgb.XGBClassifier, {"eval_metric": "logloss", "use_label_encoder": False, "random_state": random_seed}, "score"],
# light bgm
[lgb.LGBMClassifier, {"random_state": random_seed}, "score"],
# catboost
#[catboost.CatBoostClassifier, {"verbose":0, "random_seed": 1234}, "score"],
]
return models
# --- モデルとベクトル化する手法の組み合わせを列挙
arr = []
for vec_type in [
"BoW",
"ngram-2",
"ngram-3",
"TF-IDF",
"Doc2Vec",
]:
for model in get_models_classifier(1234):
arr.append([vec_type, model])
# --- 各組み合わせに対して、特徴量を出す
text_columns = []
for m in tqdm(arr):
key = "{}_{}".format(m[1][0].__name__, m[0])
metric, pred_y = train_cross_validation_text(
df,
"Name_tokenized_stopword",
"Survived",
vec_type=m[0],
n_splits=5,
model_cls=m[1][0],
model_params=m[1][1],
model_pred_type=m[1][2],
is_pred=True
)
print(metric, key)
# 特徴量を追加
df[key] = pred_y
text_columns.append(key)
print(text_columns)
0.7407444604858451 AdaBoostClassifier_BoW
0.7317996359299478 BaggingClassifier_BoW
0.7317682505806291 ExtraTreesClassifier_BoW
(略)
0.6217688782876154 MLPClassifier_Doc2Vec
0.5993283535245747 XGBClassifier_Doc2Vec
0.5881049526081225 LGBMClassifier_Doc2Vec
['AdaBoostClassifier_BoW', 'BaggingClassifier_BoW', 'ExtraTreesClassifier_BoW', 'GradientBoostingClassifier_BoW', 'RandomForestClassifier_BoW', 'RidgeClassifier_BoW', 'BernoulliNB_BoW', 'KNeighborsClassifier_BoW', 'DecisionTreeClassifier_BoW', 'ExtraTreeClassifier_BoW', 'SVC_BoW', 'NuSVC_BoW', 'LinearSVC_BoW', 'MLPClassifier_BoW', 'XGBClassifier_BoW', 'LGBMClassifier_BoW', 'AdaBoostClassifier_ngram-2', 'BaggingClassifier_ngram-2', 'ExtraTreesClassifier_ngram-2', 'GradientBoostingClassifier_ngram-2', 'RandomForestClassifier_ngram-2', 'RidgeClassifier_ngram-2', 'BernoulliNB_ngram-2', 'KNeighborsClassifier_ngram-2', 'DecisionTreeClassifier_ngram-2', 'ExtraTreeClassifier_ngram-2', 'SVC_ngram-2', 'NuSVC_ngram-2', 'LinearSVC_ngram-2', 'MLPClassifier_ngram-2', 'XGBClassifier_ngram-2', 'LGBMClassifier_ngram-2', 'AdaBoostClassifier_ngram-3', 'BaggingClassifier_ngram-3', 'ExtraTreesClassifier_ngram-3', 'GradientBoostingClassifier_ngram-3', 'RandomForestClassifier_ngram-3', 'RidgeClassifier_ngram-3', 'BernoulliNB_ngram-3', 'KNeighborsClassifier_ngram-3', 'DecisionTreeClassifier_ngram-3', 'ExtraTreeClassifier_ngram-3', 'SVC_ngram-3', 'NuSVC_ngram-3', 'LinearSVC_ngram-3', 'MLPClassifier_ngram-3', 'XGBClassifier_ngram-3', 'LGBMClassifier_ngram-3', 'AdaBoostClassifier_TF-IDF', 'BaggingClassifier_TF-IDF', 'ExtraTreesClassifier_TF-IDF', 'GradientBoostingClassifier_TF-IDF', 'RandomForestClassifier_TF-IDF', 'RidgeClassifier_TF-IDF', 'BernoulliNB_TF-IDF', 'KNeighborsClassifier_TF-IDF', 'DecisionTreeClassifier_TF-IDF', 'ExtraTreeClassifier_TF-IDF', 'SVC_TF-IDF', 'NuSVC_TF-IDF', 'LinearSVC_TF-IDF', 'MLPClassifier_TF-IDF', 'XGBClassifier_TF-IDF', 'LGBMClassifier_TF-IDF', 'AdaBoostClassifier_Doc2Vec', 'BaggingClassifier_Doc2Vec', 'ExtraTreesClassifier_Doc2Vec', 'GradientBoostingClassifier_Doc2Vec', 'RandomForestClassifier_Doc2Vec', 'RidgeClassifier_Doc2Vec', 'BernoulliNB_Doc2Vec', 'KNeighborsClassifier_Doc2Vec', 'DecisionTreeClassifier_Doc2Vec', 'ExtraTreeClassifier_Doc2Vec', 'SVC_Doc2Vec', 'NuSVC_Doc2Vec', 'LinearSVC_Doc2Vec', 'MLPClassifier_Doc2Vec', 'XGBClassifier_Doc2Vec', 'LGBMClassifier_Doc2Vec']
2.特徴量削減(RFECV)
特徴量が多すぎるので減らします。
減らし方はRFECVを使っています。
import sklearn.feature_selection
def feature_selection_RFECV(df, select_columns, target_columns):
model = lgb.LGBMClassifier(random_state=1234)
scoring = "accuracy" # 評価方法
x = df[df[target_columns].notnull()][select_columns]
y = df[df[target_columns].notnull()][target_columns]
rfe = sklearn.feature_selection.RFECV(model, scoring=scoring)
rfe.fit(x, y)
inc_columns = []
exc_columns = []
for i, flag in enumerate(rfe.get_support()):
if flag:
inc_columns.append(select_columns[i])
else:
exc_columns.append(select_columns[i])
return inc_columns, exc_columns
# 実行例
inc_columns, exc_columns = feature_selection_RFECV(df, text_columns, "Survived")
print("inc", inc_columns)
# print("exc", exc_columns)
text_columns = inc_columns
inc ['AdaBoostClassifier_BoW', 'BaggingClassifier_BoW', 'ExtraTreesClassifier_BoW', 'GradientBoostingClassifier_BoW', 'RandomForestClassifier_BoW', 'BernoulliNB_BoW', 'MLPClassifier_BoW', 'XGBClassifier_BoW', 'LGBMClassifier_BoW', 'BaggingClassifier_ngram-2', 'ExtraTreesClassifier_ngram-2', 'RandomForestClassifier_ngram-2', 'BernoulliNB_ngram-2', 'MLPClassifier_ngram-2', 'XGBClassifier_ngram-2', 'BaggingClassifier_ngram-3', 'GradientBoostingClassifier_ngram-3', 'DecisionTreeClassifier_ngram-3', 'AdaBoostClassifier_TF-IDF', 'BaggingClassifier_TF-IDF', 'ExtraTreesClassifier_TF-IDF', 'GradientBoostingClassifier_TF-IDF', 'RandomForestClassifier_TF-IDF', 'MLPClassifier_TF-IDF', 'XGBClassifier_TF-IDF', 'LGBMClassifier_TF-IDF', 'AdaBoostClassifier_Doc2Vec', 'BaggingClassifier_Doc2Vec', 'ExtraTreesClassifier_Doc2Vec', 'GradientBoostingClassifier_Doc2Vec', 'RandomForestClassifier_Doc2Vec', 'BernoulliNB_Doc2Vec', 'ExtraTreeClassifier_Doc2Vec', 'MLPClassifier_Doc2Vec', 'XGBClassifier_Doc2Vec', 'LGBMClassifier_Doc2Vec']
3.AutoMLによるモデル作成
3-1.データ読み込み
pcc_df = df[df["Survived"].notnull()][text_columns + ["Survived"]]
# データを渡す
import pycaret.classification as pcc
r = pcc.setup(pcc_df, target="Survived", silent=True, session_id=1234)
3-2.各特徴量の影響度を可視化(SHAP)
pcc.interpret_model(pcc.create_model("lightgbm"))
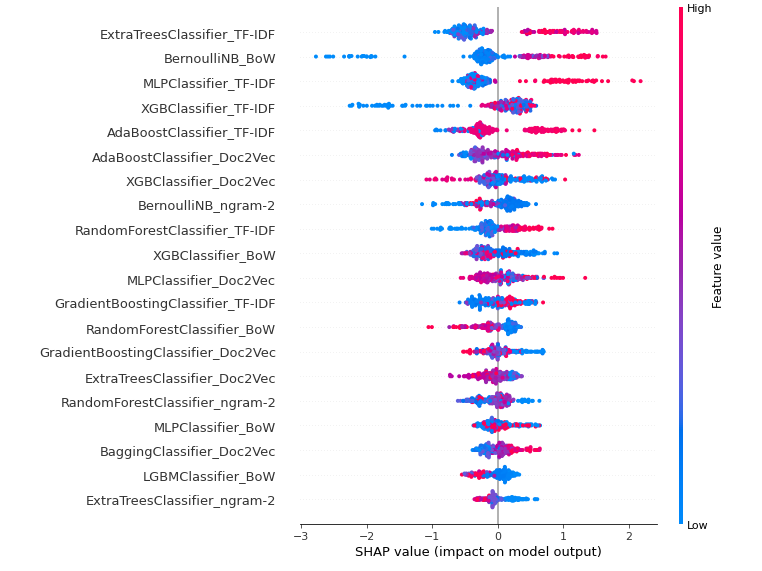
ExtraTreesCkassifierとTF-IDFの組み合わせが一番影響がありそうです。
全体的にTF-IDFの影響度が高く、ngram系はあまり影響なさそうですね。
3-3.モデル作成
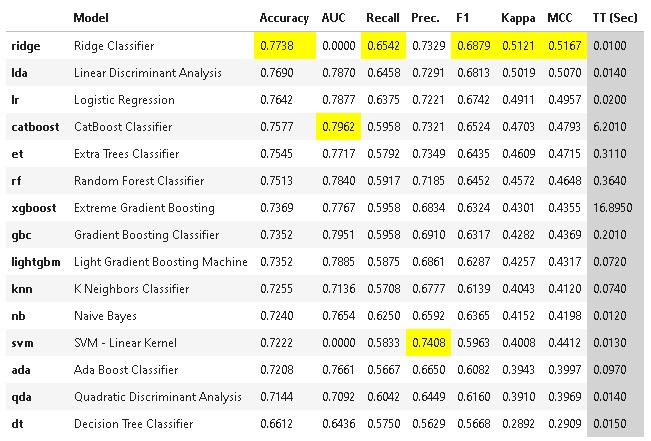
上位3位のベストなモデルを決めます。
best_models = pcc.compare_models(n_select=3)
print(best_models)
上位3位のモデルを元にブレンドし、ブレンドモデルをチューニングします。
blend_model = pcc.blend_models(best_models)
tuned_model = pcc.tune_model(blend_model)
# パラメータ表示
pcc.plot_model(tuned_model, plot='parameter')
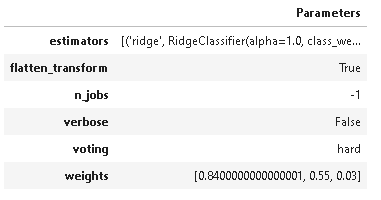
画像はチューニング後のパラメータです。
3-4.提出ファイル作成(予測)
# モデルを検証
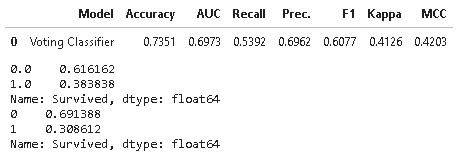
pcc.predict_model(tuned_model)
# 予測
x_pred = df[df["Survived"].isnull()]
df_pred = pcc.predict_model(tuned_model, data=x_pred)
# 予測結果をcsvで出力
df_submit = pd.DataFrame()
df_submit["PassengerId"] = df[df["Survived"].isnull()]["PassengerId"]
df_submit["Survived"] = df_pred["Label"].apply(lambda x:int(float(x)))
df_submit.to_csv('submit3.csv', header=True, index=False)
# 念のため結果の割合を表示
print(df["Survived"].value_counts(normalize='columns'))
print(df_submit["Survived"].value_counts(normalize='columns'))