はじめに
ベイズ最適化を用いて、最適なパラメータを導出する方法について解説致します。
具体的には実験において、早く最適な条件に到達することを目的として、ベイズ最適化によって次の実験条件を提案してくれる手法について説明します。ベイズ最適化を用いて最適条件を探索するという内容はよく見かけるのですが、既知の関数の最適化に焦点が当てられているものがほとんどだと思います。でも、実際の実験って関数(起こっている物理現象)が分からないから、イマイチ参考にできないんだよね…と思っていました。この投稿ではそのような悩みを解消し、「実際の実験で使える」ベイズ最適化による条件探索について解説します。ベイズ最適化の理論についてこちらにまとめました。
※機械学習やプログラミング関係の内容を他にも投稿していますので、よろしければこちらの一覧から他の投稿も見て頂けますと幸いです。
やりたいこと(想定シチュエーション)
- パラメータを調整しながら、所望の特性を得る実験
- パラメータの種類や範囲は固定されている(プロセス自体は決まっている)
- 何度か実験して、いくつか実験データが得られている(説明変数xと目的変数yのペアがいくつかある)
- 既知の実験データを用いて(参考にして)、次の実験条件を決定する
- ベイズ最適化を活用し、人よりも早く(少ない実験回数で)最適条件に到達したい
※「最適」条件と書いていますが、実際には目標値を満たす特性が得られるorより高い特性が得られる実験条件というイメージです
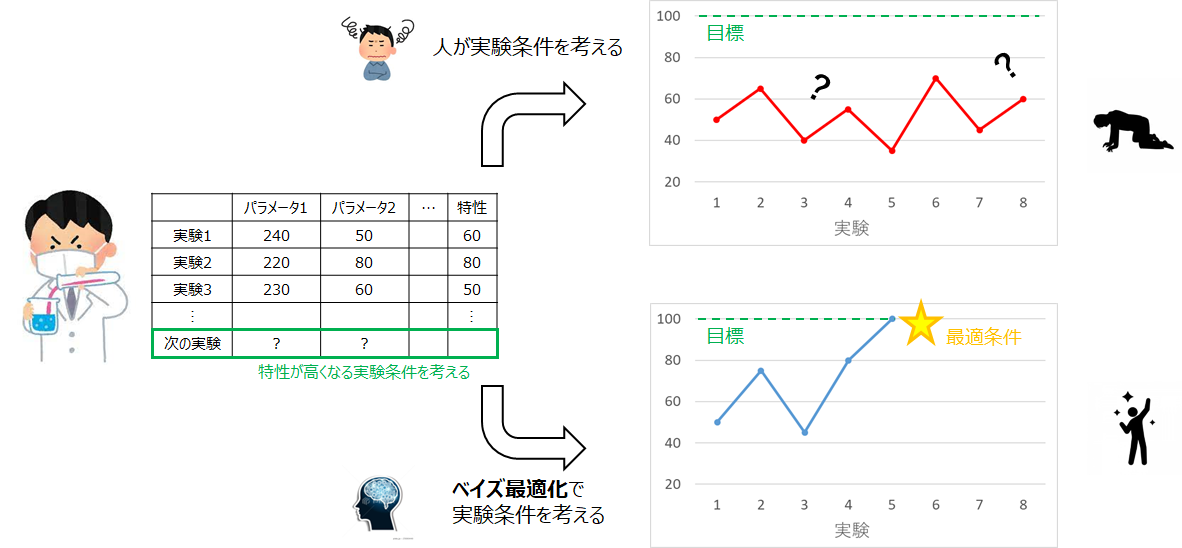
ベイズ最適化を活用した実験サイクルのイメージ
ベイズ最適化を活用することで次の実験条件が出力されます。この条件で実験を行い、新たに特性yを取得します。(実際には試験や測定など行うイメージです)そして、このxとyのペアを既知の実験データに追加して新たなインプットとしてベイズ最適化を行い、次の実験条件を得ます。この繰り返しによって少ない実験回数で最適条件に到達するイメージです。

ベイズ最適化を用いた最適条件の導出
以下で紹介するサンプルデータを用いて、次に実験する条件を導出することを考えていきます。
今回取り扱うデータ
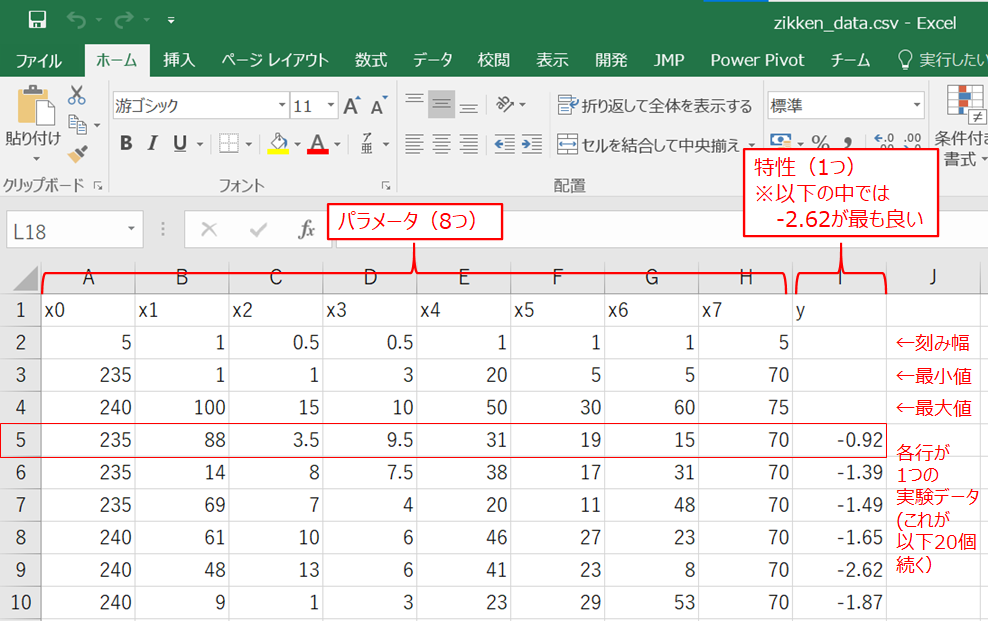
データはこちらのGitHubに保存したzikken_data.csvのデータを使っていきます。
- パラメータ(説明変数)はx0~x7の8つ
- csvの3行目に各パラメータの最小値が記載されている
- csvの4行目に各パラメータの最大値が記載されている
- csvの2行目に各パラメータの刻み幅が記載されている
- 特性(目的変数)はyの1つ
- yは望小特性で小さい方が良い(負の値で絶対値が大きい方が良い)とする
- 既知の実験データはcsvの5行目以下に計20個保存されている
※パラメータの刻み幅は装置の制約(例:整数でしかパラメータを入力できない)や
条件検討の粗さ(例:定義域が0~100までなら、まずは10刻みで検討)が反映されるイメージです
環境
- Python 3.6.6
- pandas 0.23.4
- numpy 1.19.4
- scikit-learn 0.23.2
- GPy 1.9.5
- GPyOpt 1.2.5
Pythoコード
この記事の実行可能なコードはこちらのnoteで公開しています。実務でそのまま使えるコードに整備しており、GpyOptの最適化パラメータに関しても詳しく説明しておりますので是非ご覧ください。この記事を読んで「コードを動かしてみたい」と思った方向けの内容になっております。