はじめに
今回のソースコードと学習に使用した画像データセットは、以下のGithub上に公開しています。
https://github.com/33taro/pikachu_image_classification
※2021/9/8に開催された、みんなのPython勉強会#73のライトニングトークで発表しました。
当日の資料はこちらから見れます。
またそれに伴い、発表資料用の画像等を本記事に追加しました。
ポケモン好きで機械学習を勉強したなら誰もが一度は夢見るリアルポケモン図鑑作成を目指してみました。
ただ現在のポケモンは900種類近くおり、いきなり全てを画像分類するの困難です。
そこでまずはピカチュウっぽいポケモンを機械学習で画像分類してみることにしました。
似たような特徴を持つポケモンの分類が正確にできるなら、それを拡張して将来的にポケモン図鑑を作れるんじゃないかと夢見ています。

画像収集方法はグーグル画像検索で「ポケモン名」 + (アニメ or ぬいぐるみ or イラスト)の結果を、ChromeのアドオンであるFatkunで一括保存しました。
今回分類するポケモンは以下の8匹です。
- ピカチュウ
- ライチュウ
- ピチュー
- パチリス
- エモンガ
- デデンネ
- トゲデマル
- ミミッキュ
この他にもピカチュウっぽいポケモンには、「プラスル」、「マイナン」、「ライチュウ (アローラのすがた)」、「モルペコ」がいますが、以下の理由で省いています。

- プラスルとマイナン→画像収集した結果、あまりにセットで書かれている画像が多く、分割して各々単独の画像にするのが面倒なので。
- モルペコ→「まんぷくもよう」と「はらぺこもよう」の2種類の姿があり、扱いが面倒なので今回は排除。
- ライチュウ (アローラのすがた)→名前と図鑑番号がライチュウ (原種のすがた) と同一であり、扱いが面倒なので今回は排除。
画像分類について
機械学習による画像分類は、基本的に畳み込みニューラルネットワーク(CNN)によるモデルを用います。
特に有名なのはVGG16モデルであり、ImageNetという大規模画像データセットより学習したものです。
ただ現在はより精度の高いモデルも存在します。
しかし今回は、手軽に利用できWeb上の知見も多いVGG6でまずは試してみようと思います。
VGG16を試しに使ってみる
まずは試しに、kerasによる学習済みモデルVGG16を用いた画像分類を実施します。
今回使用する画像はOpenCVのサンプルから持ってきた以下のmessi5.jpgという画像です。

上記画像を以下のサンプルコードの直下に配置後、実行すると次のような結果が得られます。
import tensorflow as tf
from tensorflow.keras.preprocessing import image as tf_image
import pprint
# ------------------------------
# (1) 判別対象画像の読み込みと標準化
# ------------------------------
# 判別対象画像読み込み (224 * 224へリサイズ)
target_img = tf_image.load_img('messi5.jpg', target_size=(224, 224))
# 画像形式から配列形式へ変換
# ※ (1 * 244 * 244 * 3)配列
target_img_array = tf_image.img_to_array(target_img)[tf.newaxis]
# 判別対象画像の標準化
target_img_array = tf.keras.applications.vgg16.preprocess_input(target_img_array)
# ------------------------------
# (2) 画像分類
# ------------------------------
# ImageNetのVGG16モデル使用
vgg16_model = tf.keras.applications.vgg16.VGG16(weights='imagenet')
# 画像分類実施
image_classification = vgg16_model.predict(target_img_array)
# 分類結果の上位から5つの、(ラベル、名前、確率)取得
# ※ 見やすいようpprintを使用
result = tf.keras.applications.vgg16.decode_predictions(image_classification, top=5)
pprint.pprint(result)
[[('n04254680', 'soccer_ball', 0.8960954),
('n04118538', 'rugby_ball', 0.04896092),
('n09835506', 'ballplayer', 0.020750962),
('n02799071', 'baseball', 0.01564166),
('n03379051', 'football_helmet', 0.013572185)]]
上位分類結果が「サッカーボール」となっており、正しく判別されています。
では順に何をやっているか解説します。
(1) 判別対象画像の読み込みと標準化
判別対象の画像を読み込む際に、サイズを**「224 * 224」**に変更しています。
これはVGG16の入力サイズが「224 * 224」であるためです。
今回のmessi5.jpgは「548 * 342」なため、リサイズにより次のような画像となります。
上図は問題ありませんが、リサイズによって画像の特徴があまりに失われる場合があります。
対処としてはリサイズの方法を工夫する、[fine tuning](#-fine tuning)による入力サイズを変更するなどが考えられます。
その後は画像オブジェクトを配列に変換します。
判別(predict)には(画像枚数 * 画像サイズ * 画像サイズ * 次元)の4階層配列を渡す必要があります。
今回は1つの画像なため(244 * 244 * 3)配列であり、このままで判別時にエラーとなります。。
そのため配列化の際に、末尾に[tf.newaxis]を記述することで、次元を1つ追加し(1 * 244 * 244 * 3)配列にします。
tf.newaxisの値はNoneですが、tensorflowのお作法として次元追加と分かりやすくするためtf.newaxisと記述します。
最後は画像標準化を実施しています。
標準化を実施しなくても、内部的に上手いことやってくれる場合もあります。
しかし明示的に標準化したほうがよいです。
おまけ:画像表示
蛇足ですが読み込んだ画像は次のコードで表示しています。
import matplotlib.pyplot as plt
plt.imshow(target_img)
plt.show()
(2) 画像分類
今回はkerasのVGG16をそのまま使います。
そのため最初のモデル宣言時はデフォルトのImageNetモデルを使うため、「weights='imagenet'」を引数に渡します。
現在(2021/8)はそもそもImageNet or Noneしかありませんが、明示的に宣言するのが一般的です。
decode_predictions()はImageNetによる画像分類結果を、指定数の上位順に取得する関数です。
その結果をpprintで見やすく表示しています。
VGG16の転移学習によるピカチュウ判別
※コードや画像ディレクトリの詳細はGitを参考にしてください。
VGG16には当然、ポケモンは学習されていません。
そのため転移学習により、ポケモンを識別できるようにします。
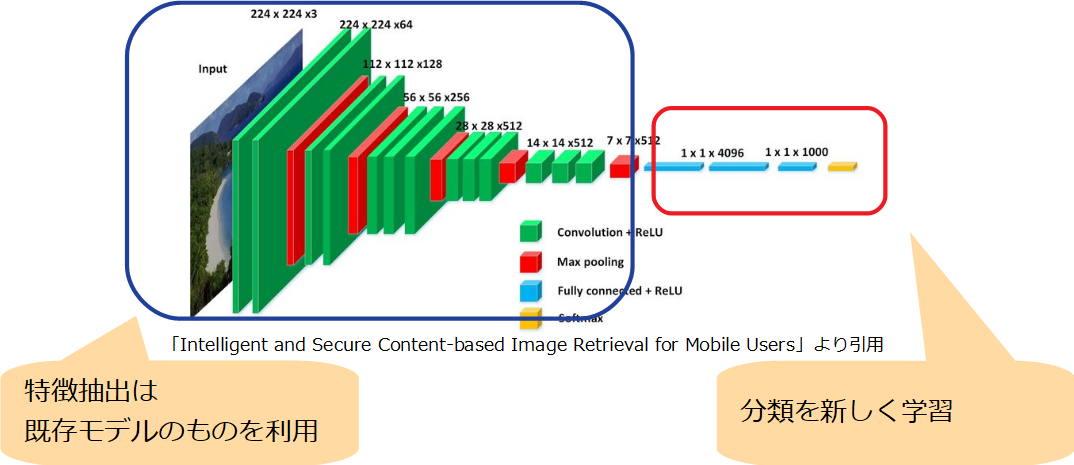
転移学習とは既存モデルから新たなモデルを生成する手法です。
特徴抽出の層は既存モデルをそのまま使い、分類を新しく学習することで、既存モデルにはない未知の分類が可能です。
利点としては、学習画像が少なくてもそれなりの精度が出ることです。
余談ですが特徴抽出段階も再学習する場合、ファインチューニングと呼ばれます。
1.画像とラベル取得と訓練・検証・テスト分割
import tensorflow as tf
from tensorflow.keras.preprocessing import image_dataset_from_directory
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
# 画像ディレクトリ
IMG_DIR = 'img2'
# バッチサイズ
BATCH_SIZE = 32
# VGG16を使用するため以下のサイズに設定
IMAGE_SIZE = (224, 224)
IMAGE_SHAPE = IMAGE_SIZE + (3, )
# 訓練、検証、テストの比率
TRAIN_SIZE = 0.6
VALIDATION_SIZE = 0.2
TEST_SIZE = 0.2
# 実行毎に同一の結果が得られるようシード値を固定
RANDOM_STATE = 123
# 学習率
LEARNING_RATE = 3e-5
# エポック数
INITIAL_EPOCHS = 5
# ------------------------------------------------------------
# 1.画像とラベル取得と訓練・検証・テスト分割
# ------------------------------------------------------------
# (1) 画像読み込み
image_dataset = image_dataset_from_directory(IMG_DIR,
shuffle=False,
batch_size=BATCH_SIZE,
image_size=IMAGE_SIZE
)
# (2) 画像データセットをX:画像とY:クラス名で各々配列化
image_class_names = image_dataset.class_names
img_X = []
img_Y = []
for img_ds_batch in list(image_dataset.as_numpy_iterator()):
img_X.extend(img_ds_batch[0])
img_Y.extend(img_ds_batch[1])
img_X = np.asarray(img_X)
img_Y = np.asarray(img_Y)
# (3) 画像データの標準化
img_X = tf.keras.applications.vgg16.preprocess_input(img_X)
# (4) データセットを訓練・検証・テストに分割
# データセットを[train, (validation + test)]に分割
img_X_train, imp_X_tmp, img_Y_train, img_Y_tmp = train_test_split(
img_X, img_Y,
train_size=TRAIN_SIZE,
random_state=RANDOM_STATE,
stratify=img_Y)
# (validation + test)データセットを[validation, test]に分割
VAL_TEST_SPLIT_SIZE = VALIDATION_SIZE / (VALIDATION_SIZE + TEST_SIZE)
img_X_valid, img_X_test, img_Y_valid, img_Y_test = train_test_split(
imp_X_tmp, img_Y_tmp,
train_size=VAL_TEST_SPLIT_SIZE,
random_state=RANDOM_STATE,
stratify=img_Y_tmp)
機械学習に使用する画像データ群を適切に読み込み、訓練・検証・テスト用に分割します。
訓練・検証・テスト用フォルダに分けてもよいですが、今後画像を増やしても対応でき、各用途に使う画像選択や画像比率を柔軟的に変更できるよう、プログラム側で制御します。
(1) 画像読み込み
# (1) 画像読み込み
image_dataset = image_dataset_from_directory(IMG_DIR,
shuffle=False,
batch_size=BATCH_SIZE,
image_size=IMAGE_SIZE
)
| 引数 | 説明 |
|---|---|
| IMG_DIR | 読み込む画像ディレクトリ。 |
| shuffle=False | 読み込んだ画像をシャッフルするか指定する。 今回は訓練・検証・テスト用分割時にシャッフルするため、Falseに設定。 |
| batch_size=BATCH_SIZE | データのバッチサイズ。使用環境は自前のノートPCであり画像数も少ないため、小さい32に設定。 |
| image_size=IMAGE_SIZE | 画像サイズ。ベースとなるVGG16と同じ(224, 224)に設定。 |
画像とラベルの組み合わせを、学習できるデータセットとして取得します。
今回はtensorflowのimage_dataset_from_directory()関数を使います。
これは画像が保存されているディレクトリを指定することで、自動的にラベル付けまでしてくれます。
ディレクトリ構造は以下のようになっており、結果として画像のようにラベル付けがされます。
※ディレクトリはGit上のここを参照
https://github.com/33taro/pikachu_image_classification/tree/main/img
img/
...025_pikachu/
......00000001.jpg
......00000002.jpg
......00000003.jpg
……(略)……
...026_raichu/
......00000001.jpg
......00000002.jpg
......00000003.jpg
……(略)……
……

画像読み込みには、より手軽なImageDataGeneratorクラスによる手法もあります。
ただしImageDataGeneratorクラスによる手法は、image_dataset_from_directory()関数と比べ柔軟性が劣ります。
特にデータセットの訓練・検証・テスト用への分割が困難となるため、今回は使いません。
(2) 画像データセットをX:画像とY:クラス名で各々配列化
# (2) 画像データセットをX:画像とY:クラス名で各々配列化
image_class_names = image_dataset.class_names
img_X = []
img_Y = []
for img_ds_batch in list(image_dataset.as_numpy_iterator()):
img_X.extend(img_ds_batch[0])
img_Y.extend(img_ds_batch[1])
img_X = np.asarray(img_X)
img_Y = np.asarray(img_Y)
読み込んだ画像データはtf.data.Datasetという形式で取得されます。
この後、データをいじる関係上、多次元配列のnumpy.ndarray型にしたいので、上記のように実施します。
tf.data.Datasetはバッチサイズ(今回は32)個のデータを含んだ塊を複数個持っています。
それを以下画像のように、全ての要素を1つに結合し、画像データ(=X)、ラベルデータ(=Y)を扱います。
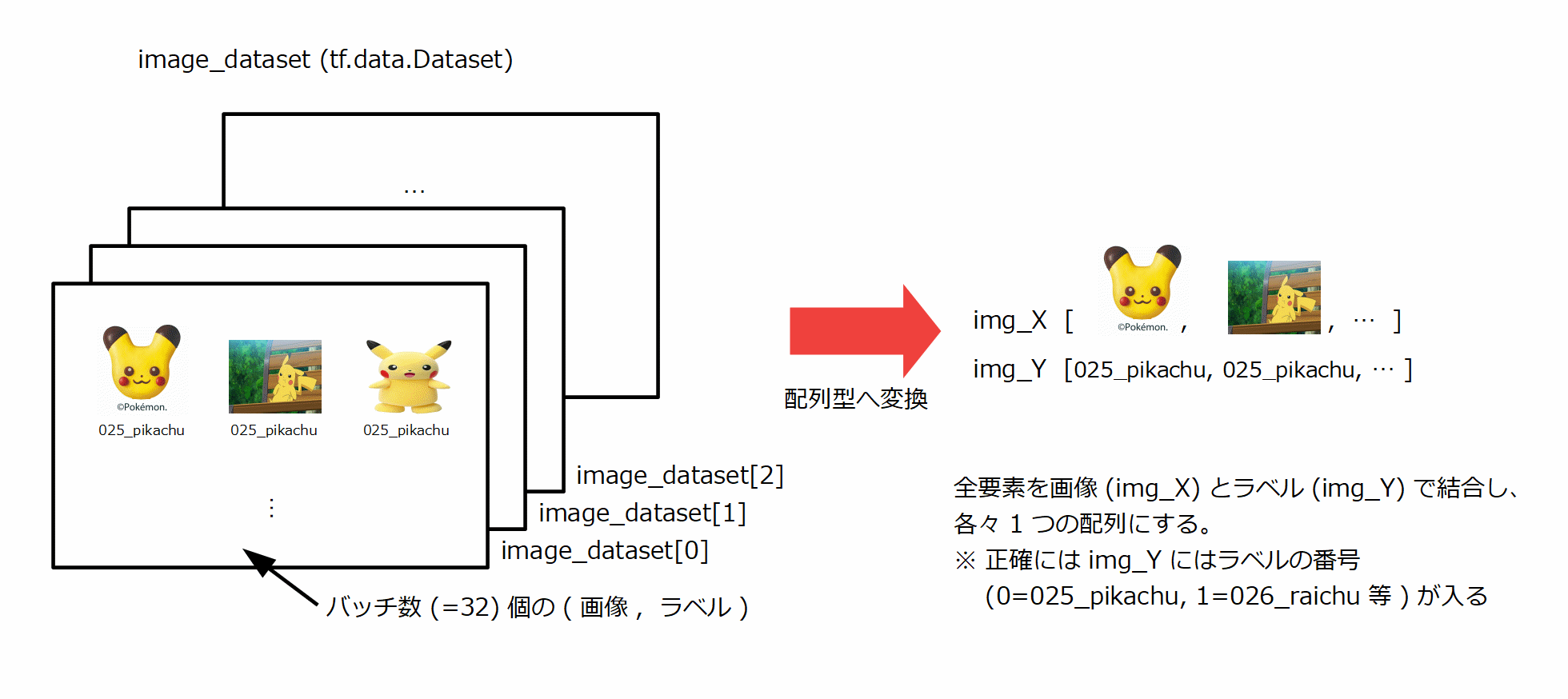
まずas_numpy_iterator()関数により、tf.data.Datasetの持つ値を配列型に変換できます。
※as_numpy_iterator()は直接numpy.ndarray型として受け取れますが、結合が高速に可能な通常の配列型を使用します。
その後、全ての要素を結合し、numpy.ndarray型に変換します。
(3) 画像データの標準化
# (3) 画像データの標準化
img_X = tf.keras.applications.vgg16.preprocess_input(img_X)
前処置としてVGG16と同様の標準化(RGBからBGEへ変換 + ImageNetのmeanを引く)を実施します。
これの代わりに、TensorFlowで扱いやすいよう、255で割り値の範囲を0~1にする標準化手法もあります。
転移学習等においてどちらを使ったほうがよいかは、こちらのサイトに記事があります。
今回はVGG16にあまり手を加えない転移学習であるため、VGG16と同一の標準化を実施しました。
(4) データセットを訓練・検証・テストに分割
# (4) データセットを訓練・検証・テストに分割
# データセットを[train, (validation + test)]に分割
img_X_train, imp_X_tmp, img_Y_train, img_Y_tmp = train_test_split(
img_X, img_Y,
train_size=TRAIN_SIZE,
random_state=RANDOM_STATE,
stratify=img_Y)
# (validation + test)データセットを[validation, test]に分割
VAL_TEST_SPLIT_SIZE = VALIDATION_SIZE / (VALIDATION_SIZE + TEST_SIZE)
img_X_valid, img_X_test, img_Y_valid, img_Y_test = train_test_split(
imp_X_tmp, img_Y_tmp,
train_size=VAL_TEST_SPLIT_SIZE,
random_state=RANDOM_STATE,
stratify=img_Y_tmp)
| 引数 | 説明 |
|---|---|
| X | 全画像データの配列。 |
| Y | 全画像ラベルの配列。 |
| train_size=XXXX | 分割サイズの割合を小数で指定。 2つにしか分けられないため1回目は(0.6, 0.4)、2回目は(0.5, 0.5)に分割。 結果、訓練・検証・テストが(0.6, 0.2, 0.2)に分割 |
| random_state=RANDOM_STATE | 分割前に要素数がランダムにシャッフルされる際のSEED値。 テストのため何回実行しても同一の結果となるよう定数を設定。 |
| stratify=Y | 分割後も、各々においてラベル(=Y)の比率が一致するように設定。 |
scikit-learnのtrain_test_split()関数により、読み込んだ画像とラベルを訓練・検証・テスト用に分割します。
ランダムにシャッフルして分割しつつ、ラベルの比率は揃えたいため、「stratify=<ラベル>」を指定します。
これにより各用途の画像群は、ピカチュウ、ライチュウ、ピチュー……等のポケモン種類の比率が同じになります。
3つの用途に分割したいですが、train_test_split()関数は2つにしか分割できません。
そのため2回train_test_split()関数を実行しています。
2.モデル構築と学習
# ------------------------------------------------------------
# 2.モデル構築と学習
# ------------------------------------------------------------
# (1) 転移学習のベースモデルとしてVGG16を宣言
base_model = tf.keras.applications.vgg16.VGG16(include_top=False,
input_shape=IMAGE_SHAPE,
weights='imagenet')
# (2) 畳み込みベースの凍結
base_model.trainable = False
# (3) モデル構築
# Flatten(=平坦化層)追加
x = tf.keras.layers.Flatten()(base_model.output)
# FC1層追加
x = tf.keras.layers.Dense(4096, activation='relu')(x)
# FC2層追加
x = tf.keras.layers.Dense(4096, activation='relu')(x)
# 入力画像の形状
transfer_learning_inputs = base_model.inputs
# predictions層の追加
# 今回分類するクラス数を指定
image_class_num = len(image_class_names)
transfer_learning_prediction = tf.keras.layers.Dense(
image_class_num, activation='softmax')(x)
# 転移学習モデル構築
transfer_learning_model = tf.keras.Model(inputs=transfer_learning_inputs,
outputs=transfer_learning_prediction)
# (4) モデルのコンパイル
transfer_learning_model.compile(optimizer=
tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# (5) モデルの学習
history = transfer_learning_model.fit(img_X_train, img_Y_train,
epochs=INITIAL_EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(img_X_valid, img_Y_valid))
画像データセットの整理が完了したため、いよいよ転移学習を実施します。
(1) 転移学習のベースモデルとしてVGG16を宣言
# (1) 転移学習のベースモデルとしてVGG16を宣言
base_model = tf.keras.applications.vgg16.VGG16(include_top=False,
input_shape=IMAGE_SHAPE,
weights='imagenet')
| 引数 | 説明 |
|---|---|
| include_top=False | Falseを指定することで出力層が含まれなくなる。 出力層は転移学習により設定。 |
| input_shape=IMAGE_SHAPE | 入力画像の形状指定。VGG16と同じ形状でよい。 include_top=Falseの場合のみ指定可能なパラメータ。 |
| weights='imagenet' | ImageNetモデルを使用。 |
ベースとなる学習モデルはVGG16です。
出力層は目的(=ピカチュウっぽいポケモンの分類)に併せて生成する必要があるため、省くようにします。
実際に以下の例を見てみると、例(1)VGG16の通常モデルと比較し、例(2)VGG16の出力層を除いたモデルは、出力層(flatten ~ predictions)がありません。
sample_model_1 = tf.keras.applications.vgg16.VGG16(weights='imagenet')
sample_model_1.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
sample_model_2 = tf.keras.applications.vgg16.VGG16(include_top=False,
input_shape=IMAGE_SHAPE,
weights='imagenet')
sample_model_2.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
(2) 畳み込みベースの凍結
# (2) 畳み込みベースの凍結
base_model.trainable = False
本設定により、転移学習時に既存のモデルは更新されなくなります。
具体的には例(2)で示されている、出力層以外の層が更新されなくなります。
転移学習では、既存のモデルをそのまま使うため、全体を凍結し、転移学習時に作成する出力層以外は変更されないようにします。
例(3)を見れば分かるように、凍結後は全てのパラメータが「Non-trainable params」になっています。
sample_model_3 = tf.keras.applications.vgg16.VGG16(include_top=False,
input_shape=IMAGE_SHAPE,
weights='imagenet')
sample_model_3.trainable = False
sample_model_3.summary()
Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_7 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 0
Non-trainable params: 14,714,688
_________________________________________________________________
(3) モデル構築
# (3) モデル構築
# Flatten(=平坦化層)追加
x = tf.keras.layers.Flatten()(base_model.output)
# FC1層追加
x = tf.keras.layers.Dense(4096, activation='relu')(x)
# FC2層追加
x = tf.keras.layers.Dense(4096, activation='relu')(x)
# 入力画像の形状
transfer_learning_inputs = base_model.inputs
# predictions層の追加
# 今回分類するクラス数を指定
image_class_num = len(image_class_names)
transfer_learning_prediction = tf.keras.layers.Dense(image_class_num, activation='softmax')(x)
# 転移学習モデル構築
transfer_learning_model = tf.keras.Model(inputs=transfer_learning_inputs,
outputs=transfer_learning_prediction)
出力層を作成します。基本的にVGG16の出力層と同じものを追加し、必要に応じて変更します。
最初のFlatten層は既存モデルと同じ平坦化処理をするので、そのままです。
FC1層とFC2層は私の場合はそのまま追加しています。
人によってはパラメータ数を4096から変更する場合があります。
この4096というパラメータ数はVGG16の1000クラス分類において適切な値です。
そのため今回のように8クラス分類しかしない場合、もっとパラメータ数を下げてもよいかもしれません。
学習率やエポック数ほどではないですが、こちらを調整することで予測精度も影響を少し受けます。
入力画像の形状は変更しないので、ベースモデルと同じにします。
この時、画像標準化をこの入力層に対して実施する人もいます。
今回は既に画像読み込み時に、標準化しているため不要です。
最後にpredictions層を追加します。
今回は独自のクラス(=ピカチュウっぽいポケモン)を分類するため、len(image_class_names)=クラス数を設定しています。
これによりモデル構築されましたが、実際に使うためにコンパイルと訓練が必要です。
(4) モデルのコンパイル
# (4) モデルのコンパイル
transfer_learning_model.compile(optimizer=
tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
| 引数 | 説明 |
|---|---|
| optimizer=tf.keras.optimizers.Adam(lr=LEARNING_RATE) | 最適化関数の指定。 一般的によく使われるAdamを使用。 |
| loss='sparse_categorical_crossentropy' | 目的関数の指定。 複数クラス分類なためSparse categorical crossentropyを使用。 |
| metrics=['accuracy'] | 評価関数の指定。 一般的なAccuracyを使用。 |
学習に用いる最適化関数・目的関数・評価関数を設定します。
今回は複数クラス分類手法でよく使われる関数を使います。
※余談ですが評価関数は結果表示などに用いられ、学習そのものには影響しません。
最適化関数を指定する際は、learning_rate(=学習率)を指定する必要があります。
最初は1e-5(=0.00001)にしていましたが、なかなか収束しないため少し大きめに3e-5としています。
これと後述するエポック数を調整することで、適切な学習を実施します。
モデルのサマリーを確認すると、手動で作成した出力層が追加され、訓練可能な状態になっています。
transfer_learning_model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
dense (Dense) (None, 4096) 102764544
_________________________________________________________________
dense_1 (Dense) (None, 4096) 16781312
_________________________________________________________________
dense_2 (Dense) (None, 8) 32776
=================================================================
Total params: 134,293,320
Trainable params: 119,578,632
Non-trainable params: 14,714,688
_________________________________________________________________
(5) モデルの学習
# (5) モデルの学習
history = transfer_learning_model.fit(img_X_train, img_Y_train,
epochs=INITIAL_EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(img_X_valid, img_Y_valid))
| 引数 | 説明 |
|---|---|
| img_X_train | 訓練画像データ |
| img_Y_train | 訓練画像の正解クラス名データ |
| epochs=INITIAL_EPOCHS | エポック数。何回繰り返し学習をするかの回数。 |
| batch_size=BATCH_SIZE | バッチサイズ。1回の処理数。 |
| validation_data=(img_X_valid, img_Y_valid) | 検証用データ |
いよいよモデルの学習を実施します。
ここで特に重要となるのはエポック数です。
過学習とならないよう、適度な値にする必要があります。
最初は30回にしていましたが、3,4回ほどで訓練・検証が収束するので、5回にしています。
3.画像分類と精度
# ------------------------------------------------------------
# 3.画像分類と精度
# ------------------------------------------------------------
# テストデータの画像分類結果を標準出力
# [損失関数, 正解率]
print(transfer_learning_model.evaluate(img_X_test, img_Y_test, verbose=0))
# 訓練と検証
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# 正解率
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
# 損失関数
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0, 10.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
転移学習で作成したモデルを用いた、テストデータに対する精度と、訓練・検証の精度は以下の通りです。
# [損失関数, 正解率]
[1.9741618633270264, 0.7676470875740051]
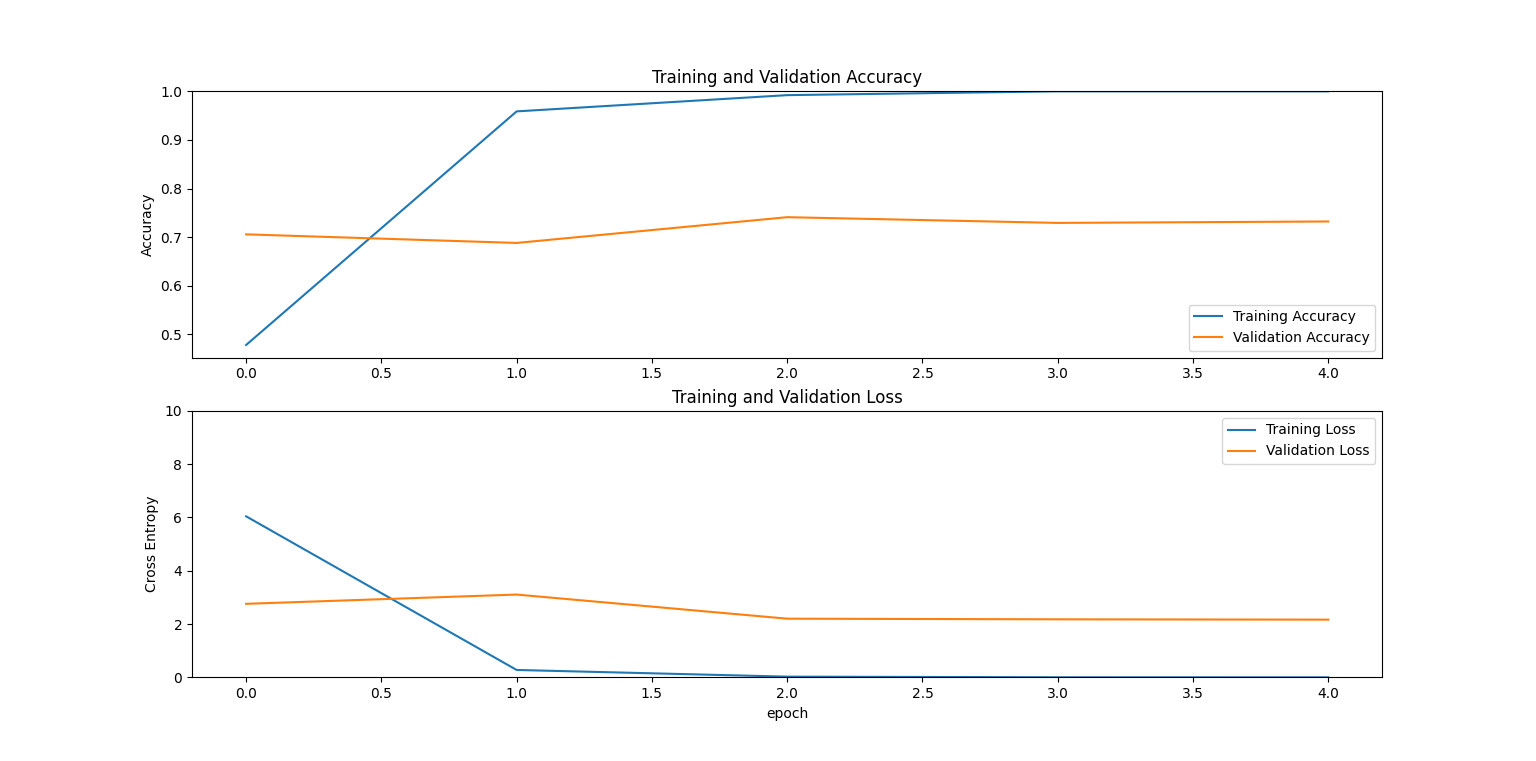
訓練・検証ともにすぐに収束しています。特に訓練は正解率が10割近くとなっており過学習気味です。
正解率は7割ほどありますが、損失関数は2.5付近となっています。
これはピカチュウっぽいポケモンの分類=類似したポケモンの分類をしたせいだと思われます。
実際に、ピカチュウ、リザードン、ゲッコウガという色も姿も大きく異る3匹で学習した結果、テスト精度は次のようになりました。
# [損失関数, 正解率]
[0.3565507233142853, 0.9407407641410828]
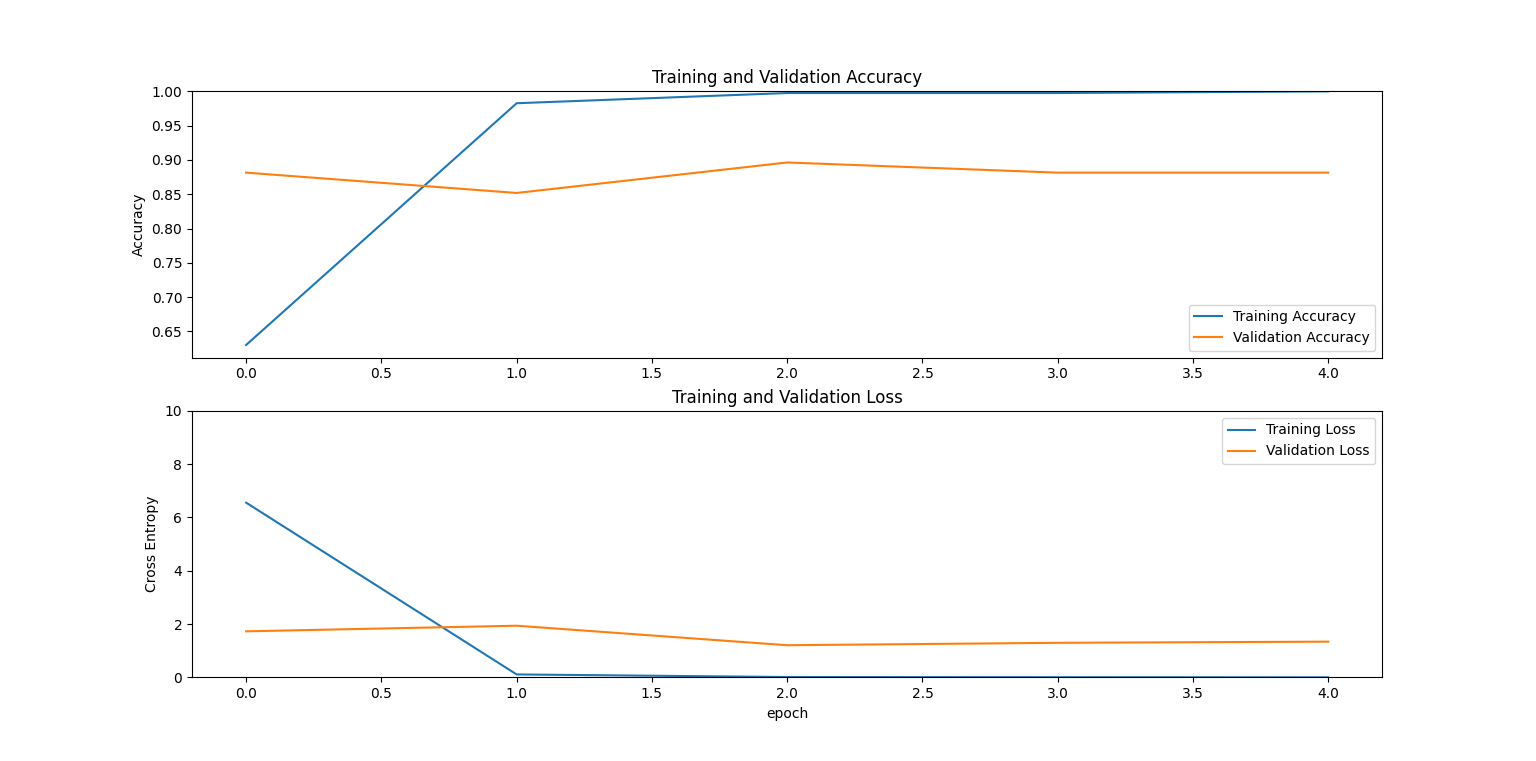
正解率は9割あり、損失関数も0.3と低めです。
ピカチュウ、リザードン、ゲッコウガならば高い精度で分類できるようです。
今後やりたいこと
ピカチュウっぽいポケモンをそれなりの精度で画像分類することに成功しました。
訓練のみに使用したのは各ポケモンに付き120枚ほどの画像ですが、成果率は思ったより出ました。
ただピカチュウと似ているためか、伸び悩んでいる点もあります。
今後は次のような改良をしたいです。
- モデルの見直し→そもそもアニメ・ゲーム・イラストであるポケモンの画像分類にVGG16が適しているのかを検討する。
- CNNの可視化→適切なモデル構築のために、画像のどのような箇所が注目されているか確認する。
- テスト結果の詳細確認→どのような画像が別のポケモンと識別されているか、より詳しく見ていく。
- 収集画像の自動化→現在は手動なので、自動で集める方法を検討する。
- 収集画像の選定→現在はアニメ、ぬいぐるみ、イラストから収集しているが、他(ゲーム、カード)からも取れないか考える。
参考
VGG16
-
VGG16の論文
https://arxiv.org/abs/1409.1556
ベースモデルとなったVGG16の論文です。VGG16の詳細な仕組みを確認するのに役立ちます。 -
深層学習論文の読解(VGG)
https://qiita.com/ttomomasa/items/b673a1e0b42a2a14a9d2
VGG16の論文を日本語で解説しているQiitaの記事です。
ただ訳すだけでなく参考リンクや補足情報があり、とても分かりやすかったです。
今回、VGG16理解のために大変参考になりました。 -
TensorFlow, KerasでVGG16などの学習済みモデルを利用 | note.nkmk.me
https://note.nkmk.me/python-tensorflow-keras-applications-pretrained-models/
今回のVGG16を試しに使ってみるにおいて参考にしたコードです。
各種動作やモデルについて詳細な説明があり、分かりやすいです。 -
Python 3.x - VGG16モデルのパラメータ数について|teratail
https://teratail.com/questions/147871
QAサイトteratailにおける、VGG16モデルのパラメータ数に関する質問と回答です。
出力層追加の際、人によってパラメータ数が異なり、どのような値がよいのか調べた結果、ここの解説が分かりやすかったです。 -
Intelligent and Secure Content-based Image Retrieval for Mobile Users
https://ieeexplore.ieee.org/document/8798734
VGG16を用いた画像検索関連の論文です。
今回、VGG16の説明のため図を引用させていただきました。
コーディング関連
-
Module: tf.keras.applications.vgg16 (TensorFlowのマニュアル)
https://www.tensorflow.org/api_docs/python/tf/keras/applications/vgg16
TensorFlowにおけるvgg16クラスのマニュアルです。
使用すべき関数や、各引数に入力すべき値について大変参考になりました。 -
tf.keras.utils.image_dataset_from_directory (TensorFlowのマニュアル)
https://www.tensorflow.org/api_docs/python/tf/keras/utils/image_dataset_from_directory
TensorFlowにおけるimage_dataset_from_directory()関数のマニュアルです。 -
tf.data.Dataset (TensorFlowのマニュアル)
https://www.tensorflow.org/api_docs/python/tf/data/Dataset
TensorFlowにおけるtf.data.Datasetクラスのマニュアルです。
読み込んだ画像が本型で取得されるため、適切な値を取り出すために、どのような機能・構造であるか参考にしました。 -
sklearn.model_selection.train_test_split (scikit-learnのマニュアル)
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html
scikit-learnにおけるtrain_test_split()関数のマニュアルです。
画像を訓練・検証・テスト分割する際に使用しました。 -
How To Split a Tensorflow Dataset into Train, Validation, and Test sets
https://towardsdatascience.com/how-to-split-a-tensorflow-dataset-into-train-validation-and-test-sets-526c8dd29438
tf.data.Datasetを複数分割する手法について説明されています。
train_test_split()関数を使ったため、今回は使用していませんが、分割手法検討において本記事を参考にしました。 -
tf.keras.Model (TensorFlowのマニュアル)
https://www.tensorflow.org/api_docs/python/tf/keras/Model
TensorFlowにおけるtf.keras.Modelクラスのマニュアルです。
モデル構築と学習において、各関数の使い方や引数へ渡すべき値について調べる際に参考になりました。
fine tuning
- Change input shape dimensions for fine-tuning with Keras
https://www.pyimagesearch.com/2019/06/24/change-input-shape-dimensions-for-fine-tuning-with-keras/
fine tuningにより入力画像サイズを変更する手法について説明したサイトです。
転移学習
-
転移学習と微調整 (TensorFlowのマニュアル)
https://www.tensorflow.org/tutorials/images/transfer_learning
TensorFlowのマニュアルで案内された転移学習のチュートリアルです。
今回の転移学習はこちらを基に作成しています。
※ベースモデルや画像データの扱いなど異なるため、差異は大きいです。
実施すべき手順や、各機能について大変参考になりました。 -
VGG16を転移学習させて「まどか☆マギカ」のキャラを見分ける
https://qiita.com/God_KonaBanana/items/2cf829172087d2423f58
VGG16の転移学習による「まどマギ」キャラ画像分類のQiita記事です。
Gitでソースコードと画像データセットも公開しており、大変参考になりました。 -
TensorFlow, Kerasで転移学習・ファインチューニング(画像分類の例) | note.nkmk.me
https://note.nkmk.me/python-tensorflow-keras-transfer-learning-fine-tuning/
TensorFlow, Kerasでの転移学習について、詳細に説明された記事です。
各処理について段階的に、詳しく解説が載っており、細かい点の調査において大変参考になりました。 -
Image Recognition with Transfer Learning (98.5%)
https://thedatafrog.com/en/articles/image-recognition-transfer-learning/
VGG16等の転移学習に関する解説とコードが書かれた記事です。
モデル構築の際に参考にしました。 -
Transfer Learning with VGG16 and Keras
https://towardsdatascience.com/transfer-learning-with-vgg16-and-keras-50ea161580b4
VGG16による転移学習に関する解説とコードが書かれた記事です。
分類レイヤーに関する調査の際に参考にしました。 -
VGGNet with TensorFlow (Transfer Learning with VGG16 Included)
https://ai.plainenglish.io/vggnet-with-tensorflow-transfer-learning-with-vgg16-included-7e5f6fa9479a
VGG16による転移学習に関する解説とコードが書かれた記事です。
モデル構築や予測に関する調査の際に参考にしました。 -
VGG16におけるKerasの前処理でmeanを引くかどうか
http://blog.abars.biz/archives/52428734.html
VGG16の前処理として、VGG16固有の標準化と一般的な標準化のどちらをを実施するかについて説明しています。
情報や議論だけでなく、精度検証もしており、VGG16の転移学習において、標準化手法検討の参考になりました。 -
【決定版】スーパーわかりやすい最適化アルゴリズム -損失関数からAdamとニュートン法-
https://qiita.com/omiita/items/1735c1d048fe5f611f80
最適化アルゴリズムを解説したQiitaの記事です。
代表的な最適化アルゴリズムを図と数式を交え、詳細に解説しています。
学習で使用するアルゴリズム選定の際、各々の特性を知るのに大変役立ちました。