投稿目的
英語で書かれた深層学習に関する論文を読むことは骨が折れます。そのため、本記事を読めば内容が分かる要約したものを書きたいと思いました。しかし、要約するには全体を正確に把握する必要がありますので、まずは論文翻訳を行いたいと思います。やり方ですが、論文pdfから一部分をクリップボードにコピーして、Webアプリ「Shaper※」で整形して、Google翻訳して、それを私になりに解釈して修正しました。※:http://dream-exp.net/shaper/
そのため、読んで分かり易いように、原文には記載されていない単語も組み入れて修正している点や、私自身が内容を掴み切れずにGoogle翻訳のままの意味不明な箇所があることをご留意頂ければと思います。論文の候補は、私も転移学習で利用したVGGに関する論文をまずは見たいという衝動にかられましたので、こちらを選びました。
論文:Very Deep Convolutional Networks for Large-Scale Image Recognition
- タイトル:大規模画像認識のための、とても深い畳込みネットワーク
- 年代:2015年4月の論文
- URL:https://arxiv.org/pdf/1409.1556.pdf
- 作者:Karen Simonyan & Andrew Zisserman
- Visual Geometry Group, Department of Engineering Science, University of Oxford
ABSTRACT(要旨)
小さい(3×3)畳み込みフィルタを有するアーキテクチャを使用して層を増したネットワークを評価します。これは従来技術の構成に対する大幅な改善がなされて、深さ16~19層にすることによって達成できることを示しています。これらの調査結果は、ImageNet Challenge 2014の1位(ローカリゼーション)と2位(分類)を確保したモデルの基礎となっています。また、他のデータセットにも一般化されています。コンピュータビジョンにおける研究を促進するために、2つの最高性能ConvNetモデルを公に利用可能にしています。
1 INTRODUCTION(導入)
畳込みネットワーク(ConvNet)は最近、大規模な画像およびビデオ認識において大きな成功を収めています。その要因は、ImageNetなどの大規模なパブリックイメージリポジトリ、およびGPUや大規模分散クラスターなどの高性能コンピューティングシステムによるものです。特に、ディープ画像認識アーキテクチャの進歩における重要な役割は、ImageNet大規模ビジュアル認識チャレンジ(ILSVRC)によって演じられてきました。そしてそれは、(高次元の浅い特徴の符号化(ILSVRC-2011の勝者)からdeepConvNets(ILSVRC-2012の勝者)までの)大規模画像分類システムの数世代にわたるたたき台として役立ってきました。
ConvNetsがコンピュータビジョンの分野でよりコモディティになるにつれて、Krizhevsky他(クリシェフスキー)(2012)の元のアーキテクチャを改善するため、より良い精度を達成するためにわずかな試みがなされてきました。例えば、ILSVRC2013への最も優れた提出物は、より小さな受容窓サイズ(=フィルターサイズ)と、より小さな最初の畳込み層の小さなストライドを利用しました。別の一連の改善は、画像全体および複数の規模にわたってネットワークを密にトレーニングおよびテストすることを扱っていました。この論文では、ConvNetアーキテクチャ設計のもう1つの重要な側面(=深さ)について説明します。この目的のために、我々はアーキテクチャの他のパラメータを固定し、そしてより多くの畳み込み層を追加することによってネットワークの深さを着実に増加させます。これは全ての層において非常に小さい(3×3)畳み込みフィルタの使用により実現可能です。
その結果、ILSVRCの分類とローカリゼーションのタスクに関して最先端の精度を達成するだけでなく、比較的単純なパイプラインの一部(例えば、ファインチューニングなしで線形SVMによって分類された深い特徴)として使用した場合でも優れた性能を達成する他の画像認識データセットにも適用可能な、はるかに正確なConvNetアーキテクチャを思いついたのです。さらなる研究を促進するために、2つの最高性能モデルをリリースしました。
この論文の残りの部分は次のように構成されています。2章ではConvNetの設定について説明します。画像分類訓練および評価の詳細は3章で説明します。そして、4章ではILSVRC分類タスクで構成を比較します。5章では論文を締めくくります。完全を期すために、付録AではILSVRC-2014オブジェクトローカライゼーションシステムについて説明し、評価し、付録Bでは他のデータセットへの非常に深い特徴の一般化について説明します。最後に、付録Cには主要なペーパーリビジョンのリストを示します。
2 CONVNET CONFIGURATIONS(畳込みネットワーク構成)
畳込み層を多層にしたことによってもたらされた改良点を、公平な状況で測定するために、すべての畳込みレイヤ構成は、Ciresan(チレサン(2011)※1)やKrizhevsky(クリシェフスキー(2012)※2)らにインスパヤーされた同じ原理を使用して設計されています。このセクションでは、まずConvNet構成の全体的なレイアウトについて説明(2.1節)し、次に、評価で使用した特定の構成について詳しく説明します(2.2節)。それから、我々の設計の選択について議論し、先行技術(=従来の技術)と比較します(2.3節)。
※1:Flexible, High Performance Convolutional Neural Networks for Image Classification
http://people.idsia.ch/~juergen/ijcai2011.pdf
※2:ImageNet Classification with Deep Convolutional Neural Networks
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
2.1 ARCHITECTURE(構造)
トレーニング中、ConvNetsへの入力は固定サイズの224×224 RGB画像です。私たちがする唯一の前処理は、各ピクセルからトレーニングセットで計算された平均RGB値を差し引くことです。画像は、非常に小さな受容野:3×3(左右、上下、中央の概念をとらえるための最小サイズ)のフィルタを使用した、畳込みレイヤの層を通過します。構成の1つでは、入力チャネルの線形変換(それに続く非線形性)として見ることができる1×1畳み込みフィルタも利用する。畳み込みストライドは1ピクセルに固定されています。畳込みレイヤ入力のパディング空間は、畳み込み後に空間解像度が維持されるようなものであり、すなわち、パディングは3×3畳込み対して1ピクセルである。空間プーリングは5つの最大プーリングレイヤによって実行されます。そして、それはいくつかの畳込みレイヤの後に続きます(すべての畳込みレイヤの後に最大プーリングが続くわけではありません)。最大プーリングはストライド2で、2×2ピクセルのウィンドウで実行されます。
畳み込み層のスタック(異なるアーキテクチャでは異なる深さを有する)の後に、3つの全結合層(FC)が続きます。最初の2つはそれぞれ4,096チャンネルを持ち、3つ目は1,000のILSVRC分類を実行し、それ故に1,000チャンネルを含みます(各クラスに1つ)。最後の層はsoft-max層です。全結合層の構成はすべてのネットワークで同じです。
すべての隠れ層は、整流性(ReLU(Krizhevsky他 2012))の非線形性を備えています。私達のネットワークのどれも(1つを除いて)Local Response Normalization(LRN)正規化を含んでいないことに注意します(Krizhevsky他 2012)。4章で示すように、このような正規化はILSVRCデータセット上の性能を向上させないばかりか、メモリ消費および計算時間の増加を招きます。該当する場合、LRNレイヤのパラメータは(Krizhevsky他 2012)のものです。
2.2 CONFIGURATIONS(設定)
この論文で評価されたConvNet構成は、各列に1つずつ表1に概説されています。以下では、ネットをそれらの名前(A~E)で参照します。すべての構成はセクション2.1に提示された一般的な設計に従います。 また、すべての構成は深さのみが異なります:ネットワークAの11個の重み層(8個の畳込み層および3個のFC層)から、ネットワークEの19個の重み付け層(16個の畳込み層および3個のFC層)。 畳込み層の幅(=チャネル数)はかなり少なく、最初のレイヤの64から始まり、512に達するまで各max-poolingレイヤの後2倍に増加します。
表2では、各構成のパラメーター数を報告しています。深さが大きなにも関わらず、私たちのネットの重み数は、より大きな畳込み層・幅と受容野を持つより浅いネットの重み数よりも大きくありません。(Sermanet等。2014の144Mの重み※)※https://arxiv.org/pdf/1312.6229.pdf
<表1:ConvNetの設定>
※深さは左から右に増加する。conv(カーネルサイズ)-(チャネル数)。簡潔さを優先して活性化関数ReLUは記載していない
<表2:パラメータの数(in millions)>

2.3 DISCUSSION(考察)
私たちのConvNet構成は、ILSVRC-2012(Krizhevsky等 2012)やILSVRC-2013コンペティション(Zeiler&Fergus 2013; Sermanet等 2014)のトップ作品に使用されているものとはかなり異なります。最初の畳込み層では比較的大きな受容野を使うのではなく(例えば、(Krizhevsky等 2012)のストライド4のフィルターサイズ11x11、または(Zeiler&Fergus、2013; Sermanet等 2014)のストライド2のフィルターサイズ7x7)、我々はネット全体にわたり非常に小さい3x3のフィルターを使用します。そして、それはストライド1ですべての入力ピクセルが畳込まれます。フィルターサイズ3×3の畳込み層(その間に空間的プーリングがない)2つは、フィルターサイズ5×5の畳込み層の効果があることが簡単に分かります。同様にフィルターサイズ3×3の畳込み層3つは、フィルターサイズ7×7の畳み込みの効果があります。それでは、フィルターサイズ7×7の単一の畳込み層の代わりに、フィルターサイズ3×3で3回畳み込みを使うことによって得たものは何でしょうか? 最初に、単一の畳込み層の代わりに、決定関数をより識別可能にする3つの非線形の活性化関数ReLUを組み入れます。次に、パラメータ数を減らします。3層(3×3)畳み込みスタックの入力と出力の両方にCチャネルがあると仮定すると、スタックは3×(3×3×C×C)=27C×Cの重みでパラメータ化されます。同時に、単一畳込み層のフィルターサイズ(7×7)は7×7×C×C=49C×Cの重みパラメータです。すなわち81%以上。これは畳み込みフィルター(7×7)に正則化を課すものとして見ることができます。フィルターサイズ(3×3)(間に非線形性が挿入されます)による分解を強制します。
フィルターサイズ(1×1)の畳込みを組み込むことは(表1の構成C)は、畳み込み層の受容野に影響を与えることなく決定関数の非線形性を増加させる方法です。たとえ1×1畳込みは本質的に同じ次元の空間への線形射影(入力および出力チャネルの数は同じである)であるとしても、さらなる非線形性がReLU関数によって導入されます。1×1畳込み層は最近「ネットワークインネットワーク」アーキテクチャ(Lin等 2014※)で利用されていることに留意してください。※https://arxiv.org/pdf/1312.4400.pdf
小型の畳み込みフィルタは、以前にCiresan等(チレサン(2011)※1)らによって使用されてきました。しかし、彼らのネットワークは私たちのものよりかなり浅く、そして彼らは大規模なILSVRCデータセットで評価しなかったです。グッドフェロー他(2014)は深いConvNets(11の重さの層)を街路番号認識のタスクに適用して、深さの増加がより良いパフォーマンスをもたらすことを示しました。ILSVRC-2014分類タスクのトップパフォーマンスエントリーであるGoogLeNet(Szegedyら 2014)は、私たちの仕事とは無関係に開発されましたが、非常に深いConvNet(22重みレイヤー)と小さな畳み込みフィルタ(3×3とは別に、彼らは1×1と5×5の畳込みも使用します)に基づいている点が似ています。しかしながら、それらのネットワークトポロジーは我々のものよりも複雑であり、そして計算量を減少させるために特徴マップの空間解像度は第1層においてより積極的に減少されています。4.5節で示されるように、私達のモデルは単一ネットワークの分類精度に関しては、Szegedy(セゲディ(2014)※2)等のそれより優れています。
※1 http://people.idsia.ch/~juergen/ijcai2011.pdf
※2 https://arxiv.org/pdf/1409.4842.pdf
3 CLASSIFICATION FRAMEWORK(分類フレームワーク)
前の章では、ネットワーク構成の詳細について説明しました。この章では、ConvNetのトレーニングと評価の詳細について説明します。
3.1 TRAINING(学習)
ConvNetトレーニング手順は一般にKrizhevsky(クリシェフスキー(2012))等に従います。(後で説明するように、マルチスケールトレーニング画像から入力クロップをサンプリングすることを除く)。すなわち、訓練は、(バックプロパゲーション(LeCun等 1989)に基づく)ミニバッチ勾配降下を用いた多項ロジスティック回帰を目的関数として、モーメンタムを用いて最適化することによって行われます。バッチサイズは256、モメンタムは0.9に設定されました。トレーニングは、重み減衰(L2ペナルティ乗数を「5×10の-4乗」に設定)および最初の2つの全結合層のドロップアウト正則化(ドロップアウト率を0.5に設定)を行いました。学習率は当初0.01に設定され、その後検証セットの精度が向上しなくなったときに10倍減少した。合計で、学習率は3回減少し(つまり最後の学習率は0.00001)、学習は37万回のイテレーション(74エポック)後に停止しました。我々は、Krizhevsky(クリシェフスキー(2012))に比べて、パラメータの数が多く、ネットの深さが大きいにもかかわらず、ネットワークが収束するのに必要なエポックが少ないと推測します。その理由は(a)大きな深さと小さな畳込みフィルターサイズによって、暗黙的に正則化されていたこと。(b)特定の層の事前初期化によるものだと思います。
ネットワークの重みの初期化は重要です。初期化がうまくいかないと、ディープネットの勾配が不安定になるため学習が止まる可能性があるからです。この問題を回避するために、我々は、ランダムな初期化で訓練されるのに十分浅い構成A(表1)を訓練することから始めました。次に、より深いアーキテクチャをトレーニングするときに、最初の4つの畳み込み層と最後の3つの全結合層をネットAの層で初期化しました(中間層はランダムに初期化しました)。我々は事前に初期化された層の学習率を減少させず、それらは学習中に変化することを可能にしました。ランダム初期化(該当する場合)のために、ゼロ平均と10の-2乗の分散を持つ正規分布から重みをサンプリングしました。バイアスはゼロで初期化されました。論文の提出後に、Glorot&Bengio(2010)のランダム初期化手順を使用することによって(今回のような)事前トレーニングなしに重みを初期化することが可能であることがわかったことは注目に値します。
固定サイズの224×224のConvNet入力画像を取得するために、リスケーリングされたトレーニング画像からランダムにクロップされました(SGDのイテレーション毎、画像毎に1つのクロップ)。トレーニングセットをさらに強化するために、クロップはランダムな水平反転とランダムなRGBカラーシフトを経ました(Krizhevsky等 2012)。トレーニング画像のリスケーリングは以下で説明します。
トレーニング画像のサイズ
等方的にリスケーリングされたトレーニング画像の最小の側をSとします。そこからConvNet入力が切り取られます(トレーニングスケールとしてもSを参照します)。クロップサイズは224×224に固定されていますが、原則としてSは224以上の任意の値を取ることができます。S=224の場合、クロップはトレーニング画像の最も小さい辺全体に渡って全体画像統計を取得します。S≫224では、クロップは小さなオブジェクトまたはオブジェクト部分を含む画像の小さな部分に対応します。
トレーニングスケールSを設定するための2つのアプローチを検討します。1つ目はSを固定することです。これはシングルスケールトレーニングに対応します(サンプリングされたクロップ内の画像コンテンツは依然としてマルチスケール画像統計を表すことができます)。我々の実験では、2つの固定スケールで訓練されたモデルを評価した:S=256(これは先行技術(Krizhevskyら、2012年;Zeiler&Fergus、2013年;Sermanetら、2014年)で広く使用されている)とS=384。ConvNet構成では、最初にS=256を使用してネットワークをトレーニングしました。S=384ネットワークのトレーニングをスピードアップするために、S=256で事前トレーニングされた重みを使用して初期化しました。そして、我々は小さな初期の学習率は0.001(10の-3乗)を使用しました。
Sを設定するための2つ目のアプローチはマルチスケールトレーニングであり、各トレーニング画像は、ある範囲[Smin、Smax](我々はSmin=256およびSmax=512を用いた)からSをランダムにサンプリングすることによって個々にリスケーリングされます。 画像内のオブジェクトはサイズが異なる可能性があるので、トレーニング中にこれを考慮に入れることが有益です。これは、スケールジッタリングによるトレーニングセットの拡張と見なすこともできます。この場合、単一のモデルで、広範囲のスケールにわたってオブジェクトを認識するようにトレーニングされます。速度上の理由から、固定スケールS=384で事前に訓練された、同じ構成を持つ単一スケールモデルのすべてのレイヤーをファインチューニングすることによって、マルチスケールモデルを訓練しました。
3.2 TESTING(テスト)
テスト時には、訓練されたConvNetと入力画像が与えられると、次のように分類されます。最初は、Qとして示される、予め定義された最小の画像側に等方的に再スケーリングされます(我々はそれをテストスケールとして参照する)。我々は、Qが必ずしも訓練スケールSに等しいとは限らないことに注意します(4章で示すように、各Sに対してQのいくつかの値を使用することは性能の向上をもたらす)。次に、(Sermanet等。2014)と同様の方法で、リスケーリングされたテスト画像上にネットワークを密に適用します。すなわち、最初に全結合層が畳込み層(最初のFC層から7×7の畳込み層、最後の2つのFC層から1×1の畳込み層)へ変換されます。結果として得られる完全畳み込みネットは、全体の(切り抜かれていない)画像に適用されます。その結果、入力画像サイズに応じて、クラス数に等しいチャンネル数と可変空間解像度を持つクラススコアマップが得られます。最後に、画像に対するクラススコアの固定サイズのベクトルを得るために、クラススコアマップは空間的に平均されます(合計プールされる)。また、画像を水平に反転させることでテストセットを増やします。元の画像と反転した画像のソフトマックスクラスの後部を平均して、画像の最終スコアを取得します。
完全畳み込みネットワークは画像全体に適用されるため、テスト時に複数のクロップをサンプリングする必要はなく、各クロップに対してネットワークの再計算が必要となるため効率が低下します。同時に、Szegedy等(2014)によってなされたように、一組の大規模なクロップを使うことです。完全畳み込みネットと比較して入力画像のより良いサンプリングをもたらすので、精度を改善することができます。また、コンボリューション境界条件が異なるため、マルチクロップ評価はdense評価を補完します。ConvNetをクロップに適用すると、畳込まれた特徴マップにゼロが埋め込まれます。一方、dense評価の場合は同じクロップのパディングが自然に発生します。画像の隣接部分から(畳込みと空間プーリングの両方のために)、それは全体的なネットワーク受容野を実質的に増加させるので、より多くの文脈がとらえられます。実際には、複数のcropの計算時間が増えても精度が向上するわけではないと考えていますが、参考までに、スケールあたり50crop(5x5の標準グリッドで2フリップ)を使用してネットワークを評価します。3スケール以上のcrop、これはSzegedy等(2014)によって使用された4スケール以上の144cropに匹敵します。
3.3 IMPLEMENTATION DETAILS(実装の詳細)
私たちの実装は公に入手可能なC++ Caffeツールボックス(Jia、2013)(2013年12月に分岐)から成り立ってていますが、重要な変更が含まれています。そして、複数のスケール(上述のように)でフルサイズ(クロップされていない)画像をトレーニングして評価するだけではなく、単一のシステムにインストールされた複数のGPUでトレーニングや評価を行うことができました。マルチGPUトレーニングはデータの並列性を利用し、トレーニング画像の各バッチを複数のGPUバッチに分割し、各GPUで並行して処理することによって実行されます。GPUバッチ勾配が計算された後、それらはフルバッチの勾配を得るために平均化されます。勾配計算はGPU間で同期しているため、結果は1つのGPUでトレーニングした場合とまったく同じです。
ネットのさまざまな層に対してモデルとデータの並列処理を採用するConvNetトレーニングをスピードアップするためのより洗練された方法が最近提案されている間(Krizhevsky、2014年)、単一のGPUを使用する場合と比較して、概念的にはるかに単純な方式が既製の4-GPUシステムで3.75倍のスピードアップをすでに提供していることを我々は見つけました。4つのNVIDIA Titan Black GPUを搭載したシステムでは、アーキテクチャにもよりますが、1つのネットのトレーニングに2〜3週間かかりました。
4 CLASSIFICATION EXPERIMENTS(分類の実験)
データセット
この章では、ILSVRC-2012データセット(ILSVRC 2012–2014の課題に使用された)で、説明したConvNetアーキテクチャによって達成された画像分類結果を示します。データセットには1,000クラスの画像が含まれており、トレーニング(1.3M画像)、検証(50K画像)、テスト(クラスラベルを隠した100K画像)の3つのセットに分けられます。分類性能は、2つの尺度、すなわちトップ1とトップ5の誤差を使用して評価されます。前者は多クラス分類エラー、すなわち誤って分類された画像の割合である。後者はILSVRCで使用される主な評価基準であり、グランドトゥルースカテゴリ(=真の正解のカテゴリ)が上位5つの予測カテゴリの外側の、画像の割合として計算されます。大部分の実験では、検証セットをテストセットとして使用しました。テストセットで特定の実験も実施され、ILSVRC-2014コンペティションへ「VGG」チームとして参加し、公式のILSVRCサーバーに提出されました(Russakovsky等。2014)。
※コメント:訓練データ130万枚、検証データ5万枚、テストデータ10万枚あり、それぞれ分かれている。ILSVRCの画像分類の評価基準は、提出した結果のトップ5に正解が含まれていない場合の割合であること。つまり不正解割合を評価基準にしています。
4.1 SINGLE SCALE EVALUATION(シングルスケール評価)
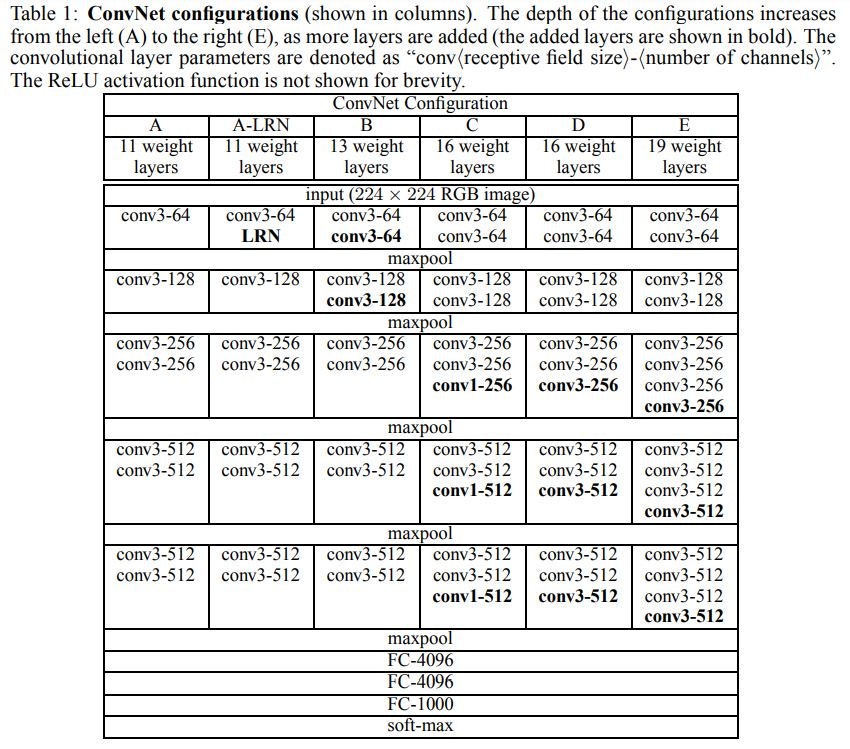
私たちは2.2節で説明した層構成で、単一のスケールで個々のConvNetモデルの性能を評価することから始めます。テスト画像サイズは次のように設定した:固定Sに対してQ=S、Q=0.5(Smin+Smax)ジッタに対してS∈S[Smin、Smax]。結果を表3に示す。
まず、ローカル応答正規化(A-LRNネットワーク)を使用しても、モデルAでは改善されません。したがって、より深いアーキテクチャでは正規化を使用しません(B~E)。
次に、ConvNetの深さが増えると分類誤差が減少することを確認します。Aの11層からEの19層までです。特に、同じ深さにも関わらず、構成C(3つの1×1の畳込み層がある)が、ネットワーク全体で3×3の畳込み層を使用する構成Dよりもパフォーマンスが劣る点です。これは、追加の非線形性が役立つ一方で(CはBよりも優れている)、無視できない受容野をもつconvフィルタ(DはCより優れています)を使用して空間コンテキストを捉えることも重要であることを示しています。私たちのアーキテクチャのエラー率は19層の深さに達すると飽和しますが、より深いモデルでさえより大きなデータセットには有益かもしれません。また、「ネットB」と「5つの5×5畳込みを持つ浅いネット」と比較しました。これは、ネットBにある「3×3畳込み層の組み」と、「単一の5×5畳込み層」を置き換えただけの、つまりBに由来するモデルです(2.3節で説明したよう、それぞれ同じ受容野を持つ)。浅いネットのトップ1の誤差は、(中央のクロップ上で)Bのそれより7%高いと測定され、これは、小さいフィルターを有する深いネットが、より大きいフィルターを有する浅いネットよりも優れていることを裏付けます。
最後に、トレーニング時のスケールジッタリング(S∈[256;512])は、テスト時に単一のスケールが使用されていても、サイドが最小に固定された画像(S=256またはS=384)でトレーニングするよりもはるかに優れた結果をもたらします。これは、スケールジッタリングによるトレーニングセットの拡張が、マルチスケール画像統計をキャプチャするために実際に役立つことを裏付けます。
<表3:単一のテストスケールでのConvNetのパフォーマンス>
4.2 MULTI-SCALE EVALUATION(マルチスケール評価)
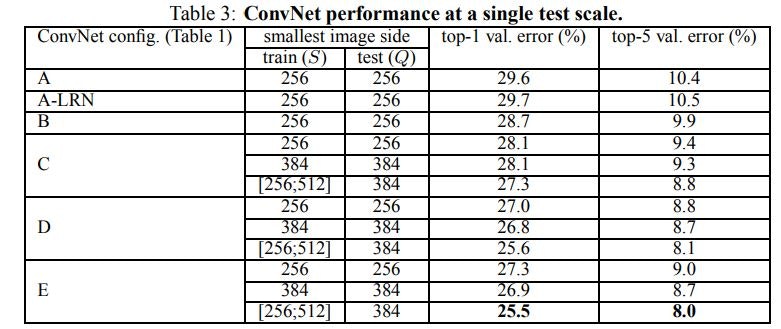
ConvNetモデルを1つのスケールで評価したので、次にテスト時にスケールジッタリングの影響を評価します。それは、テスト画像のいくつかのリスケーリングされたバージョン(Qの異なる値に対応する)上でモデルを実行し、続いて結果として得られるクラスの後部を平均化することから成ります。トレーニングスケールとテストスケールの間の大きな不一致がパフォーマンスの低下をもたらすことを考慮して、固定Sでトレーニングされたモデルは、トレーニングサイズに近い3つのテスト画像サイズで評価されました。Q={S-32、S、S+32} 。同時に、トレーニング時のスケールジッタリングにより、テスト時にネットワークをより広範囲のスケールに適用できるため、モデルは変数S∈[Smin;Smax]より広い範囲のサイズQ={Smin,0.5(Smin+Smax),Smax}を評価しました。
表4に示されている結果は、テスト時のスケールジッタリングが(表3に示されている単一のスケールで同じモデルを評価した場合と比較して)パフォーマンスが向上することを示しています。以前と同様に、最も深い設定(DとE)が良い結果をだし、スケールジッタリングは固定された最小のサイドSを使用したトレーニングよりも優れています。検証セットにおける我々の単一ネットワークの最高性能は、24.8%:トップ1エラー、7.5%:トップ5エラーです(表4で太字で強調表示されています)。テストセットでは、構成Eは7.3%のトップ5エラーを達成します。
<表4:複数のテストスケールでのConvNetの性能>
4.3 MULTI-CROP EVALUATION(マルチクロップ評価)
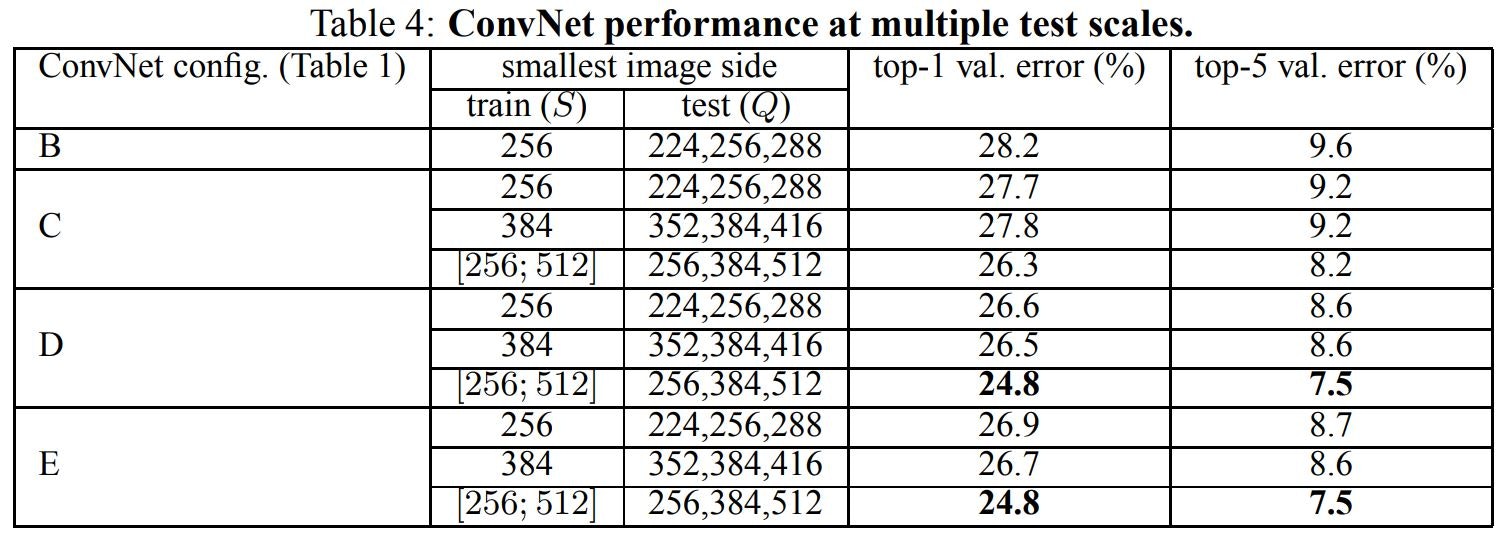
表5では、denseConvNet評価とマルチクロップ評価を比較しています(詳細は3.2節を参照してください)。また、softmaxの出力を平均することによって、2つの評価手法の相補性を評価します。見てわかるように、マルチクロップ評価を使用することはdense評価よりわずかによく機能します、そして2つのアプローチはそれらの組み合わせがそれらのそれぞれよりも優れているので確かに補完的です。上記のように、我々はこれが畳み込み境界条件の異なる取り扱いによるものであると仮定します。
<表5:ConvNet評価手法の比較>
全ての実験において、訓練スケールSは[256;512]からサンプリングされた。そして3つのテストスケールQが考慮された:{256、384、512}。
4.4 CONVNET FUSION(ConvNetの融合)
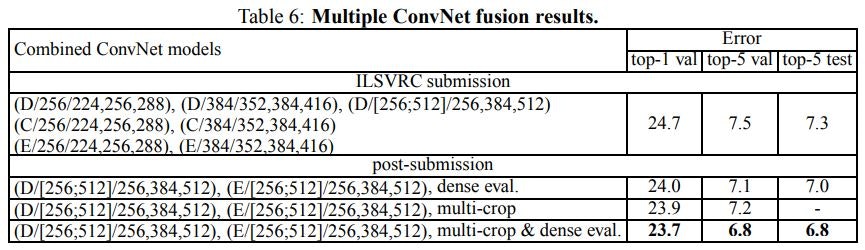
これまで、個々のConvNetモデルのパフォーマンスを評価してきました。今回の実験では、いくつかのモデルの出力を、それらのsoft-maxクラスの後部を平均することによって結合します。これにより、複数のモデルの相補性によりパフォーマンスが向上します。この手法は2012年および2013年のトップILSVRCサブミッションで使用されました。
結果を表6に示します。ILSVRC提出時までに、我々は、(全ての層ではなく、全結合層のみをファインチューニングすることによって)マルチスケールモデルDだけではなくシングルスケールネットワークだけを訓練しました。結果として得られる7つのネットワークのアンサンブルは、7.3%のILSVRCテストエラーを示します。提出後、我々は2つの最高性能のマルチスケールモデル(構成DとE)のみのアンサンブルを検討しました。それはdense評価を用いてテスト誤差を7.0%、dense評価とマルチクロップ評価を組み合わせて6.8%に減らしました。参考までに、当社の最高性能の単一モデルは7.1%の誤差を達成しています(モデルE、表5)。
<表6:複数のConvNet融合結果>
4.5 COMPARISON WITH THE STATE OF THE ART(最新技術との比較)
最後に、表7の通り、最先端の技術と比較します。ILSVRC-2014チャレンジの分類タスクでは、「VGG」チームが7つモデルのアンサンブルを使用して7.3%のテストエラーで2位を確保しました。提出後、2つのモデルのアンサンブルを使用してエラー率を6.8%に下げました。
<表7:ILSVRC分類における最新技術との比較>
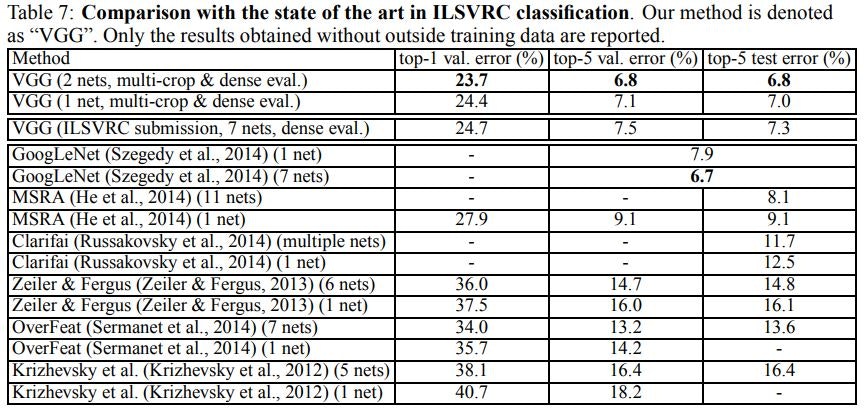
表7からわかるように、我々のモデルは、ILSVRC-2012およびILSVRC-2013コンペティションで最高の結果を達成した前世代のモデルを大幅に上回っています。我々の結果は分類タスクの勝者(6.7%のエラーでGoogLeNet)に関しても競争力があり、外部トレーニングデータで11.2%、それなしで11.7%を達成したILSVRC-2013受賞作品Clarifaiを大幅に上回りました。 私たちの最良の結果がたった2つのモデルを組み合わせることによって達成されることを考えると、これは注目に値します - ほとんどのILSVRC提出で使用されるよりかなり少ないです。シングルネット性能に関しては、私たちのアーキテクチャは最良の結果(7.0%テストエラー)を達成し、シングルGoogLeNetを0.9%上回っています。特に、我々はLeCunらの古典的なConvNetアーキテクチャから逸脱しませんでした。しかし深さを実質的に増やすことによってそれを改善しました。
5 CONCLUSION(結び)
この研究では、大規模画像分類のために非常に深い畳み込みネットワーク(最大19の重みレイヤ)を評価しました。 表現の深さは分類の正確さにとって有益であり、ImageNetチャレンジデータセットに対する最先端の性能は、大幅に増加した深さを持った従来のConvNetアーキテクチャを使用して達成できることが実証された。
付録では、モデルが広範囲のタスクとデータセットにうまく一般化(適用)され、より複雑でない画像表現を中心に構築された認識パイプラインのマッチングまたは性能の向上を示しています。 我々の結果はまたもや視覚的表現における深さの重要性を確認します。
ここまでが論文の翻訳となります。以下では、この論文をより理解するために、単語の補足や、図、コードを記載しました。
単語の補足
**crop:**Data Augumentationの1つで、画像の中から一部を切り出す「crop処理」のこと。ちなみに、左右にひっくり返す「flip処理」もData Augumentationの1つです。
**receptive field:**受容野。ニューロンに変化を生じさせる局所的な空間領域のこと(by ゼロから作るDeepLearning(斎藤 康毅著)P247より)。ちょっとわからずらいと思いますので、こちらのサイトで詳しく解説されています。受容野で検索してみて下さい。https://nnadl-ja.github.io/nnadl_site_ja/chap6.html
scale jittering(スケールジッタリング):
画像に「揺らぎ」を加える手法のようです。
ネットワーク図
引用元サイト:https://www.abtosoftware.com/blog/kitchen-furniture-appliances-recognition-in-photos
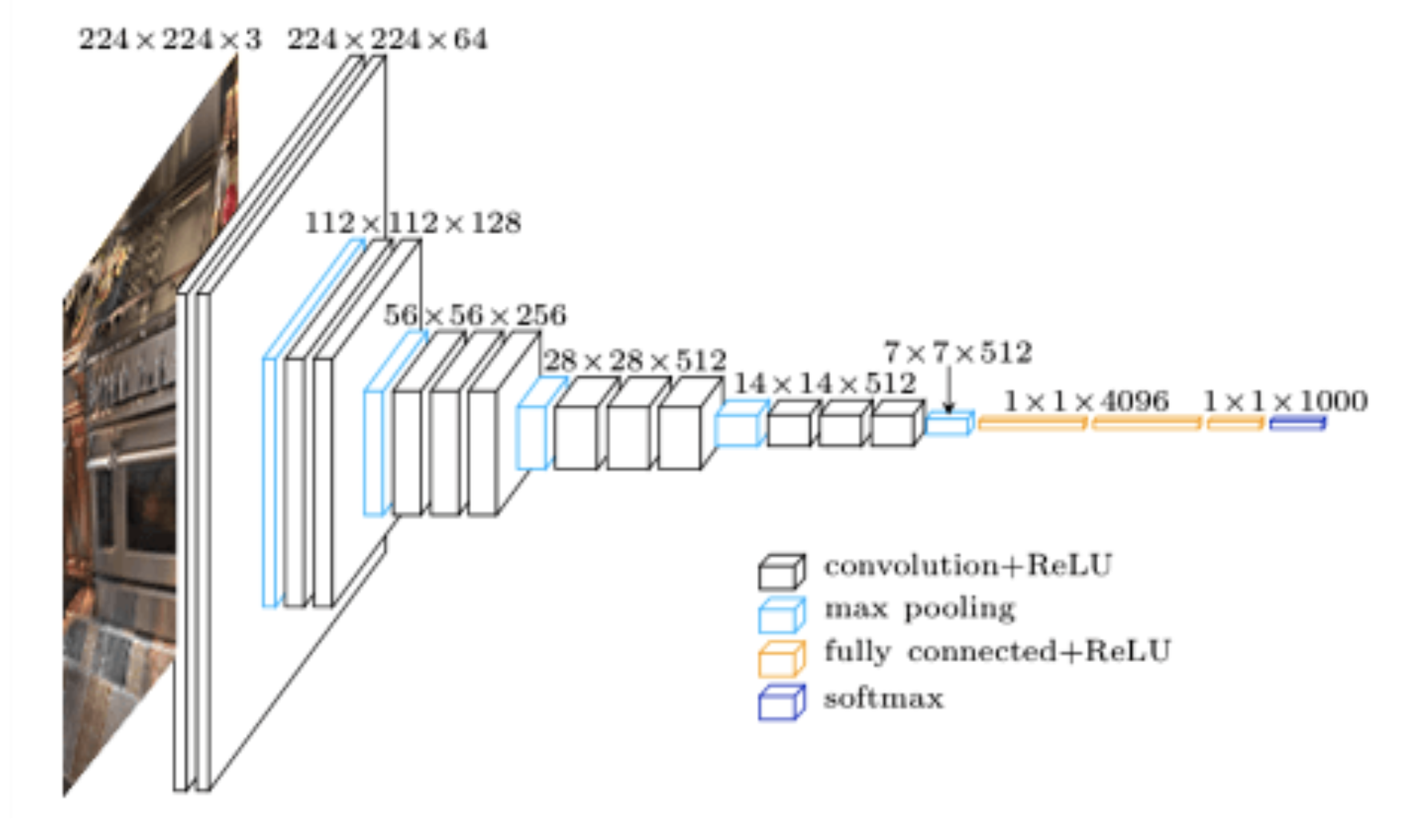
モデルサマリー
VGG16のモデルのサマリーです。パッと見、「input_1(InputLayer)」から「predictions(Dense)」まで23層あるよう見えます。16層だと言われているのに違うじゃん!!と思いましたが、16層は重み付き層のことなのです。Param列の数字が"重み"と"バイアス"の数です。この層を数えるとちょうど16層あります。Total params: 138,357,544とありますが、VGG16のパラメータ数が約1億3,800万あります。誤差逆伝播では、このパラメータの値を更新する事になるのです。
from keras.applications.vgg16 import VGG16
# include_top: ネットワークの出力層側にある3つの全結合層を含むかどうか
# weights: None (ランダム初期化) か 'imagenet' (ImageNetで学習した重み) のどちらか一方.
model = VGG16(include_top=True, weights='imagenet')
# モデルの要約を出力します.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
vgg16のソース(Github)
https://github.com/keras-team/keras-applications/blob/master/keras_applications/vgg16.py
活性化関数にreluが使われていることがわかります。
"""VGG16 model for Keras.
# Reference
- [Very Deep Convolutional Networks for Large-Scale Image Recognition](
https://arxiv.org/abs/1409.1556)
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import os
from . import get_submodules_from_kwargs
from . import imagenet_utils
from .imagenet_utils import decode_predictions
from .imagenet_utils import _obtain_input_shape
preprocess_input = imagenet_utils.preprocess_input
WEIGHTS_PATH = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg16_weights_tf_dim_ordering_tf_kernels.h5')
WEIGHTS_PATH_NO_TOP = ('https://github.com/fchollet/deep-learning-models/'
'releases/download/v0.1/'
'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5')
def VGG16(include_top=True,
weights='imagenet',
input_tensor=None,
input_shape=None,
pooling=None,
classes=1000,
**kwargs):
backend, layers, models, keras_utils = get_submodules_from_kwargs(kwargs)
if not (weights in {'imagenet', None} or os.path.exists(weights)):
raise ValueError('The `weights` argument should be either '
'`None` (random initialization), `imagenet` '
'(pre-training on ImageNet), '
'or the path to the weights file to be loaded.')
if weights == 'imagenet' and include_top and classes != 1000:
raise ValueError('If using `weights` as `"imagenet"` with `include_top`'
' as true, `classes` should be 1000')
# Determine proper input shape
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=32,
data_format=backend.image_data_format(),
require_flatten=include_top,
weights=weights)
if input_tensor is None:
img_input = layers.Input(shape=input_shape)
else:
if not backend.is_keras_tensor(input_tensor):
img_input = layers.Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
# Block 1
x = layers.Conv2D(64, (3, 3),
activation='relu',
padding='same',
name='block1_conv1')(img_input)
x = layers.Conv2D(64, (3, 3),
activation='relu',
padding='same',
name='block1_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block1_pool')(x)
# Block 2
x = layers.Conv2D(128, (3, 3),
activation='relu',
padding='same',
name='block2_conv1')(x)
x = layers.Conv2D(128, (3, 3),
activation='relu',
padding='same',
name='block2_conv2')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block2_pool')(x)
# Block 3
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv1')(x)
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv2')(x)
x = layers.Conv2D(256, (3, 3),
activation='relu',
padding='same',
name='block3_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block3_pool')(x)
# Block 4
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv1')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv2')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block4_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block4_pool')(x)
# Block 5
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv1')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv2')(x)
x = layers.Conv2D(512, (3, 3),
activation='relu',
padding='same',
name='block5_conv3')(x)
x = layers.MaxPooling2D((2, 2), strides=(2, 2), name='block5_pool')(x)
if include_top:
# Classification block
x = layers.Flatten(name='flatten')(x)
x = layers.Dense(4096, activation='relu', name='fc1')(x)
x = layers.Dense(4096, activation='relu', name='fc2')(x)
x = layers.Dense(classes, activation='softmax', name='predictions')(x)
else:
if pooling == 'avg':
x = layers.GlobalAveragePooling2D()(x)
elif pooling == 'max':
x = layers.GlobalMaxPooling2D()(x)
# Ensure that the model takes into account
# any potential predecessors of `input_tensor`.
if input_tensor is not None:
inputs = keras_utils.get_source_inputs(input_tensor)
else:
inputs = img_input
# Create model.
model = models.Model(inputs, x, name='vgg16')
# Load weights.
if weights == 'imagenet':
if include_top:
weights_path = keras_utils.get_file(
'vgg16_weights_tf_dim_ordering_tf_kernels.h5',
WEIGHTS_PATH,
cache_subdir='models',
file_hash='64373286793e3c8b2b4e3219cbf3544b')
else:
weights_path = keras_utils.get_file(
'vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5',
WEIGHTS_PATH_NO_TOP,
cache_subdir='models',
file_hash='6d6bbae143d832006294945121d1f1fc')
model.load_weights(weights_path)
if backend.backend() == 'theano':
keras_utils.convert_all_kernels_in_model(model)
elif weights is not None:
model.load_weights(weights)
return model