<科目> 機械学習
目次
第一章:線形回帰モデル
[第二章:非線形回帰モデル]
(https://qiita.com/matsukura04583/items/baa3f2269537036abc57)
[第三章:ロジスティク回帰モデル]
(https://qiita.com/matsukura04583/items/0fb73183e4a7a6f06aa5)
[第四章:主成分分析]
(https://qiita.com/matsukura04583/items/b3b5d2d22189afc9c81c)
[第五章:アルゴリズム1(k近傍法(kNN))]
(https://qiita.com/matsukura04583/items/543719b44159322221ed)
[第六章:アルゴリズム2(k-means)]
(https://qiita.com/matsukura04583/items/050c98c7bb1c9e91be71)
[第七章:サポートベクターマシン]
(https://qiita.com/matsukura04583/items/6b718642bcbf97ae2ca8)
第二章:非線形回帰モデル
非線形回帰モデルの説明
- 複雑な非線形構造を内在する現象に対して、非線形回帰モデリングを実施
- データの構造を線形で捉えられる場合は限られる
- 非線形な構造を捉えられる仕組みが必要
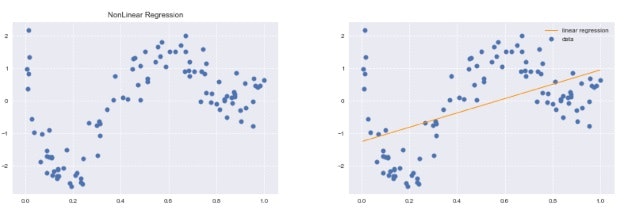
-
基底展開法
- 回帰関数として、基底関数と呼ばれる既知の非線形関数とパラメータベクトルの線型結合を使っている
- 未知パラメータは線形回帰モデルと同様に最小2乗法や最尤法により推定
- $$y_i=f(x_i)+\epsilon_i$$ $$y=w_0+\sum_{j=1}^{m} W_j\phi_j(x_i)+\epsilon_i$$
線形の写像に$$\phi$$の部分が掛けられて非線形化しているだけで、線形モデルと実はあまり変わらない。
-
よく使われる基底関数
-
多項式関数
-
ガウス型基底関数
-
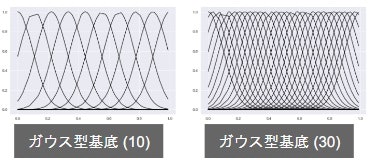
-
スプライン関数/ Bスプライン関数
-
-
1次元の基底関数に基づく非線形回帰
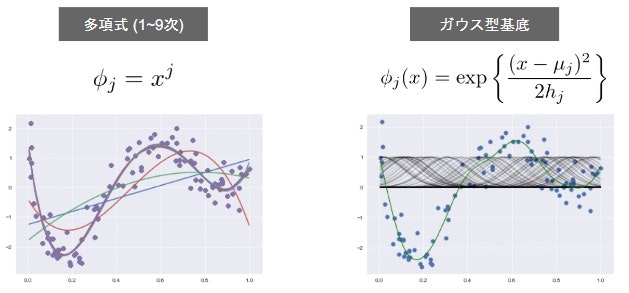
-
2次元の基底関数に基づく非線形回帰
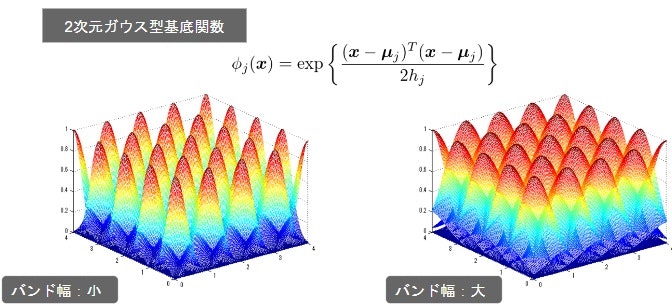
-
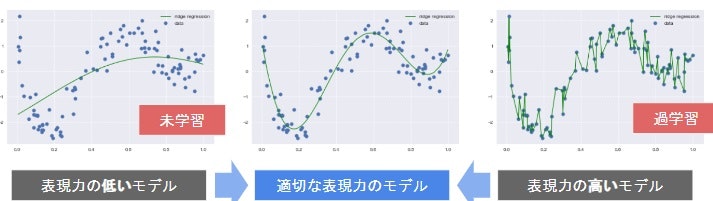
未学習(underfitting)と過学習(overfitting)
- 学習データに対して、十分小さな誤差が得られないモデル→未学習
-
(対策1)モデルの表現力が低いため、表現力の高いモデルを利用する
-
(対策2) 不要な基底関数(変数)を削除して表現力を抑止
-
(対策3)正則化法を利用して表現力を抑止
※ 下二つはモデルの複雑さを調整する方法
-
- 学習データに対して、十分小さな誤差が得られないモデル→未学習
-
不要な基底関数を削除
- 基底関数の数、位置やバンド幅によりモデルの複雑さが変化
- 解きたい問題に対して多くの基底関数を用意してしまうと過学習の問題がおこるため、適切な基底関数を用意(CVなどで選択)
-
正則化法(罰則化法)
-
「モデルの複雑さに伴って、その値が大きくなる正則化項(罰則項)を課した関数」を最小化
-
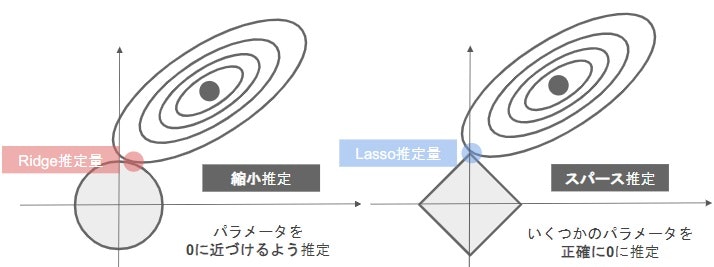
正則化項(罰則項)
- 形状によっていくつもの種類があり、それぞれ推定量の性質が異なる
-
正則化(平滑化)パラメータ
- モデルの曲線のなめらかさを調節▶適切に決める必要あり

-
正則化項(罰則項)の役割
- 無い▶最小2乗推定量
- L2ノルムを利用▶**Ridge推定量**
- L1ノルムを利用▶**Lasso推定量**
-
正則化パラータの役割
- 小さく▶制約面が大きく
- 大きく▶制約面が小さく
- 汎化性能
- 学習に使用した入力だけでなく、これまで見たことのない新たな入力に対する予測性能
- (学習誤差ではなく)汎化誤差(テスト誤差)が小さいものが良い性能を持ったモデル
- 汎化誤差は通常、学習データとは別に収集された検証データでの性能を測ることで推定
- バイアス・バリアンス分解
(参考)バイアス-バリアンス分解:機械学習の性能評価

- 手元のモデルがデータに未学習しているか過学習しているか
- 訓練誤差もテスト誤差もどちらも小さい▶汎化しているモデルの可能性
- 訓練誤差は小さいがテスト誤差が大きい▶過学習
- 訓練誤差もテスト誤差もどちらも小さくならない▶未学習
- 回帰の場合には陽に解が求まります(学習誤差と訓練誤差の値を比較)52非線形回帰モデル
- ホールドアウト法
-
有限のデータを学習用とテスト用の2つに分割し、「予測精度」や「誤り率」を推定する為に使用
- 学習用を多くすればテスト用が減り学習精度は良くなるが、性能評価の精度は悪くなる
- 逆にテスト用を多くすれば学習用が減少するので、学習そのものの精度が悪くなることになる。
- 手元にデータが大量にある場合を除いて、良い性能評価を与えないという欠点がある。例えば、二つに割ってしまった場合に片方にだけハズレのデータがいっいてまう危険性もある。
-
基底展開法に基づく非線形回帰モデルでは、基底関数の数、位置、バンド幅の値とチューニングパラメータをホールドアウト値を小さくするモデルで決定する53非線形回帰モデル
-
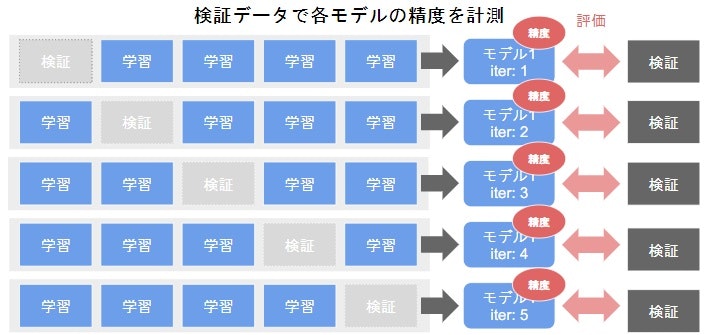
クロスバリデーション(交差検証)
イテレータごとに以下のような検証データと学習データを分けてモデルをそろえてあげる。下は、データを学習用と評価用に5分割の例。大切なのは、検証データと学習データで被らないこと。

ホールドアウト検証法で検証したところ70%の精度、CVでは、65%だったとしても、汎化性能の推定としてはCVを利用するようにする。クロスバリデーションの方がホールドアウト検証法よりも汎化性能が高い。
(演習)
Googleドライブのマウント
from google.colab import drive
drive.mount('/content/drive')
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# seaborn設定
sns.set()
# 背景変更
sns.set_style("darkgrid", {'grid.linestyle': '--'})
# 大きさ(スケール変更)
sns.set_context("paper")
n=100
def true_func(x):
z = 1-48*x+218*x**2-315*x**3+145*x**4
return z
def linear_func(x):
z = x
return z
# 真の関数からノイズを伴うデータを生成
# 真の関数からデータ生成
data = np.random.rand(n).astype(np.float32)
data = np.sort(data)
target = true_func(data)
# ノイズを加える
noise = 0.5 * np.random.randn(n)
target = target + noise
# ノイズ付きデータを描画
plt.scatter(data, target)
plt.title('NonLinear Regression')
plt.legend(loc=2)

from sklearn.linear_model import LinearRegression
clf = LinearRegression()
data = data.reshape(-1,1)
target = target.reshape(-1,1)
clf.fit(data, target)
p_lin = clf.predict(data)
plt.scatter(data, target, label='data')
plt.plot(data, p_lin, color='darkorange', marker='', linestyle='-', linewidth=1, markersize=6, label='linear regression')
plt.legend()
print(clf.score(data, target))

from sklearn.kernel_ridge import KernelRidge
clf = KernelRidge(alpha=0.0002, kernel='rbf')
clf.fit(data, target)
p_kridge = clf.predict(data)
plt.scatter(data, target, color='blue', label='data')
plt.plot(data, p_kridge, color='orange', linestyle='-', linewidth=3, markersize=6, label='kernel ridge')
plt.legend()
# plt.plot(data, p, color='orange', marker='o', linestyle='-', linewidth=1, markersize=6)

# Ridge
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Ridge
kx = rbf_kernel(X=data, Y=data, gamma=50)
# KX = rbf_kernel(X, x)
# clf = LinearRegression()
clf = Ridge(alpha=30)
clf.fit(kx, target)
p_ridge = clf.predict(kx)
plt.scatter(data, target,label='data')
for i in range(len(kx)):
plt.plot(data, kx[i], color='black', linestyle='-', linewidth=1, markersize=3, label='rbf', alpha=0.2)
# plt.plot(data, p, color='green', marker='o', linestyle='-', linewidth=0.1, markersize=3)
plt.plot(data, p_ridge, color='green', linestyle='-', linewidth=1, markersize=3,label='ridge regression')
# plt.legend()
print(clf.score(kx, target))

from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# PolynomialFeatures(degree=1)
deg = [1,2,3,4,5,6,7,8,9,10]
for d in deg:
regr = Pipeline([
('poly', PolynomialFeatures(degree=d)),
('linear', LinearRegression())
])
regr.fit(data, target)
# make predictions
p_poly = regr.predict(data)
# plot regression result
plt.scatter(data, target, label='data')
plt.plot(data, p_poly, label='polynomial of degree %d' % (d))
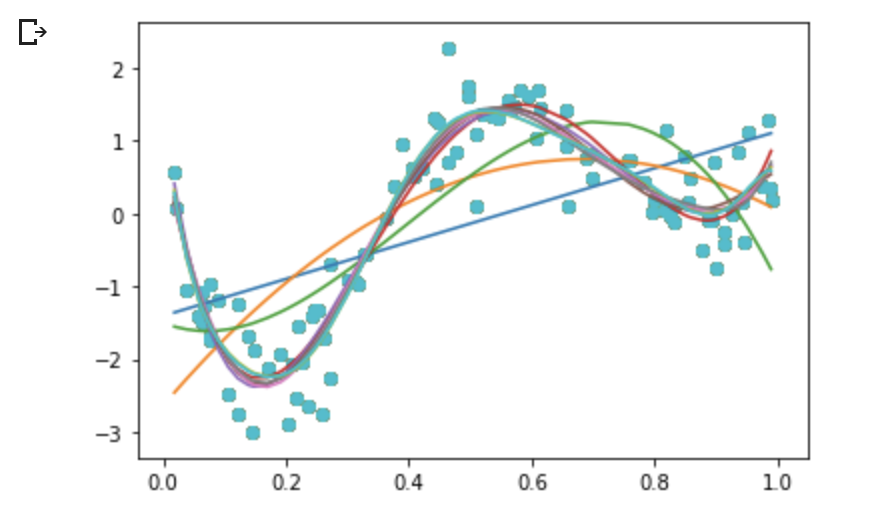
# Lasso
from sklearn.metrics.pairwise import rbf_kernel
from sklearn.linear_model import Lasso
kx = rbf_kernel(X=data, Y=data, gamma=5)
# KX = rbf_kernel(X, x)
# lasso_clf = LinearRegression()
lasso_clf = Lasso(alpha=10000, max_iter=1000)
lasso_clf.fit(kx, target)
p_lasso = lasso_clf.predict(kx)
plt.scatter(data, target)
# plt.plot(data, p, color='green', marker='o', linestyle='-', linewidth=0.1, markersize=3)
plt.plot(data, p_lasso, color='green', linestyle='-', linewidth=3, markersize=3)
print(lasso_clf.score(kx, target))

from sklearn import model_selection, preprocessing, linear_model, svm
# SVR-rbf
clf_svr = svm.SVR(kernel='rbf', C=1e3, gamma=0.1, epsilon=0.1)
clf_svr.fit(data, target)
y_rbf = clf_svr.fit(data, target).predict(data)
# plot
plt.scatter(data, target, color='darkorange', label='data')
plt.plot(data, y_rbf, color='red', label='Support Vector Regression (RBF)')
plt.legend()
plt.show()
/usr/local/lib/python3.6/dist-packages/sklearn/utils/validation.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
/usr/local/lib/python3.6/dist-packages/sklearn/utils/validation.py:724: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)

from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.1, random_state=0)
from keras.callbacks import EarlyStopping, TensorBoard, ModelCheckpoint
cb_cp = ModelCheckpoint('/content/drive/My Drive/study_ai_ml/skl_ml/out/checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', verbose=1, save_weights_only=True)
cb_tf = TensorBoard(log_dir='/content/drive/My Drive/study_ai_ml/skl_ml/out/tensorBoard', histogram_freq=0)
def relu_reg_model():
model = Sequential()
model.add(Dense(10, input_dim=1, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='relu'))
model.add(Dense(1000, activation='linear'))
# model.add(Dense(100, activation='relu'))
# model.add(Dense(100, activation='relu'))
# model.add(Dense(100, activation='relu'))
# model.add(Dense(100, activation='relu'))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
from keras.models import Sequential
from keras.layers import Input, Dense, Dropout, BatchNormalization
from keras.wrappers.scikit_learn import KerasRegressor
# use data split and fit to run the model
estimator = KerasRegressor(build_fn=relu_reg_model, epochs=100, batch_size=5, verbose=1)
history = estimator.fit(x_train, y_train, callbacks=[cb_cp, cb_tf], validation_data=(x_test, y_test))
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:66: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:541: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:4432: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/optimizers.py:793: The name tf.train.Optimizer is deprecated. Please use tf.compat.v1.train.Optimizer instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:1033: The name tf.assign_add is deprecated. Please use tf.compat.v1.assign_add instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:1020: The name tf.assign is deprecated. Please use tf.compat.v1.assign instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:3005: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.
Train on 90 samples, validate on 10 samples
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:190: The name tf.get_default_session is deprecated. Please use tf.compat.v1.get_default_session instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:197: The name tf.ConfigProto is deprecated. Please use tf.compat.v1.ConfigProto instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:207: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:216: The name tf.is_variable_initialized is deprecated. Please use tf.compat.v1.is_variable_initialized instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/backend/tensorflow_backend.py:223: The name tf.variables_initializer is deprecated. Please use tf.compat.v1.variables_initializer instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/callbacks.py:1122: The name tf.summary.merge_all is deprecated. Please use tf.compat.v1.summary.merge_all instead.
WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/keras/callbacks.py:1125: The name tf.summary.FileWriter is deprecated. Please use tf.compat.v1.summary.FileWriter instead.
Epoch 1/100
90/90 [==============================] - 2s 17ms/step - loss: 1.7399 - val_loss: 0.4522
Epoch 00001: saving model to /content/drive/My Drive/study_ai_ml/skl_ml/out/checkpoints/weights.01-0.45.hdf5
---------------------------------------------------------------------------
OSError Traceback (most recent call last)
<ipython-input-19-26d4341f0e70> in <module>()
6 estimator = KerasRegressor(build_fn=relu_reg_model, epochs=100, batch_size=5, verbose=1)
7
----> 8 history = estimator.fit(x_train, y_train, callbacks=[cb_cp, cb_tf], validation_data=(x_test, y_test))
8 frames
/usr/local/lib/python3.6/dist-packages/h5py/_hl/files.py in make_fid(name, mode, userblock_size, fapl, fcpl, swmr)
146 fid = h5f.create(name, h5f.ACC_EXCL, fapl=fapl, fcpl=fcpl)
147 elif mode == 'w':
--> 148 fid = h5f.create(name, h5f.ACC_TRUNC, fapl=fapl, fcpl=fcpl)
149 elif mode == 'a':
150 # Open in append mode (read/write).
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/_objects.pyx in h5py._objects.with_phil.wrapper()
h5py/h5f.pyx in h5py.h5f.create()
OSError: Unable to create file (unable to open file: name = '/content/drive/My Drive/study_ai_ml/skl_ml/out/checkpoints/weights.01-0.45.hdf5', errno = 2, error message = 'No such file or directory', flags = 13, o_flags = 242)
y_pred = estimator.predict(x_train)
90/90 [==============================] - 0s 1ms/step
plt.title('NonLiner Regressions via DL by ReLU')
plt.plot(data, target, 'o')
plt.plot(data, true_func(data), '.')
plt.plot(x_train, y_pred, "o", label='predicted: deep learning')
# plt.legend(loc=2)

print(lasso_clf.coef_)
[-0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0.
-0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0. -0.
-0. -0. -0. -0. -0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
関連サイト
第一章:線形回帰モデル
[第二章:非線形回帰モデル]
(https://qiita.com/matsukura04583/items/baa3f2269537036abc57)
[第三章:ロジスティク回帰モデル]
(https://qiita.com/matsukura04583/items/0fb73183e4a7a6f06aa5)
[第四章:主成分分析]
(https://qiita.com/matsukura04583/items/b3b5d2d22189afc9c81c)
[第五章:アルゴリズム1(k近傍法(kNN))]
(https://qiita.com/matsukura04583/items/543719b44159322221ed)
[第六章:アルゴリズム2(k-means)]
(https://qiita.com/matsukura04583/items/050c98c7bb1c9e91be71)
[第七章:サポートベクターマシン]
(https://qiita.com/matsukura04583/items/6b718642bcbf97ae2ca8)