ラビットチャレンジのレポートに関するリンクはこちら
ラビットチャレンジ 応用数学
ラビットチャレンジ 機械学習
ラビットチャレンジ 深層学習 Day1
ラビットチャレンジ 深層学習 Day2
ラビットチャレンジ 深層学習 Day3
ラビットチャレンジ 深層学習 Day4前半
ラビットチャレンジ 深層学習 Day4後半
0.前回の復習
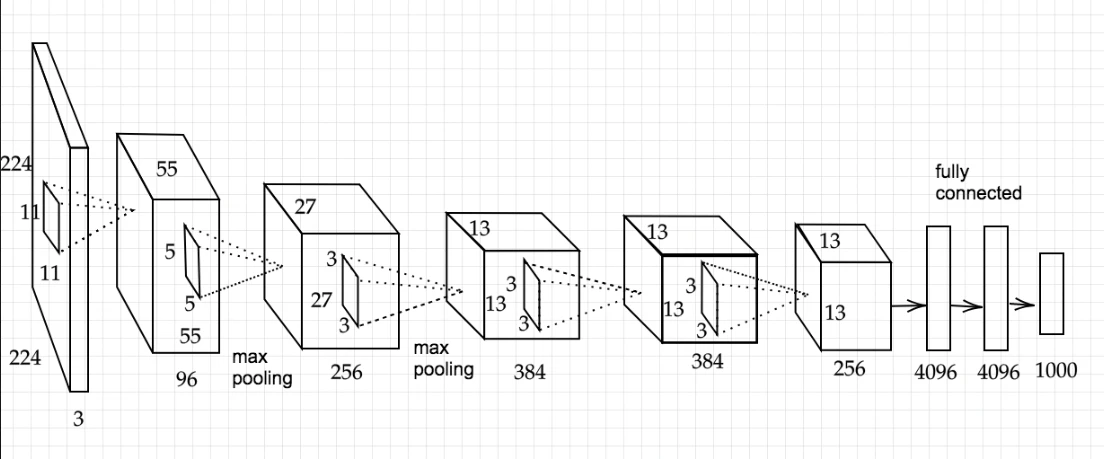
AlexNetについて
2012年に開かれた画像認識コンペティション2位に大差をつけて優勝したモデルである。
AlexNetの登場で、ディープラーニングが大きく注目を集めた。
モデルの構造
5層の畳み込み層およびプーリング層など、それに続く3層の全結合層から構成される。
過学習を防ぐ施策
サイズ4096の全結合層の出力にドロップアウトを使用している
<確認テスト>
サイズ5×5の入力画像を、サイズ3×3のフィルタで畳み込んだ時の出力画像のサイズを答えよ。
なおストライドは2、パディングは1とする。
<解答>
3×3
縦:
$$
\frac{5 + 21 -3}{2} + 1 = 3
$$
高さ:
$$
\frac{5 + 21 -3}{2} + 1 = 3
$$
1.再帰型ニューラルネットワーク(RNN)
RNNとは
よく用いられているニューラルネットワークはフィードフォワードと呼ばれるタイプのものである。単純で理解しやすいといったメリットがある反面、時系列データに対応できなかった。そこで、時系列データに対応可能な、ニューラルネットワークであるRNNが誕生した。時系列データである音声データやテキストデータの学習で扱われる。
RNNの課題
時系列を遡るほど、勾配が消失していくため、長い時系列の学習が困難である。
そこで構造自体を変えて解決したものがLSTMである(LSTMについては後述する)。
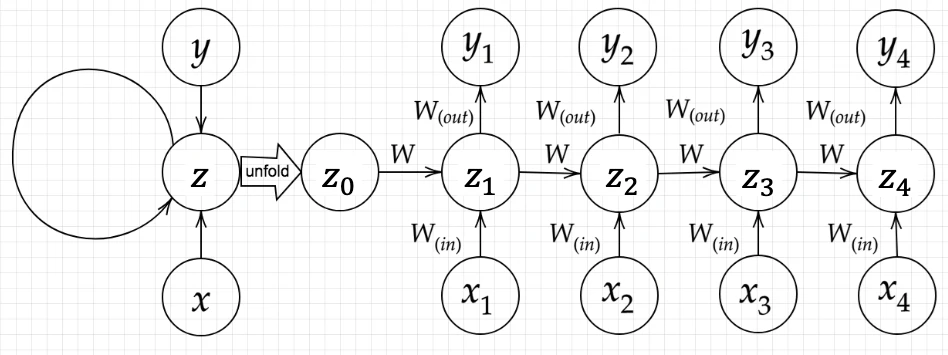
$$u^t = W_{in}x^t + Wz^{t-1} + b$$
$$z^t = f(W_{in}x^t + Wz^{t-1} + b)$$
$$υ^t = W_{out}z^t + c$$
$$y^t = g(W_{out}z^t + c)$$
# 上記の数式をコードに示すと以下の通りとなる
u[:, t+1] = X@W_in + z[:, t].reshape(1, -1)@W + b
z[:, t+1] = functions.sigmoid(u[:, t+1]) + b
z[:, t+1].reshape(1,- 1)@W_out
y[:, t+1] = functions.sigmoid(z[:, t+1].reshape(1, -1)@W_out)
<確認テスト>
RNNのネットワークには大きく分けて3つの重みがある。1つは入力から現在の中間層を定義する際にかけられる重み、1つは中間層から出力を定義する際にかけられる重みである。残り1つの重みについて説明せよ。
<解答>
前の中間層から現在の中間層(または現在の中間層から次の中間層)を定義する際に掛けられる重み。
BPTTとは
RNNにおけるパラメータの調整方法の1つである。
→誤差逆伝播の1種である。
BPTTの数学的記述
【重み】
$$
\frac{∂E}{∂W_{in}} = \frac{∂E}{∂u^t}\left[\frac{∂u^t}{∂W_{in}}\right]^T = δ^t\left[x^t\right]^T
$$
$$
\frac{∂E}{∂W_{out}} = \frac{∂E}{∂υ^t}\left[\frac{∂υ^t}{∂W_{out}}\right]^T = δ^{out,t}\left[z^t\right]^T
$$
$$
\frac{∂E}{∂W} = \frac{∂E}{∂u^t}\left[\frac{∂u^t}{∂W}\right]^T = δ^{t}\left[z^{t-1}\right]^T
$$
【バイアス】
$$
\frac{∂E}{∂b} = \frac{∂E}{∂u^t}\frac{∂u^t}{∂b} = δ^t
$$
$$
\frac{∂E}{∂c} = \frac{∂E}{∂υ^t}\frac{∂υ^t}{∂c} = δ^{out,t}
$$
パラメータの更新式
【重み】
$$
W_{in}^{t+1}=W_{in}^t−ϵ\frac{∂E}{∂W_{in}}=W_{in}^t−ϵ\sum_{z=0}^{T_t}δ^{t−z}[x^{t−z}]^T
$$
$$
W_{out}^{t+1}=W_{out}^t−ϵ\frac{∂E}{∂W_{out}}=W_{out}^t−ϵ\sum_{z=0}^{T_t}δ^{out,t}[x^{t}]^T
$$
$$
W^{t+1}=W^t−ϵ\frac{∂E}{∂W}=W^t−ϵ\sum_{z=0}^{T_t}δ^{t−z}[x^{t−z-1}]^T
$$
【バイアス】
$$
b^{t+1}=b^t−ϵ\frac{∂E}{∂b} = b^t−ϵ\sum_{z=0}^{T_t}δ^{t−z}
$$
$$
c^{t+1}=c^t−ϵ\frac{∂E}{∂c}=c^t−ϵδ^{out,t}
$$
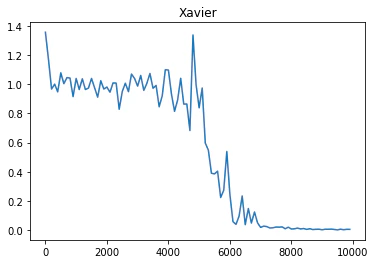
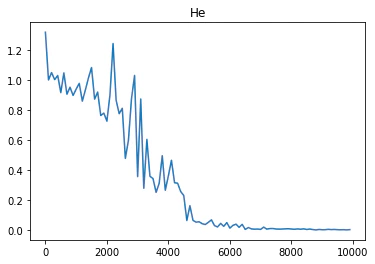
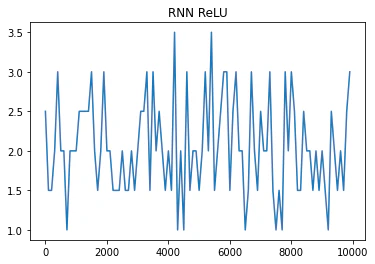
バイナリ加算を用いてRNNを実装した結果を以下に示す。
※x軸:イテレーション回数、y軸が誤差を表している
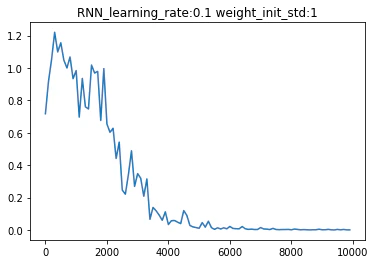
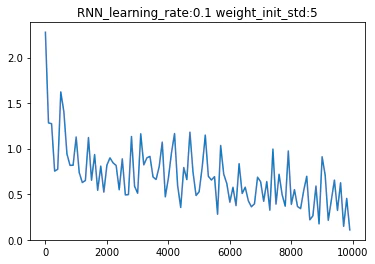
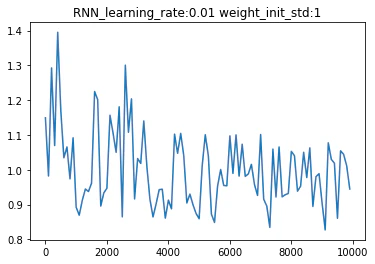
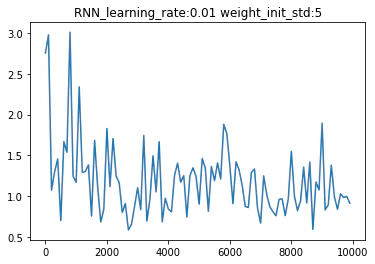
重みの初期値をXavier法とHe法で行った結果
活性化関数をシグモイド関数からReLU関数へ変更した場合
※learningu_rate:0.1 weight_int_std:1
<確認テスト1>
連鎖律の原理を使い、dz_dxを求めよ
$$z=t^2$$
$$t=x+y$$
<解答>
$$\begin{align}
\frac{dz}{dx}&=\frac{dz}{dt}\frac{dt}{dx}\
&=2t = 2(x+y)
\end{align}
$$
<確認テスト2>
下図のy_1を
$$x・z_0・z_1・w_{in}・w・w_{out}$$を用いて数式で表せ。
※バイアスは任意の文字で定義せよ。
また、中間層の出力にシグモイド関数g(x)を作用させよ。
<解答>
$$
z_1=sigmoid(z_0W + x_1W_{in} + b)
$$
$$
y_1=sigmoid(z_1W_{out} + c)
$$
2.LSTMについて
LSTM(Long short-term memory)は、RNN(Recurrent Neural Network)の拡張として1995年に登場した、時系列データ(sequential data)に対するモデル、あるいは構造の1種である。その名は、Long term memory(長期記憶)とShort term memory(短期記憶)という神経科学における用語から取られている。LSTMはRNNの中間層のユニットをLSTMblockと呼ばれるメモリと3つのゲートを持つブロックに置き換えることで実現されている。
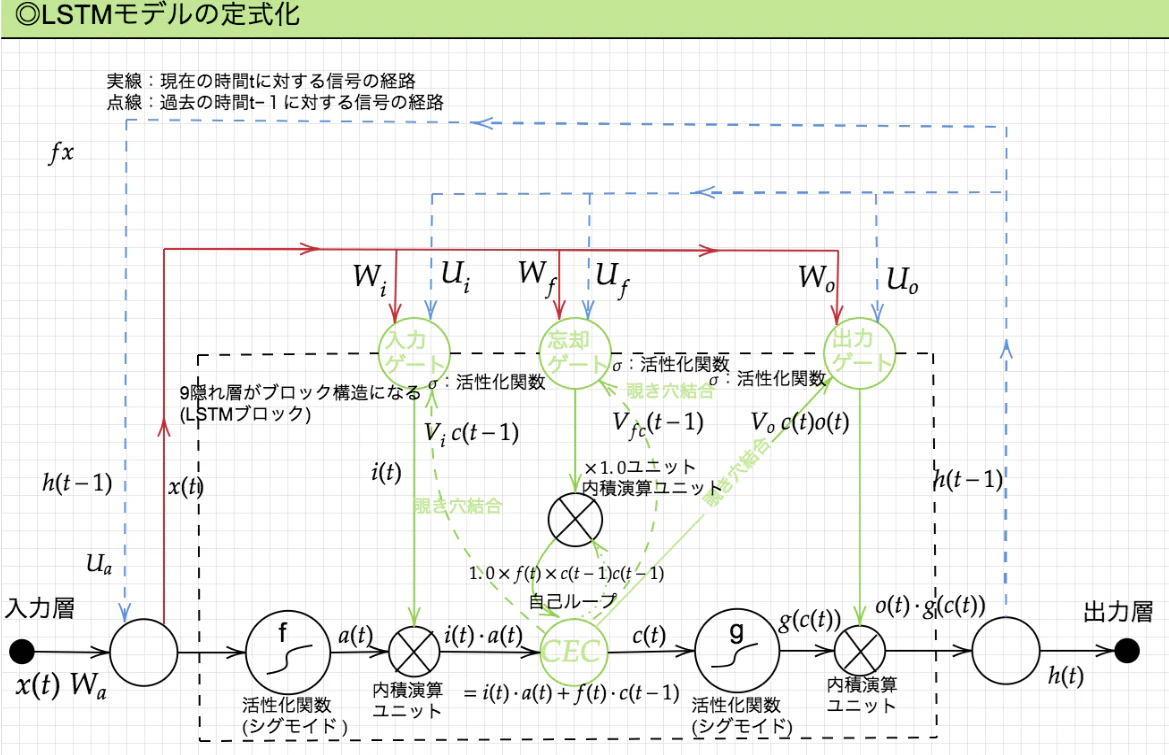
CEC:過去のデータを保存するためのユニット
入力ゲート:「前のユニットの入力をどの程度受け取るか」を調整するためのゲート
出力ゲート:「前のユニットの出力をどの程度受け取るか」を調整するためのゲート
忘却ゲート:「過去の情報が入っているCECの中身をどの程度残すか」を調整するためのゲート
3つのゲートが追加された背景を説明する。
CECの課題として以下の2点が挙げられていた。
・入力データについて、時間依存度に関係なく重みが一律であること。
・ニューラルネットワークの学習特性が無いということ。
入力層 -> 隠れ層への重み入力重み衝突
隠れ層 -> 出力層への重み出力重み衝突
上記の課題を解決するために入力・出力ゲートを追加した
また、CECは、過去の情報が全て保管されており、過去の情報が要らなくなった場合、そのタイミングで情報を忘却する機能が必要だった。その問題を解決するために忘却ゲートが追加された。
確認テスト
以下の文章にLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられるか。このような場合、どのゲートが作用すると考えられるか。
「映画面白かったね。ところで、とてもお腹が空いたから何か____。」
解答:
忘却ゲート
とてもは無くても学習に影響を与えないため
3.GRU
LSTMではパラメータ数が多く、計算負荷がかかるといった問題があった。そこでGRUと呼ばれる構造が誕生。GRUでは、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望める様になった。
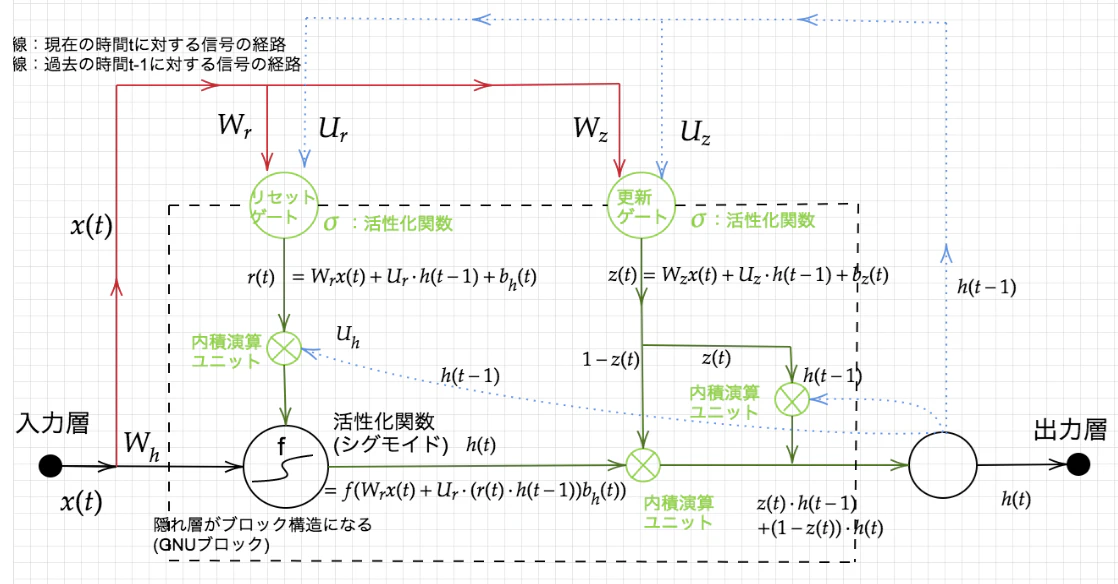
<確認テスト1>
LSTMとCECが抱える課題についt、それぞれ簡潔に述べよ
<解答>
LSTM:パラメータ数が多く、計算負荷がかかる
CEC:学習機能を備えていない(入力・出力ゲートが必要になる根本の原因)
<確認テスト2>
LSTMとGRUの違いについて説明せよ
<解答>
LSTMはCEC、入力ゲート、出力ゲート、忘却ゲートを持ち、パラメータが多く計算コストが大きい。一方で、GRUはリセットゲートの更新ゲートを持ち、パラメータが少ないため計算コストが小さい。
4.双方向RNN
過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデル。
文章の推敲や機械翻訳等で実用されている。
5.seq2seq
Seq2seqとは、Encoder-Decoderモデルの一種を指す。
具体的な用途として機械対話や、機械翻訳などが挙げられる。

Taking:文章を単語等のトークン毎に分割し、トークンごとのIDに分割する。
Embedding:IDから、そのトークンを表す分散表現ベクトルに変換。
Encoder RNN:ベクトルを順番にRNNに入力していく。
Encoder RNN の処理手順
- vec1をRNNに入力し、hidden stateを出力。このhidden stateと次の入力vec2をまたRNNに入力してきたhidden stateを出力という流れを繰り返す。
- 最後のvecを入れたときのhidden stateをfinal stateとしてとっておく。
このfinal stateがthought vectorと呼ばれ、入力した文の意味を表すベクトルとなる。
Decoder RNN の処理手順
- Decoder RNN:Encoder RNNのfinal state(thought vector)から、各tokenの生成確率を出力していく。final stateをDecoder RNNのinitial state として設定し、Embeddingを入力。
- Sampling:生成確率にもとづいてtokenをランダムに選ぶ。
- Embedding:2)で選ばれたtokenをEmbeddingしてDecoder RNNへの次の入力とする。
- Detokenize:1) ~3)を繰り返し、2)で得られたtokenを文字列に直す。
HREDとは
過去n-1個の発話から次の発話を生成する。
Seq2seqでは一問一答しかできず、会話の文脈無視で応答がなされたが、HREDでは、前の単語の流れに即して応答されるため、
より人間らしい文章が生成される。
Seq2Seq + Context RNN
Context RNN:Encoderのまとめた各文章の系列をまとめて、これまでの会話コンテキスト全体を表すベクトルに変換する構造。
システム:インコかわいいよね。
ユーザー:うん
システム:インコかわいいのわかる。
HREDの課題
HREDは確率的な多様性が字面にしかなく、会話の「流れ」のような多様性が無い。同じコンテキスト(発話リスト)を与えられても、答えの内容が毎回会話の流れとしては同じものしか出せない。HREDは短く情報量に乏しい答えをしがちである。短いよくある答えを学ぶ傾向がある。
ex)「うん」「そうだね」「・・・」など。
VHRED
VHREDとは、HREDの課題を、VAEの潜在変数の概念を追加することで解決した構造。
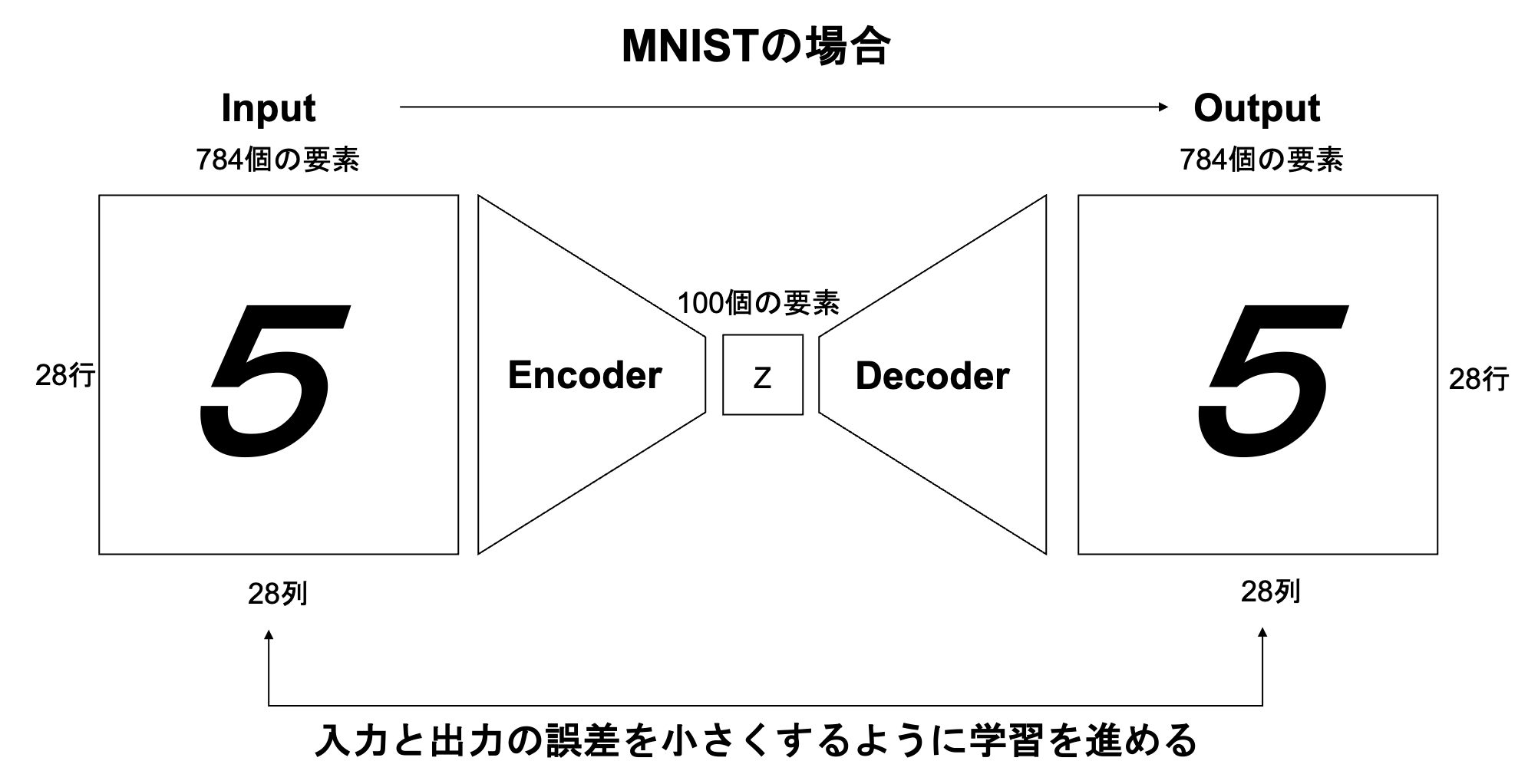
オートエンコーダ
オートエンコーダとは、教師なし学習の一つ。そのため学習時の入力データは訓練データのみで教師データは利用しない。
説明入力データから潜在変数zに変換するニューラルネットワークがEncoderで、
潜在変数zをインプットとして元画像を復元するニューラルネットワークがDecoderである。
メリットとして、次元削減が行えることが挙げられる。
※zの次元が入力データより小さい場合、次元削減とみなすことができる。
例えば、MNISTの場合、28x28の数字の画像を入れて、同じ画像を出力するニューラルネットワークということになる。
VAE
通常のオートエンコーダーの場合、何かしら潜在変数zにデータを押し込めているものの、その構造がどのような状態かわからない。VAEはこの潜在変数zに確率分布z∼N(0,1)を仮定したもの。
VAEは、データを潜在変数zの確率分布という構造に押し込めることを可能にする。
<確認テスト1>
下記の選択肢から、seq2seqについて説明しているものを選べ。
(1)時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
(2)RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
(3)構文木などの木構造に対して、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、文全体の表現ベクトルを得るニューラルネットワークである。
(4)RNNの一種であり、単純なRNNにおいて問題となる勾配消失問題をCECとゲートの概念を導入することで解決したものである。
<解答>
(2)
(1)は双方向RNNについての説明
(3)は構文木についての説明
(4)はLSTMについての説明
<確認テスト2>
seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ。
<解答>
seq2seqは会話の文脈を無視した処理を行うといった課題があったが、HREDは文脈の流れを考慮した処理を行う
HREDは短く情報量の乏しいな返事しかできない課題があったが、VHREDはHREDの課題をVAEの潜在変数の概念を追加して解決したもの。
<確認テスト3>
VAEに関する下記の説明文中の空欄に当てはまる言葉を答えよ。
「自己符号化器の潜在変数に____を導入したもの。」
<解答>
確率分布
word2vec
RNNでは、単語のような可変長の文字列をNNに与えることはできないといった課題があった。
そこで誕生したword2vecは単語の分散表現の獲得を目指した手法である。
メリット
大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能にした。
×:ボキャブラリ×ボキャブラリだけの重み行列が誕生。
○:ボキャブラリ×任意の単語ベクトル次元で重み行列が誕生。
学習データからボキャブラリを作成
Ex) I want to eat apples. I like apples.
→ {apples,eat,I,like,to,want}
※わかりやすく7語のボキャブラリを作成したが、
本来は、辞書の単語数だけできあがる。
Attention Mechanism
seq2seqの問題は長い文章への対応が難しいことだった。seq2seqでは、2単語でも、100単語でも、固定次元ベクトルの中に入力しなければならない。
そのため、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく、仕組みが必要になる。
そこで誕生したのがAttention Mechanismである。
→「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組み。