ラビットチャレンジのレポートに関するリンクはこちら
ラビットチャレンジ 応用数学
ラビットチャレンジ 機械学習
ラビットチャレンジ 深層学習 Day1
ラビットチャレンジ 深層学習 Day2
ラビットチャレンジ 深層学習 Day3
ラビットチャレンジ 深層学習 Day4前半
ラビットチャレンジ 深層学習 Day4後半
1.物体検知
1.1.広義の物体認識タスク
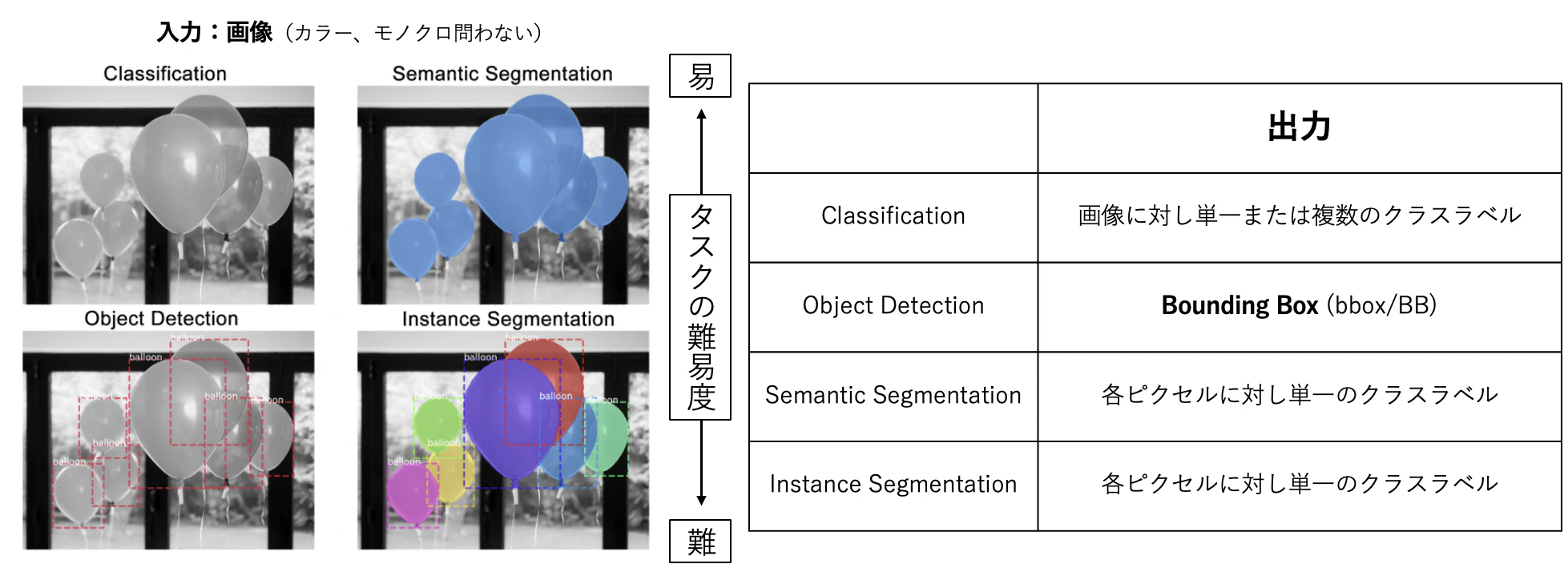
1.2.物体検知タスクにおけるデータセット
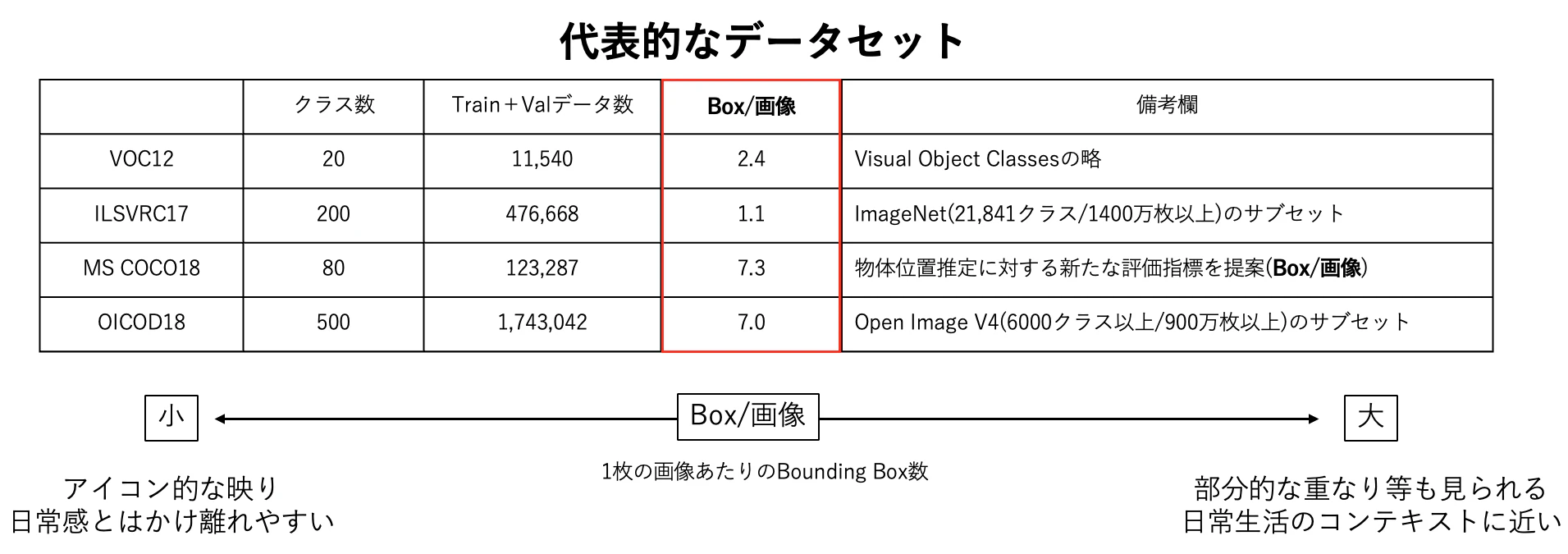
1.3.評価指標
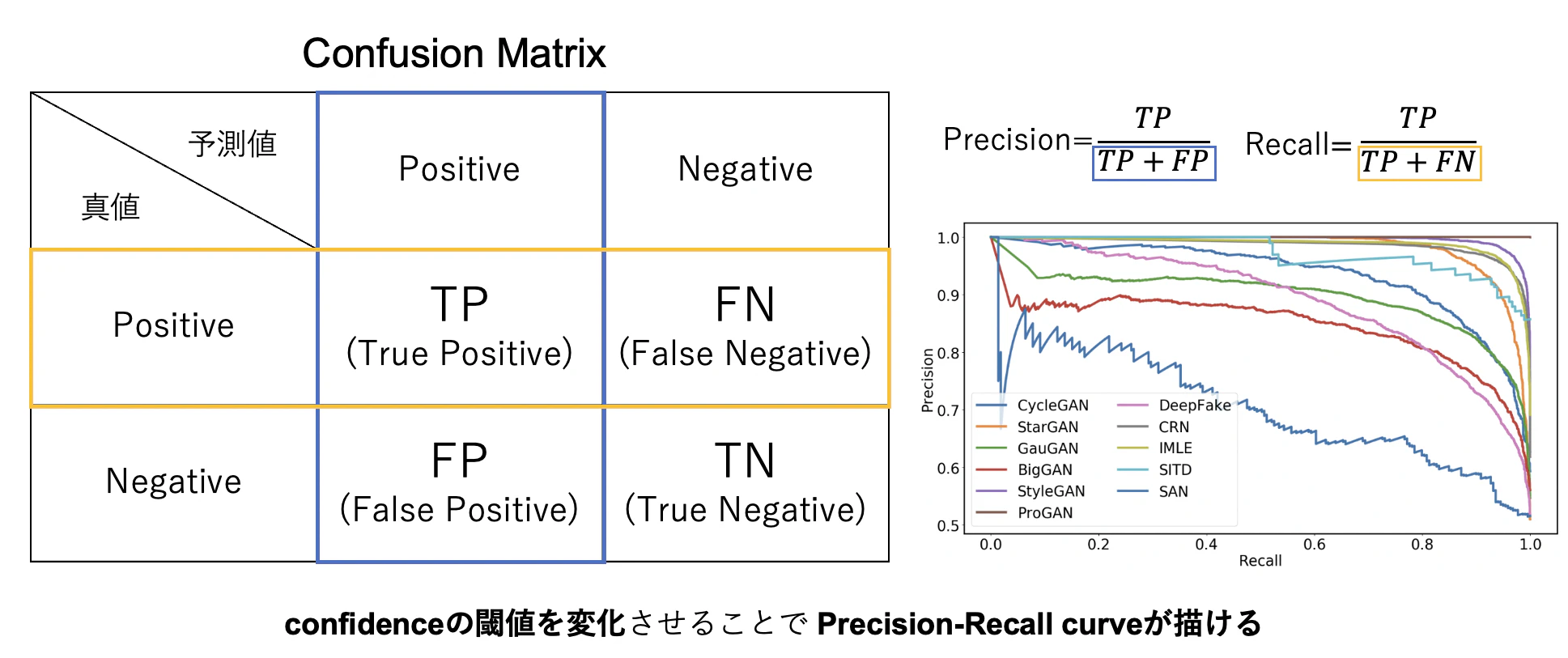
1.3.1.IoU(Intersection over Union)
IoUとは予測領域がどれだけ正解領域と重なっているのかを示す指標である。
IoUの最大値は1(正解領域と予測領域が一致している場合)。
IoUの最小値は0(正解領域と予測領域が全く重なっていない場合)。
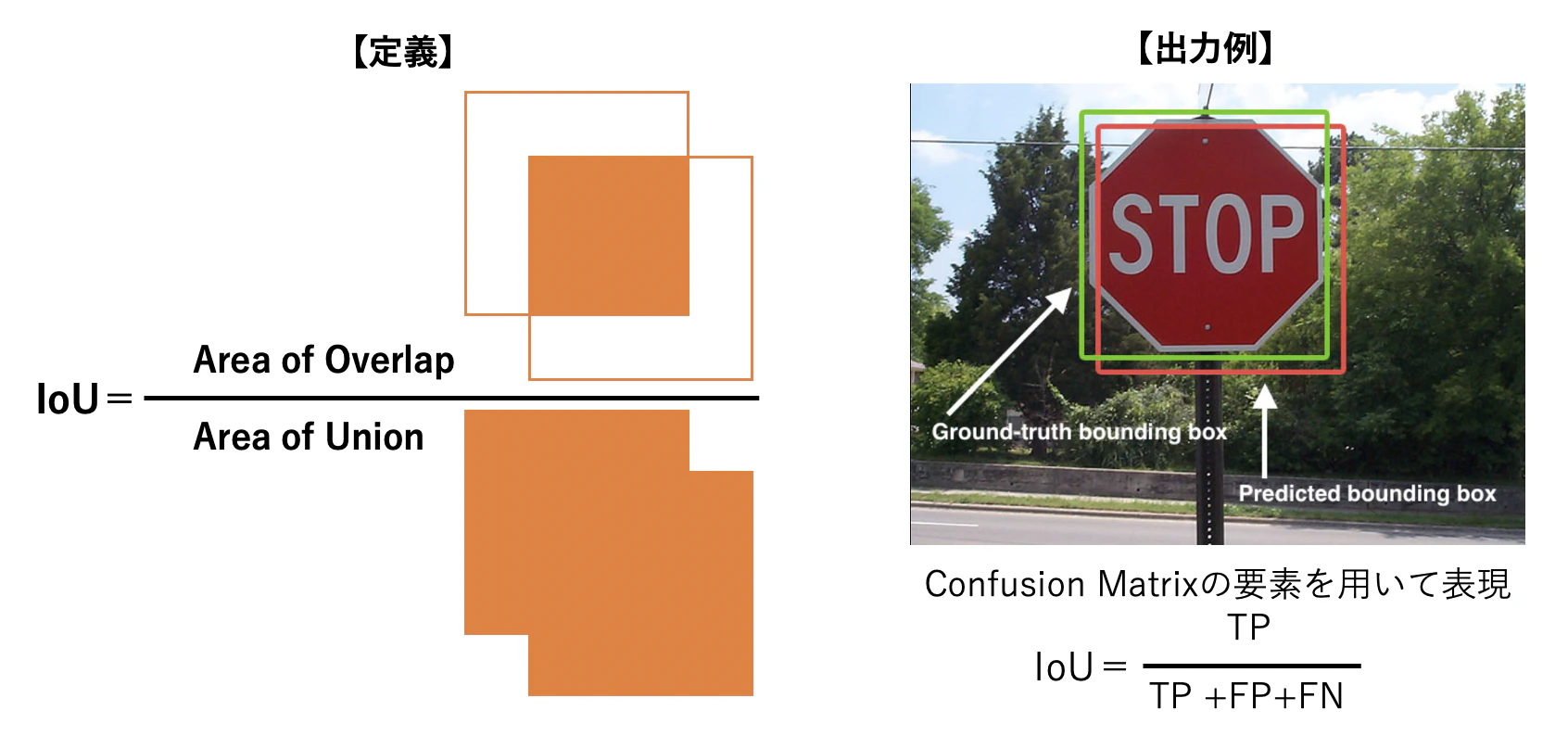
IoUは厳しい評価指標となっており、
同じ正方形を斜めに1/9ズラしただけでも、
IoUは81/118≒0.69になる(一辺の長さが10だった場合)。
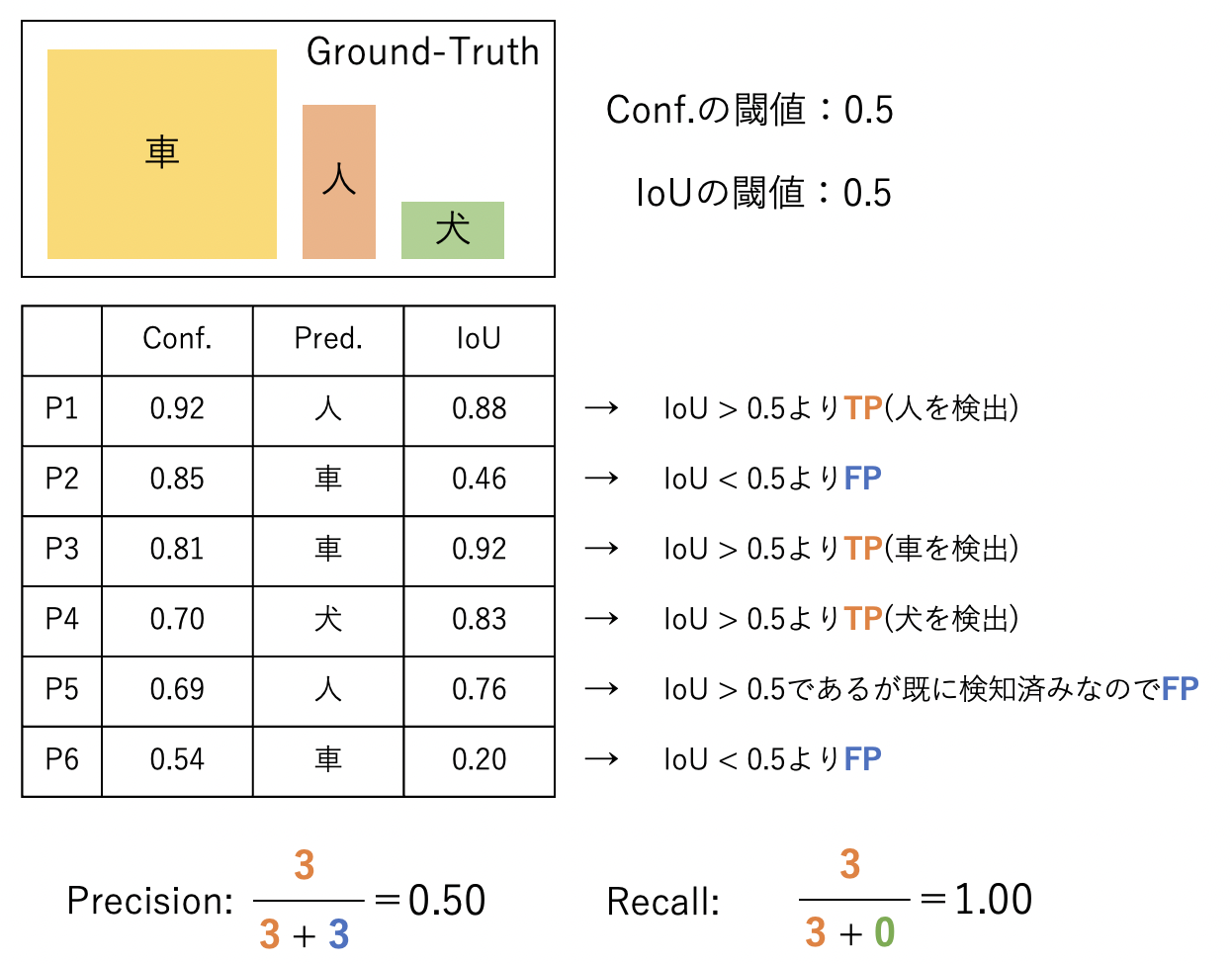
1.3.2.Precision/Recallの指標の見方
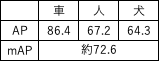
1.3.3.mAP(mean Average Precision)
クラス数がCの時
$$
mAP = \frac{1}{C}\sum_{i=1}^CAP_i
$$
【計算例】
余談になるが、MS COCOはIoU閾値は0.5から0.95まで0.05刻みで
AP&mAPを計算し算術平均を計算した指標を用いている。
$$
mAP_{COCO} = \frac{mAP_{0.5} + mAP_{0.55} + \cdots + mAP_{0.95}}{10}
$$
1.3.4.FPS(Flames per Second)
応用する上で検出精度に加え検出速度も問題となる
Frame Pre Secondとは1秒あたりに何フレーム処理できるかという処理速度を測る指標である。
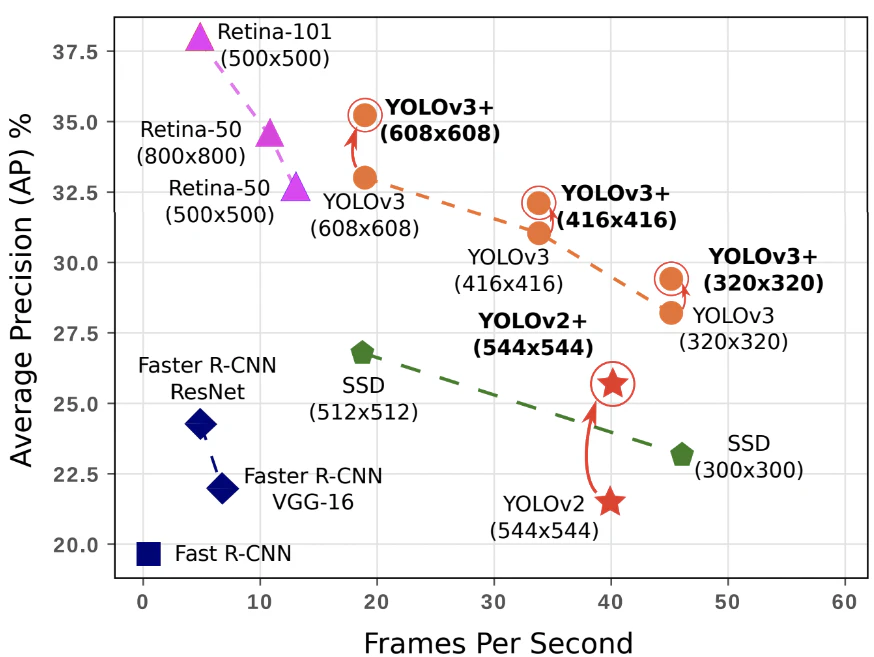
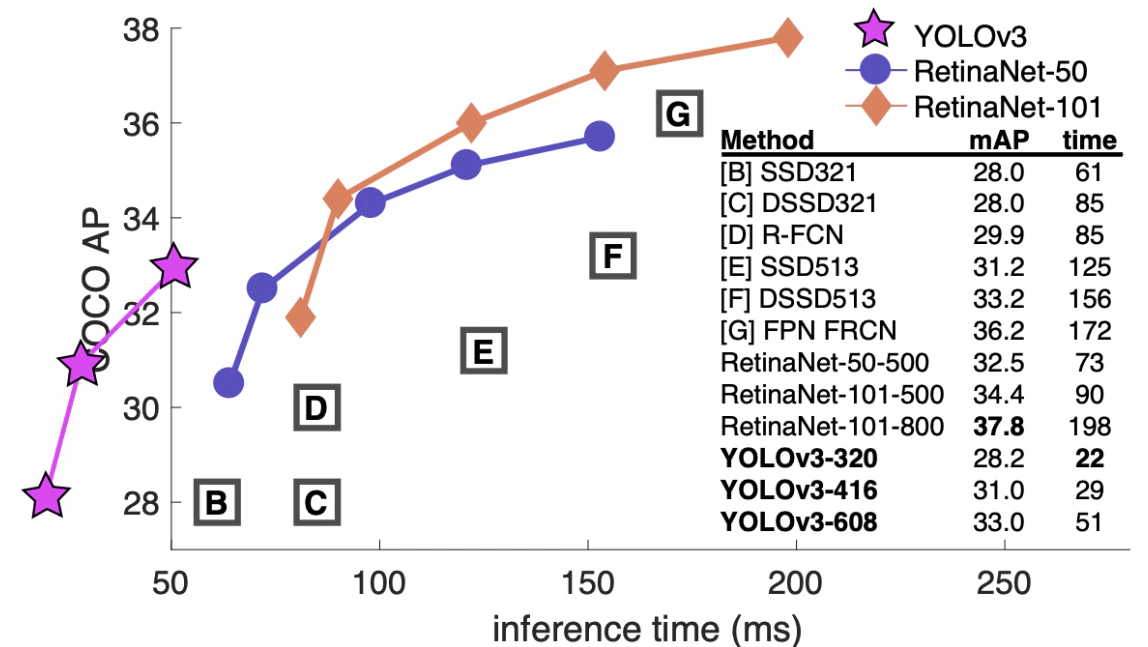
1.4.物体検知のフレームワーク
1.4.1.フレームワーク
物体検知のフレームワークは大きく分けて2種類ある。
【1段階検出器】 DetectorNet、YOLO、SSD、YOLO9000、RetinaNet、CornerNet
・候補領域の検出とクラス推定を同時に行う
・相対的に精度が低い
・相対的に計算量が小さく推論も早い傾向
【2段階検出器】 RCNN、SPPNet、Fast RCNN、Faster RCNN、RFCN、FPN、Mask RCNN
・候補領域の検出とクラス推定を別々に行う
・相対的に精度が高い傾向
・相対的に計算量が大きく推論も遅い傾向

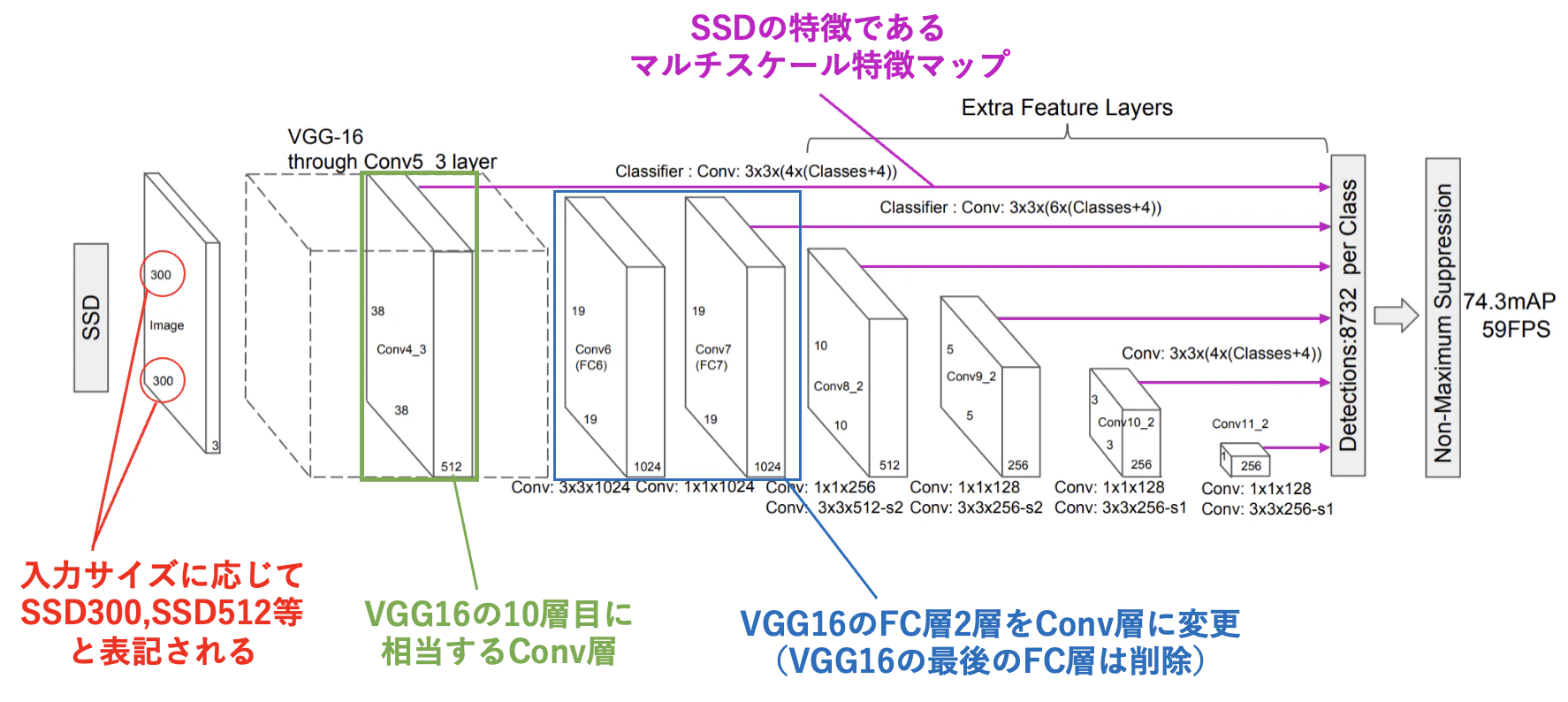
1.4.2.SSD(Single Shot Detector)

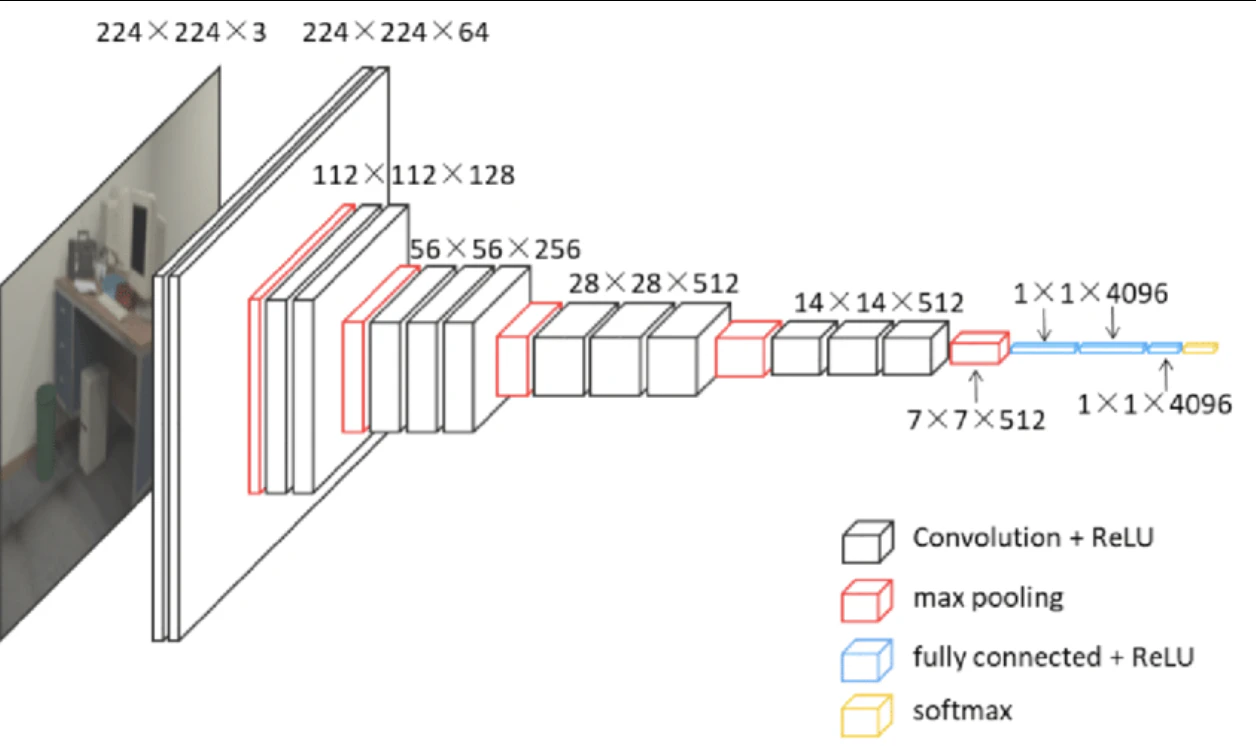
SSDを説明するためにVGGを比較対象として見ていく。
下図がVGG16のネットワーク図である
一方でSSDのネットワークアーキテクチャは下図の通りとなっている。
2.Transfomer
2.1.Transfomerとは
ニューラル機械翻訳は長文に対して精度が高くないことが問題点として挙げられていたが、
TransformerはAttention機構を用いることで長文に対しても高い精度を出すことができる。

また、TransformerはRNN構造を使用せずにAttention技術から作られたもので、Attention機構だけでAttention付きのRNNに匹敵するパフォーマンスが得られることを明らかにした。
2.2.Attention
Attention機構とは和訳で「注意機構」と呼ばれるもので、
翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用する手法のことである。
query(検索クエリ)に一致するkeyを索引し、対応するvalueを取り出す操作であると見做すことができるため、
辞書オブジェクトの機能と同じである。

queryとKeyの内積はqueryと各Keyの類似度を測り、
softmaxで正規化したAttention Weightは、queryに一致したKeyの位置を表現する。
Attention wightとValueの内積はKeyの位置に対応するValueを加重和として取り出す操作である。
翻訳元の各単語の隠れ状態を加重平均
$$
C_i = \sum_{j=1}^{T_x}α_{ij}h_j
$$
重み(全て足すと1)はFFNN (FeedForward Neural Network)で求める
$$
a_{ij}=\frac{exp(e_{ij})}{\sum_{k=1}^{T_x}exp(e_{ik})}
$$
$$
e_{ij} = a(s_{i-1}, h_j)
$$
【メリット】
・現在のSoTAの多くがAttentionベースで学習が速い
・RNNは時刻tの計算が終わるまで時刻t+1の計算をできず、GPUをフルに使えないことがある。
一方で、Transformerは推論時のDecoderを除いて、すべての時刻の計算を同時に行えるためGPUをフルに使いやすい。
・RNNを使わないため比較的構造が単純。全結合と行列積くらい知っていれば理解できてしまう。
2.3.Transfomer主要モジュール

2.4.Transfomer-Encoder



3.GAN(Generative Adversarial Nets)
3.1.GANとは
**生成器(Generator)と識別機(Discriminator)**を競わせて学習する生成&識別モデル
Generator:乱数からデータを生成
Discriminator:入力データが真のデータ(学習データ)であるか識別

3.2.GANの価値関数
GANでは価値関数Vに対し、Dが最大化、Gが最小化を行う

GANの価値関数はバイナリークロスエントロピーである。
$$
L=−\sum{y}\log{\hat{y}}+(1−y)\log{(1−\hat{y})}
$$

3.3.最適化方法
【Generatorのパラメータを固定】
真データと生成データをm個ずつサンプル
θdを勾配上昇法で更新
$$\frac{𝜕}{𝜕θ_d}\frac{1}{m}[log[D(x)]+log[1-D(G(z)]]$$
【Discriminatorのパラメータを固定】
真データと生成データをm個ずつサンプル
θgを勾配降下法で更新
$$\frac{𝜕}{𝜕θ_g}\frac{1}{m}[log[1-D(G(z)]]$$
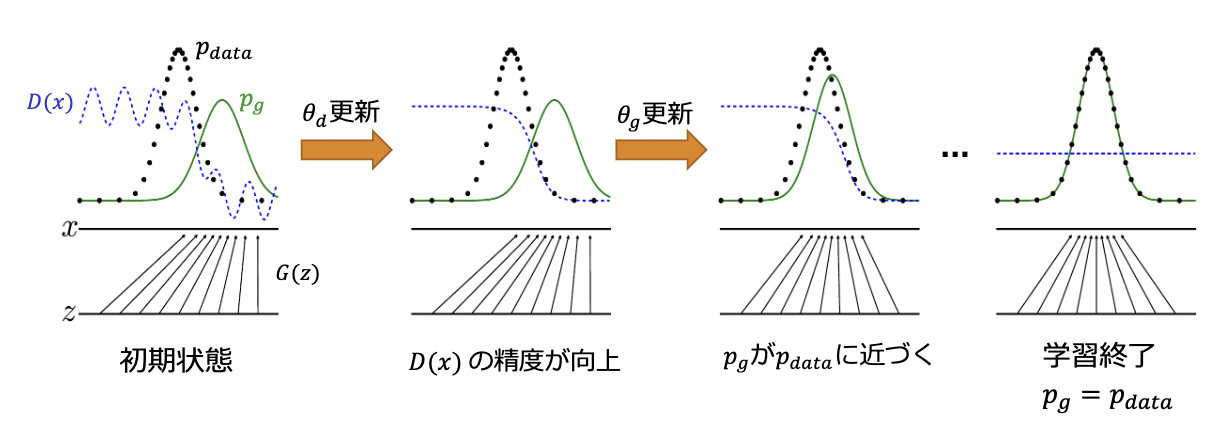
3.4.Generatorの生成アルゴリズム
生成データが真データとそっくりな状況とは
$$p_g=p_{data}$$
であるはず
価値関数が上記の時に最適化されていることを示せば良い。
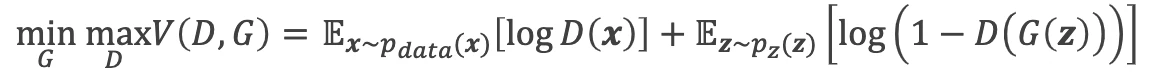
2つのステップにより確認していく。
- Gを固定し、価値関数が最大値を取るときのD(x)を算出
- 上記のD(x)を価値関数に代入し、Gが価値関数の最小化する条件を算出
1)

ここでalog(y)+blog(a-y)をyで微分



4.DCGAN(Deep Convolutional GAN)
DCGANとはGANを利用した画像生成モデルで、いくつかの構造制約により生成品質を向上。
【Generator】
・Pooling層の代わりに転置畳み込み層を使用
・最終層はtanh、その他はReLU関数で活性化
【Discriminator】
・Pooling層の代わりに畳み込み層を使用
・Leaky ReLU関数で活性化
【共通事項】
・中間層に全結合層を使わない
・バッチノーマライゼーションを適用