ラビットチャレンジに関するリンクはこちら
ラビットチャレンジ 応用数学
ラビットチャレンジ 機械学習
ラビットチャレンジ 深層学習 Day1
ラビットチャレンジ 深層学習 Day2
ラビットチャレンジ 深層学習 Day3
ラビットチャレンジ 深層学習 Day4前半
ラビットチャレンジ 深層学習 Day4後半
1.強化学習
1.1.強化学習とは
長期的に報酬を最大化できるように環境のなかで行動を選択できるエージェントを作ることを目標とする機械学習の一分野。
行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組み。
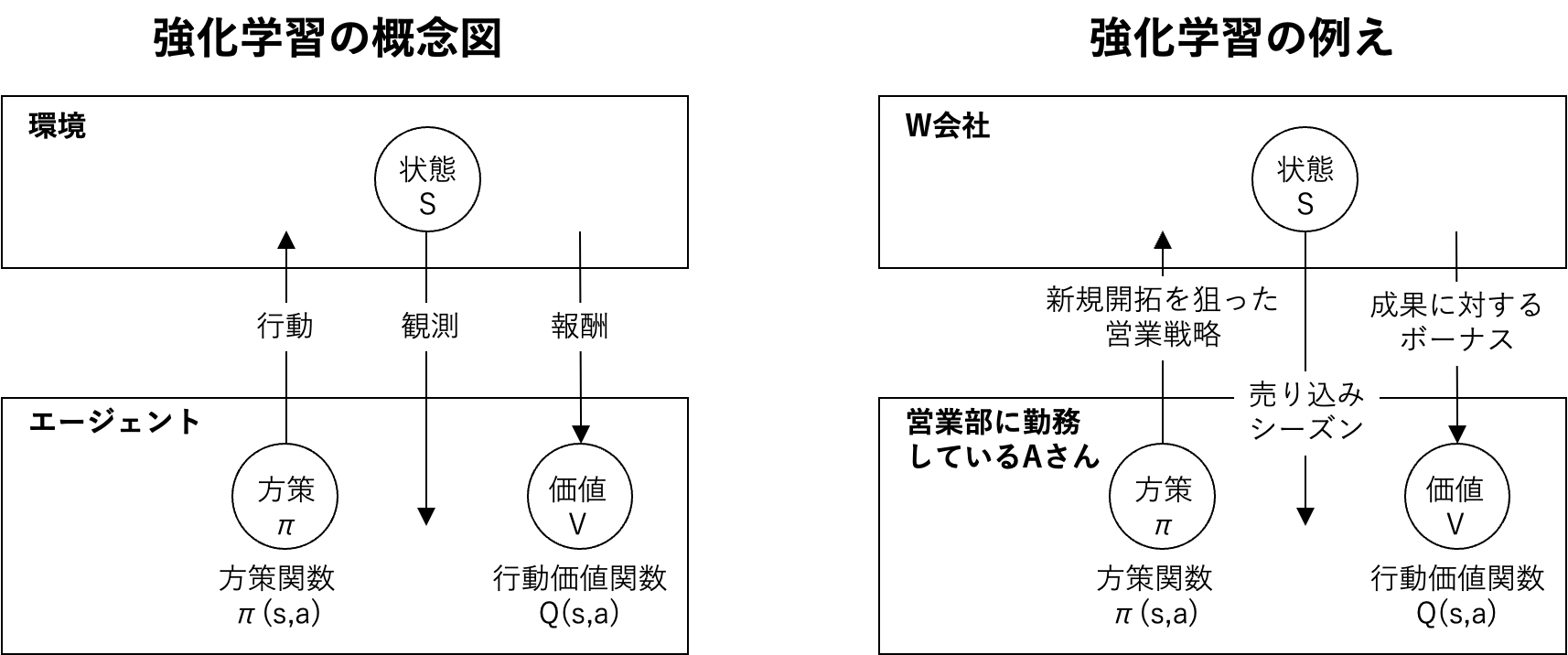
方策関数:方策ベースの強化学習手法において、ある状態でどのような行動を取るのかの確率を与える関数。
価値関数:状態価値関数と行動価値関数の2種類がある。
ある状態の価値に注目する場合は状態価値関数。
状態と価値を組み合わせた価値に注目する場合は行動価値関数。
1.2.方策勾配法
方策をモデル化して最適化する手法
$$
θ^{t+1} = θ^t + ε∇J(θ)
$$
関数Jは方策の良さを表し、定義しなければならない
【定義方法】
・平均報酬
・割引報酬和
上記の定義に対応して、行動価値関数Q(s,a)の定義を行い、方策勾配定理が成り立つ。
$$
∇𝐽(𝜃) = E_{𝜋𝜃}[∇log_{𝜋𝜃}(𝑎|𝑠)𝑄^{𝜋𝜃}(𝑠,𝑎)]
$$
1.3.強化学習のトレードオフ関係
環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能。
どのような顧客にキャンペーンメールを送信すると、どのような行動を行うのかが既知である状況。
強化学習の場合、上記仮定は成り立たないとする。不完全な知識を元に行動しながら、
データを収集し、最適な行動を見つけていく。
過去のデータで、ベストとされる行動のみを常に取り続ければ他にベストな行動を見つけることはできない
→探索が足りない状態
↑
トレードオフの関係
↓
未知の行動のみを取り続ければ、過去の経験が活かせない
→利用が足りない状態
1.4.強化学習と通常の教師あり、教師なし学習との違い
結論から述べると目標が異なる。
教師なし、教師あり学習では、データに含まれるパターンを見つけ出すことが目標。
一方で、強化学習では、優れた方策を見つけることが目標。
2.AlphaGo
2.1.PolicyNet(方策関数)とValueNet(価値関数)について



2.2.RollOutPolicy
NNではなく、線形の方策関数である。
PolicyNetでは学習に時間がかかるため、この手法を用いる(ただし精度は落ちる)。

2.3.AlphaGoの学習
1) 教師あり学習によるRollOutPolicyとPolicyNetの学習
2) 強化学習によるPolicyNetの学習
3) 強化学習によるValueNetの学習
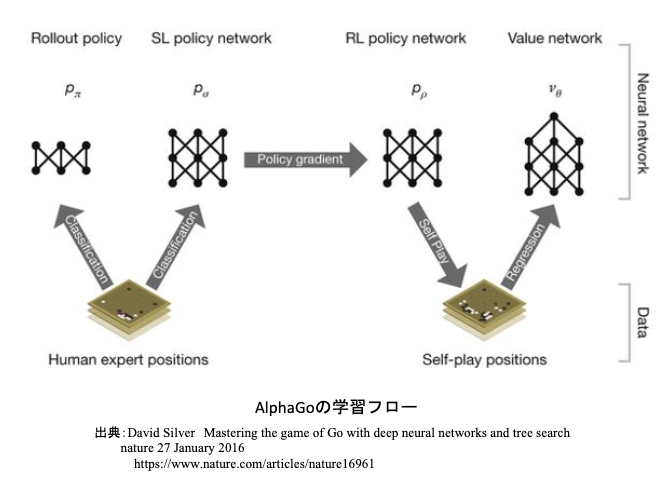
2.3.1. 教師あり学習
KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。
具体的には、教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
この学習で作成したPolicyNetは57%ほどの精度である。
2.3.2. PolicyNetの強化学習
現状のPolicyNetとPolicyPoolからランダムに選択されたPolicyNetと対局シミュレーションを行い、その結果を用いて方策勾配法で学習を行った。PolicyPoolとは、PolicyNetの強化学習の過程を500Iteraionごとに記録し保存しておいたものである。現状のPolicyNet同士の対局ではなく、PolicyPoolに保存されているものとの対局を使用する理由は、対局に幅を持たせて過学習を防ごうというのが主である。
この学習をminibatch size 128で1万回行った。
2.3.3. ValueNetの強化学習
PolicyNetを使用して対局シミュレーションを行い、その結果の勝敗を教師として学習した。
【教師データ作成の手順】
1) まずSL PolicyNet(教師あり学習で作成したPolicyNet)でN手まで打つ。
2) N+1手目の手をランダムに選択し、その手で進めた局面をS(N+1)とする。
3) S(N+1)からRLPolicyNet(強化学習で作成したPolicyNet)で終局まで打ち、その勝敗報酬をRとする。
S(N+1)とRを教師データの対にして、**回帰問題(誤差関数は平均二乗誤差)**として学習した。この学習をminibatch size 32で5000万回行った。
N手までとN+1手からのPolicyNetを別々にしてある理由は、過学習を防ぐためであると論文では説明されている。
2.4.AlphaGo Zero
2.4.1.AlphaGoとAlphaGo Zeroの違い
1) 教師あり学習を一切行わず、強化学習のみで作成
2) 特徴入力からヒューリスティックな要素を排除し、石の配置のみにした
3) PolicyNetとValueNetを1つのネットワークに統合した
4) Residual Net(後述)を導入した
5) モンテカルロ木探索からRollOutシミュレーションをなくした
2.4.2.AlphaGo ZeroのNetwork
先ほど述べたようにPolicyNetとValueNetが1つのネットワークに統合している。
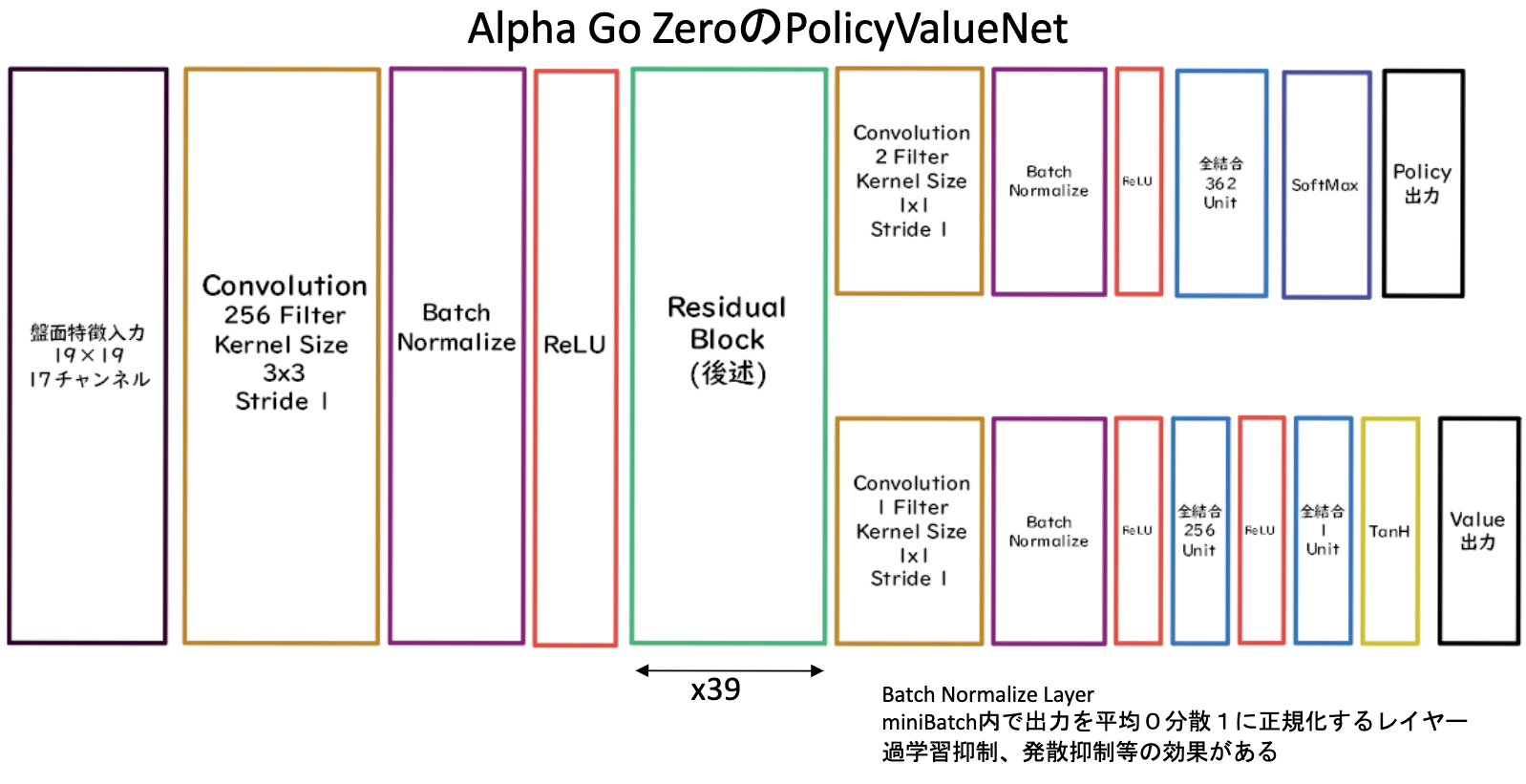
2.4.3.ResidualBlock
上図のResidualBlockの中身。
ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの。
Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった。
基本構造は
Convolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLU
のBlockを1単位にして積み重ねる形となる。また、Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある

2.4.4.AlphsGo Zeroの学習
Alpha Goの学習は大きく分けて3ステップある。
-
自己対局による教師データの作成
-
学習
-
ネットワークの更新
-
自己対局による教師データの作成現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。自己対局中の各局面での着手選択確率分布と勝敗を記録する。教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。
2)学習自己対局で作成した教師データを使い学習を行う。NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。
3)損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差。
ネットワークの更新学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
3.軽量化・高速化技術
3.1.分散深層学習
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。
•複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行いたい。
•データ並列化、モデル並列化、GPUによる高速技術は不可欠である。
3.2.データ並列化
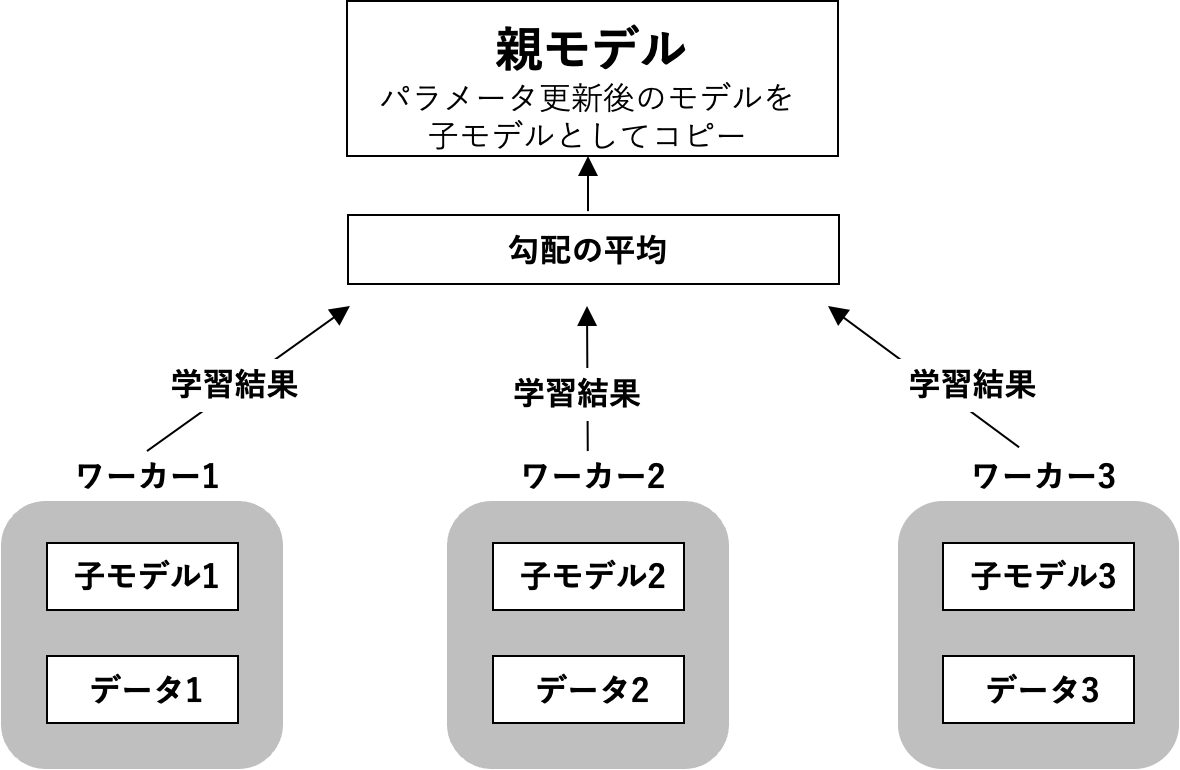
3.2.1データ並列化とは
•親モデルを各ワーカーに子モデルとしてコピーする。
•データを分割し、各ワーカーごとに計算させる。

3.2.2.データ並列化 同期型
データ並列化の同期型は、各ワーカーの計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する手法。
3.2.3.データ並列化 非同期型
非同期型のパラメータ更新は、各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。

3.2.4.同期型と非同期型の比較
•処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
•現在は同期型の方が精度が良いことが多いので、主流となっている。
•非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
-> Stale Gradient Problem
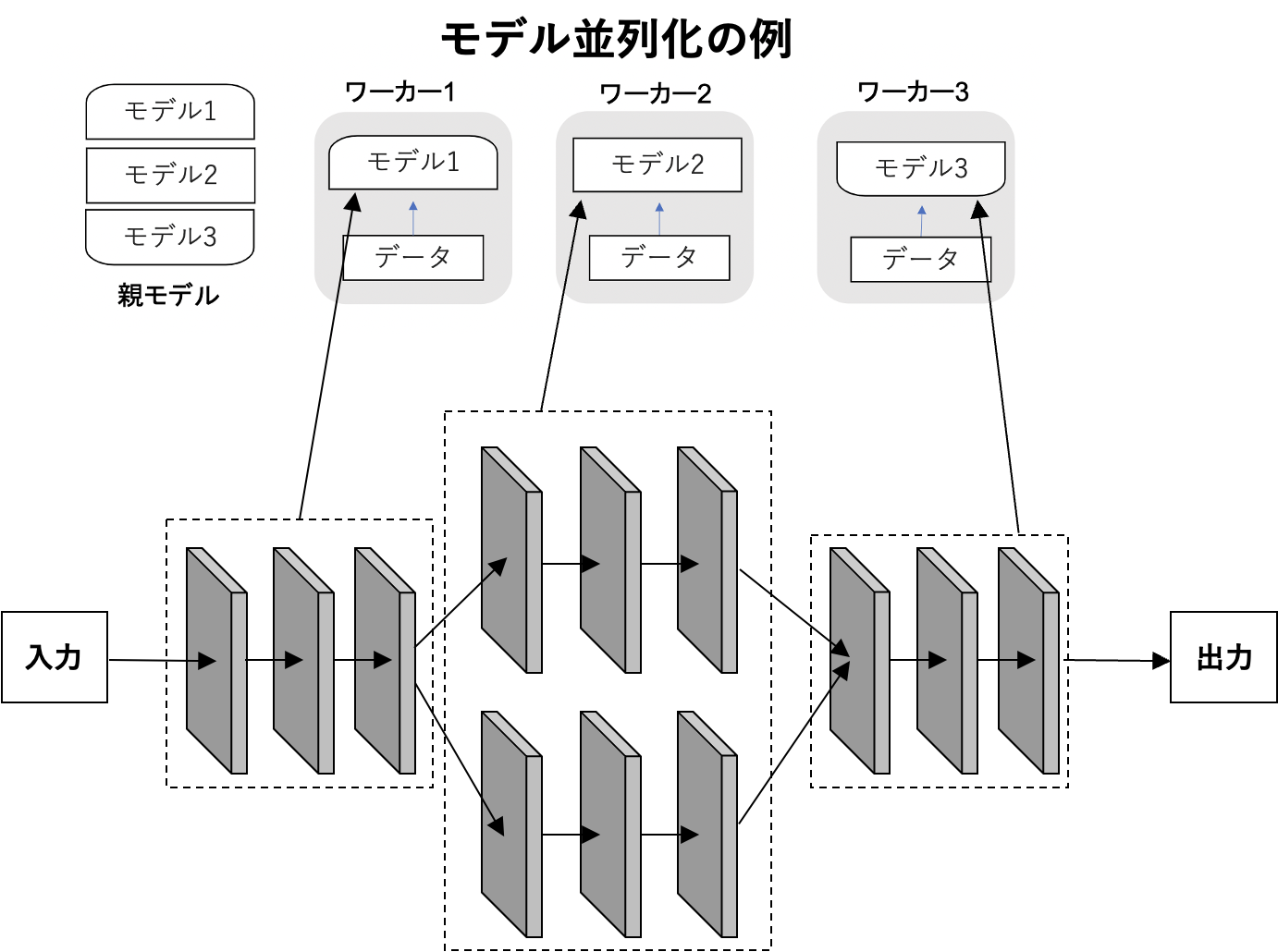
3.3.モデル並列化
•親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元。
•モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
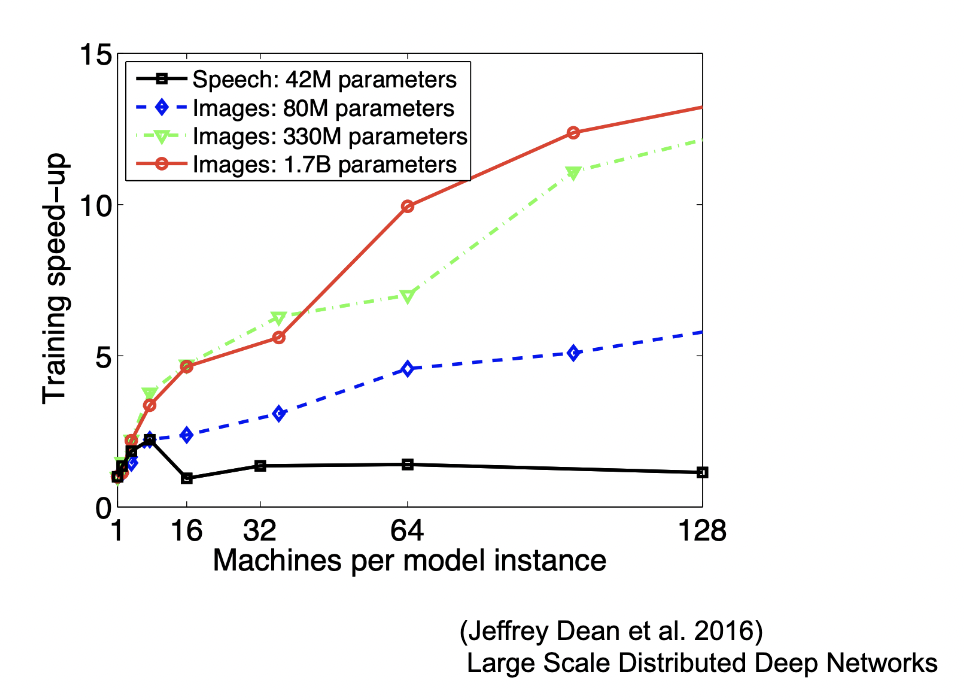
モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
3.4.GPUによる高速化
・GPGPU (General-purpose on GPU)
元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称
・CPU
高性能なコアが少数。複雑で連続的な処理が得意
・GPU
比較的低性能なコアが多数。簡単な並列処理が得意。
ニューラルネットの学習は単純な行列演算が多いので、高速化が可能
3.5.軽量化の手法
3.5.1.量子化(Quantization)
ネットワークが大きくなると大量のパラメータが必要なり学習や推論に多くのメモリと演算処理が必要。
そこで通常のパラメータの64bit浮動小数点を32bitなど下位の精度に落とすことでメモリと演算処理の削減を行う。
3.5.2.蒸留
規模の大きなモデルの知識を用いて、軽量なモデルの作成を行う手法。
学習済みの精度の高いモデルの知識を軽量なモデルへ継承させる。
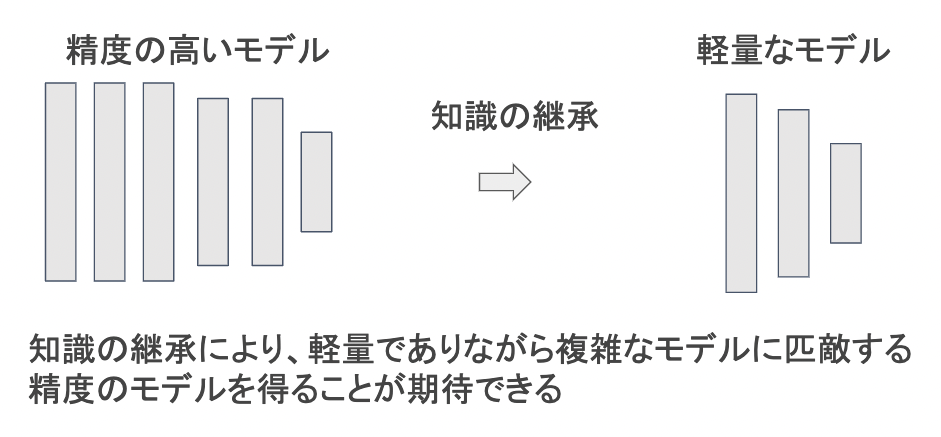
蒸留は教師モデルと生徒モデルの2つで構成される。
教師モデル
予測精度の高い、複雑なモデルやアンサンブルされたモデル
生徒モデル
教師モデルをもとに作られる軽量なモデル

3.5.3.プルーニング
モデルの精度に対して寄与度が小さいニューロンを削減することでモデルの軽量化・高速化が見込まれる。
以下の表は、実際にOxford 102 category ower datasetをCaffeNetで学習したモデルをプルーニングしたものである。
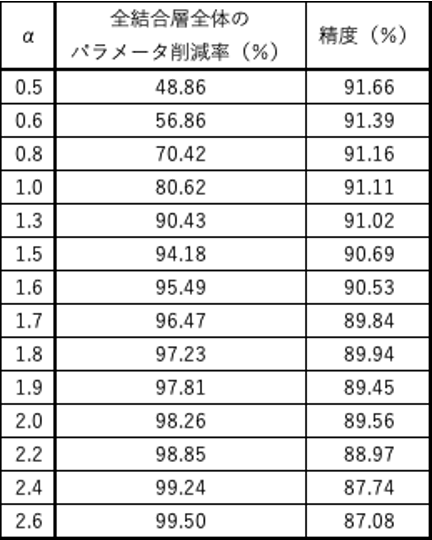
佐々木健太、佐々木勇和、鬼塚真(2015)「ニューラルネットワークの全結合層におけるパラメータ削減手法の比較」
4.応用技術
4.1.MobileNets
Depthwise ConvolutionとPointwise Convolutionの組み合わせで軽量化を実現。
全体像は以下の通りとなっている。
具体的な説明は後述していく。

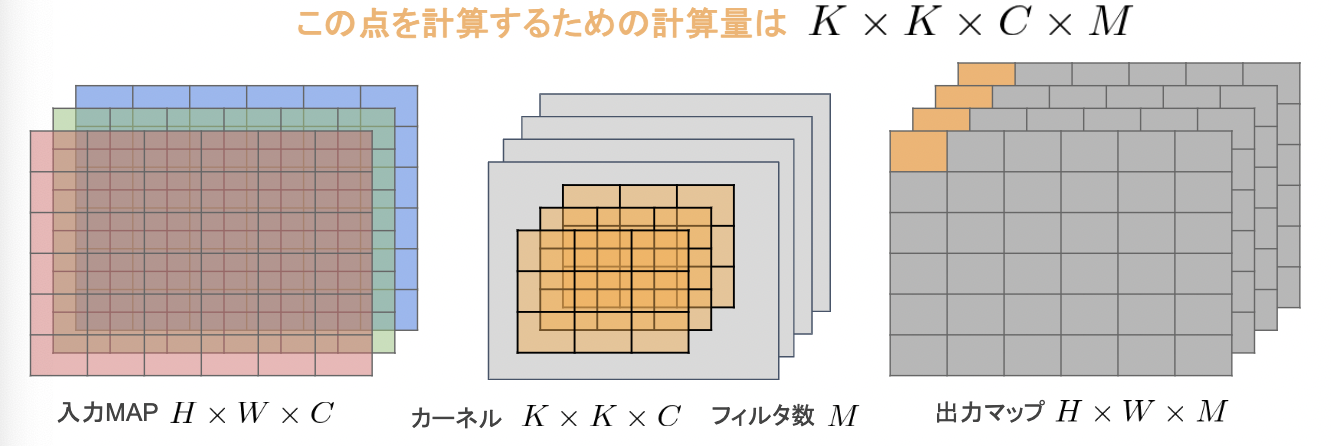
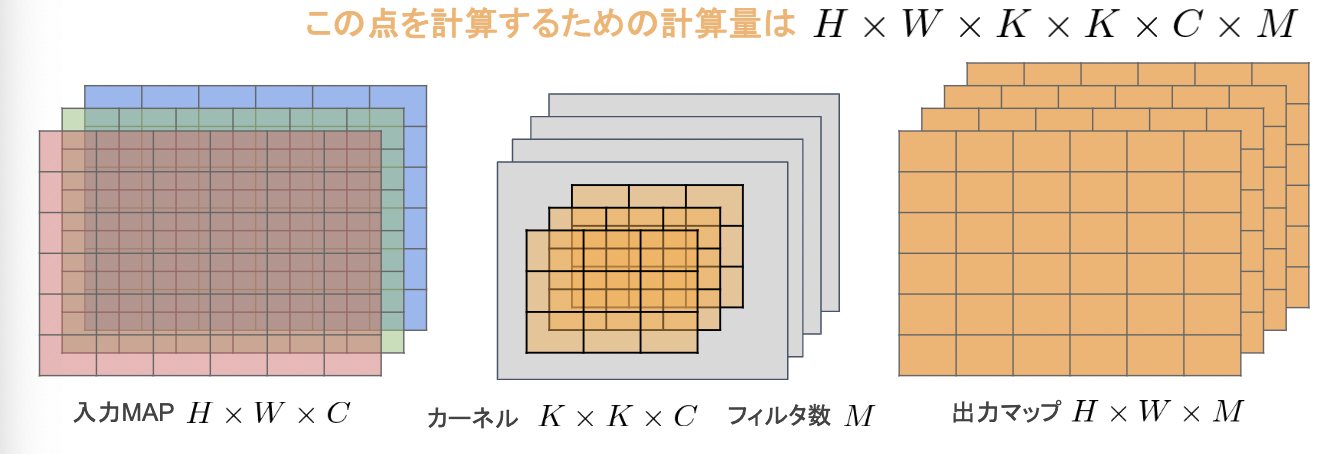
【一般的な畳み込みレイヤー】
○入力特徴マップ(チャネル数):H×W×C
○畳込みカーネルのサイズ:K×K×C
○出力チャネル数(フィルタ数):M
○ストライド1でパディングを適用した場合
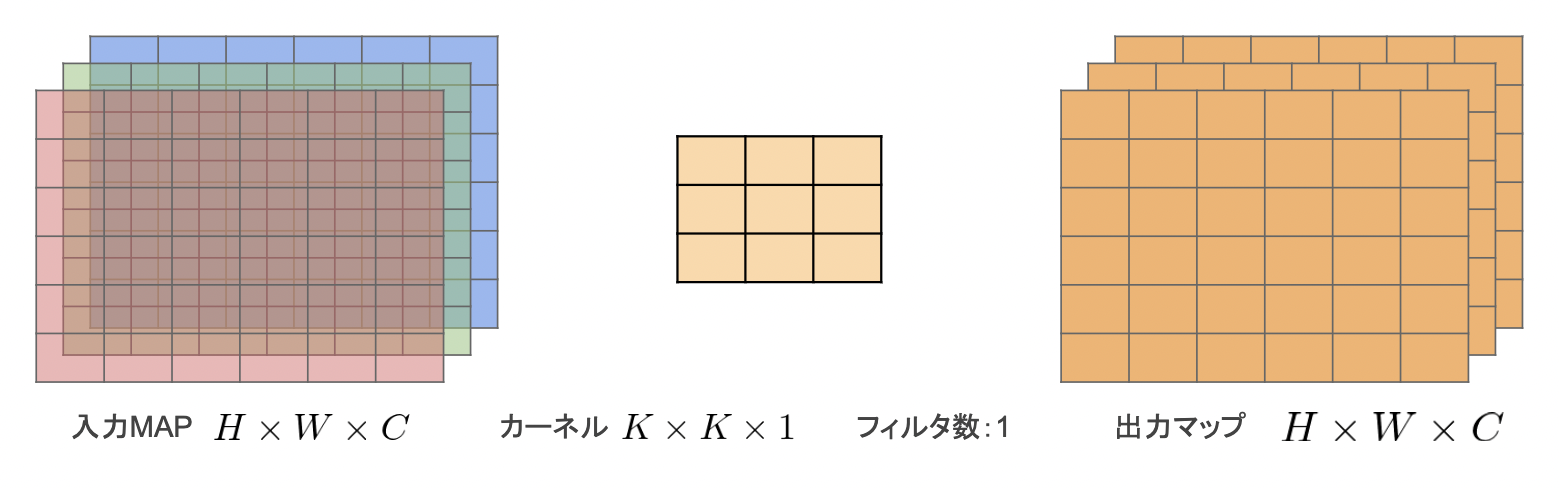
【Depthwise Convolution】
・入力マップのチャネルごとに畳み込みを実施。
・出力マップをそれらと結合(入力マップのチャネル数と同じになる)
・通常の畳み込みカーネルは全ての層にかかっていることを考えると計算量が大幅に削減可能。
・各層ごとの畳み込みなので層間の関係性は全く考慮されない。
→通常はPW畳み込みとセットで使うことで解決
・出力マップの計算量
$$H×W×C×K×K$$
【Pointwise Convolution】
・1 x 1 convとも呼ばれる(正確には1 x 1 x c)
・入力マップのポイントごとに畳み込みを実施
・出力マップ(チャネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)
・出力マップの計算量
$$H×W×C×M$$

4.2.DenseNet
Dense Convolutional Network(以下、DenseNet)は、CNNアーキテクチャの一種である。ニューラルネットワークでは層が深くなるにつれて、学習が難しくなるという問題があったが、ResNetなどのCNNアーキテクチャでは前方の層から後方の層へアイデンティティ接続を介してパスを作ることで問題を対処した。DenseNetは、DenseBlockと呼ばれるモジュールを用いたアーキテクチャの一つである。
Transition Layerと呼ばれる層でDence blockをつなぐ。そこでは特徴マップのサイズを変更し、ダウンサンプリングを行っている(青い枠内がTransition Layer)。

出力層に前の層の入力を足しあわせる。
層間の情報の伝達を最大にするために全ての同特徴量サイズの層を結合する。

4.3.WaveNet
時系列データに対してDilated Convolution(畳み込み)を適用する
【Dilated Convolution】
層が深くなるにつれて畳み込むリンクを離す。
受容野を簡単に増やすことができるという利点がある。

<確認テスト>
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNetの大きな貢献の1つである。提案された新しいConvolution 型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。(あ)に入るものを選べ。
- Dilated causal convolution
- Depthwise separable convolution
- Pointwise convolution
- Deconvolution
<解答>
1)が正しい
2)、3)はMobileNetで扱われるもの
4)は逆畳み込みと呼ばれ、画像の解析度を上げる際に用いられる
<確認テスト2>
Dilated causal convolutionを用いた際の大きな利点は、単純なConvolution layer と比べて(い)ことである。
1) パラメータ数に対する受容野が広い
2) 受容野あたりのパラメータ数が多い
3) 学習時に並列計算が行える
4) 推論時に並列計算が行える
<解答2>
1)が正しい