ラビットチャレンジのレポートに関するリンクはこちら
ラビットチャレンジ 応用数学
ラビットチャレンジ 機械学習
ラビットチャレンジ 深層学習 Day1
ラビットチャレンジ 深層学習 Day2
ラビットチャレンジ 深層学習 Day3
ラビットチャレンジ 深層学習 Day4前半
ラビットチャレンジ 深層学習 Day4後半
各項目の要約についてまとめています。
線形回帰モデル
非線形回帰モデル
ロジスティック回帰モデル
主成分分析
k-NN, k-means
サポートベクターマシン
線形回帰モデル
・線形回帰は教師あり学習で、特に回帰問題の手法のなかで最も基本的な回帰モデルである。
線形回帰モデルは、入力と出力との関係が1次式によっておおよそ表現可能な場合に有効なモデルで、2乗損失と呼ばれる損失を最小化するような1次式を予測器として学習する。
また、線形回帰モデルの学習は
・外れ値の影響を強く受ける。
・多重共線性に注意する
といったことを意識する必要がある。
$$
\hat{y} =w_0 + \boldsymbol{w^Tx} = w_0 + w_1x_1 + \cdots + w_ix_i
$$
最小二乗法とは、学習データの最小2乗誤差を最小とするようにパラメータを推定すること。
最小2乗誤差(MSE)の式
$$
MSE_{train}=\frac{1}{n}\sum_{i=1}^n(y_i- \hat{y}_i)^2
$$
・重みwは最小二乗法により求めることができ、解析的に解くことができる。
重みの導出式
$$
\boldsymbol{w} =\boldsymbol{(X^TX)}^{-1}\boldsymbol{X^Ty}$$
※ 最小二乗法の解析解である
$$
\boldsymbol{w}=\boldsymbol{(X^TX)}^{-1}\boldsymbol{X^Ty}
$$
についてもう少し理解を深めておこう。
基本的に回帰分析を点を通る直線を求める問題であると解釈すれば、
$$X\mathbf{w} = \mathbf{y}$$
を$w$について解く問題であると考えられる。
ここから、すぐに
$$\mathbf{w} = X^{-1}\mathbf{y}$$
と変形したいところだが、この方程式が解を持つのは、$X$が正方行列(データ数と説明変数+1の数が同じ)かつ逆行列を持つ場合のみである。そこで式の両辺に$X$の転置行列である$X^T$を乗ずる。すると式は
$$X^TX \mathbf{w} = X^T\mathbf{y}$$
ここで、$X^TX$は必ず正方行列となることに注意し、それが逆行列を持つならば、両辺にその逆行列$$\mathbf{(X^TX)^{-1}}$$を乗じて、
$$\mathbf{w} = \mathbf{(X^TX)^{-1}X^Ty}$$
を得ることができる。
・重みの導出式と同様、予測値も定式化できる。
予測値:
$$\hat{y} =\boldsymbol{X(X^TX)}^{−1}\boldsymbol{X^Ty }$$
・説明変数が1次元の場合(n=1)は単回帰となり、2次元以上の場合(n>1)は重回帰となる。
非線形回帰モデル
・非線形回帰モデルは学習パラメータwと目的変数との関係が線形になっていないモデル。
指数関数や反比例の分母に重みがついている場合は非線形回帰であるが、多項式は重みがxの累乗にかかっているだけであり線形な関係が成り立っているため、多項式回帰は線形回帰に分類される。
非線形回帰の例:
$$y=exp^x$$
$$y=w_0 + w_1x_1^2$$
線形回帰(多項式回帰)の例:
$$
w_0+w_1x_1+ w_2x_1^2
$$
・回帰を実行するにあたり、未学習と過学習の対策が必要。
未学習:学習データに対して、十分小さな誤差が得られないこと。
対策→表現力の高いモデルを採用する。
過学習:学習データへの当てはまりが良すぎて、テストデータに対する誤差が大きくなりすぎていること。
対策→学習データ数を増やす、不要な基底関数を削除する、正則化を行う。
・正則化とは、損失関数に罰則項を組み込むことで、次数が大きくなった時のパラメータを抑え、モデルの複雑さを緩和すること。
複雑なモデルが過学習を起こす原因として、学習パラメータが極端に大きい(または小さい)ことが挙げられる。
罰則項は、学習パラメータの絶対値が大きくなることに対して、損失が大きくなるような罰則を与える役割を持っている。
L1ノルムを利用する場合の回帰をLasso回帰、
L2ノルムを利用する場合の回帰をRidge回帰と呼ぶ。
Lasso回帰:
$$||w||=|w_0|+|w_1|+\cdots+|w_d|$$
Ridge回帰:
$$||w||^2=w_0^2+w_1^2\cdots+w_d^2$$
・作成されたモデルの汎化性能を検証するためにホールドアウト法や交差検証法が存在する。
学習データや検証データの相性が偶然にもよい(または悪い)場合があるため、交差検証を行うことが推奨される。
以下に線形回帰の実装コードを記載する。
# 線形回帰モデルの実装
import numpy as np
import matplotlib.pyplot as plt
# ランダムな値を生成
seed = np.random.RandomState(0)
x = 30*seed.rand(100)
y = x*2 - 14 + 10*seed.rand(100)
# 関数を作成
def LinearRegression(x, y):
a_nume = np.dot(x, y) - x.sum() * y.sum() / len(x)
a_denom = (x**2).sum() - x.sum()**2/len(x)
a = a_nume/ a_denom
d = (y.sum() - a * x.sum()) / len(x)
return a, b
a, b = LinearRegression(x, y)
y_ = a*x + b
# 可視化
plt.figure(figsize=(5, 5))
plt.scatter(x, y)
plt.plot(x, y_, c='indianred')
plt.show()
ロジスティック回帰モデル
・ロジスティック回帰はある事象が起こる確率を学習し、ある事象が起こる・起こらないの2値分類を行うモデル。
入力とn次元パラメータの入力をシグモイド関数に入力すると、y=1となる確率の値を出力する。
シグモイド関数の式:
$$
σ(z)=\frac{1}{1+exp({-z})}
$$
・あるデータxが与えられた時にy=1である確率pは
$$
p=σ(w_0 + w^TX)
$$
通常は予測確率0.5を閾値とし、
0.5より小さい場合 -> yの予測値は0
0.5以上の場合 -> yの予測値は1
と判定する。
import numpy as np
class Sigmoid:
def forward(self, x, w, b):
"""
x.shape = (データ数, 次元数)
w.shape = (1, 次元数)
b.shape = (1,)
"""
self.x = x
z = np.sum(w * x, axis=1) + b
y_pred = 1 / (1 + np.exp(-z))
self.y_pred = y_pred
return y_pred
def backward(self, dy):
dz = dy * (1 - self.y_pred) * self.y_pred
dw = np.sum(dz.T * self.x, axis=0)
db = np.sum(dz)
return dw, db
x = np.array([[1, 2],
[4, 5]])
w = np.array([0.1, 0.2])
b = 3
Sig = Sigmoid()
Sig.forward(x, w, b)
・シグモイド関数の微分は、シグモイド関数自身で表現することが可能。
$$ σ(z)'=σ(z)(1−σ(z))
$$
・ロジスティック回帰のパラメータは最尤推定で求める。
最尤推定とは、尤度関数を最大にするようなパラメータを選ぶ方法である。
ロジスティック回帰の尤度関数:
$$
\begin{align}
L(w_0+w_1+⋯+w_n)&=−\log{L}(w_0+w_1+⋯+w_n)\
&=−\sum_{i=1}^n{y_i\log{p_i}+(1−y_i)\log{(1−p_i)}}
\end{align}
$$
・上式の尤度関数を最小化するパラメータは解析的には求まらないため、勾配降下法を用いる。
勾配降下法は反復学習によりパラメータを逐次的に更新するアプローチのひとつ。
勾配降下法ではパラメータを更新するのにすべてのデータに対する和を求める必要があるため、膨大な計算資源が必要になることがある。
そのため、データを1つずつランダムに選んでパラメータを更新する
***「確率的勾配降下法」***を用いて、効率よく最適な解を求めるアプローチを通常とる。
パラメータ更新の式:
$$
w_{k+1}=w_k+η(y_i−p_i)x_i
$$
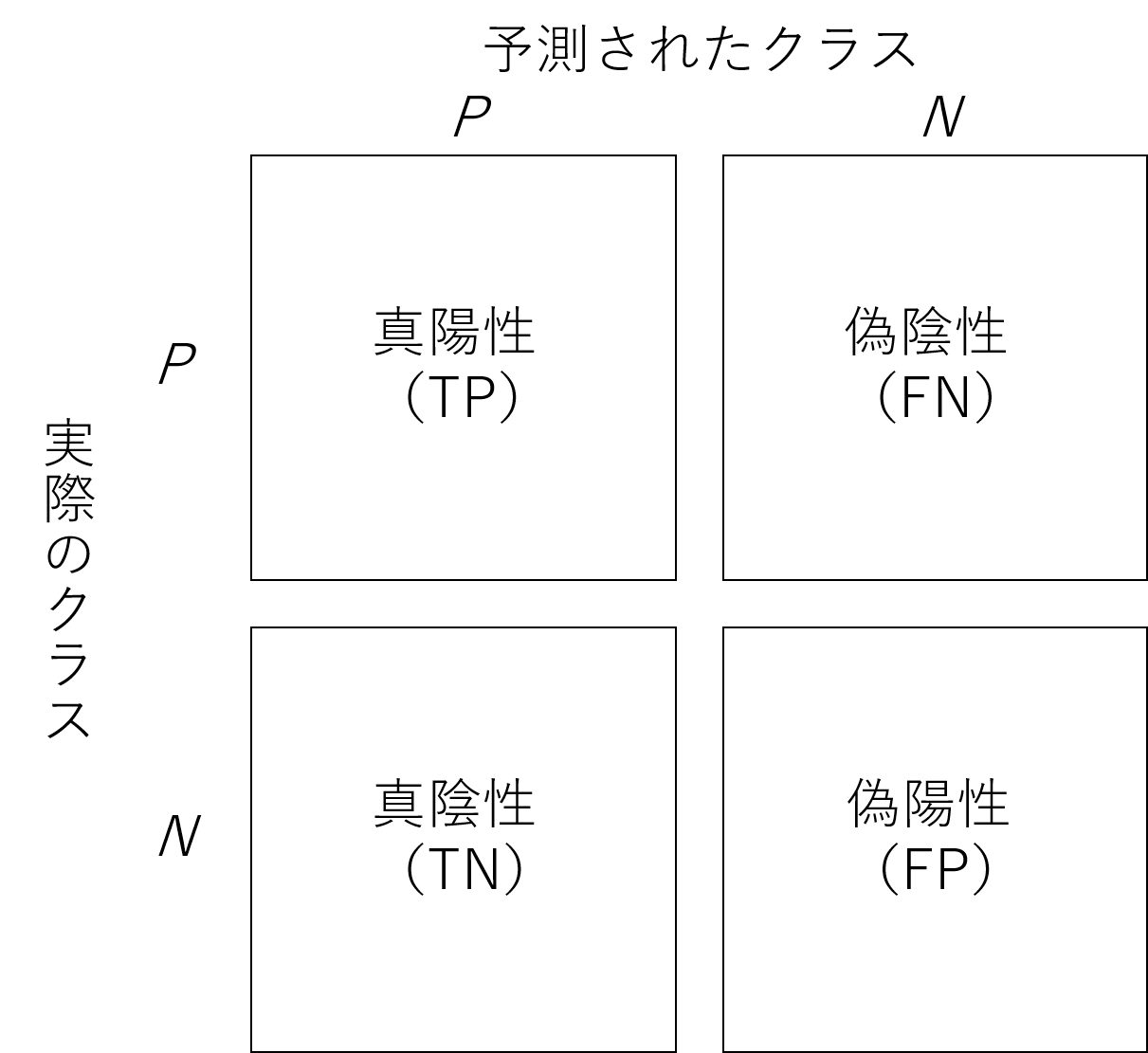
分類の評価方法
(1) 再現率(REC)
本当にPositiveであるものの中からPositveと予測できている割合
$$
REC = \frac{TP}{TP+FN}
$$
※TP:True Positive, FN:False Negative
(2) 適合率(PRE)
モデルがPositiveと予想したものの中で本当にPositiveであったものの割合
$$
PRE = \frac{TP}{TP+FP}
$$
※TP:True Positive, FP:False Positive
(3) F値
PREとRECの調和平均でも求めることができる
$$
F = \frac{2(PRE×REC)} {(PRE+REC)}
$$
主成分分析
・データの変数を圧縮する手法の一つ。対象データにおける方向と重要度を見つける。
・主成分ごとに計算される固有値を固有値の総和で割ると、主成分の重要度を割合で表すことが可能。
この時の割合を寄与率という。
・主成分分析で計算される第一主成分は分散を最大化するような軸になっている。
→元データの情報を多く含んでいる。
・主成分分析の手順
①分散共分散行列を求める
②分散共分散行列に対して、固有値問題を解き、固有ベクトル・固有値を求める。
③各主成分方向にデータを表現する
以下にボストン住宅のデータセットを用いて実装
from sklearn.datasets import load_boston
import pandas as pd
# データの読み込み
boston = load_boston()
# pandasのデータフレーム形式に変換
df = pd.DataFrame(boston.data, columns=boston.feature_names)
from sklearn.decomposition import PCA
# 3次元に次元圧縮
pca = PCA(n_components=3)
df_pca = pca.fit_transform(df)
# 次元圧縮後のデータを確認
print(df_pca)
# 固有値を出力
print('固有値:', pca.explained_variance_)
# 寄与率を出力
print('寄与率:', pca.explained_variance_ratio_)
(1) k近傍法
・k近傍法のアルゴリズム
①入力データと学習データの距離を計算する。
②入力データに近いほうからk個の学習データを取得する。
③学習データのラベルで多数決を行い、分類結果とする。
・2値分類の場合にはkを奇数にとり、多数決の結果がどちらかに決まるようにすることが一般的。
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
%matplotlib inline
from sklearn.neighbors import KNeighborsClassifier
from sklearn import metrics
# iris datasets
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
kNN = KNeighborsClassifier(n_neighbors=6)
kNN.fit(X, y)
y_pred = kNN.predict(X)
print(metrics.accuracy_score(y, y_pred))
(2) k-means法
・k-means法のアルゴリズム
①データ点の中心から、適当な点をクラスタ数だけ選び、それらを重心とする。
②データ点と各重心の距離を計算し、最も近い重心をそのデータ点の所属するクラスタとする。
③クラスタごとにデータ点の平均値を計算し、それを新しい重心とする。
④2と3を繰り返し実行し、すべてデータ点が所属するクラスタが変化しなくなるか、計算ステップ数の上限に達するまで計算を続ける。
・2,3の手順では重心の選び方によって、学習がうまく進まない場合がある。
k-means++という手法を利用するとなるべく離れた重心を初期値として選ぶため、この問題に対応することができる。
# k-meansの実装
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
%matplotlib inline
# iris datasets
iris = load_iris()
X = iris.data[:, :2]
y = iris.target
km = KMeans(n_clusters=3, init='k-means++')
km.fit(X, y)
y_means = km.predict(X)
plt.scatter(X[y_means == 0, 0], X[y_means == 0, 1], c = 'red', label = 'Iris-setosa')
plt.scatter(X[y_means == 1, 0], X[y_means == 1, 1], c = 'blue', label = 'Iris-versicolour')
plt.scatter(X[y_means == 2, 0], X[y_means == 2, 1], c = 'green', label = 'Iris-virginica')
# Plotting the centroids of the clusters
plt.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:,1], c = 'yellow', label = 'Centroids')
plt.legend()
サポートベクターマシン
・線形判別関数(決定境界)と最も近いデータ点との距離をマージンとよび、マージンが最大化されるような線形判別関数を求める。
線形判別関数:
$$
\boldsymbol{w^Tx}+b=0
$$
サポートベクトルマシーンにはデータを分類するための超平面を求めて、データの分類を行なっている。
その超平面の計算方法として、ハードマージン法とソフトマージン法がある。
ハードマージン法は、データが空間上できれいにクラスごとに分離している場合だけに適用できる。これに対して、ソフトマージン法は、データがきれいに分離していなくても適用でき、その適用範囲は広い。ソフトマージン法では、教師データが間違って分類された場合に、ペナルティを与えることで誤分類に対応している
・カーネルトリックを利用することで、複雑な決定境界を学習することができる。
カーネル関数:
$$
k(xi,xj)=ϕ(x_i)^Tϕ(x_j)
$$