初版: 2021年6月4日
著者: 橋本恭佑、柿田将幸, 株式会社 日立製作所
はじめに
近年、機械学習をはじめとするAI技術を活用したデータ分析が注目を集めており、AIを活用する案件が増加しています。
機械学習モデルを活用したシステムを構築する案件では、まずPoC(Proof of Concept)で機械学習モデルの有用性を確認し、その成果をもとに本番用のシステムを開発するケースが多いです。機械学習モデルをシステムに組み込み、サービスとして公開する一連の技術はサービング技術と呼ばれており、システム構築と運用を担う技術者にとって重要な技術です。
特に、機械学習サービスの負荷が大きく変動する場合は、負荷に合わせて柔軟にリソースを増減可能なパブリッククラウド上でのサービングが有効といえます。
本連載では、オンプレミス環境で作成した機械学習モデルをパブリッククラウド(AWSおよびMicrosoft Azure)でサービングする技術について、実際に検証した手順を交えながら解説します。
投稿一覧
- AWSとMicrosoft Azureにおける機械学習モデルのサービング技術の概要・・・本投稿
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: AWS/Azureが提供するコンテナイメージを利用する場合
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: 自作コンテナイメージを利用する場合
- AWS FargateとAzure Container Instancesにおける機械学習モデルのサービング技術比較
パブリッククラウドにおける機械学習モデルのサービングパターン
パブリッククラウドにおける機械学習モデルのサービング
パブリッククラウドにおける機械学習モデルのサービングに必要なコンポーネントとサービングの手順の概要を図1に示します。
パブリッククラウド上で機械学習モデルをサービングする際は、前処理、モデル、後処理、およびそれらの実行に必要なライブラリ群を、
パブリッククラウドのコンテナ基盤上にまとめてコンテナとしてデプロイします。
AWSやMicrosoft Azureが提供する機械学習プラットフォームであるAmazon SageMakerやAzure Machine Learning(以下、Azure ML)では、
各々の機械学習プラットフォーム上で機械学習モデルを学習させて、同じパブリッククラウドのコンテナ基盤上へサービングする機能を提供しています。
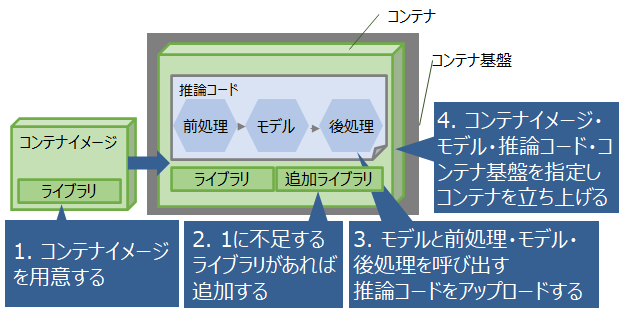
図1 パブリッククラウドにおける機械学習モデルのサービングに必要なコンポーネントとサービングの手順の概要
オンプレミス環境で作成した機械学習モデルのサービングパターン
Amazon SageMakerやAzure MLを利用してサービングする場合は、SageMakerやAzure ML上で利用可能なコンテナイメージを用意します1。
AWSやMicrosoft Azureが提供するコンテナイメージに、必要なライブラリが不足している場合や、オンプレミス環境で利用したライブラリとバージョンが異なる場合は、次の2つのパターンのいずれかを行う必要があります。
- パターン1: パブリッククラウドが提供するコンテナイメージをコンテナ基盤にデプロイするときに、ライブラリの追加またはバージョン変更して、前処理・モデル・後処理を追加する
- パターン2: パブリッククラウドが提供するコンテナイメージを利用せず、オンプレミス環境で必要なライブラリを含んだコンテナイメージを作成して、コンテナ基盤へデプロイするときに、前処理・モデル・後処理を追加する
一方で、Amazon SageMakerやAzure MLを利用せずにサービングする場合は、AWS FargateやAzure Container Instance (Azure CI)といったコンテナ実行サービスを利用します。
- パターン3: オンプレミス環境でライブラリ・前処理・モデル・後処理を含んだコンテナイメージを作成し、コンテナ基盤へデプロイする
パターン1、パターン2、パターン3の比較を表1に示します。パターン毎に、オンプレミス環境で用意するものの多さと、パブリッククラウド環境で必要な手順の多さが異なります。
表1 サービングパターンの比較
| パターン | サービングに利用するクラウドサービス | ベースとなるコンテナイメージ | 必要ライブラリの追加方法 | 前処理・モデル・後処理の追加方法 |
|---|---|---|---|---|
| 1 | 機械学習プラットフォーム(Amazon SageMaker/Azure ML) | パブリッククラウドが提供 | コンテナイメージのデプロイ後に追加 | コンテナイメージをデプロイするときに追加 |
| 2 | 機械学習プラットフォーム(Amazon SageMaker/Azure ML) | オンプレミス環境で作成 | コンテナイメージの作成時に追加 | コンテナイメージをデプロイするときに追加 |
| 3 | コンテナ実行基盤(Amazon Fargate/Azure CI) | オンプレミス環境で作成 | コンテナイメージの作成時に追加 | コンテナイメージの作成時に追加 |
パターン1とパターン2については、機械学習モデルの学習や更新を担う技術者にとってのライブラリの利用の手間と、機械学習モデルの学習や更新を担う技術者の責任範囲の大きさのトレードオフがあります。
パターン1は機械学習モデルの学習や更新を担う技術者が、オンプレイス環境で学習に利用したライブラリをすぐにパブリッククラウド上に引き継いでサービングできます。一方で、サービング後もライブラリの更新まで担う必要があり、責任範囲が大きくなります。
これに対し、パターン2はオンプレミス環境でライブラリをインストールしたコンテナイメージを作成する手間が増えますが、機械学習モデルの学習や更新を担う技術者はモデルや推論コードの運用に注力でき、責任範囲を局所化できます。
パターン3については、パターン1、2と比較して、オンプレミスで動作確認した推論コードとライブラリを改変なしにパブリッククラウド上で利用開始できることが利点です。一方でサービング後にAmazon SageMakerやAzure MLで利用可能な機械学習モデルの監視機能や再学習機能を利用できないことが欠点です。
本連載では、パターン1からパターン3を実際にパブリッククラウドで試し、パブリッククラウド毎にどのパターンが可能であるかを確認します。さらに、複数のパブリッククラウドで可能なパターンについては、実際に試した結果を踏まえて、どのパブリッククラウドのサービスを使うべきか、指針を示します。
サービング検証のシナリオ
パターン1からパターン3の実現可能性と各パターンの選定の指針を検討するために、今回設定した検証シナリオを説明します。
今回の投稿では機械学習モデルの学習に用いたソースコードと、前処理、推論、後処理を行うソースコードを紹介し、次回以降の投稿で実際にパブリッククラウドでサービングした結果を紹介します。
検証シナリオ: MNISTデータセットを用いた手書き文字画像の認識
本連載における検証シナリオでは、オンプレミス環境で学習させた手書き文字認識(MNIST)の機械学習モデルをパブリッククラウドでサービングします。
MNISTは28×28ピクセルの手書き画像で、ピクセル値は0から255までの整数です。MNISTのデータセットを学習用データセットと推論用データセットに分割し、学習用データセットを用いて作成した機械学習モデル(joblibファイル)に、JPEGファイルの手書き画像データを入力させて推論結果を出力します。
まず、機械学習モデルの前処理、学習、後処理、推論を実行する環境を用意します。表2に本検証シナリオに用いたpythonライブラリのバージョンを示します。
表2: 今回の検証シナリオに用いたpythonライブラリのバージョン
| ソフトウェア | バージョン |
|---|---|
| python | 3.7.6 |
| numpy | 1.18.1 |
| scikit-learn | 0.22.1 |
| pillow | 7.0.0 |
| joblib | 1.0.0 |
| flask | 1.1.2 |
手書き文字認識モデルの学習
下記に学習用のソースコード(train.py)を示します。
import numpy as np
from sklearn import model_selection, svm, metrics
from sklearn.neural_network import MLPClassifier
import joblib
# MNISTデータセット(mnist.npz)を学習用データセットと推論用データセットに分割する
# X_train is 60000 rows of 28x28 values --> reshaped in 60000 x 784
RESHAPED = 784
NB_CLASSES = 10
x_train = x_train.reshape(60000, RESHAPED)
x_test = x_test.reshape(10000, RESHAPED)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# 学習
clf = MLPClassifier(hidden_layer_sizes=(128,),
solver='adam', max_iter=20, verbose=10, random_state=0)
clf.fit(x_train, y_train)
# 推論用データセットを利用して精度を検証
print('accuracy_score: %.3f' % clf.score(x_test, y_test))
# joblibファイルとして機械学習モデルをエクスポート
joblib.dump(clf, "./model.joblib")
手書き文字認識モデルによる推論
次に、推論用のソースコード(api_server.py)を示します。
import argparse
import os
import sys
import numpy as np
from PIL import Image
import joblib
import flask
app = flask.Flask(__name__)
@app.route("/")
def hello_world():
return 'Flask Hello world'
@app.route("/predict", methods=["POST"])
def predict():
model = joblib.load(os.path.join(“/root/serving/”, "model.joblib"))
response = {"Content-Type": "application/json",
"number": None}
RESHAPED = 784
if flask.request.method == "POST":
if flask.request.files["file"]:
image_number = np.array(
Image.open(flask.request.files["file"]).convert('L'))
array = [image_number.reshape(RESHAPED)]
print('type(array): {0}, array: {1}'.format(type(array), array))
prediction = model.predict(array)
response["number"] = str(prediction[0])
return flask.jsonify(response)
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0')
上記のソースコード(api_server.py)を実行すると、前処理、推論、後処理を行うサーバプログラムが起動します。
$ python api_server.py
* Serving Flask app "api_server" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: on
* Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)
* Restarting with stat
* Debugger is active!
* Debugger PIN: 180-690-578
手書き文字認識サービスの利用
上記のソースコード(api_server.py)を実行して、手書き数字のJPEGファイルを送信します。今回利用した手書き数字のJPEGファイルを図2に示します。
図2 今回利用した手書き数字の画像ファイル(左がx_test_30.jpeg, 右がx_test_60.jpeg)
図2に示した画像ファイルをサーバへ入力した場合の出力を下記に示します。
$ curl -F file=@x_test_30.jpeg localhost:5000/predict
{
"Content-Type": "application/json",
"number": "3"
}
$ curl -F file=@x_test_60.jpeg localhost:5000/predict
{
"Content-Type": "application/json",
"number": "6"
}
実行環境の選定
パターン1からパターン3をAWSおよびMicrosoft Azureで実現する際のサービス一覧を表3に示します。パターン1とパターン2については、Amazon SageMakerと Azure Machine Learningで対応します。また、パターン3についてはAWSではAWS Fargate、Microsoft AzureではAzure Container Instancesが対応します。
表3 オンプレミス環境で学習させた機械学習モデルをAWSおよびMicrosoft Azure上でサービングする際のサービス一覧(2021年2月現在)
| パターン | 概要 | AWS | Microsoft Azure |
|---|---|---|---|
| 1 | AWS/Azureが提供するコンテナイメージを利用(デプロイ時にライブラリと前処理・モデル・後処理を追加) | Amazon SageMaker | Azure Machine Learning |
| 2 | 自作コンテナイメージを利用(コンテナイメージ作成時にライブラリを追加し、デプロイ時に前処理・モデル・後処理を追加) | Amazon SageMaker | Azure Machine Learning |
| 3 | 自作コンテナイメージを利用(コンテナイメージ作成時にライブラリと前処理・モデル・後処理を追加) | AWS Fargate | Azure Container Instances |
おわりに
次回以降の投稿で、表3に示した各パターンをAWSおよびMicrosoft Azureで実現する技術を紹介します。また実際にサービングしてわかった注意点や使いどころを紹介します。