初版: 2021年6月9日
著者: 橋本恭佑、柿田将幸, 株式会社 日立製作所
はじめに
本投稿では、学習済みの機械学習モデルをAWS FargateおよびAzure Container Instancesを用いてサービングする方法を紹介します。
今回の検証では、サービングに必要なライブラリや前処理、モデル、後処理を含んだコンテナイメージを事前に作成しておき、それをAWS/Azureのコンテナ基盤上にデプロイして使用します(下表の赤枠の部分)。

投稿一覧
- AWSとMicrosoft Azureにおける機械学習モデルのサービング技術の概要
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: AWS/Azureが提供するコンテナイメージを利用する場合
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: 自作コンテナイメージを利用する場合
- AWS FargateとAzure Container Instancesにおける機械学習モデルのサービング技術比較・・・本投稿
本検証の事前準備
本投稿では、以前の投稿の検証シナリオで作成した下記ファイルを利用しますので、事前に用意してください。
- 学習済みの手書き文字認識モデル:
model.joblib - 前処理・モデル利用・後処理を記載したスクリプト:
api_server.py
AWSとAzureにおけるパターン3の実現技術の違い
パターン3を実現する場合の手順を図1に、パターン3を実現する場合に利用する技術をAWSとAzureで比較した結果を表2に示します。
コンテナイメージをデプロイするサービスとして、AWSの場合はAWS Fargate、Azureの場合はAzure Container Instancesを利用でき、双方の技術に大きな差分は見られません。本稿ではこの手順に沿ってパターン3が実現可能かを実機検証した結果を紹介します。
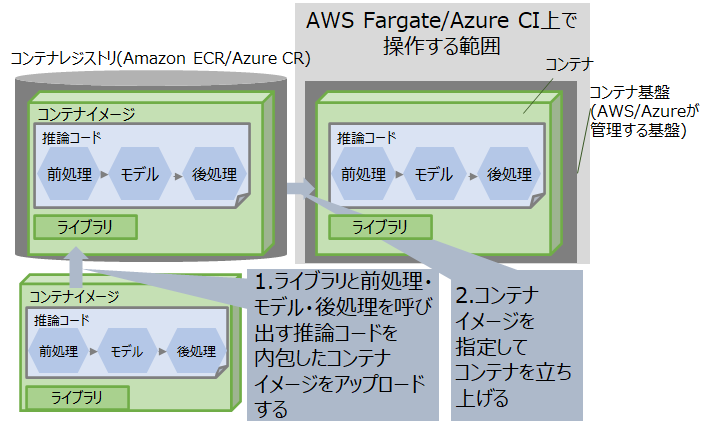
図1: パブリッククラウドにおいてパターン3を実現する場合の手順
表2: AWSとAzureでパターン3を実現する場合に利用する技術の比較
| 項番 | 手順 | AWSで手順を実現する技術 | Microsoft Azureで手順を実現する技術 |
|---|---|---|---|
| 1 | ライブラリと前処理・モデル・後処理を呼び出す推論コードを内包したコンテナイメージをアップロードする | ライブラリをインストールし前処理・モデル・後処理を呼び出す推論コードを内包したコンテナイメージをオンプレミス環境で作成し、Amazon ECR(Elastic Container Registry)へプッシュする | ライブラリをインストールし前処理・モデル・後処理を呼び出す推論コードを内包したコンテナイメージをオンプレミス環境で作成し、Azure Container Registryへプッシュする |
| 2 | コンテナイメージを指定してコンテナを立ち上げる | AWSのマネジメントコンソールまたはAWS CLIでコンテナイメージを指定し、AWS Fargateを実行する | AzureのポータルまたはAzure CLIでコンテナイメージを指定し、Azure Container Instancesを実行する |
AWS Fargateでサービングする場合
以前の投稿で作成した前処理・モデル・後処理のスクリプトapi_server.pyを格納した推論用コンテナイメージを作成し、Amazon ECRへアップロードします。
まず、下記コマンドを実行して、Amazon ECRへアップロードする前処理・モデル・後処理を格納した推論用コンテナイメージを作成します。
# 1. 必要なライブラリをインストールして、前処理・後処理・モデルを内包したコンテナを起動。
# 仮想環境(下の例はawsという名前)を作成した場合は、./bashrc && conda activate awsすることで、仮想環境下でpythonの各モジュールを利用可能。
$ docker run -d -it -p 5000:5000 --network=host --name awsserving-02 awsserving:0.1 bash -c "source ~/.bashrc && conda activate aws; cd /root/serving; python api_server.py"
# 2. 作成したコンテナをイメージ化。下の例ではossset:0.2というコンテナイメージが作成される。
$ docker commit awsserving-02 ossset:0.2
次に、コンテナを作成した環境にAWSのCommand Line Interface (CLI)をインストールして、AWSのCLIを利用してAmazon ECRにコンテナイメージをpushします。AWSのCLIは、zipファイルを入手し、解凍したzipファイルのinstallスクリプトを起動することでインストールできます。AWSのCLIをインストールした後は、AWSのECR環境へログインするための情報を入力します。AWSのECR環境でコンテナレポジトリを作成し、Access keyとSecret Access Keyを用意して、AWSのECR環境へログインしてください。ログインコマンド、タグコマンド、pushコマンドは、ECR環境で自分のコンテナレポジトリを作成すると、図1の「プッシュコマンドの表示」から得ることができます。
# 1. AWSのCLIのzipを解凍する
$ unzip awscliv2.zip
# 2. AWSのCLIをインストールする
$ cd aws; ./install
# 3. aws configureして、自分のaccess keyとsecret access key, region, output(json/text)を入力する。profile名defaultとして登録される。
# 4. Amazon ECR環境へログインする。
$ aws ecr get-login-password --profile default | docker login --username AWS --password-stdin xxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com
(注意点2)regionではなくprofileをオプションとして指定すること
# 5. 作成したコンテナイメージをAmazon ECRへアップロードするためにタグ付けする。
$ docker tag ossset:0.2 xxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/ossset:latest
# 6. タグ付けしたコンテナイメージをAmazon ECRへpushする。
$ docker push xxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/ossset:0.2
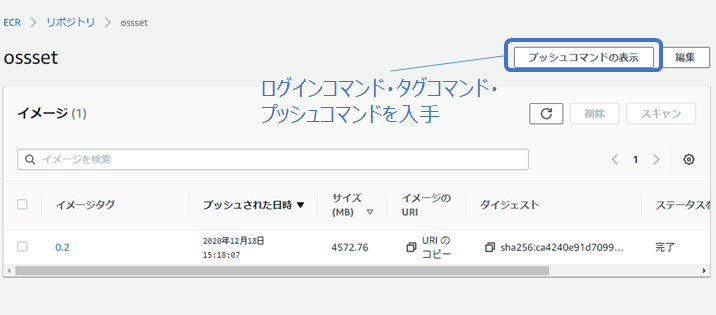
図1: Amazon ECRにおけるプッシュコマンドの入手先
最後に、AWS Fargateを用いてAmazon ECRにプッシュしたコンテナイメージをデプロイします。本投稿ではAWSのマネジメントコンソールを利用する方法を紹介します。
AWSのマネジメントコンソールで「タスク定義」を作成し、コンテナイメージをデプロイするコンテナ基盤(AWS Fargateでは「クラスター」と呼びます)を作成して、クラスター上でタスクを実行することで、コンテナイメージをデプロイできます。
まず、Amazon ECS(Elastic Container Service)の「タスク定義」で「ステップ 1: 起動タイプの互換性の選択」から「Fargate」を選択して、「ステップ 2: タスクとコンテナの定義の設定」の「コンテナの定義」の欄から「コンテナの定義」をクリックして、ECRへプッシュしたコンテナイメージを呼び出します。Flaskではデフォルトで5000番ポートを利用するため、図2の「コンテナの定義」の画面のポートマッピングで5000番を入力します。
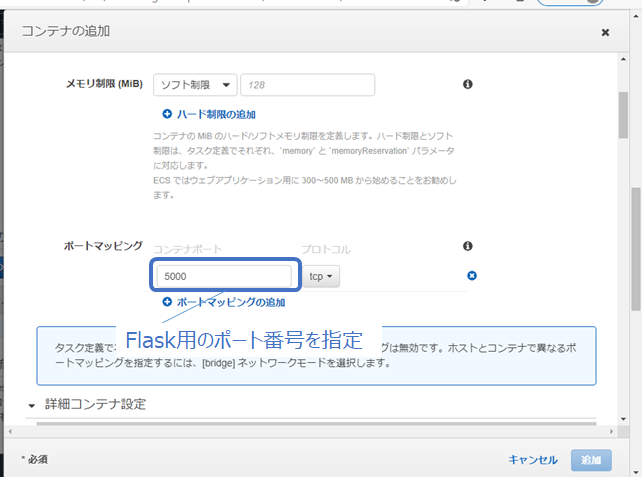
図2:「コンテナの追加」画面
次に、クラスターを作成します。Amazon ECSの「クラスター」から「クラスターの作成」を選択し、「ステップ 1: クラスターテンプレートの選択」から「ネットワーキングのみ」を選択し、「ステップ2: クラスターの設定」でクラスターに名前をつけて、クラスターを作成します。
最後に、クラスター上でタスクを実行します。Amazon ECSの「クラスター」から、先程作成したクラスターを選択して、「タスク」タブから「新しいタスクの実行」を選択します。図3の様に「起動タイプ」で「Fargate」を選択し、「タスク定義」で先程作成したタスク定義を呼び出して、「プラットフォームのバージョン」で「1.4.0」を選択します。ここで、サイズが10GB以上あるコンテナは、Fargateのプラットフォームが1.4.0以上でないとデプロイできず、デフォルトの「LATEST」を選択しても1.3.0になってしまうので明示的に設定する必要があることに注意してください。入力し終わったら、「タスクの実行」をクリックして、コンテナイメージのデプロイが成功すればサービング完了です。
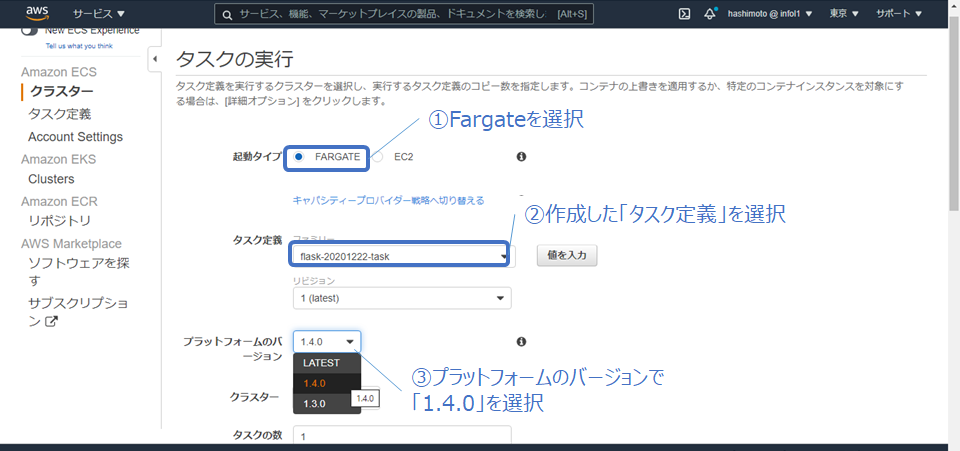
図3: コンテナのデプロイ用画面
推論が成功することを、デプロイしたコンテナへアクセス可能なネットワーク上の他の仮想マシンやコンテナから、以前の投稿の最後に示した動作確認用のコマンドを実行して確認してください。
$ curl -F file=@x_test_30.jpeg localhost:5000/predict
{
"Content-Type": "application/json",
"number": "3"
}
$ curl -F file=@x_test_60.jpeg localhost:5000/predict
{
"Content-Type": "application/json",
"number": "6"
}
以上の検証結果から、AWS Fargateを利用して「オンプレミス環境でライブラリ・前処理・モデル・後処理を含んだコンテナイメージを作成し、コンテナ基盤へデプロイする」ことが可能であることを確認できました。
Azure Container Instancesでサービングする場合
以前の投稿で作成した前処理・モデル・後処理のスクリプトapi_server.pyを格納した推論用コンテナイメージを作成し、Azure Container Registry(ACR)へアップロードします。ACRへアップロードする前処理・モデル・後処理を格納した推論用コンテナイメージは、AWS Fargateの場合で示したコマンド例と同様にして作成できます。
次に、コンテナを作成した環境にAzureのCLIをインストールし、AzureのCLIを利用してACRにコンテナイメージをpushします。AzureのCLIは、rpmファイルを入手し、installコマンドを起動することでインストールできます1。AzureのCLIをインストールして、ACRをAzureのポータルから作成した後は、Azure環境およびACRへログインするための情報を入力します。
# 1. Azure環境へログインする。出力されるURLへアクセスしてコードを入力すると、Azure環境へのログインが完了する。
$ az login
To sign in, use a web browser to open the page https://microsoft.com/devicelogin and enter the code XXXXX to authenticate.
# 2.ACRへログインする。次の例はレジストリ名を「osscenter」とした場合の例
$ az acr login --name osscenter
# Login Succeededと出力されることを確認する。
# 3. 作成したコンテナイメージをACRへアップロードするためにタグ付けする。
$ docker tag ossset:0.2 osscenter.azurecr.io/ossset:0.2
# 4. タグ付けしたコンテナイメージをACRへpushする。
$ docker push osscenter.azurecr.io/ossset:0.2
コンテナイメージをACRへプッシュした後は、Azure Container Instancesを用いてコンテナをデプロイします。デプロイするためには、Azureのポータルからデプロイする方法と、Azure CLIを利用する2つの方法があります。前者の方法は、ACRの管理者アカウントを利用するため、複数人でコンテナイメージを共有する場合には適切ではありません。そこで、ここでは後者の方法を紹介します。
後者の方法では、Azure CLIからACRを操作するために、ACRのサービスプリンシパルを作成し、作成したレジストリに割り当てます。サービスプリンシパルとは、Azure CLIやAzure Container InstancesのようなプログラムからAzureのリソースへアクセスするためのIDを指します。下記スクリプトに必要な情報(作成したレジストリ名など)を入力して実行することで、作成したレジストリにサービスプリンシパルを割り当てます。割り当てが成功すると、サービスプリンシパルIDとサービスプリンシパルパスワードが出力されます。
# !/bin/bash
# Modify for your environment.
# ACR_NAME: The name of your Azure Container Registry
# SERVICE_PRINCIPAL_NAME: Must be unique within your AD tenant
ACR_NAME=<container-registry-name>
SERVICE_PRINCIPAL_NAME=acr-service-principal
# Obtain the full registry ID for subsequent command args
ACR_REGISTRY_ID=$(az acr show --name $ACR_NAME --query id --output tsv)
# Create the service principal with rights scoped to the registry.
# Default permissions are for docker pull access. Modify the '--role'
# argument value as desired:
# acrpull: pull only
# acrpush: push and pull
# owner: push, pull, and assign roles
SP_PASSWD=$(az ad sp create-for-rbac --name http://$SERVICE_PRINCIPAL_NAME --scopes $ACR_REGISTRY_ID --role acrpull --query password --output tsv)
SP_APP_ID=$(az ad sp show --id http://$SERVICE_PRINCIPAL_NAME --query appId --output tsv)
# Output the service principal's credentials; use these in your services and
# applications to authenticate to the container registry.
echo "Service principal ID: $SP_APP_ID"
echo "Service principal password: $SP_PASSWD"
次に、作成したサービスプリンシパルのIDやパスワードをAzureに安全に保管するための、Azure キーコンテナを作成します。下記コマンドで作成できます。
# (下記はリソースグループの名称をosscenter-rg、キーコンテナの名称を
# osscenter-vaultとした場合です)
$ az keyvault create --resource-group osscenter-rg --name osscenter-vault
Azureキーコンテナを作成した後は、サービスプリンシパルIDとサービスプリンシパルパスワードをAzureキーコンテナに格納します。
# 1. サービスプリンシパルパスワードをAzureキーコンテナへ格納する。
$ az keyvault secret set \
> --vault-name osscenter-vault \
> --name osscenter-pull-pwd \
> --value $(az ad sp create-for-rbac \
> --name http://acr-service-principal \
> --scopes $(az acr show --name osscenter --query id --output tsv) \
> --role acrpull \
> --query password \
> --output tsv)
# 2. サービスプリンシパルIDをAzureキーコンテナへ格納する。
$ az keyvault secret set \
> --vault-name osscenter-vault \
> --name osscenter-pull-usr \
> --value $(az ad sp show --id http://acr-service-principal --query appId --output tsv)
# 1. サービスプリンシパルパスワードをAzureキーコンテナへ格納する。
$ az keyvault secret set \
> --vault-name osscenter-vault \
> --name osscenter-pull-pwd \
> --value $(az ad sp create-for-rbac \
> --name http://acr-service-principal \
> --scopes $(az acr show --name osscenter --query id --output tsv) \
> --role acrpull \
> --query password \
> --output tsv)
# 2. サービスプリンシパルIDをAzureキーコンテナへ格納する。
$ az keyvault secret set \
> --vault-name osscenter-vault \
> --name osscenter-pull-usr \
> --value $(az ad sp show --id http://acr-service-principal --query appId --output tsv)
最後に、Azureキーコンテナを利用して入力した認証情報を利用して、Azure CLIからコンテナをデプロイします。
# 下記はACIでデプロイするコンテナ名をflaskとして、公開するDNSの名称を
# flask-osssetとした場合のコマンド例です。
$ az container create
> --resource-group osscenter-rg \
> --name flask –image osscenter.azurecr.io/ossset:0.2
> --cpu 1 --memory 1 --registry-login-server osscenter.azurecr.io \
> --registry-username $(az ad sp show --id http:// acr-service-principal --query appId --output tsv) \
> --registry-password $SERVICE_PRINCIPAL_PASSWORD --dns-name-label flask-ossset --ports 5000
# “Finished”と出力されることを確認する。
これでサービング完了です。以前の投稿に示した動作確認用のコマンドを下記の様に実行して、推論結果が返ってくることが確認できれば動作検証完了です。
$ curl -F file=@x_test_30.jpeg http://flask-ossset.japaneast.azurecontainer.io:5000/predict
{
"Content-Type": "application/json",
"number": "3"
}
$ curl -F file=@x_test_60.jpeg http://flask-ossset.japaneast.azurecontainer.io:5000/predict
{
"Content-Type": "application/json",
"number": "6"
}
以上の検証結果から、Azure Container Instancesを利用して「オンプレミス環境でライブラリ・前処理・モデル・後処理を含んだコンテナイメージを作成し、コンテナ基盤へデプロイする」ことが可能であることを確認できました。
検証結果の考察
今回の検証を通して、オンプレミス環境でライブラリ・前処理・モデル・後処理を含んだコンテナイメージを作成し、コンテナ基盤へデプロイすることは、AWS FargateとAzure Container Instancesの両方であることがわかりました。
パターン3で、ライブラリやモデル・推論コードをすべて含むコンテナイメージをオンプレミス環境で作成すると、コンテナイメージのサイズが大きくなりがちです。特にAWSを利用する場合、Fargateのバージョンが1.3.0以下の場合は、コンテナイメージ用の一時ストレージに10GBの容量制限があります。したがって、10GBよりサイズの大きいコンテナをデプロイする場合は、Fargateのバージョンを1.4.0に指定することに注意が必要です。
なお、今回は紹介しませんでしたが、AWSを利用する方法には、ユーザが管理できるコンテナ基盤を作成し、その上にコンテナをデプロイする方法もあります(AWS Elastic Container Service)。コンテナに割り当てるコンピュータリソース(CPU・メモリ量など)をFargateよりも細かく指定できるため、性能要件が厳しい場合に有効です。
おわりに
本投稿では、学習済みの機械学習モデルを自作コンテナイメージを用いてサービングする技術について、AWSとMicrosoft Azureで実際にサービングして比較した結果を解説しました。