初版: 2021年6月9日
著者: 橋本恭佑、柿田将幸, 株式会社 日立製作所
はじめに
本投稿では、学習済みの機械学習モデルをパブリッククラウド上でサービングする技術について、Amazon SageMakerおよびAzure Machine Learning (Azure ML)上で実際に試した手順を踏まえて比較した結果を解説します。
前回の投稿では、AWS/Azureが提供するコンテナイメージを利用してサービングしました。
今回の検証では、オンプレミス環境で必要なライブラリを含んだコンテナイメージを作成し、デプロイするときに、前処理・モデル・後処理を追加します(表1の赤枠の部分)。
表1: オンプレミス環境で学習させた機械学習モデルをAWSおよびMicrosoft Azure上でサービングする際のサービス一覧(2021年2月現在)

投稿一覧
- AWSとMicrosoft Azureにおける機械学習モデルのサービング技術の概要
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: AWS/Azureが提供するコンテナイメージを利用する場合
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較: 自作コンテナイメージを利用する場合・・・本投稿
- AWS FargateとAzure Container Instancesにおける機械学習モデルのサービング技術比較
本検証の事前準備
本投稿では、以前の投稿の検証シナリオ(第1回の「検証シナリオ」節へのリンクを掲載予定)で作成した下記ファイルを利用しますので、事前に用意してください。
- 学習済みの手書き文字認識モデル:
model.joblib - 前処理・モデル利用・後処理を記載したスクリプト:
api_server.py
AWSとAzureにおけるパターン2の実現技術の違い
パターン2を実現する場合の手順を図1に、パターン2を実現する場合に利用する技術をAWSとAzureで比較した結果を表2に示します。
Amazon SageMakerとAzure MLの双方で、機械学習モデルのサービングに必要なサービスが提供されており、モデルのアップロード先が双方のパブリッククラウドで異なる以外に大きな差分は見られません。本稿ではこの手順に沿ってパターン2が実現可能かを実機検証した結果を紹介します。
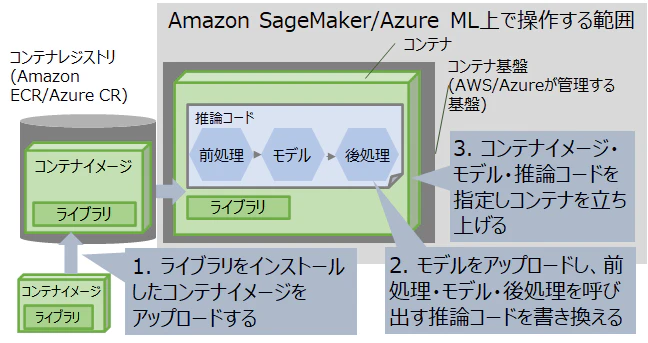
図1: パブリッククラウドにおいてパターン2を実現する場合の手順
表2: AWSとAzureでパターン2を実現する場合に利用する技術の比較
| 項番 | 手順 | AWSで手順を実現する技術 | Microsoft Azureで手順を実現する技術 |
|---|---|---|---|
| 1 | ライブラリをインストールしたコンテナイメージをアップロードする | ライブラリをインストールしたコンテナイメージをオンプレミス環境で作成し、Amazon ECR(Elastic Container Registry)へpushする | ライブラリをインストールしたコンテナイメージをオンプレミス環境で作成し、Azure Container Registryへpushする |
| 2 | モデルをアップロードし、前処理・モデル・後処理を呼び出す推論コードを書き換える | Amazon S3にモデルをアップロードし、Amazon SageMakerのノートブックインスタンス上で推論コードを書き換える | Azure MLのノートブックインスタンス上にモデルをアップロードし、推論コードを書き換える |
| 3 | コンテナイメージ・モデル・推論コードを指定しコンテナを立ち上げる | Amazon SageMakerのノートブックインスタンス上でコンテナイメージ・モデル・推論コードを指定する | Azure MLのノートブックインスタンス上でコンテナイメージ・モデル・推論コードを指定する |
Amazon SageMakerでサービングする場合
学習済みの手書き文字認識モデルを、Amazon SageMaker上で自作のコンテナイメージを用いてサービングできるか検証しました。
Amazon SageMaker向けにAWSが提供するscikit-learnのコンテナイメージのDockerfileをGithubからクローンして、コンテナに含めるパッケージ一覧(requirements.txt)を下記の様に変更して必要なライブラリを追加します。
boto3==1.16.4
botocore==1.19.4
Flask==1.1.1
gunicorn==20.0.4
model-archiver==1.0.3
multi-model-server==1.1.1
numpy==1.19.2
pandas==1.1.3
psutil==5.7.2
python-dateutil==2.8.1
sagemaker-inference==1.2.0
retrying==1.3.3
sagemaker-containers==2.8.6.post2
sagemaker-inference==1.2.0
sagemaker-training==3.6.2
scikit-learn==0.22.1
scipy==1.4.1
six==1.15.0
pillow==7.0.0 # 行を追加
joblib==1.0.0 # 行を追加
次に、Githubからクローンしたディレクトリで下記を実行して、AWSが提供するscikit-learnのコンテナイメージに、必要なライブラリを追加した新しいコンテナイメージ(preprod-sklearn:0.22-1-cpu-py3)を作成します。
# ベースになるコンテナイメージをビルド
$ docker build -t sklearn-base:0.22-1-cpu-py3 -f docker/0.22-1/base/Dockerfile.cpu .
Sending build context to Docker daemon 3.872MB
Step 1/15 : ARG UBUNTU_VERSION=18.04
…
# requirements.txtを含む最終的なコンテナイメージのビルド(preprod-sklearn:0.22-1-cpu-py3の名前のコンテナイメージができる)
$ docker build -t preprod-sklearn:0.22-1-cpu-py3 -f docker/0.22-1/final/Dockerfile.cpu .
Step 1/27 : FROM sklearn-base:0.22-1-cpu-py3
…
最後に、作成した新しいコンテナイメージをAmazon ECR(Elastic Container Registry)へpushします。
# ECRにアクセスするために認証を実施する。aws_account_id は AWSのアカウントID(数値)
$aws ecr get-login-password --profile default | docker login --username AWS --password-stdin aws_account_id.dkr.ecr.ap-northeast-1.amazonaws.com
# コンテナイメージをpush
$docker push aws_account_id.dkr.ecr.ap-northeast-1.amazonaws.com/preprod-sklearn:0.22-1-cpu-py3
The push refers to repository [aws_account_id.dkr.ecr.ap-northeast-1.amazonaws.com/preprod-sklearn]
b435a550234f: Pushed
…
0.22-1-cpu-py3: digest: sha256:79d36acf270fb1adfa9f9327ce35e962e1985bc7360f0328b7a188b6016b5b8f size: 4500
最後に、Amazon ECRへpushしたコンテナイメージを、ノートブックインスタンス上のJupyter Notebookから下記のコマンドを呼び出してデプロイします。前処理・後処理・推論用のコードは以前の投稿で示したentry.pyと同一のものを利用できます。
from sagemaker.sklearn.model import SKLearnModel
image_uri = 'aws_account_id.dkr.ecr.ap-northeast-1.amazonaws.com/preprod-sklearn:0.22-1-cpu-py3'
model = SKLearnModel(model_data=uploaded_model, role=role, framework_version='0.22-1', entry_point='entry.py', image_uri=image_uri)
predictor = sklearn_model.deploy(instance_type="ml.c4.xlarge", initial_instance_count=1)
# 推論時に必要なエンドポイント名を確認する
print(predictor.endpoint_name)
# preprod-sklearn-2021-02-02-10-17-34-988などと出力があればサービングが完了している
これでサービング完了です。あらためて推論が成功するかを、ノートブックインスタンス上のJupyter Notebookから下記のコマンドを用いて確認します。
import boto3
import json
import numpy as np
## 読み込んだ画像データを、モデル側が受け取れる形式に変換
npy = BytesIO()
L = img.flatten().shape[0]
np.save(npy, img.reshape(1, L))
ByteArr = npy.getvalue()
# コンテナ作成時に確認したエンドポイント名を入力
endpoint = “endpoint_name”
runtime= boto3.client('sagemaker-runtime')
response = runtime.invoke_endpoint(
EndpointName=endpoint,
ContentType='application/x-npy',
Accept = 'application/json',
Body=ByteArr
)
prediced_value = json.load(response['Body'])
print("Predicted value for {} is {}".format(filename, prediced_value))
# Predicted value for x_test_50.jpeg is 6と返答が返ってくることを確認する
これで動作検証も完了し、サービングが成功したことを確認できました。以上の検証結果から、Amazon SageMakerでは「パブリッククラウドが提供するコンテナイメージを利用せず、オンプレミス環境で必要なライブラリを含んだコンテナイメージを作成して、デプロイした後に、前処理・モデル・後処理を追加する」ことが可能であることを確認できました。
Azure MLでサービングする場合
学習済みの手書き文字認識モデルを、Azure ML上で自作のコンテナイメージを用いてサービングできるか検証しました。
ライブラリを下記のDockerfileの例に沿って追記します1。
FROM ubuntu:16.04
ARG CONDA_VERSION=4.7.12
ARG PYTHON_VERSION=3.7
ARG AZUREML_SDK_VERSION=1.13.0
ARG INFERENCE_SCHEMA_VERSION=1.1.0
ENV LANG=C.UTF-8 LC_ALL=C.UTF-8
ENV PATH /opt/miniconda/bin:$PATH
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update --fix-missing && \
apt-get install -y wget bzip2 && \
apt-get install -y fuse && \
apt-get clean -y && \
rm -rf /var/lib/apt/lists/*
RUN useradd --create-home dockeruser
WORKDIR /home/dockeruser
USER dockeruser
RUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda3-${CONDA_VERSION}-Linux-x86_64.sh -O ~/miniconda.sh && \
/bin/bash ~/miniconda.sh -b -p ~/miniconda && \
rm ~/miniconda.sh && \
~/miniconda/bin/conda clean -tipsy
ENV PATH="/home/dockeruser/miniconda/bin/:${PATH}"
RUN conda install -y conda=${CONDA_VERSION} python=${PYTHON_VERSION} numpy==1.19.2 scikit-learn==0.23.2 pillow==7.0.0 joblib==1.0.0 && \ # モデル・推論に必要なライブラリを追記
pip install azureml-defaults==${AZUREML_SDK_VERSION} inference-schema==${INFERENCE_SCHEMA_VERSION} &&\
conda clean -aqy && \
rm -rf ~/miniconda/pkgs && \
find ~/miniconda/ -type d -name __pycache__ -prune -exec rm -rf {} \;
次に、上記のDockerfileをビルドして必要なライブラリを追加した新しいコンテナイメージ(ossset:v2)を作成して、Azure Container Registry(osssetmlregistry)をpushします。Pushする前にAzureのCLIのインストールとAzure Container Registryの作成を事前に行うことに注意してください。
# Azure CLIからAzure環境へログイン
$ az login
# 認証するためのwebリンクとパスワードが表示されるので、webリンクにアクセスしてパスワードを入力する
# Azure Container Registryへログインする
$ az acr login --name osssetmlregistry
# Dockerfileをビルドし、Azure Container Registryへpush
$ sudo az acr build --image ossset:v2 --registry osssetmlregistry --file Dockerfile .
Step 1/15 : ARG UBUNTU_VERSION=18.04
…
最後に、Azure Container Registryへpushしたコンテナイメージを、ノートブックインスタンス上のJupyter Notebookから下記のコマンドを呼び出してデプロイします。前処理・後処理・推論用のコードは以前の投稿に示したscore.pyと同一の下記コードを利用可能です。推論用のコンテナとして動作させるためのオプション(inferencing_stack_version)が別途必要であることと、自作のコンテナイメージを作成する際にインストールしたanacondaを優先して利用するためにAzure Machine Learningのanacondaの設定を無効にする必要があることに注意してください。
from azureml.core.environment import Environment
from azureml.core.model import InferenceConfig
from azureml.core.webservice import AciWebservice, Webservice
# 環境を定義
ossc_byoc = Environment(name="ossset-v2")
# デプロイしたコンテナイメージの場所を指定
ossc_byoc.docker.enabled = True
ossc_byoc.docker.base_image = "hashmlregistry.azurecr.io/ossset:v2"
# 推論用のコンテナとして動作させるために必要なオプションを追加
ossc_byoc.inferencing_stack_version='latest'
# コンテナイメージ作成時にインストールしたanacondaを優先して利用するために、Azure Machine Learningのcondaを無効にする
ossc_byoc.python.user_managed_dependencies = True
inference_config = InferenceConfig(entry_script="score.py", environment=ossc_byoc)
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
model = Model(ws, name='hash-mnist-v2')
service = Model.deploy(ws, 'hash-mnist-second', [model], inference_config, deployment_config)
service.wait_for_deployment(True)
print(service.state)
print("scoring URI: " + service.scoring_uri)
# 下記の様にコマンドが返ってくることを確認する
# Running............................................................................
# Succeeded
# ACI service creation operation finished, operation "Succeeded"
# Healthy
# scoring URI: http://7032b584-13d9-4bcb-a096-9fe0d9dc4941.japaneast.azurecontainer.io/score
これでサービング完了です。推論が成功することを、上記のscoring URIおよび以前の投稿に示した下記のコード例を利用して確認できます。
$ curl -F file=@x_test_30.jpeg http://7032b584-13d9-4bcb-a096-9fe0d9dc4941.japaneast.azurecontainer.io:5000/predict
{
"Content-Type": "application/json",
"number": "3"
}
$ curl -F file=@x_test_60.jpeg 7032b584-13d9-4bcb-a096-9fe0d9dc4941.japaneast.azurecontainer.io:5000/predict
{
"Content-Type": "application/json",
"number": "6"
}
以上の検証結果から、Azure Machine Learningでは「パブリッククラウドが提供するコンテナイメージを利用せず、オンプレミス環境で必要なライブラリを含んだコンテナイメージを作成して、デプロイした後に、前処理・モデル・後処理を追加する」ことが可能であることを確認できました。
検証結果の考察
今回の検証を通して、「パブリッククラウドが提供するコンテナイメージを利用せず、オンプレミス環境で必要なライブラリを含んだコンテナイメージを作成して、デプロイした後に、前処理・モデル・後処理を追加する」ことは、Amazon SageMakerとAzure MLの両方で可能であることがわかりました。
この手法は、ライブラリの更新と、モデルや前処理・後処理の更新で明確に役割を分けることができることが利点です。Amazon SageMakerとAzure MLの比較の観点では、ライブラリの更新について、ライブラリの種類やバージョンを別ファイルで明確に分けるAmazon SageMakerの方が、バージョンの間違いなどのミスが起こりづらいと考えられます。
また、入力データ・出力データの型についても、Amazon SageMakerはユーザが定義できる点から、より柔軟に対応できるといえます。
おわりに
次回の投稿において、オンプレミス環境でライブラリ・前処理・モデル・後処理を含んだコンテナイメージを作成しデプロイするパターンについて、AWS FargateとAzure Container Instanceで実証し両者の違いを比較した結果を解説します。
-
Anacondaレポジトリに接続してMinicondaをダウンロードするため、大規模な商用利用などに用いる際は有償ライセンスが必要な方法です(参考URL: https://www.anaconda.com/terms-of-service)。 ↩