初版: 2020年11月18日
著者: 橋本恭佑、柿田将幸, 株式会社 日立製作所
はじめに
機械学習技術のビジネスへの活用ニーズが高まり、機械学習モデルの開発や運用のライフサイクルを支援するフレームワークに注目が集まっています。
パブリッククラウドでは上述のフレームワークを公開しており、フレームワーク利用者は機械学習モデルを迅速に作成し自身のシステムに組み込んで公開することができます。
機械学習モデルをシステムに組み込み、サービスとして公開する一連の技術はサービング技術と呼ばれており、
システム構築と運用を担うSEにとって重要な技術です。
本連載ではAI案件に対応するSEを対象として、Amazon SageMakerとAzure MLを例に、パブリッククラウドが提供するフレームワークとサービング技術を概観し、2つのクラウドベンダにどのような違いや特徴があるかを説明します。
なお、本連載に記載のAmazon SageMakerまたはAzure MLの情報は2020年9月末日現在のものであり、今後のアップデート等によって内容が変わることがあります。
投稿一覧
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較(前編)・・・本投稿
- Amazon SageMakerとAzure MLにおける機械学習モデルのサービング技術比較(後編)
機械学習システムのライフサイクルとサービング技術
機械学習案件ではデータサイエンティストとSEが連携して運用サイクルを回します。
パブリッククラウドベンダの機械学習サービスでは、図1のように機械学習の継続的な運用サイクルを実現する一連の機能群を提供しています。
本連載ではAmazon SageMakerとAzure MLの推論システム構築機能の違いを解説します。
図1: 機械学習の継続的な運用サイクル
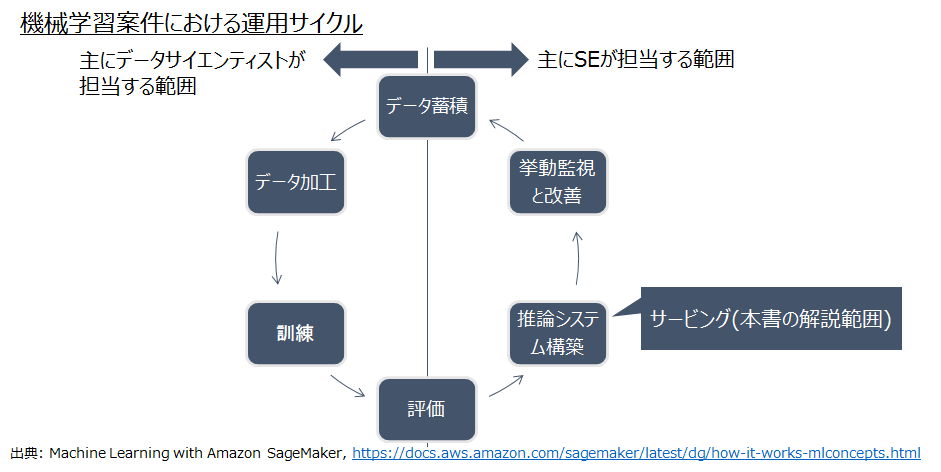
出典: Machine Learning with Amazon SageMaker(https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html)
パブリッククラウドで実現する推論システムの種別
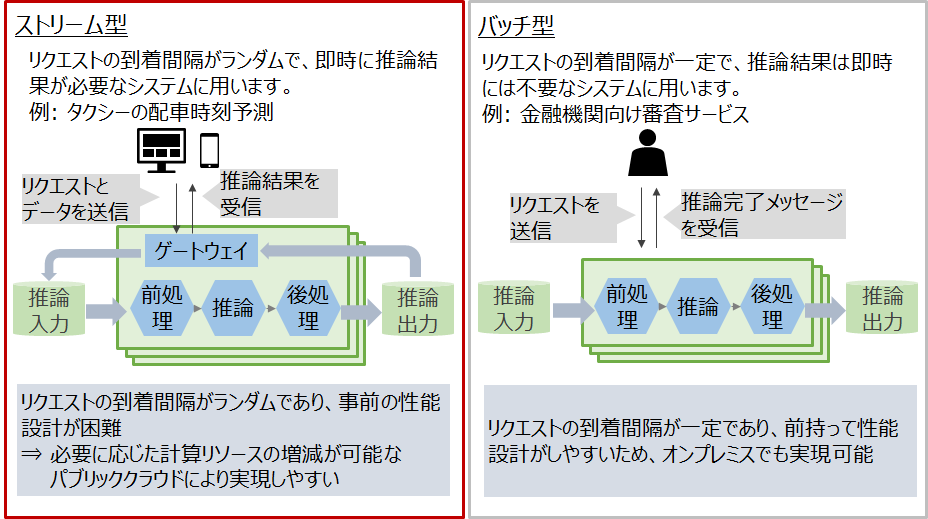
推論システムは利用用途により図2のようにストリーム型とバッチ型の2種類に大別されます。
特にストリーム型はリクエストの到着間隔がランダムであり、バッチ型と比較して
事前の性能設計が困難であるため、必要に応じた計算リソースの増減が可能なパブリッククラウドにより実現しやすいといえます。
そこで本連載では、ストリーム型について紹介します。
図2: 推論システムの種別
ストリーム型推論システムの概要と構築の勘所
パブリッククラウドにおけるサービングでは、ゲートウェイ、前処理、モデル、後処理、およびそれらの実行に必要なライブラリ群を、まとめて「ランタイム」としてデプロイします。
以後では特に初学者向けに、パブリッククラウド上でモデルを学習させてランタイムを作成する場合の構築の勘所を、アプリ層と基盤層に分けて説明します。
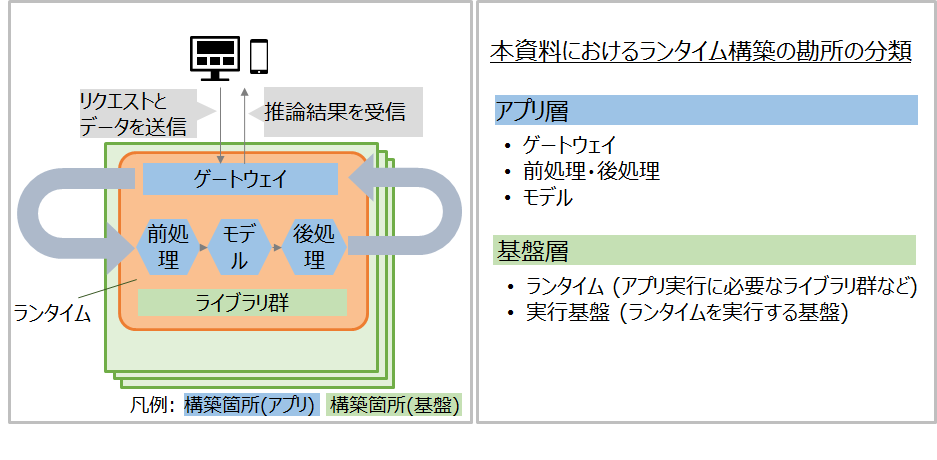
ストリーム型推論システム構築に向けたパブリッククラウドサービスの機能比較: アプリ層
表1から、Amazon SageMakerとAzure MLの両者で、前処理や後処理の実装方法が大きく異なることがわかります。
モデル作成時は、各サービスであらかじめ用意されたバージョンのOSSを利用します。
表1: パブリッククラウドサービスの機能比較: アプリ層
| カテゴリ | 項目 | Amazon SageMaker | Azure ML |
|---|---|---|---|
| ゲートウェイ | 送信データの形式 | MIME Type(テキスト、画像、音声) | MIME Type(テキスト、画像、音声) |
| 受信データの形式 | MIME Type(テキスト、画像、音声) | MIME Type(テキスト、画像、音声) | |
| 通信プロトコル | HTTPのみ | HTTPのみ | |
| 認証 | IAMベースのアカウント認証 | Azureロールベースのアカウント認証 | |
| 前処理・後処理 | 実装方法(後編で実機検証) | 前処理と後処理を異なる関数に分けて実装 | 前処理・後処理も同じ関数内に実装 |
| モデル | 学習や推論に利用するOSS | コンテナイメージに含まれるOSSを利用する | コンテナイメージに含まれるOSSを利用する |
| モデルDB | S3 | Azure DB |
ストリーム型推論システム構築に向けたパブリッククラウドサービスの機能比較: 基盤層(ランタイム)
パブリッククラウドで本番環境を構築する場合は、ランタイムをコンテナで作成します。
デフォルトまたは自作のコンテナイメージを選択して、コンテナ作成時に必要なOSSを導入・更新します。
Azure MLではランタイム作成時にpipやcondaを利用して独自OSSを追加することもできます。
表2: パブリッククラウドサービスの機能比較: 基盤層(ランタイム)
| 項目 | Amazon SageMaker | Azure ML |
|---|---|---|
| ランタイムの種類 | コンテナ | コンテナ |
| デフォルトで提供されるコンテナイメージに含まれるOSSの種類 | TensorFlow, PyTorch, Apache MXNet, Chainer, Keras, Gluon, Horovod, scikit-learn, および Deep Graph Library | TensorFlow, PyTorch, Keras, scikit-learn, ONNX |
| 上述のOSSの保守期限 | 言及なし(サポートページ参照) | 言及なし(サポートページ参照) |
| ランタイム作成時のOSS追加方法(後編で実機検証) | 事前にコンテナイメージを用意する | 事前にコンテナイメージを用意する、またはランタイム作成時にnotebook経由でpipやcondaを利用して任意のOSSを追加する |
| ランタイムに含まれるOSSのアップデート可否 | ×(新規ランタイム作成要) | ×(新規ランタイム作成要) |
ストリーム型推論システム構築に向けたパブリッククラウドサービスの機能比較: 基盤層(実行基盤)
Amazon SageMakerではAWSのマネージド環境にランタイムをデプロイしますが、Azure MLではランタイムの実行環境がコンテナ基盤(AKS)に限定されます。
Azure MLの基盤層はコンテナ基盤(AKS)の制約を受けるため、運用時はAKSの知識が必要といえます。
また、Amazon SageMakerとAzure MLの両方ともに可用性や運用・保守の機能についてはコンテナ基盤の機能に準拠していることがわかります。
表3: パブリッククラウドサービスの機能比較: 基盤層(実行基盤)
| 項目 | Amazon SageMaker | Azure ML |
|---|---|---|
| ランタイム実行環境(後編で実機検証) | マネージド環境が提供される | 別途コンテナ基盤(Azure Kubernetes Service)の用意が必要 |
| コンテナの性能 | コンテナホストに依存 | コンテナホストに依存 |
| コンテナホストの性能 | 2cpu/4GB ~ 96cpu/384GB | 2cpu/4GB ~ 64cpu/256GB |
| コンテナ基盤(kubernetesクラスタ)のサイズ | -(SageMakerの裏は意識しない) | ノード3つ以上、クラスタ全体で12コア以上 |
| 複数ランタイムの並列処理 | 〇 | × |
| 1ランタイム内の並列処理 | 〇 | × |
| GPUの利用 | 〇 | 〇 |
| オートスケール | 〇 | △(AKSで可能) |
| 障害発生時の自動復旧 | 〇(Amazon CloudWatchとの連携で可能) | 〇(AKSによる自動復旧) |
| 費用の上限値設定 | AWS Budgetにてアラート | Azure monitorにてアラート |
| ランタイムのモデル作成時と異なるリージョンへのデプロイ可否 | 〇 | 〇 |
| ディザスタリカバリ | × | × |
おわりに
本投稿では、ストリーム型の機械学習システムをサービングする技術について、
Amazon SageMakerとAzure Machine Learningを比較した結果を紹介しました。
後編では、実際にストリーム型の機械学習システムを両クラウドでサービングして、本投稿で紹介した違いが現れること、
また、SEがどのような基準でAmazon SageMakerまたはAzure MLの利用を検討するべきかについて議論します。