本記事の概要
scikit-learnのワインデータセットを分析しましょう。
本記事では教師なし学習の機械学習手法でクラスタリング(clustering)に利用されるk-meansを実践的に学びます。
「機械学習を触ってみたいけど、データもないからどこから手を付けていいか分からない。」
そんな方にも機械学習の入門としておすすめです。
目次
1. k-meansの概要
2. データセットの確認
3. K-meansによるクラスタリング
4. おわりに
1. k-meansの概要
k-meansクラスタリングは、最も単純で最も広く利用されているクラスタリングアルゴリズムです。このアルゴリズムは与えられたデータセットをk個のクラスタ(似ているデータ同士をグループ化する)に分類する手法です。
<参考になる記事>
・k-means
2. データセットの確認
まずは、今回分析の対象とするワインデータセットを確認してみましょう。scikit-learnのsklearn.datasets.load_wineを利用します。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import datasets
wine = datasets.load_wine()
# データの概要の表示
print(wine.DESCR)
Data Set Characteristics: # 理解のため特徴量は日本語訳しています。
:Number of Instances: 178 (50 in each of three classes)
:Number of Attributes: 13 numeric, predictive attributes and the class
:Attribute Information:
- Alcohol
- Malic acid
- Ash
- Alcalinity of ash
- Magnesium
- Total phenols
- Flavanoids
- Nonflavanoid phenols
- Proanthocyanins
- Color intensity
- Hue
- OD280/OD315 of diluted wines
- Proline
- class:
- class_0
- class_1
- class_2:Summary Statistics:
============================= ==== ===== ======= =====
Min Max Mean SD
============================= ==== ===== ======= =====
Alcohol: 11.0 14.8 13.0 0.8 #アルコール
Malic Acid: 0.74 5.80 2.34 1.12 #リンゴ酸
Ash: 1.36 3.23 2.36 0.27 #灰
Alcalinity of Ash: 10.6 30.0 19.5 3.3 #アルカリ灰
Magnesium: 70.0 162.0 99.7 14.3 #マグネシウム
Total Phenols: 0.98 3.88 2.29 0.63 #総フェノール
Flavanoids: 0.34 5.08 2.03 1.00 #フラボノイド
Nonflavanoid Phenols: 0.13 0.66 0.36 0.12 #非フラボノイドフェノール
Proanthocyanins: 0.41 3.58 1.59 0.57 #プロアントシアニン
Colour Intensity: 1.3 13.0 5.1 2.3 #色彩強度
Hue: 0.48 1.71 0.96 0.23 #色調
OD280/OD315 of diluted wines: 1.27 4.00 2.61 0.71 #蒸留ワインのOD280/OD315
Proline: 278 1680 746 315 #プロリン
============================= ==== ===== ======= =====:Missing Attribute Values: None
:Class Distribution: class_0 (59), class_1 (71), class_2 (48)
説明変数(wine.data)が13個、データ数が178、ターゲットとしてワインの等級がclass0~3まであることが分かります。このデータをpandasによりデータフレームにしましょう。
# pandasによるデータセットの表示
X = pd.DataFrame(wine.data, columns=wine.feature_names)
y = pd.DataFrame(wine.target, columns=["target"])
df = pd.concat([y, X], axis=1)
df
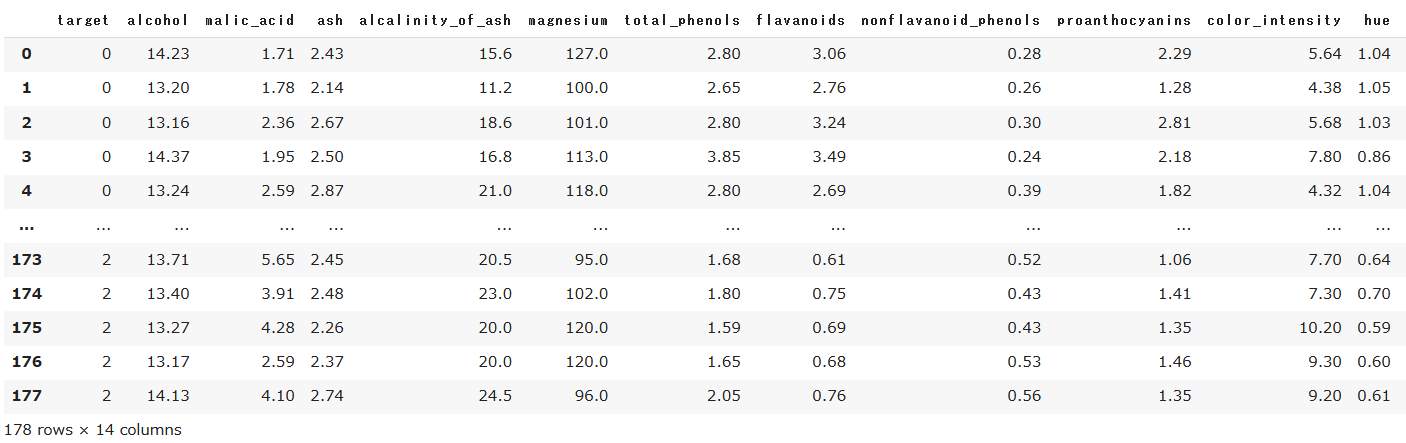
データフレームを見るだけではデータの構造が分からないので、ペアグリッドを作成して全体のデータ構造を眺めてみましょう。
sns.set()
sns.set_style("ticks")
sns.pairplot(df, hue='target', palette='tab10')
class0~3を色分けしてプロットしています。Alcohol(アルコール, 1行目)、Flavanoids(フラボノイド, 7行目)、Proline(プロリン, 13行目)などを確認すると、3classが上手く分類出来そうだということが分かります。

3. K-meansによるクラスタリング
それではk-meansによるクラスタリングに移りましょう。scikit-learnのsklearn.cluster.KMeansを利用します。
from sklearn.cluster import KMeans
model = KMeans(n_clusters=3) # クラスターの個数=3
# クラスタリングを実行し、各サンプルのクラスタ番号を予測
labels = model.fit_predict(X)
# クラスタリングの結果をデータフレーム化
y_pred = pd.DataFrame({'labels': labels})
df_pred = pd.concat([y, y_pred], axis=1)
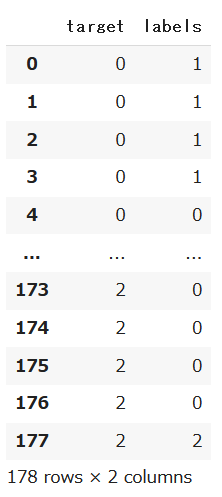
df_pred
実際のクラスをtareget、クラスタリングの予測結果をlabelsに格納したデータフレームが得られました。データフレームからもあまり精度が良くないことが伺えます。
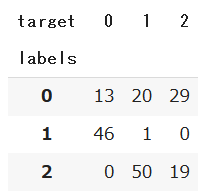
# targetとlabelを比較
pd.crosstab(df_pred['labels'], df_pred['target'])
データフレームからも伺えましたが、実際のターゲットに対してクラスタリングのラベルの番号が違っていそうなので、ラベルの番号を変更してみます。
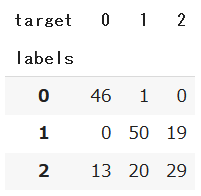
# labelのクラスNoを変更
df_pred['labels'] = df_pred['labels'].replace({0 : 2, 1 : 0, 2 :1}) # 表に対応するように変換
pd.crosstab(df_pred['labels'], df_pred['target'])
k-meansによるクラスタリングにより、おおよその傾向は掴めてそうですが特にclass2のクラスタリングの誤差が大きそうです。
4. おわりに
今回は、ワインデータセットをk-meansによりクラスタリング解析を実施しました。データからクラスタ重心を見つけ、3つの等級でクラスタリングを実施しました。
機械学習入門のリンク
今後も引き続き機械学習の実装入門を記事にしていきます。
参考にどうぞ。
・線形回帰モデル
・非線形回帰モデル
・k-近傍法
・ロジスティック回帰モデル
・主成分分析
・K-means 本記事
・サポートベクターマシン ※今後更新予定