[初心者です]タイタニック号でのobject has no attribute のエラー
タイタニック号で精度80パーセント以上を出す課題が出ています。
データセットはkaggleのものとは違い,欠損値が?になっていたり,'age', 'pclass'と小文字になっていたりと少し違うものになっています。インターネットに掲載されていたものhttps://qiita.com/jun40vn/items/d8a1f71fae680589e05c
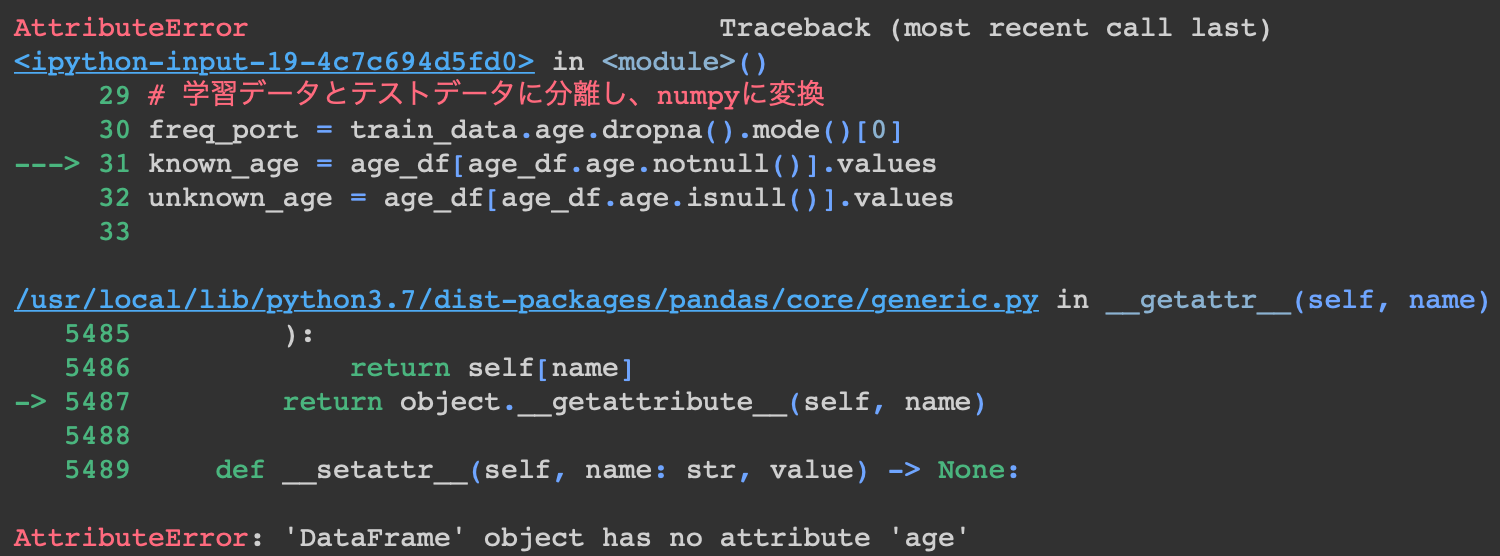
を参考に書いてみたのですが,画像のエラーが出てしまう状態です。原因をご教示していただけますと嬉しいです。(皆さんみたいに綺麗なコードの貼り方がわからず。。。見にくくて申し訳ないです。)
訓練データ:https://drive.google.com/uc?export=download&id=1-12Pg5IsjNAEbgk7G4a2WqFaOhpYmbyJ
テストデータ:https://drive.google.com/uc?export=download&id=1jmzmYNPRWUGLcHeqhcwKTGlb_d2Rzn4Y
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
学習用のデータのダウンロード
!wget 'https://drive.google.com/uc?export=download&id=1-12Pg5IsjNAEbgk7G4a2WqFaOhpYmbyJ' -O titanic_train.csv
提出用のデータをダウンロード
!wget 'https://drive.google.com/uc?export=download&id=1-1KX2NQmwUOXAstOE7c2INC1rRMNABVZ' -O titanic_test_x.csv
train_data = pd.read_csv('titanic_train.csv', index_col=0)
test_data = pd.read_csv('titanic_test_x.csv', index_col=0)
#空いた部分に中央値を入れて埋める
train_data['name'].fillna(freq_port, inplace=True)
test_data['name'].fillna(freq_port, inplace=True)
train_dataとtest_dataの連結
test_data['survived'] = np.nan
df = pd.concat([train_data, test_data], ignore_index=True, sort=False)
dfの情報
df.info()
Sexと生存率の関係
sns.barplot(x='sex', y='survived', data=df, palette='Set3')
plt.show()
------------ Age ------------
Age を Pclass, Sex, Parch, SibSp からランダムフォレストで推定
from sklearn.ensemble import RandomForestRegressor
推定に使用する項目を指定
age_df = df[['age', 'pclass','sex','parch','sibsp']]
ラベル特徴量をワンホットエンコーディング
age_df=pd.get_dummies(age_df)
学習データとテストデータに分離し、numpyに変換
freq_port = train_data.age.dropna().mode()[0]
known_age = age_df[age_df.age.notnull()].values
unknown_age = age_df[age_df.age.isnull()].values
学習データをX, yに分離
X = known_age[:, 1:]
y = known_age[:, 0]
ランダムフォレストで推定モデルを構築
rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1)
rfr.fit(X, y)
推定モデルを使って、テストデータのAgeを予測し、補完
predictedAges = rfr.predict(unknown_age[:, 1::])
df.loc[(df.age.isnull()), 'age'] = predictedAges
年齢別生存曲線と死亡曲線
facet = sns.FacetGrid(df[0:890], hue="survived",aspect=2)
facet.map(sns.kdeplot,'age',shade= True)
facet.set(xlim=(0, df.loc[0:890,'age'].max()))
facet.add_legend()
plt.show()
------------ Name --------------
Nameから敬称(Title)を抽出し、グルーピング
df['title'] = df['name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df['title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True)
df['title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True)
df['title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True)
df['title'].replace(['Mlle'], 'Miss', inplace=True)
df['title'].replace(['Jonkheer'], 'Master', inplace=True)
sns.barplot(x='title', y='survived', data=df, palette='Set3')
------------ Surname ------------
NameからSurname(苗字)を抽出
df['surname'] = df['name'].map(lambda name:name.split(',')[0].strip())
同じSurname(苗字)の出現頻度をカウント(出現回数が2以上なら家族)
df['familyGroup'] = df['surname'].map(df['surname'].value_counts())
家族で16才以下または女性の生存率
Female_Child_Group=df.loc[(df['familygroup']>=2) & ((df['age']<=16) | (df['sex']=='female'))]
Female_Child_Group=Female_Child_Group.groupby('surname')['survived'].mean()
print(Female_Child_Group.value_counts())
家族で16才超えかつ男性の生存率
Male_Adult_Group=df.loc[(df['familygroup']>=2) & (df['age']>16) & (df['sex']=='male')]
Male_Adult_List=Male_Adult_Group.groupby('surname')['survived'].mean()
print(Male_Adult_List.value_counts())
デッドリストとサバイブリストの作成
Dead_list=set(Female_Child_Group[Female_Child_Group.apply(lambda x:x==0)].index)
Survived_list=set(Male_Adult_List[Male_Adult_List.apply(lambda x:x==1)].index)
デッドリストとサバイブリストの表示
print('dead_list = ', Dead_list)
print('survived_list = ', Survived_list)
デッドリストとサバイブリストをSex, Age, Title に反映させる
df.loc[(df['survived'].isnull()) & (df['surname'].apply(lambda x:x in Dead_list)),
['sex','age','title']] = ['male',28.0,'Mr']
df.loc[(df['survived'].isnull()) & (df['Surname'].apply(lambda x:x in Survived_list)),
['sex','age','title']] = ['female',5.0,'Mrs']
----------- Fare -------------
欠損値を Embarked='S', Pclass=3 の平均値で補完
fare=df.loc[(df['embarked'] == 'S') & (df['pclass'] == 3), 'fare'].median()
df['fare']=df['fare'].fillna(fare)
----------- Family -------------
Family = SibSp + Parch + 1 を特徴量とし、グルーピング
df['family']=df['sibSp']+df['parch']+1
df.loc[(df['family']>=2) & (df['family']<=4), 'family_label'] = 2
df.loc[(df['family']>=5) & (df['family']<=7) | (df['family']==1), 'family_label'] = 1 # == に注意
df.loc[(df['family']>=8), 'family_label'] = 0
----------- Ticket ----------------
同一Ticketナンバーの人が何人いるかを特徴量として抽出
Ticket_Count = dict(df['ticket'].value_counts())
df['ticketGroup'] = df['ticket'].map(Ticket_Count)
sns.barplot(x='ticketGroup', y='survived', data=df, palette='Set3')
plt.show()
生存率で3つにグルーピング
df.loc[(df['ticketGroup']>=2) & (df['ticketGroup']<=4), 'Ticket_label'] = 2
df.loc[(df['ticketGroup']>=5) & (df['ticketGroup']<=8) | (df['ticketGroup']==1), 'ticket_label'] = 1
df.loc[(df['ticketGroup']>=11), 'ticket_label'] = 0
sns.barplot(x='ticket_label', y='survived', data=df, palette='Set3')
plt.show()
------------- Cabin ----------------
Cabinの先頭文字を特徴量とする(欠損値は U )
df['cabin'] = df['cabin'].fillna('Unknown')
df['cabin_label']=df['cabin'].str.get(0)
sns.barplot(x='cabin_label', y='survived', data=df, palette='Set3')
plt.show()
---------- Embarked ---------------
欠損値をSで補完
df['embarked'] = df['embarked'].fillna('S')
------------- 前処理 ---------------
推定に使用する項目を指定
df = df[['survived','pclass','sex','age','fare','embarked','title','family_label','cabin_label','ticket_label']]
ラベル特徴量をワンホットエンコーディング
df = pd.get_dummies(df)
データセットを trainとtestに分割
train = df[df['survived'].notnull()]
test = df[df['survived'].isnull()].drop('survived',axis=1)
データフレームをnumpyに変換
X = train.values[:,1:]
y = train.values[:,0]
test_x = test.values
----------- 推定モデル構築 ---------------
from sklearn.feature_selection import SelectKBest
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import cross_validate
採用する特徴量を25個から20個に絞り込む
select = SelectKBest(k = 20)
clf = RandomForestClassifier(random_state = 10,
warm_start = True, # 既にフィットしたモデルに学習を追加
n_estimators = 26,
max_depth = 6,
max_features = 'sqrt')
pipeline = make_pipeline(select, clf)
pipeline.fit(X, y)
フィット結果の表示
cv_result = cross_validate(pipeline, X, y, cv= 10)
print('mean_score = ', np.mean(cv_result['test_score']))
print('mean_std = ', np.std(cv_result['test_score']))
-------- 採用した特徴量 ---------------
採用の可否状況
mask= select.get_support()
項目のリスト
list_col = list(df.columns[1:])
項目別の採用可否の一覧表
for i, j in enumerate(list_col):
print('No'+str(i+1), j,'=', mask[i])
シェイプの確認
X_selected = select.transform(X)
print('X.shape={}, X_selected.shape={}'.format(X.shape, X_selected.shape))
----- Submit dataの作成 -------
name=test_data["name"]
predictions = pipeline.predict(test_x)
submission = pd.DataFrame({"name": name, "name": predictions.astype(np.int32)})
submission.to_csv("my_submission.csv", index=False)