本題
この記事は、AI初心者の自分がResNetについての疑問を解決するために調べた結果です。
4本立て(序、破、Q、:||)
ですので、AIガチ勢の人、ResNetなんてもう深く知ってるよ、って方にはつまらない内容かもしれません。
ただ、自分のように疑問を持ちながらもなんか理解できたらなて思う人にぜひ読んでほしいです。(自分は下記の論文を読んで調査していくにつれてめちゃくちゃ感動しました。)
感想
「やっぱりResNetって素晴らしい」って思うこともあった反面、
おそらくオリジナルの論文 ResNet始祖論文の時点ではあまりわかっていなかったことが多く、
とりあえず実験的に精度が良すぎるから精査する前に急いで論文が出たのかなあと思いました。
その後、いくつかの論文(この記事で取り上げる論文)
- Residual Networks Behave Like Ensembles of Relatively Shallow Networks
- Learning Deep ResNet Blocks Sequentially using Boosting Theory
- THE LOSS SURFACE OF RESIDUAL NETWORKS: ENSEMBLES & THE ROLE OF BATCH NORMALIZATION
- Functional Gradient Boosting based on Residual Network Perception (ラスボス)
などで実験的な考察や、数学的な精査により、ResNetの真価が明らかになってきたと思われます。
長くなりますが、丁寧にまとめますので最後まで見ていただけると嬉しいです。
また、わかりやすいなとか、少しわかった気がする!という方がいらっしゃいましたら「いいね」や「コメント」お待ちしております!!
ResNet始祖論文についての考察から
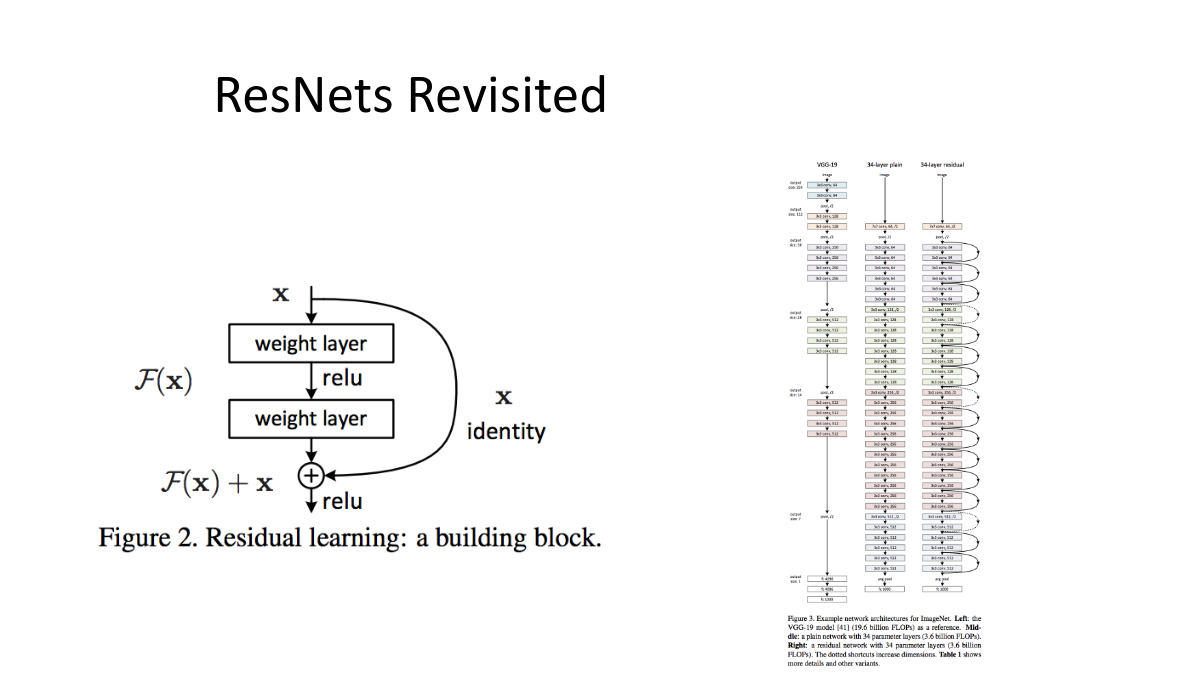
たくさん素晴らしいResNetの解説記事があるので、そちらをまずは見てもらうのもアリです。
簡単に説明すると、ResNetは残差ブロックというものから成っていて、それに入る前の入力を、ショートカット(残差ブロックをすっ飛ばすこと)することをアイディアとして、学習(重みの更新)はショートカットしてきたものと、残差ブロックをくぐったものの差「残差」を学習することで行っています。
その結果、この残差ブロックを構成単位とするResNetは、それより以前のモデルよりもより深くモデルを構成でき、高い精度を達成しました。

ただ、ここで、以下の疑問が出てきます。
- 研究者がどうやってこの残差ブロックのアイディアに至ったのか
- そもそもなぜ残差を学習するのか
- なぜResNetが(数学的に)高精度を達成できるのか
ということです。

これに答えることが今回の目的になります。

上にも書きましたが、上が今回の参考文献になります。
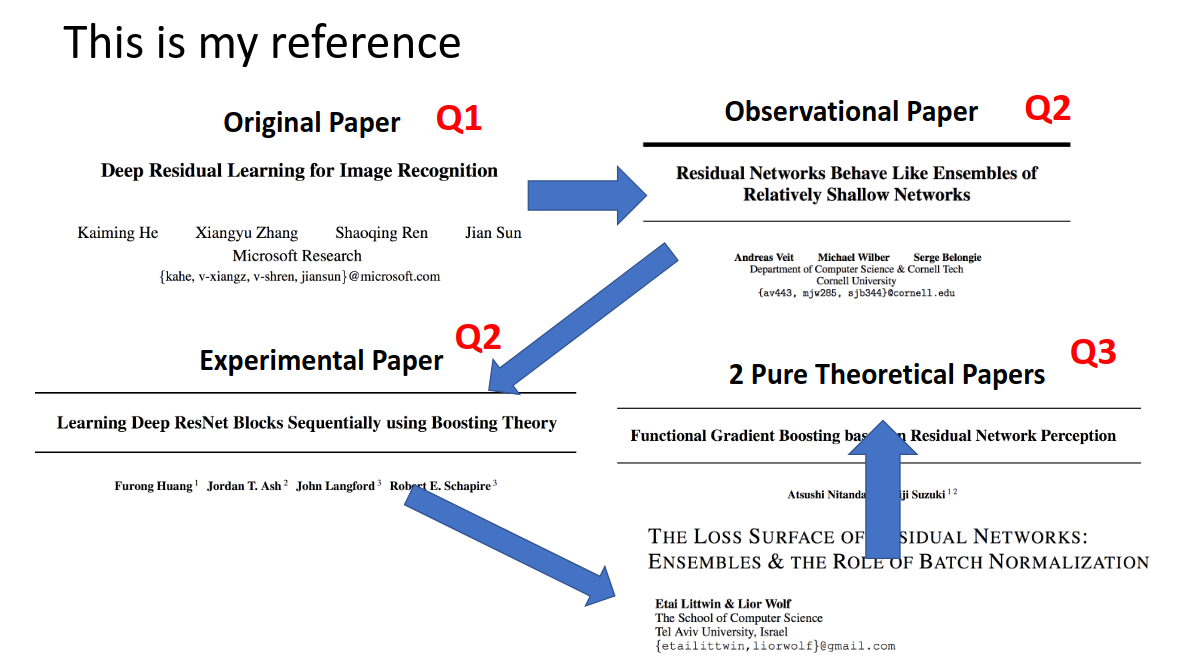
読んでいく流れ(自分的にはこの流れがしっくり来た。)はこうなりますが、
その流れの中でそれぞれ上で出てきた疑問に答えていきます。
個人的には、最後に登場する2017年に書かれたFunctional Gradient Boosting based on Residual Network Perception (ラスボス)
が日本の研究者(東大と理研の方)が書かれたものだったことがとても感動しました。

ということで、まずはResNet始祖論文から。
一番疑問だったのは、どういう発想でResNetのアイディアに行き着いたのかというところ。

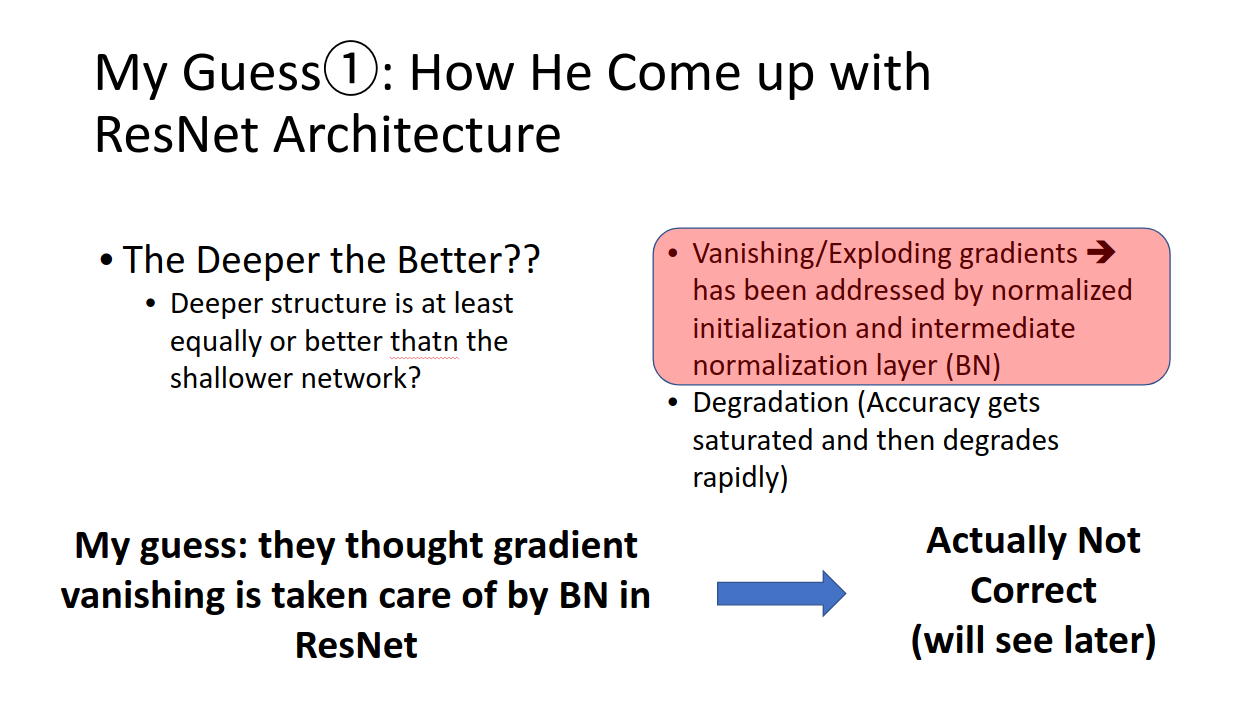
論文のイントロでは主に2つのことについて言及されています。
- 勾配消失
と - モデル劣化
です。
イントロには、上の勾配消失についてはバッチノーマライゼーションなどが解決を試みてきた。
と書いてあり、ニュアンス的にはResNetはモデル劣化を解決する。
というようなふうに読めます。
実際ResNetは
勾配消失を解決する==>ので、モデル劣化が起こりにくい
みたいな理解をしている人が多いのではないでしょうか。実際に調べていくと、この考えは少しずれている、というかこの一言で片付けるほど簡単ではない、です。
私の推測では、Kaimingさんたちはモデル劣化の問題点と、他の機械学習モデルからのヒント(これからお話しします)
からある意味直感的に残差ブロックをひらめいて、それを使った結果ものすごい精度が出た。のかなあと感じています。
この際には数学的な深い精査は行わず、とりあえずこれを世の中に論文で出したのではないでしょうか。
そこの「とりあえずすごいモデル」が出てきたけども、「なんでこんなに高精度なの?」っていう考察や精査は、とりあえずこの段階では他の研究者にまかせて、「とりあえず世にだそう!」みたいな背景があったのではないかと思います。
さらに、私の考察的に、どうやってKaimingさんたちがこの構成にたどり着いたかというのを考えてみます。
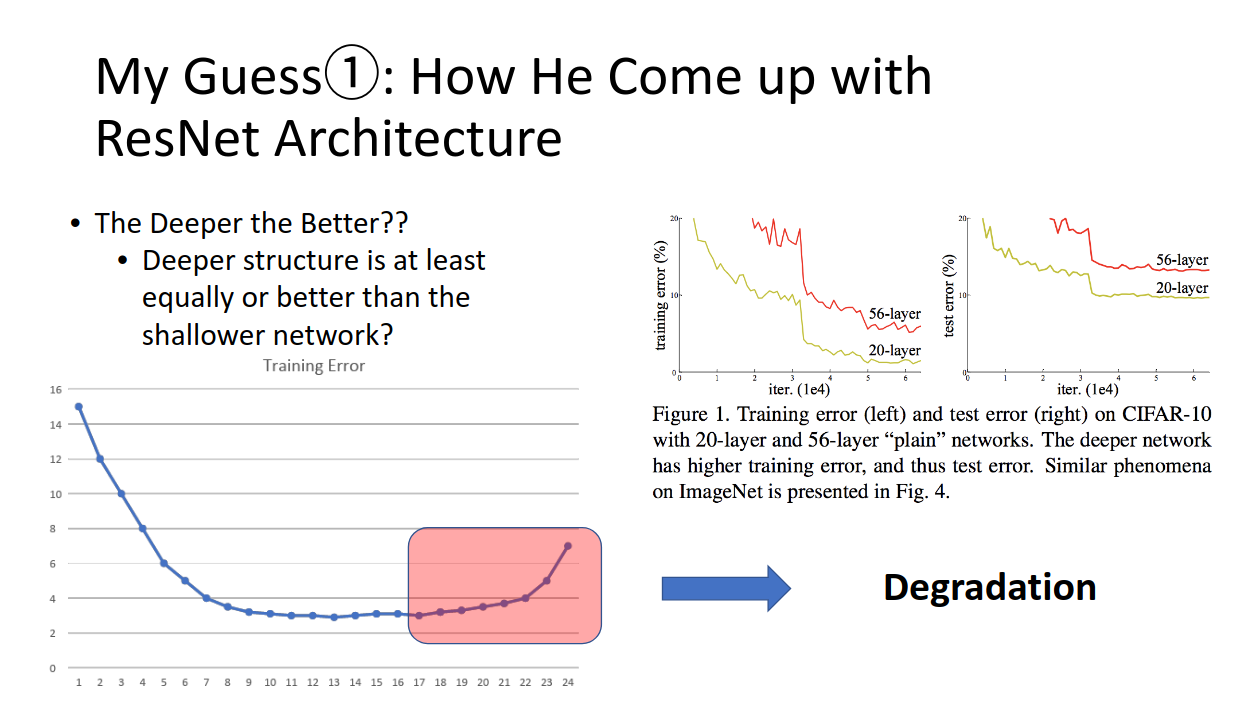
まず根本として、「機械学習モデルは、深くすればするほど複雑な問題でも高精度に予測できるよね??」と考えられていました。
もちろんそこにはモデルを大きくする代償として計算コストが大きくなるという問題はあるけども、理論上パラメータを増やして、複雑な深いNNを組むことで、より複雑な問題も解決可能だろう、とは考えられていたわけです。
しかし、それとは異なる結果が実験的に出てきていました。これがモデル劣化です。モデルを深くしても、ある一定の場所で精度は頭打ちになり、更に深くするとそれを維持することすらできずに精度が悪くなってしまうのです。
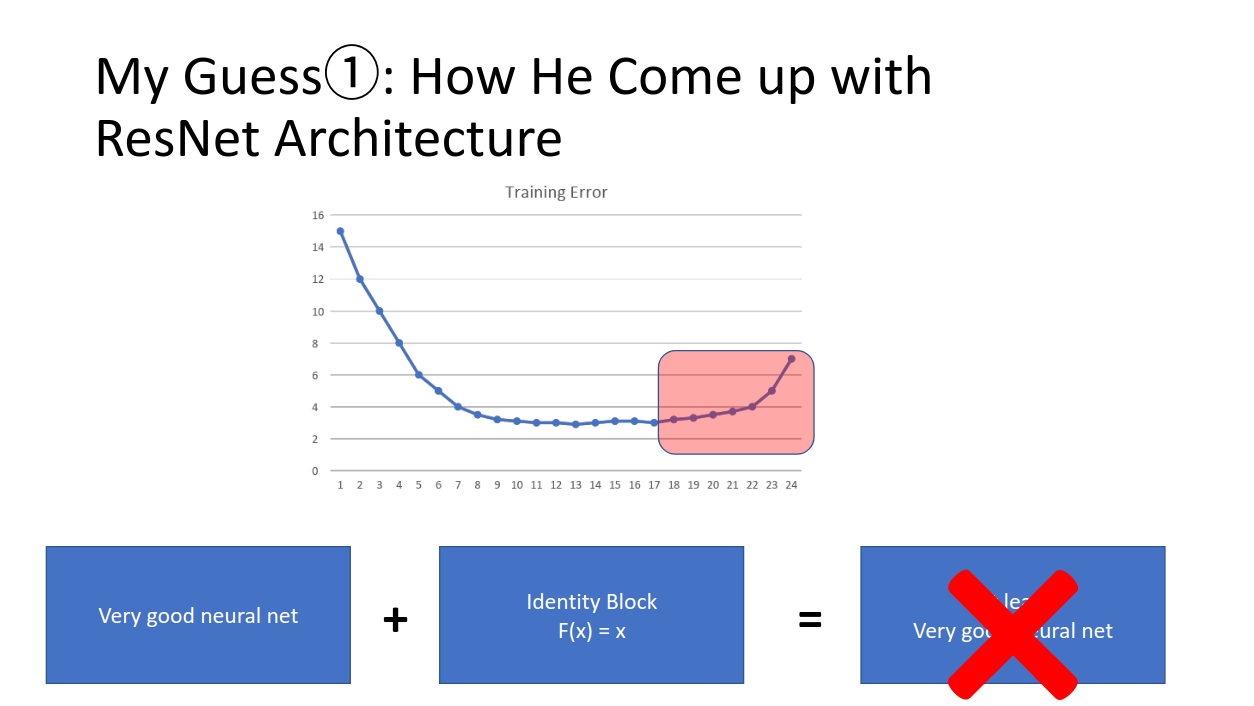
ここでやっていることは、
- ある深さのすでにいい精度をもっているモデルがある
- これを更に深くしたらもっと良くなるか?(なってほしい)
ということです。
このとき、モデルはもうすでにかなりいい精度になっているので、深さを追加しても劇的にモデルが変化することはないだろう、
と予測できると思います。つまり、より深くしようとして追加したブロックは恒等変換(入ったものと出てくるものがほぼ一緒なもの)になるわけです。モデルの最後らへんのブロックに対しては、「恒等変換っぽいことをして、さらに少しだけ入力をより良い精度が出る特徴マッピングして〜」というお願いをしているわけです。
しかし、これがうまく行っていない。。
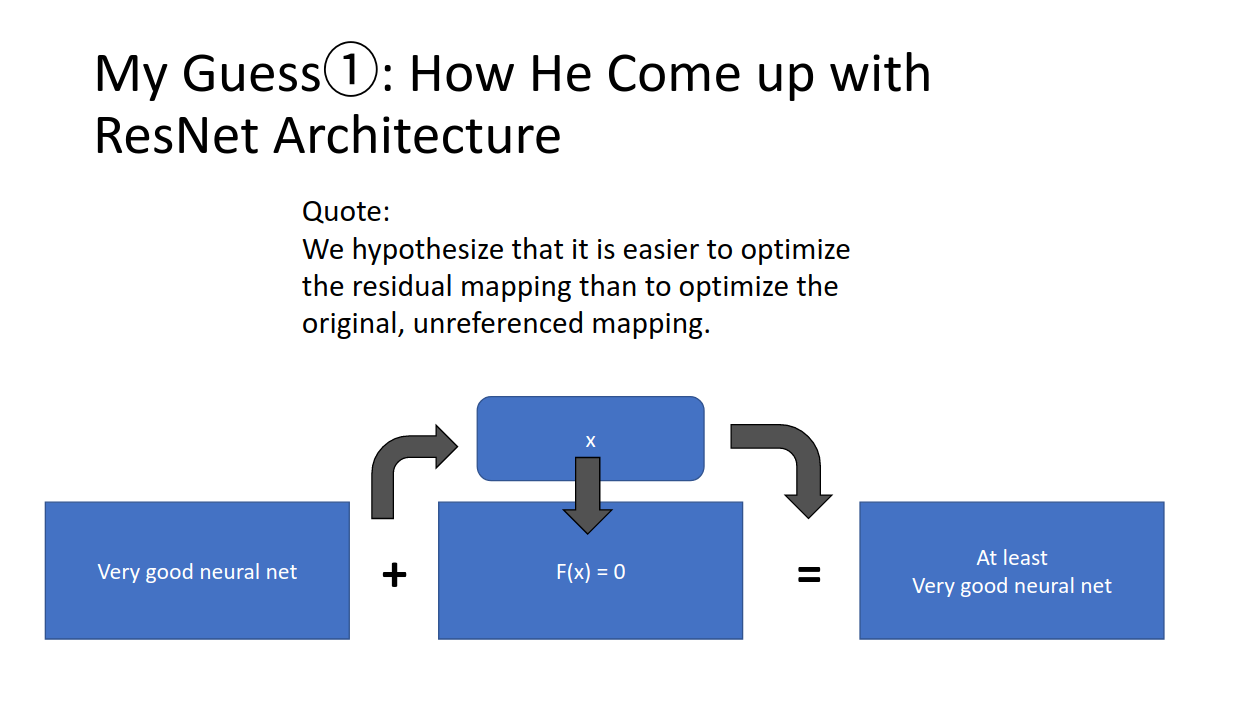
そこで、Kaimingさんたちは、「モデルに恒等変換お願いして、さらにちょっとずつ精度を高めるマッピングお願いするのは酷だよね?なら、恒等変換だけはこっちで用意してあげようか!」ってなったわけです。
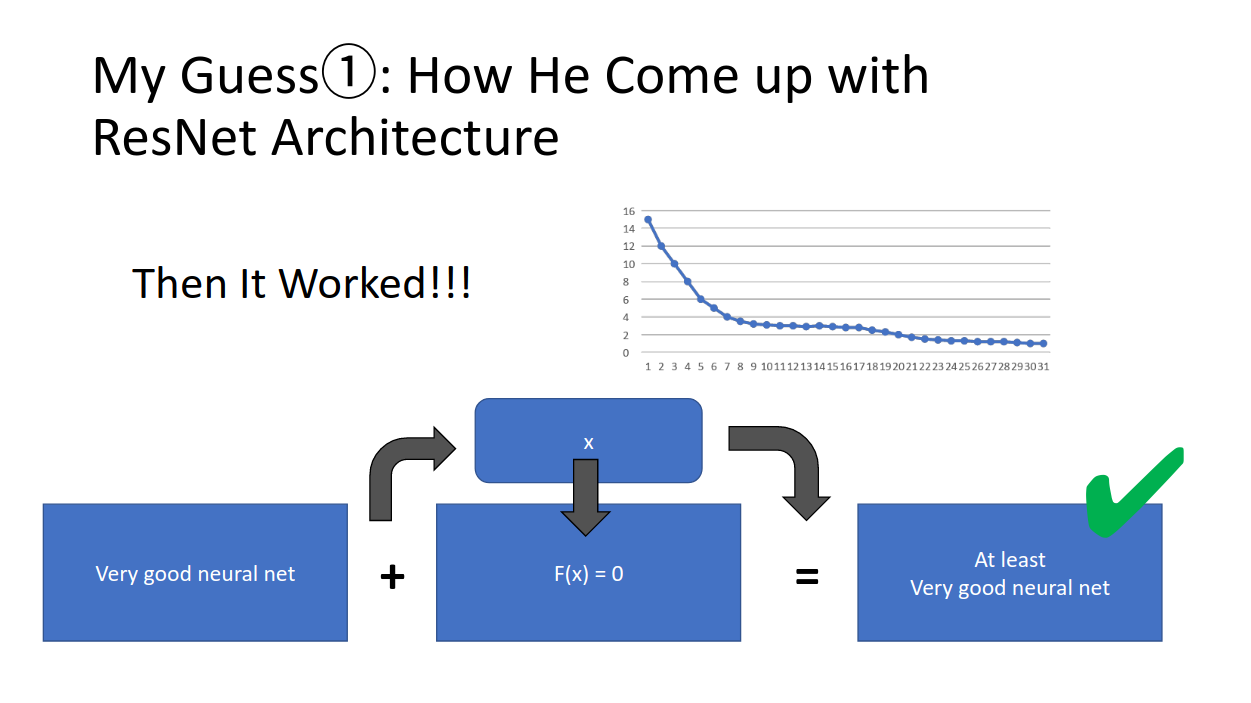
この結果、これなんかうまくいくぅ!!ってなったみたいです。
「ああ、モデルくんも恒等変換ずっとするのしんどかったみたいだね。。お疲れ様〜」
とでも思ったのかなあ。。。

というわけで、恒等変換分はショートカットで用意してあげよう、あとはモデルがうまくちょっとずつ精度を上げてくれるのを期待しよう!
というふうな発想でResNetは生まれたんではないでしょうか。
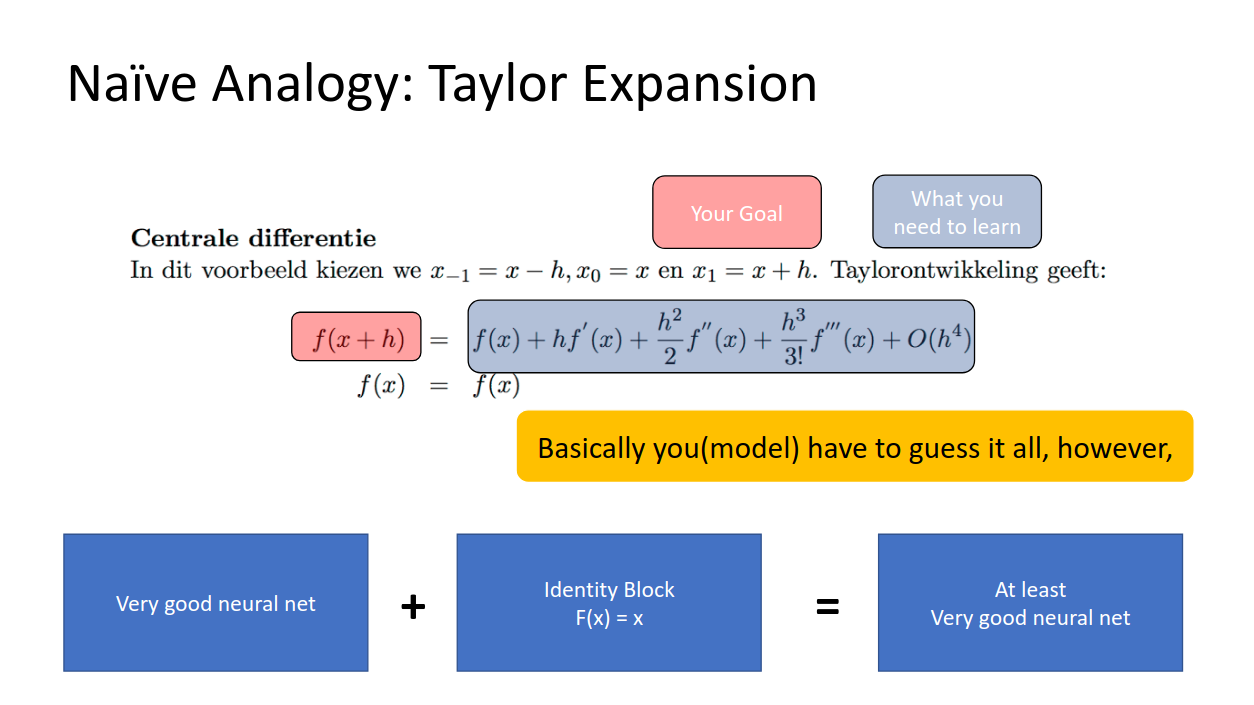
個人的には、テイラー展開のアナロジーがそこそこしっくり来ています。
左の赤いf(x+h)がより良い精度のモデルだとして、それをテイラー展開(青で囲まれた右辺)したとします。テイラー展開は無限次元の近似で、最初の項だけより次の項を足したもの、それより更に次の項を足したもの、・・・というふうに近似をより良くしていきますよね?
今までは右の項をすべてモデルに学習させ続けようとしていたのですが、これはある意味やりすぎだったわけで、
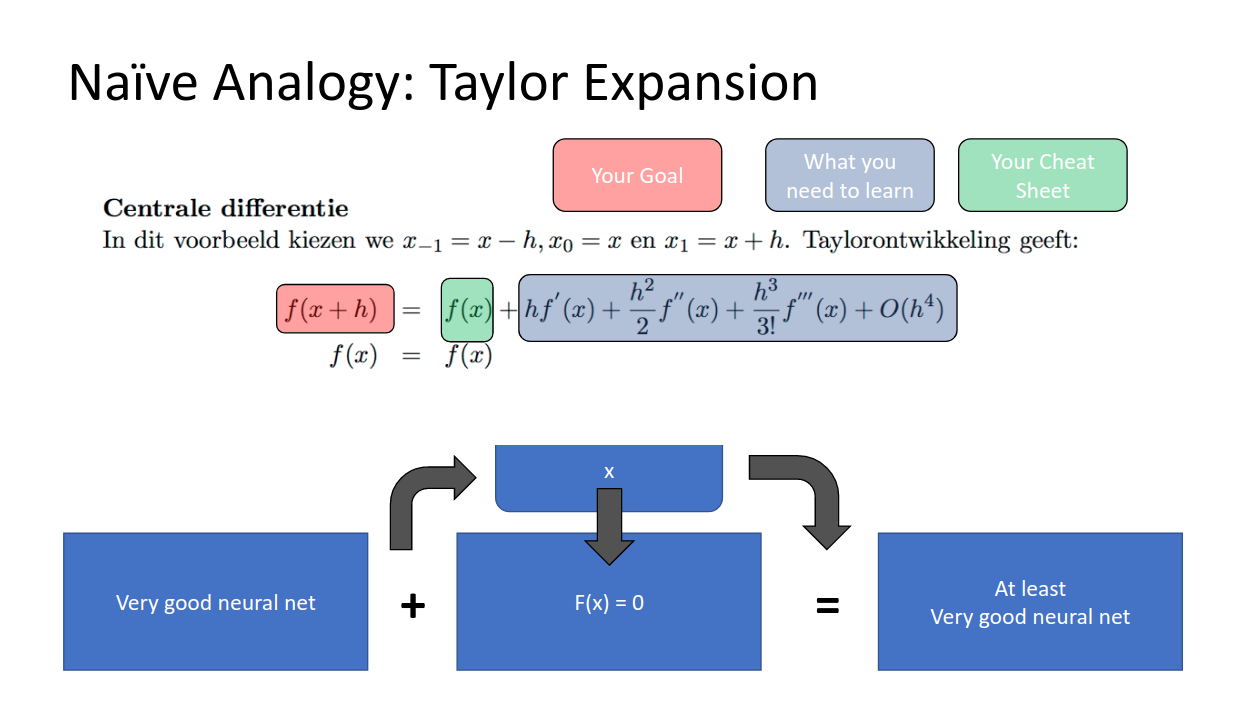
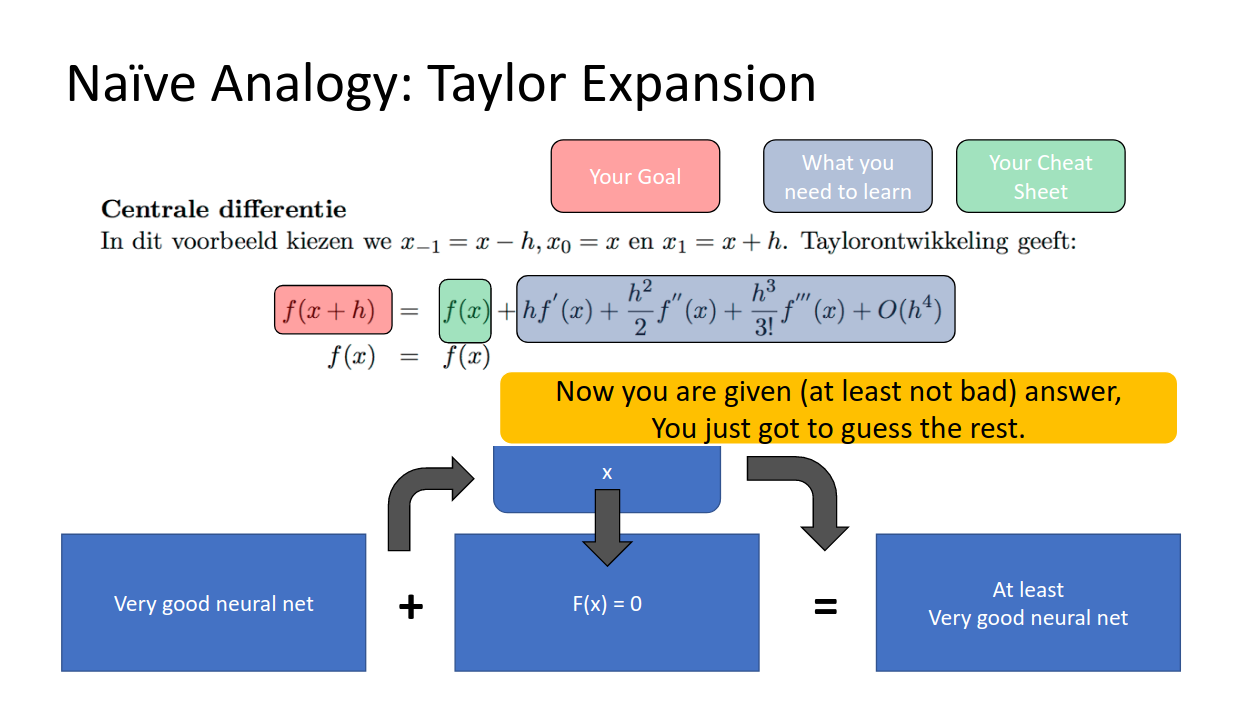
恒等変換(現状維持)の項だけは与えて(テストのチートシートみたいに)、あとの項だけ頑張って推測してよ!
というモデルにトライした結果、うまく行ったというわけです。
序のまとめ
というわけで、私の推測にしか過ぎませんが、KaimingさんたちがどうやってResNetの構成を思いついたか、というのはこんな感じだったんじゃないかなーと思いました。
これで当初の疑問の1には一応答えたということで、次回は2に答えていけるようにがんばります。