本題
これは、ResNetについて考察した4本立て(序、破、Q、:||)の一記事です。
というわけで、前回の続きなのですが、前回は、
第一回で定義した疑問
- 研究者がどうやってこの残差ブロックのアイディアに至ったのか
- そもそもなぜ残差を学習するのか
- なぜResNetが(数学的に)高精度を達成できるのか
の2つ目について考えました。加えて、
の考察を用いて、ResNetとは異なる経路長をもつものを弱学習器単位とした、アンサンブル学習である。
という根幹にも迫りました。

今回は、
-
Learning Deep ResNet Blocks Sequentially using Boosting Theory
を読み込んでいきます。
簡単にこの論文の趣旨を説明すると、
「ResNetはアンサンブル学習を行っているようだけど、じゃあアンサンブル学習からResNetって作れるよね?」
ということです。

まあでもよく考えると、ResNetがアンサンブル学習っぽいということはわかっても、普通のアンサンブル学習とは違うよね、、ってなります。
なぜかと言うと、
普通の残差を学習するアンサンブル学習、勾配ブースティングは弱学習器から得られる推論値をアンサンブルしていたのに対し、
ResNetは推測される特徴量表現をアンサンブルしているからです。
ここ大事なのでもう一度いいます。
ResNetのアンサンブルは、正解ラベルと比べる推論値をアンサンブルするのではなく、(推論途中の)特徴量表現のアンサンブルなのです。
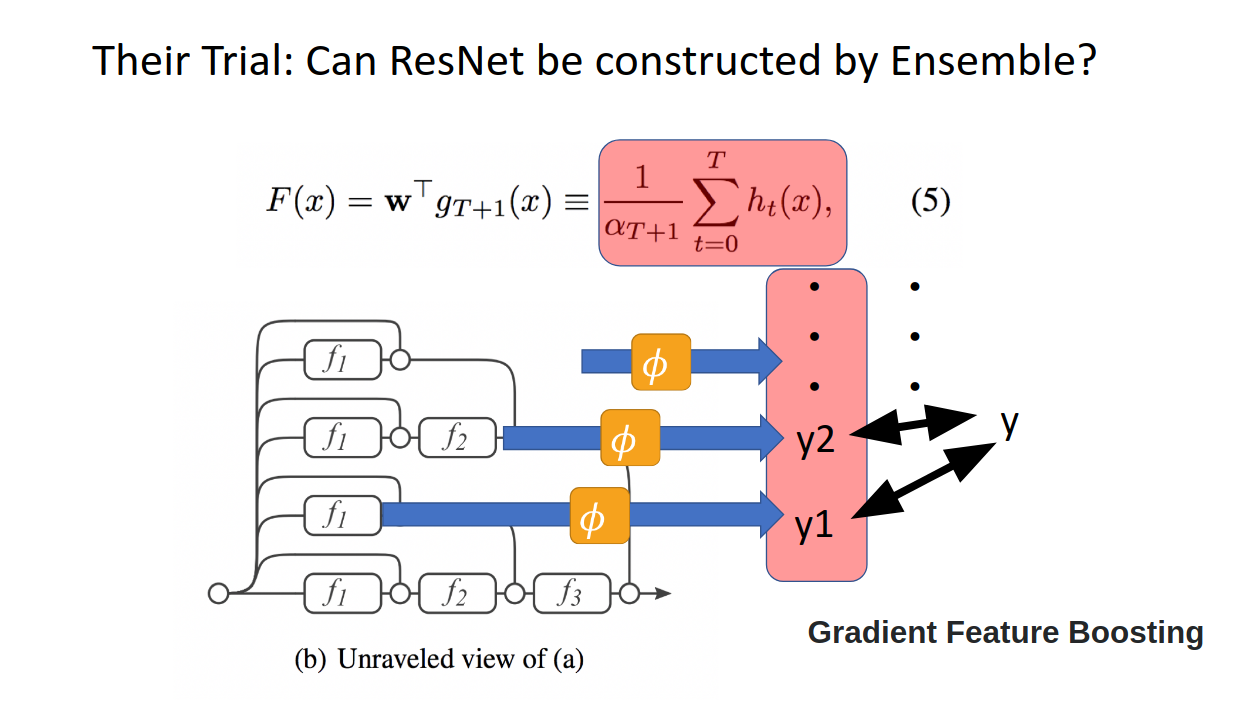
ここで、この論文の著者Huangさんはこうやりました。
無理やり途中の特徴量から推論値を吐き出す変換を一個人工的に入れて、それを使って正解ラベルと比べてやろう。
ここでは例として回帰問題となっているので、上の(3)のように途中の特徴量表現g_t(x)に人工的に入れたw_tを書けてあげることで、
むりやり最後の推論問題まですっ飛ばします。
そして、(4)で定義したすっ飛ばされた推論値と、次の層からすっ飛ばされた推論値の差に対して学習をし、それらを最後アンサンブルとして強学習器を作ったらどうなるんやろ?ってやってみたわけです。

結論から言います。なんと、(5)のこの結果は、ResNetからの出力と、上で作られたアンサンブルモデルの結果が一緒になったのです!!!
つまり、やはりResNetはアンサンブル学習であり、残差を学習させるということは、それぞれの弱学習器の途中結果を正解ラベルと比べたときの残差を学習させることと同じことをしている!!
ことがわかったのです。
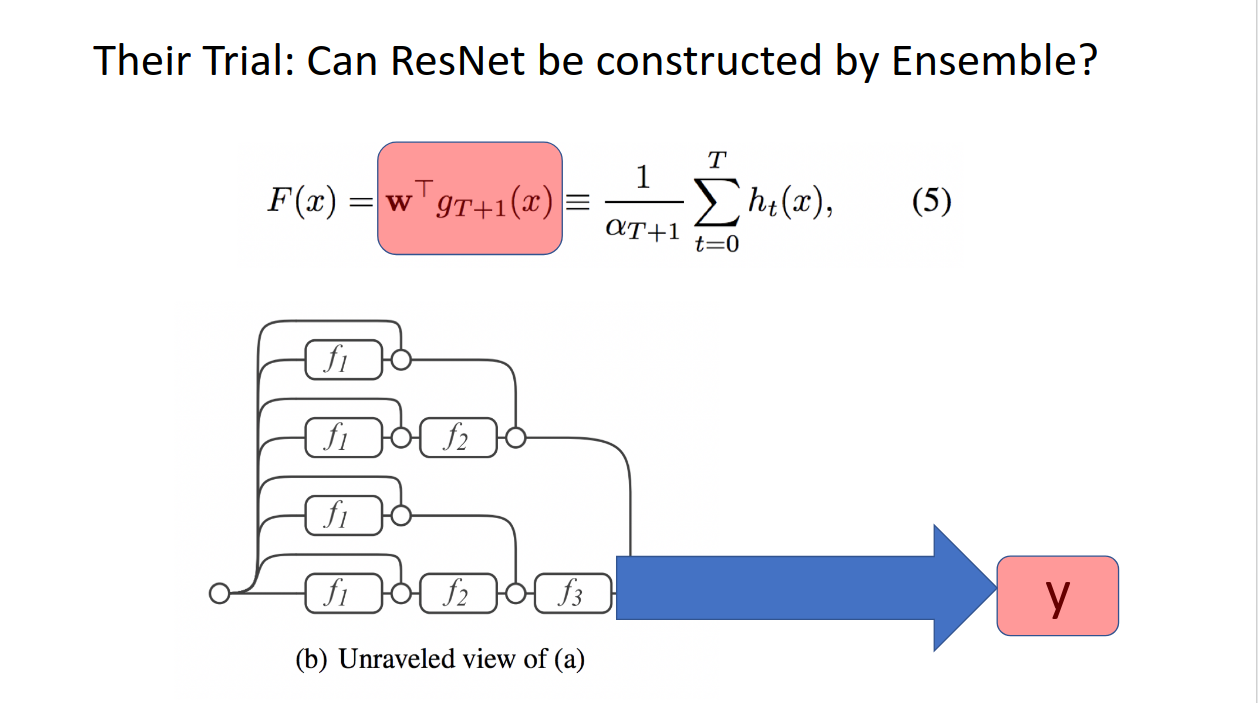
たぶん混乱させてしまったので、もう一度詳しく説明します。
(5)の左辺は、ResNetを普通に学習させたときに出てくる出力です。g_(t+1)(x)がxを入れたあと、t回残差ブロックをくぐらせたもので、最後のwは最後に推論させる(例では回帰なので1次元に飛ばす)ための線形変換です。
一方(5)の右辺は、ResNetの途中の層をそれぞれ推論空間にマッピングさせ、残差を学習させたものの和、つまり勾配ブースティングによるアンサンブル学習です。
(5)は、それらの結果が等しくなる!ということを言っているのです!!
すごいよね、。。。。
Qのまとめ
今回は比較的短かったですが、まとめです。
ResNetがアンサンブル学習っぽいことはわかっていたが、実際にResNetをブロックごとに残差学習させたものをアンサンブルすると、それはResNetの出力そのものに成るということがわかった。