はじめに
機械学習の分野でDeep Learningがその地位を揺るがぬものにして久しくなりました。
Deep Learningの応用分野は多岐に渡りますが、今回はその中でも非常に有用性と実用性の高い「Image Denoising」への応用について、簡単なまとめといくつかのデモを紹介していきたいと思います。
通常のデノイズと、実問題に近い設定としてノイズ画像しか手に入らない状態でのデノイズもやります。
Image Denoisingとは
Image Denoisingとは、文字通り、「画像からのノイズ除去」です。カメラなどで撮影する写真や映像データには、撮影環境など、様々な要因によってノイズが付加され、本来の画像に比べて視認性の低下を招いてしまいます。こうしたノイズが付加された画像から、元の画像を復元する事をデノイズといい、我々が普段目にする画像だけでなく、CTやMRIの画像からのノイズ除去など、医用画像の分野にも応用されています。

Deep Learning for Image Denoising
画像のノイズ除去の基本的な手法として、メディアンフィルタ、ガウシアンフィルタ、移動平均等の平滑化処理が古くから用いられてきました。機械学習の分野においては、ニューラルネットワークを用いた手法自体は古くから提案されてはいましたが、主流な手法という訳ではありませんでした。しかし、畳み込みニューラルネットワークなどの発明を皮切りに、Deep Learningが画像領域において圧倒的なパフォーマンスを示す中で、デノイズの分野への応用も急速に進みました。現在も日夜研究されている分野の一つであり、コンピュータビジョン系のトップカンファレンスでも主要トピックの1つとなっています。
以下、Deep Learningを用いたデノイズにおける、いくつかの主要な手法とそのデモを紹介して行きます。
デモ1. 手書き文字からのデノイズ
データは、今回もMNIST(手書き文字画像)を使って行きます。
ノイズが付加された画像を入力データ、その元画像を正解データとしてノイズを除去するモデルを学習し、新規のノイズ画像に対してのデノイズを行います。

入力データ:正解データにガウシアンノイズを付加したノイズ画像50,000枚
正解データ:元画像50,000枚
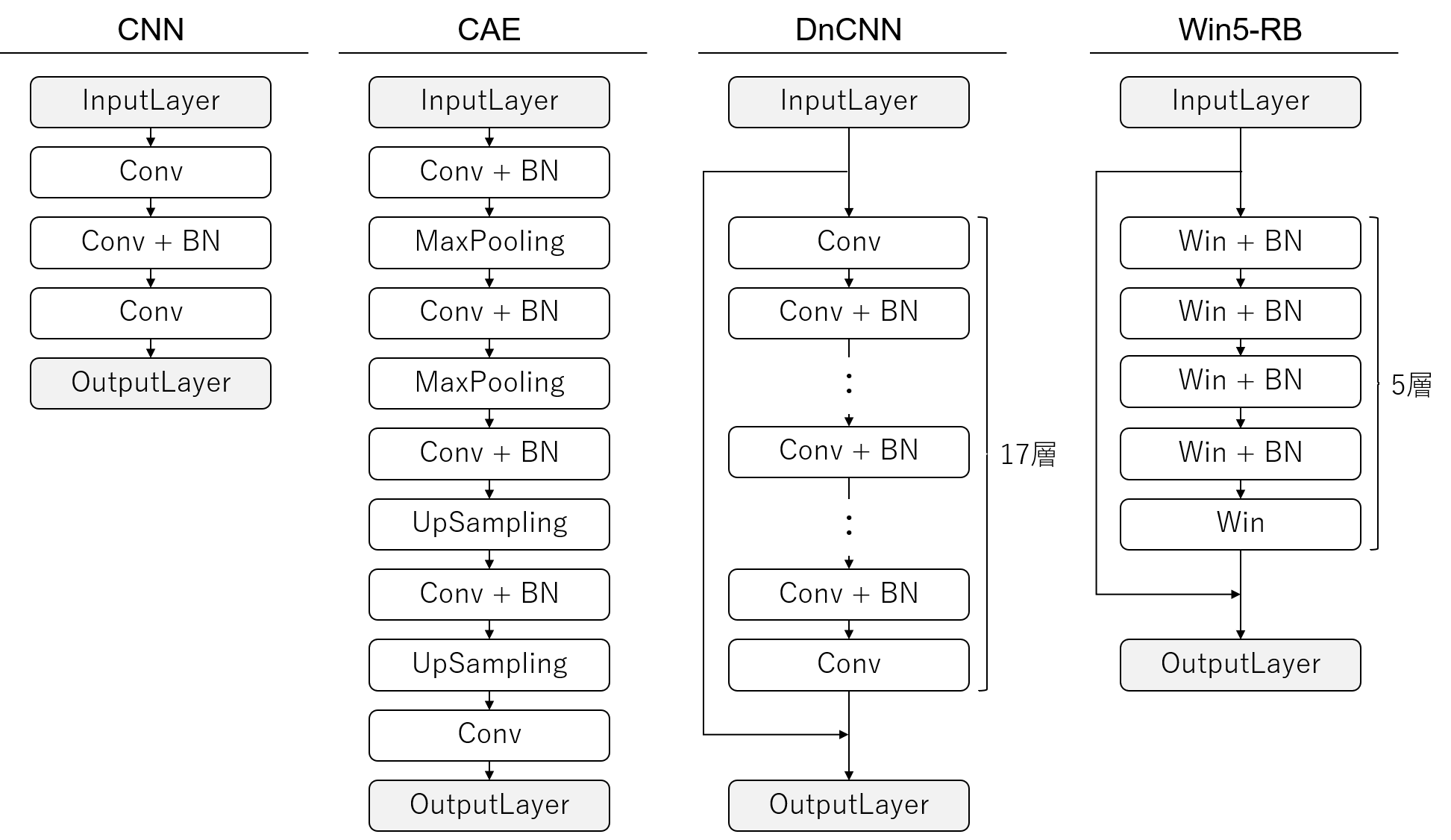
学習するモデルとしては、通常のCNN(Convolutional Neural Network)に加え、以下の3つで比較を行っていきます。
- CAE(Convolutional Autoencoder)
- DnCNN(Denoising Convolutional Neural Network)
- Win5-RB(Wide Inference Network 5layer + Resnet and BatchNormalization)
1. CAE(Convolutional Autoencoder)
Autocoderは出力データが入力データに近づくように学習を行う、ニューラルネットワークアーキテクチャの一種で、次元削減の分野で主に活用されています。
EncoderとDecoderが対になっており、入力データをEncoderで潜在変数に圧縮し、圧縮した潜在変数からDecoderで復元する構造になっています。

潜在変数の次元を入力データより小さくする事で、入力データを再現できるような低次元の特徴を捉える事ができ、EncoderとDecoderにニューラルネットを使うので非線形の次元削減が可能になります。
次元削減の用途だけでなく、「潜在変数に圧縮して本質的な特徴を捉える」「Decoderで画像の復元が可能」という性質から、ノイズ除去にも利用されており、入力画像をノイズ画像にする事でデノイズが可能になります(別名Denoising Autoencoder)。

AutoencoderのEncoderとDecoderのニューラルネット部分を畳み込みニューラルネットに置き換えたものがCAEであり、畳み込みニューラルネットを使う事で画像データからのデノイズの精度が大きく向上します。

2. DnCNN(Denoising Convolutional Neural Network)
DnCNNは「Denosing」という名前の通り、ノイズ除去を目的としたCNNです。
DnCNN は17層から構成される多層のCNNであり、入力画像に対して、Convolution(畳み込み)とBatchNormalization(バッチ正規化)を繰り返し適用する形になっています。

BatchNormalizationとは、ニューラルネットの各層の出力を正規化する手法で、内部共変量シフト(各層の分布が訓練中に変わる事)の問題を抑制する事ができ、学習効率と精度の向上に寄与します。
また、DnCNNの大きな特徴の一つが、ResNet(残差ネットワーク)の枠組みを用いている点で、ノイズ画像から、ノイズが除去された画像を直接推定するのではなくノイズ成分を推定し、そのノイズ成分をノイズ画像から取り除く事で元画像を推定します。ノイズレベルが低い場合含め、デノイズの枠組みでは入力と出力の値が近い場合が多く、恒等写像に近い学習を有限なニューラルネットによる非線形写像で行う事は非効率なため、その差分を学習させる事で学習効率を向上させます。例えば、差分がない場合は、恒等写像をニューラルネットで学習させる必要はなく、各層の重みを単純に0にするだけで良くなります。実装方法としては、入力値をそのままバイパスさせ、最終層に繋げる事で、ニューラルネットにその差分を学習させます。
3. Win5-RB(Wide Inference Network 5layer + Resnet and BatchNormalization)
Win5-RBは、Wide Inference Network(Win)が5層で、それをResnet(R)とBatchNormalization(B)で接続したモデルであり、デノイズのタスクにおいては、層の深さだけでなく、フィルタ数とカーネルサイズを通常のCNNよりも大きくする事が有効であると主張されており、Wide Inferenceという名前がついています。
様々なデータを利用したデノイズの実験からフィルタ数128、カーネルサイズ7×7が採用されており、フィルタ数とカーネルサイズの大きさにより各層の表現力が高く、DnCNNに比べ浅いネットワーク構成になっています。

モデル構築
モデルの構築はGoogle Colaboratory上でKerasを使ってやって行きます。
各モデルの概要は以下の通りです。
各種学習パラメータ
- エポック数:10
- バッチサイズ:128
- 各層のフィルタ数:64(Win5-RBのみ128)
- カーネルサイズ:3×3(Win5-RBのみ7×7)
結果
テストとして、同じくガウシアンノイズを付加したノイズ画像からのデノイズ結果は以下です。

CNNでは一部で滲みのようなものが出てしまっていますが、CAE, DnCNN, Win5-RBでは、元画像との差がほとんどわからないレベルで上手くノイズが除去できています。
テスト画像10,000枚でのMSE(平均二乗誤差)では、Win5-RBが最も高い精度を出しています。
| モデル | MSE |
|---|---|
| CNN | 0.01171 |
| CAE | 0.00991 |
| DnCNN | 0.00943 |
| Win5-RB | 0.00873 |
Flaskでのデモ
学習したモデルを使って、Flaskでリアルタイムで処理できるデモを作りました。
こちらはCAEでのデモですが、ノイズを上手く除去してくれている事がわかります。

デモ2. ノイズデータのみの状況でのデノイズ
デモ1では、ノイズ画像とノイズがない元画像を使ってノイズ成分を除去するモデルの構築を行いました。
既に気付いた方もいるかもしれませんが、そもそもノイズがない元画像が入手できるのか?という問題があり、実問題においては、ノイズのない元画像が手に入らない場合が多く、手元にあるのは全てノイズが乗った画像だけです。このような実問題を考慮し、ノイズ画像しか手に入らない状況でのデノイズをやって行きます。
Noise2Noise
Noise2Noise(N2N)とは、学習時にノイズ画像のみを利用するノイズ除去の機会学習手法で、ノイズ画像しか利用しないにも関わらず、ノイズのない画像(正解データ)を使う学習手法と遜色ない性能が出せる手法です。
一言で言うと、ノイズ画像からノイズ画像への変換(Noise2Noise)を学習する事で、ノイズ画像からノイズのない画像(正解データ)への変換を学習します。

以下、簡単な解説です。
ノイズ画像$ \hat{x}_i $と、ノイズのない元画像$y_i$のペア$(\hat{x}_i, y_i)$からのノイズ除去のタスクは、以下の経験損失の最小化で定式化されます。
\tag{1}
\underset{\theta}{argmin} \displaystyle \sum_i L(f_\theta(\hat{x}_i),y_i)
ここで$ f_{\theta} $は、損失関数$L$の条件における変換のパラメータ(例:CNNの重み)となります。
一方、Noise2Noiseでは正解画像もノイズ画像であるため、$y_i$が$ \hat{y}_i $となった以下の経験損失の最小化となります。
\tag{2}
\underset{\theta}{argmin} \displaystyle \sum_i L(f_\theta(\hat{x}_i),\hat{y}_i)
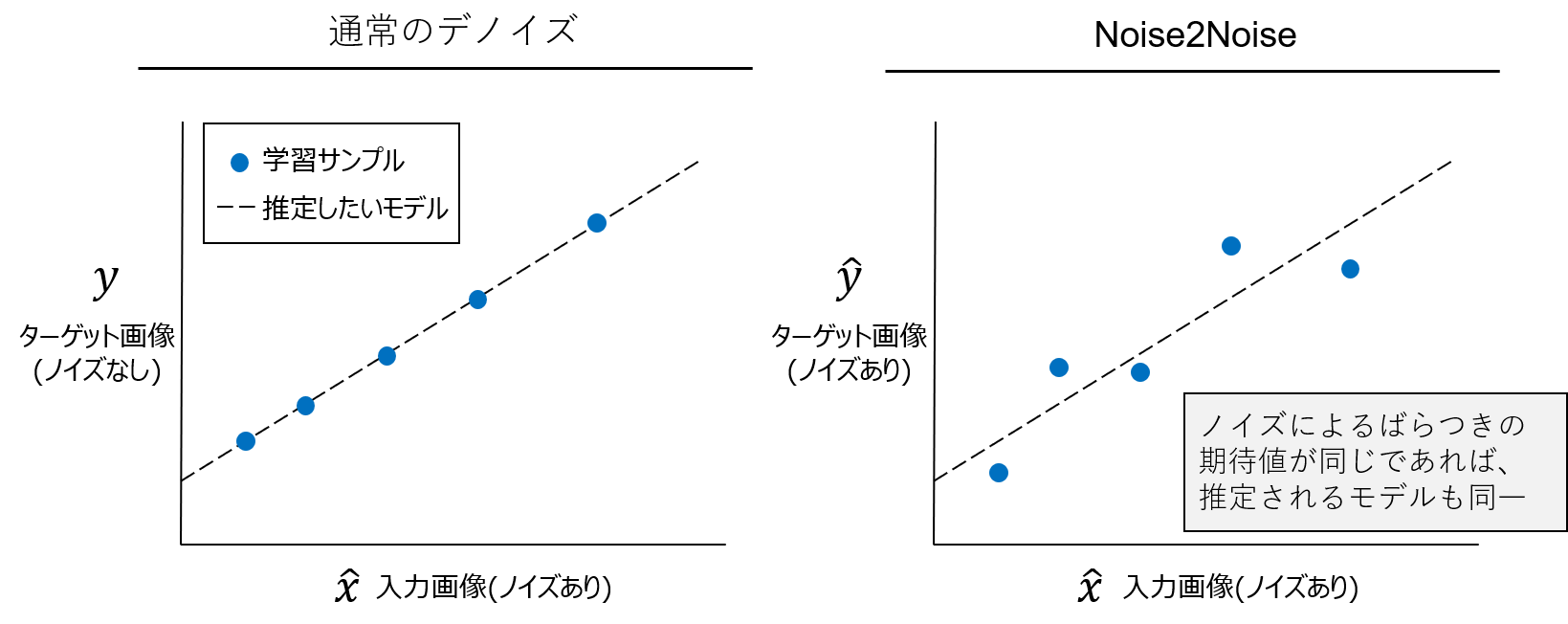
Noise2Noiseにおいては、入力条件付きのターゲット分布$p(y|x)$が任意の同じ期待値を持つ分布に置き換えられても、最適化するパラメータ$\theta$は変化しないと主張しています。つまり、ターゲットがノイズ画像であっても、その期待値は $E \{ \hat{y} _i | \hat{x} _i \} = y _i $であるため、(1)と(2)を最適化した際に得られる$f _\theta$は等価であるという事になります(ただし、推定結果の分散は、ターゲットにおけるノイズの分散を学習サンプルの数で割った平均)。
これは回帰の文脈で考えてみるとわかりやすく、得られたサンプルから背後にあるモデルを推定したい場合、同一のモデルが推定されるサンプルの組み合わせは一つではなく無数にあります。このため、ノイズによって観測値にばらつきがあったとしても、そのバラつきの期待値が元のサンプルと同じであれば($E \{ \hat{y} _i | \hat{x} _i \} = y _i $)、そのサンプルから損失を最小化して得られるモデルと、ノイズのない画像で損失を最小化して得れらるモデルは同一という事になります。これがノイズ画像からノイズ画像への変換(Noise2Noise)を学習する事で、ノイズ画像からノイズのない画像(正解データ)への変換の学習が可能になる理由です。
モデル構築
学習は、入力とターゲットにそれぞれノイズ画像を使用します。

モデルはWin5-RBを使用し、デモ1と同様の学習パラメータを使用します。
結果
テストとして、同じくガウシアンノイズを付加したノイズ画像からのデノイズ結果は以下です。

学習にノイズ画像しか利用していないにも関わらず、驚くべき事にノイズが除去できています。
私自身、最初に論文を読んだ時は半信半疑だったのですが、この結果を見てかなり驚きました。N2Nはこのように、正解データの入手が困難な状況においてもノイズ除去が可能なため、利用可能なシーンの幅が大きく広がる画期的な技術である事がわかります。
論文では、ノイズのない画像(正解データ)を使う学習手法と遜色ない性能が得られたと報告されていますが、テスト画像10,000枚に対するMSEの値を見てみると、正解データを利用したデモ1に比べて高い値になっています。
| モデル | MSE |
|---|---|
| Win5-RB(N2N) | 0.0425 |
考察のために、学習時とテスト時の画像の画素値のヒストグラムを見てみます(0が黒、1が白の画素値に相当)。
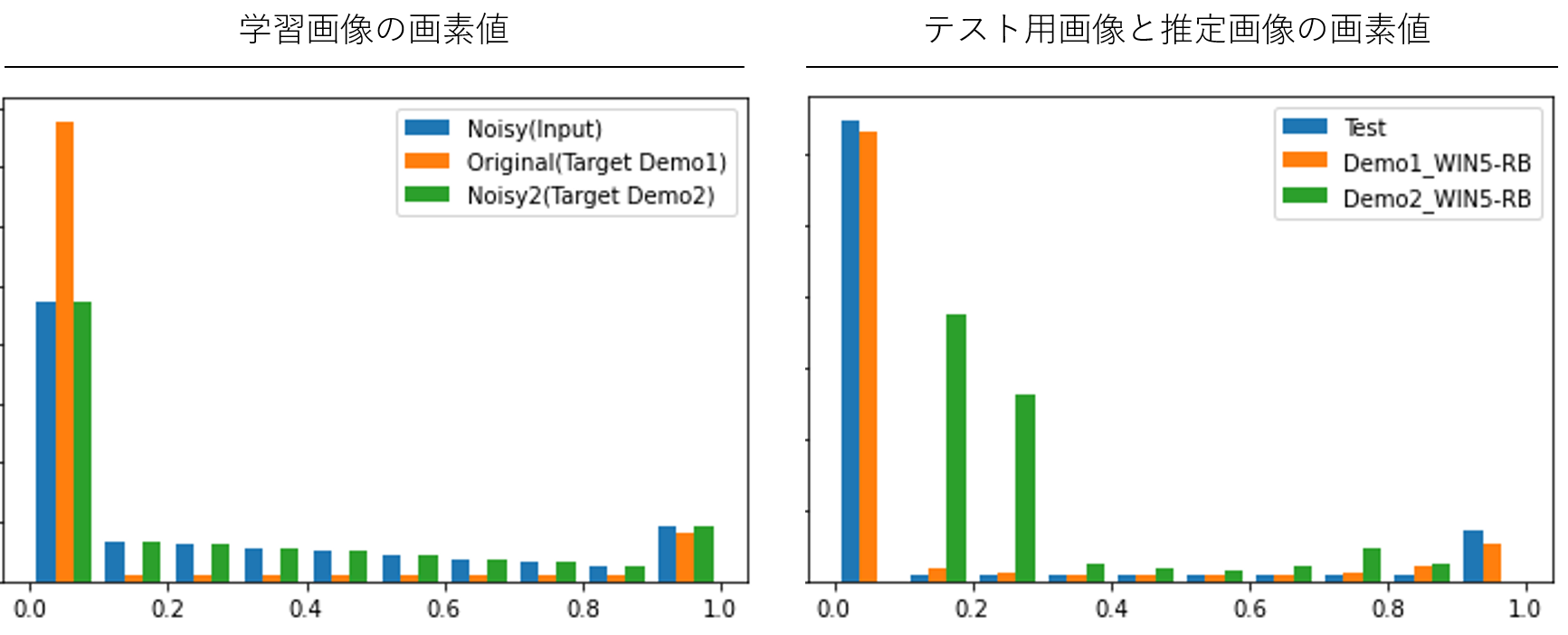
デモ1での学習時のターゲット画像はノイズのない元画像(Original)のため、画素値に0が多い一方で、デモ2のターゲット画像はノイズ画像のため、ノイズにより0の数が減り、画素値がまんべんなく分布している事がわかります。推定画像を見てみると、デモ1のWin5-RBは、テスト画像に近い分布(0と1がくっきりとわかれている分布)を示しているものの、デモ2の推定画像は0と1から中央によった分布となっています。つまり、ノイズ画像からノイズ画像への学習においては、0や1をくっきりと出すより、少し間に寄せた値を出すほうが損失関数の最小化に寄与するため、この結果となっている事がわかります。
今回使用した手書き文字画像は2値画像に近く、偏りが極端に大きい画像であったため、このような結果となった事が推察されます。デモ2の実際の推定結果の画像を見ても、形状はしっかりと捉えているものの、全体的に少し薄みがかった画像になっている事がわかり、自然画像のように画素値の分布が左右になだらかな場合においてはより高い性能が出るのではないかと思われます。
まとめ
Deep LearningのImage Denoisingの分野への応用を紹介し、ノイズのない正解画像を元に学習するケースと、ノイズ画像しか手に入らない実問題に近いケースでのノイズ除去を行いました。今回はガウシアンノイズを中心にデノイズをやりましたが、ごま塩ノイズやその他のノイズにおいても有効な手法である事が論文においても示されています。
今回はノイズ除去を実施しましたが、ノイズというレベルではなく、画像に大きな欠損がある場合のDeep Learningによる復元についてもまた紹介して行きたいと思います。
<参考>
Qiita記事
・AIで遊べるデモサイト「AI World」
・【AI】Deep Metric Learning
・【AI】Deep Learning for Image Inpainting
・【AI】Deep Convolutional Autoencoderベースの教師なし異常箇所検知
・RPAは誰でも簡単に作れるという罠
・VBAが組める人ならRPAは簡単に作れるという罠
・UiPathのコーディングチェックツールを作ってみた【RPA】
・RPAへの理解がぐっと深まる、RPAがよくこける理由
・RPAのオススメ書籍
・RPAの開発に向いている人、向いていない人
・寿司打を自動化してみた
・RPAの推進に必須なRPAOpsという考え方
デモ
・AI World:DeepLearningを使ったAIのデモサイト
・UiPathCodingChecker:UiPathのxamlファイルからコードを分析
・寿司打自動化(YouTube):タイピングゲーム寿司打のRPA×OCRでの自動化