はじめに

どれも良い画像ですね。
しかし、実はこれらは元々この世に存在しない画像で、オリジナル画像は以下です。

今回はこのような応用を可能にする「Image Inpainting」をやって行きたいと思います。Image Inpaintingを使用する事で、画像の指定領域の再構成が可能になり、画像上の不要なオブジェクトの消去や欠損領域の復元を周辺領域を元に自然な形で実現する事ができます。
本記事では、オブジェクト消去と欠損領域の復元、人検出と組み合わせたオブジェクトの自動消去のデモをそれぞれやって行きます。
Image Inpaintingとは
Image Inpaintingとは、一言で言うと「画像上のマスクされた領域を再構成する技術」になります。
・インプット:マスクを含む画像
・アウトプット:マスク領域が再構成された画像

この技術により、元画像に対して、再構成したい領域をマスクで指定する事でマスク領域が再構成された画像を得る事ができます。
Image Inpaintingの手法自体は古くから存在し、パターンは大きく以下の3つに別れます。
- 拡散ベース:周辺ピクセルの加重平均等により再構成(OpenCVデフォルト)
- パッチベース:画像内で類似領域を検索し、パッチを貼り付けて補完
- 学習ベース:マスク画像をインプット、元画像を正解ラベルとしてDNNで学習
拡散ベースの手法では、ある程度マスクが大きいケースでは限界があり、パッチベースではそもそも画像内に類似領域がないものは復元できず、やはり高い精度を得るにはDNNによる学習ベースが主流になってきます。
ComputerVisionの応用として、GANやContextualAttentionなど様々な手法を取り入れたアーキテクチャが提案されています。
今回使用するモデル
今回は、ICCV2019のOralに採択されたGated Convolutionを使用したモデル(DeepFillv2)を使って行きます[1]。
モデルの全体構成は以下の通りで、GANを用いたモデルになっています。
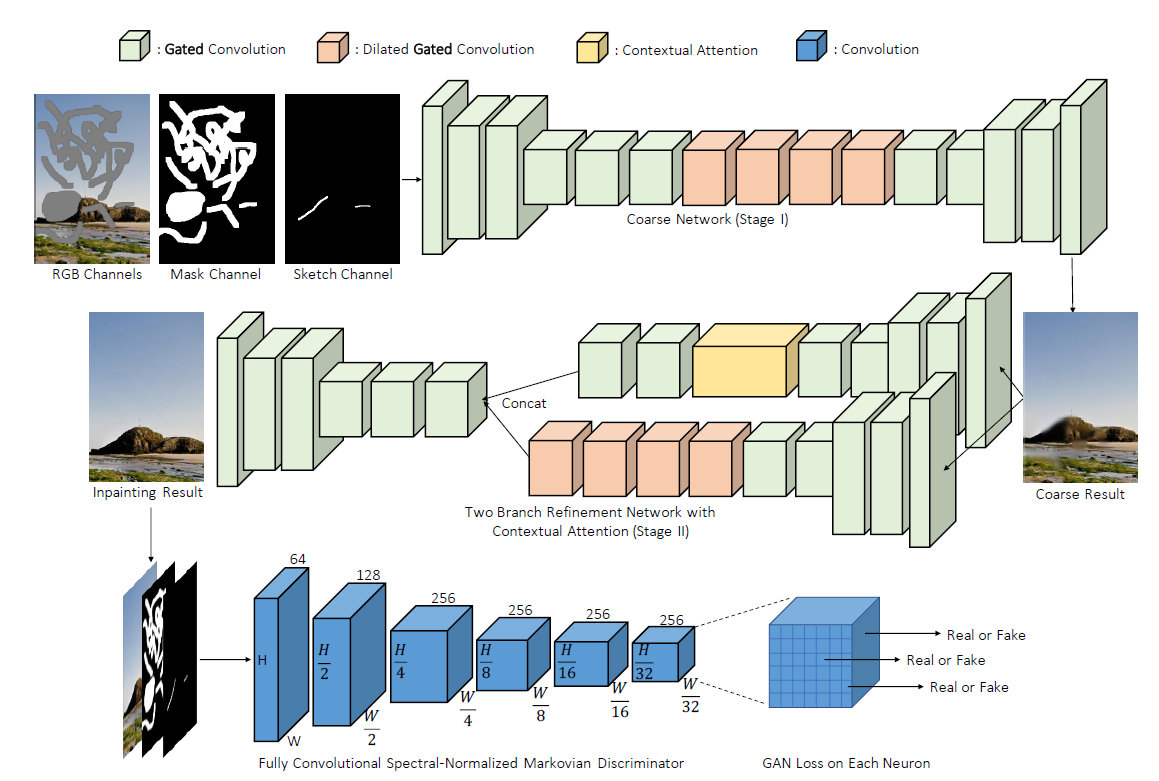
上の2段がGeneratorで、ネットワークとしては1本であるものの、Coarse to fineの構造を持っています(Coarse to fine:一度粗い結果を出してから鮮明化する機構で、構造としてはEncoder-Decoder構成を2つ繋げた形)。
1段目(Coarse側)がConvolution層とDilated Convolution層(間隔の空いたフィルタにより広域情報を取り込み)を繋げた形で、2段目(Fine側)は更に2本に分かれています。手前側は1段目と同様にConvolution層とDilated Convolution層を繋げた形、奥側はContextual Attentionが入った構造になっており、この2本の分岐により、Convolution層による出力結果とContextual Attentionによる出力結果を統合し、より鮮明な出力結果を出す事ができます。
Coarse to fineやDilated Convolution, Contextual Attentionでの2本の分岐などは、一つ前のバージョンであるDeepFillv1[2]と大きく変わらないですが、肝はConvolution層が全てGated Convolution層に置き換えられているという事です。
既存手法として、NVIDIAの強烈なデモで有名なPartial Convolution[3]がありますが、本論文ではPartial ConvolutionによりInpaintingの性能は大きく向上したものの、以下の課題があると述べています。
- マスクのアップデートルールが恣意的(マスク領域でないピクセル数が1ピクセルしかない場合も9ピクセルの場合も次の層では同等に有効なピクセルとしての扱い)
- ルールベースのアップデートによりマスク領域が徐々に消え、深い層まで情報が伝搬しない
- 同レイヤーでは全てのチャネルが同一のマスクを使用しており、ニューラルネットの柔軟性に大きな制限がかかっている
Partial Convolutionのように、マスクのアップデートをルールベースでやるのではなく、アップデート自体をニューラルネットに決めさせるというのがGated Convolutionの思想になります。
以下の図の左側がPartial Convolution、右側がGated Convolutionを表しています。
Partial ConvoutionがBinaryのマスクをルールベースでアップデートしている(マスク領域の縮小操作)のに対し、Gated Convolutionはマスクのアップデート自体を学習するSoft Gatingの形となっています。
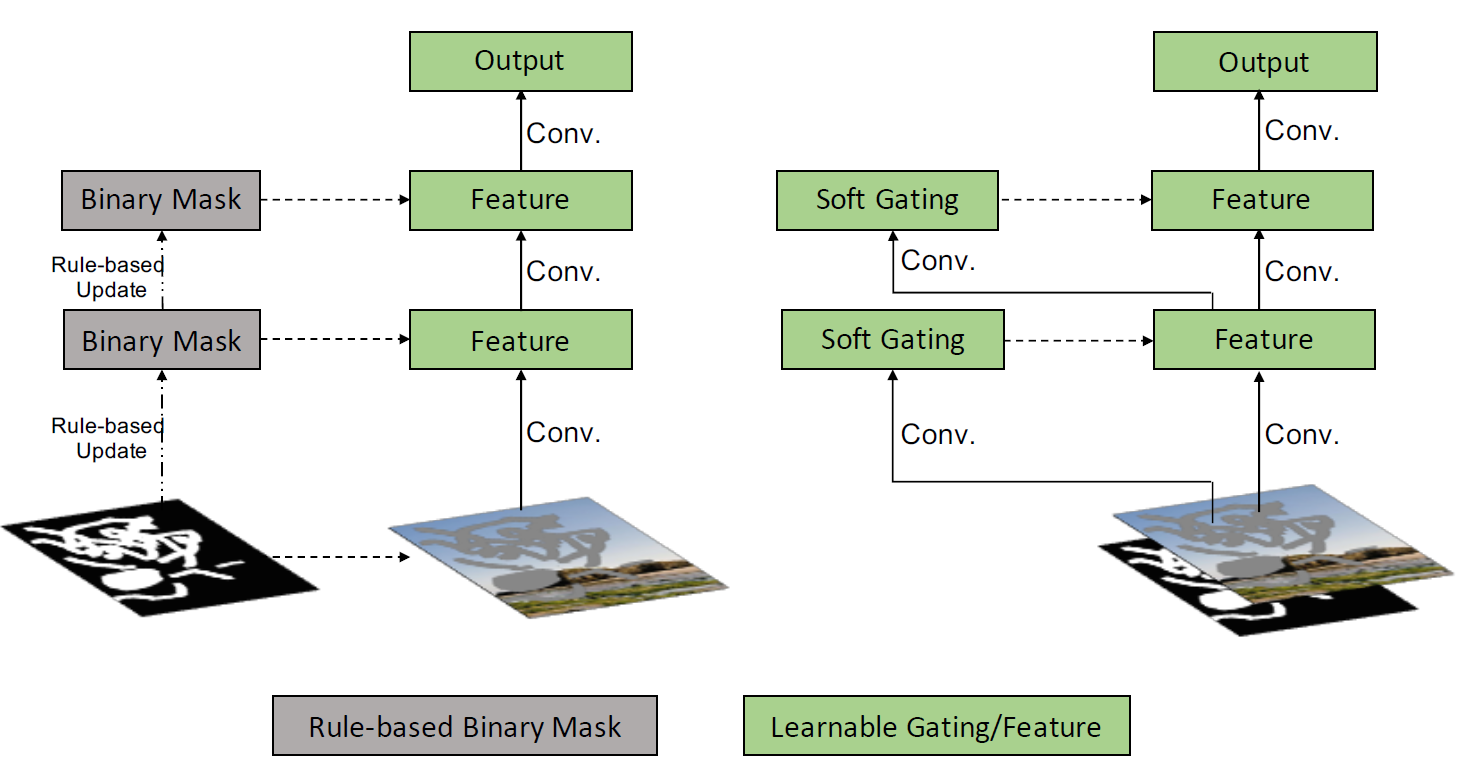
Gated Convolutionの実装自体はシンプルで、通常のConvolutionを適用した後、活性化関数をかける前にチャンネルを半分に分け、一方をReLU等の活性化関数、もう一方をSigmoid関数にかけ(これがソフトマスクの扱い)、その結果を掛け合わせて出力とする形となります。
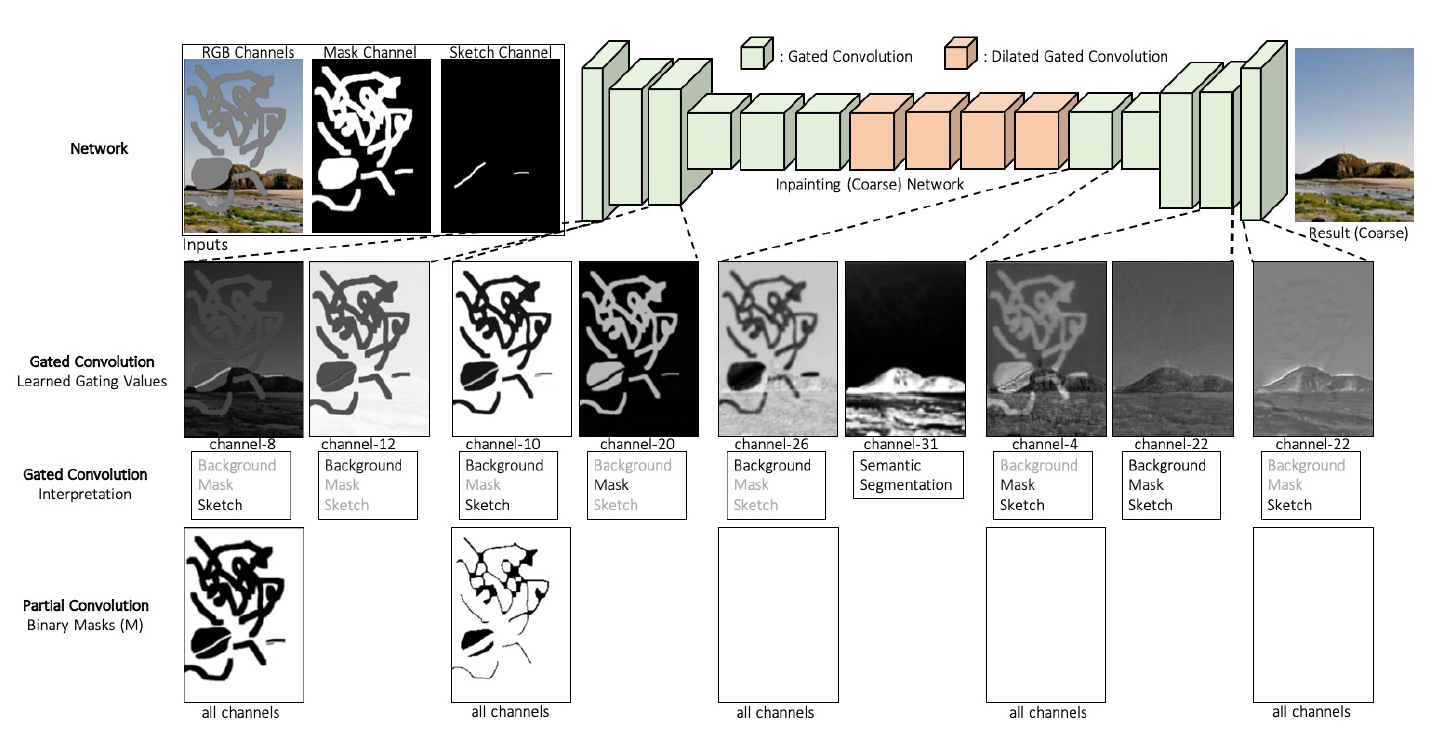
このGated Convolutionにより、深い層でもマスクの情報が消える事なく、またParitial Convolutionのように全てのチャンネルでルールベースでアップデートされる同一のマスクを使用するわけではないため、モデルの柔軟性が大きく向上します(以下、Partial Convolutionとの比較)。
識別機はPatchGANに、spectral normalizationを入れたSN-PatchGANを使用する事で、安定性を向上させています。
デモ1:画像再構成
それでは実際にデモをやって行きましょう。
オリジナルの論文でTensorFlow版のソースが公開されていますが、
Pytorch版のコードが公開されているので、以下のデモではそちらをベースに利用して行きます。
オリジナルのサンプル画像に対して、再構成したい領域のマスクを指定し、そのマスク領域がImage Inpaintingによってどのように再構成されるか見て行きます。

上記画像(多数のオブジェクト指定)に加え、ランドマークとなるオブジェクトの指定、広範囲におけるマスク、欠損領域のマスクなどを以下の画像とマスクのペアで試して行きます。

予測はGPUを使うと、1枚辺り1秒もかからず、通常のCPUでも数秒程度で完了しました。
Image Inpaintingによる再構成の結果は以下の通りです。

マスクの位置にあるオブジェクトを消した上で、周辺の画素から自然な形で画像を再構成できていますね。論文や各種デモを見た時は、実際の所どうかなと思っていましたが、想定を上回る結果でした。右側の再構成画像だけを見せられて、これが人工的に作られた画像である事に気づく人はそうそういないでしょう。
オブジェクトにマスクをかけ、消しゴムのような用途で使用したり、最後の画像のように、一部欠損のあるオブジェクトの修復に利用したりと、様々な用途で活用できそうです。
デモ2:人検出によるオブジェクト自動消去
デモ1でマスク箇所の再構成をやりましたが、対象が多数ある場合などは、正直マスクを1つ1つ手で作るのは面倒です。
対象オブジェクトが決まっているケースを想定し、オブジェクト検出と組み合わせ、マスクの生成からImage Inpaintingによる再構成までを自動化したいと思います。
以下、オブジェクトとして「人」を対象とし、人検出と組み合わせて、インプット画像から人を消すモデルを作って行きます。
人検出にはyoloを使い、yoloの検出結果から人の矩形領域のみを抽出します。その領域をマスクとしてImage Inpaintingへインプットし、画像を再構成します。
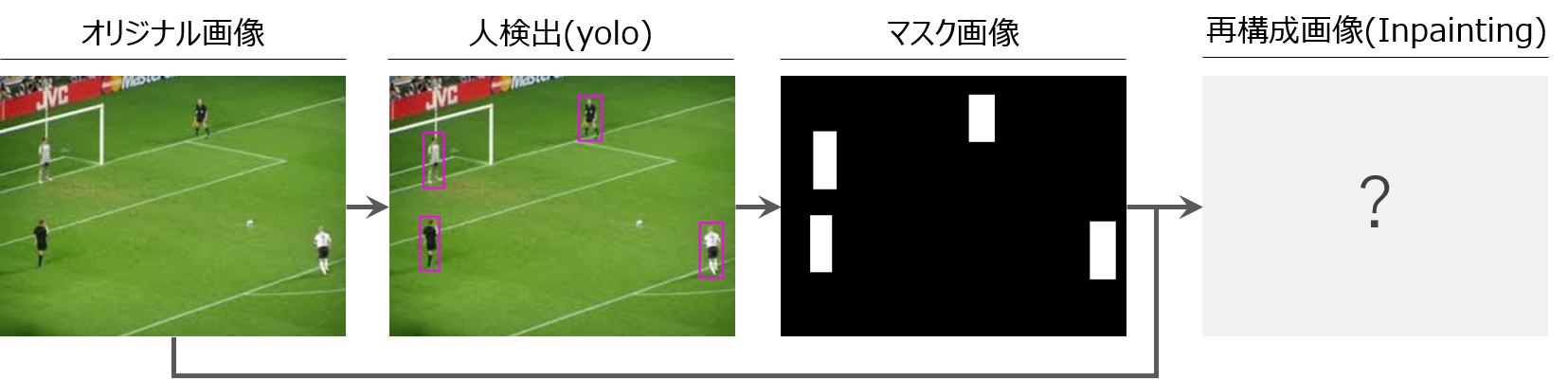
yoloが抽出する人の矩形領域では、手足などの身体の一部が若干外に出るケースがあり、Image Inpaintingではこれが致命的となるため、yoloが抽出した矩形領域を数ピクセル広げる補正をルールベースで入れています。
上記画像に加え、人のサイズや姿勢が異なるケース、多数の人が写っているケースなどで試して行きたいと思います。

デモ1と異なり、マスクは自動生成を期待しているので、インプットはこれらのオリジナル画像のみとなります。yoloがCPUだとかなり時間がかかるので、実行はGoogle Colaboratory上でGPUを使ってやって行きます。
人検出とImage Inpaintingによる再構成の結果は以下の通りです。

1つ1つ手でマスクを作る事なく、人検出から自動生成したマスクがImage Inpaintingへのインプットとして上手く機能しています。
Image Inpaintingの話ではないですが、2つ目のサンプルで影になっていて気付かなかったラインズマン(線審)をyoloが検出しているのが面白いです。
今回は人を対象にやりましたが、対象オブジェクトを変更すれば、画像内の車や動物などのオブジェクトを一気に消したりとこちらも色々と応用できそうです。
まとめ
いかがでしたでしょうか。
実際に色々と試してみた所かなり綺麗に再構成してくれるため、アイディア次第で様々な応用が可能だなと感じました。利用場面がある程度限定されるのであれば、学習画像もそのドメインに特化したものにすれば、より綺麗に再構成できそうです。
一方、オブジェクトの境界ギリギリの情報は非常に重要で、今回の人検出のように矩形領域でまるっと切り取ると情報損失が大きいため、複雑な画像において綺麗に再構成するためには、セグメンテーションによるマスクの作成(どれだけギリギリまで攻められるか)が肝になりそうです。
継続してInpaintingはアップデートしつつ、関連分野であるOutpaintingについてもまた紹介して行きたいと思います。
【論文・コード参考】
・[1] Free-Form Image Inpainting with Gated Convolution
・[2] Generative Image Inpainting with Contextual Attention
・[3] Image Inpainting for Irregular Holes Using Partial Convolutions
・10 Papers You Must Read for Deep Image Inpainting
・DeepFillv2-Pytorch
■参考
デモ
・AI World:DeepLearningを使ったAIのデモサイト
Qiita記載記事
・Deep Metric Learning
・Deep Learning for Image Denoising
・ホテル暮らしはクラウドである
・AIの実業務適用に必須なHITLという考え方と、HITLを加速させるAI×RPA
・RPAの推進に必須なRPAOpsという考え方
・VBAが組める人ならRPAは簡単に作れるという罠
個人ブログ(キャリア・コンサル)
・コンサルティングファームが優秀な人材をどんどん昇格させる本当の理由
・なぜ「コンサルタント」というキャリアはこれほど面白いのか
・キャリアアップのための転職の使い方 ~内部昇格と転職の歪み~
・コンサルタントになりたい人がコンサルファームに長くいてはいけない理由
・未経験からコンサルに転職する場合、必ず頭に入れておくべき1つの事