はじめに
今回は、AIの実業務適用を検討する際に必ず覚えておきたい「HITL(Human-in-the-loop)」という考え方について書いて行きたいと思います。
HITLは元々、宇宙や防衛分野におけるモデリング・シミュレーション方法のひとつとして研究されていましたが、現在では、機械学習やディープラーニングをコアとするAIシステムにおけるプロセスデザイン手法として発展しており、今年話題となった「ダブルハーベスト―勝ち続ける仕組みをつくるAI時代の戦略デザイン」の中でも深く解説されています。
特に、AIにあまり詳しくない業務担当者の方々は、「AIの業務適用」と聞いた時に必要以上に高いハードルをイメージしてしまいがちなのですが、HITLという考え方を持つ事によって、「これなら自分達の業務でも使えるところがあるかも」といった具体的なイメージを持つ事ができるようになります。
AIの導入・展開を妨げる要因は、推進担当者や現場の利用者のAIに対する不理解が大きく、一方で課題は現場にあるため、AIに知見のある技術者だけを雇っても、現場の方々の理解が追い付かなければ実業務適用はなかなか進まないというのが実情になります。
このようなギャップを少しでも埋められるよう、実際の導入経験を元に、HTILの勘所を説明して行きたいと思います。
本記事の要点
- 精度が3割のAIは使い物にならないのではなく、業務を3割削減する効果があると考える
- AIはデータを食べて成長する。使いながら成長させて行くのが最も効率が良い
- HITLの業務適用の鍵となるのは推定信頼度の使い方とUI設計
- AI×RPAはHITLに最適
よくあるAI導入とHITLの違い
それでは本題に入って行きましょう。よくあるAI導入とHITLの違いはどこにあるのでしょうか?
その違いは非常にシンプルで、「フィードバックループがあるか」という事になります。
よくあるAI導入の利用シーンは、「AIにまずは対応させるが、AIが解けない問題は人が代わりに対応する」といったものでしょう。
例えば、自動運転車において、自動運転で対応できない複雑なシーンにおいては、自動運転モードが解除されて人にコントロールが移ったり、コールセンターのチャットボットでは対応しきれない場合に、オペレーターが代わりに対応するといった事も同様で、基本的にはこの構造となります。
一方、HITLにはフィードバックループがあり、現時点のAIモデルで対応できずに人が対応した際のデータは、AIモデルの新しい学習データとなり、フィードバックループによってAIモデルが継続してトレーニングされます。つまり、このAIの継続的な学習過程自体がHITLには組み込まれています。
AIで構築したモデルの精度を静的なものと捉えるのではなく、継続的に向上させる対象として考えるのがHITLのポイントになります。
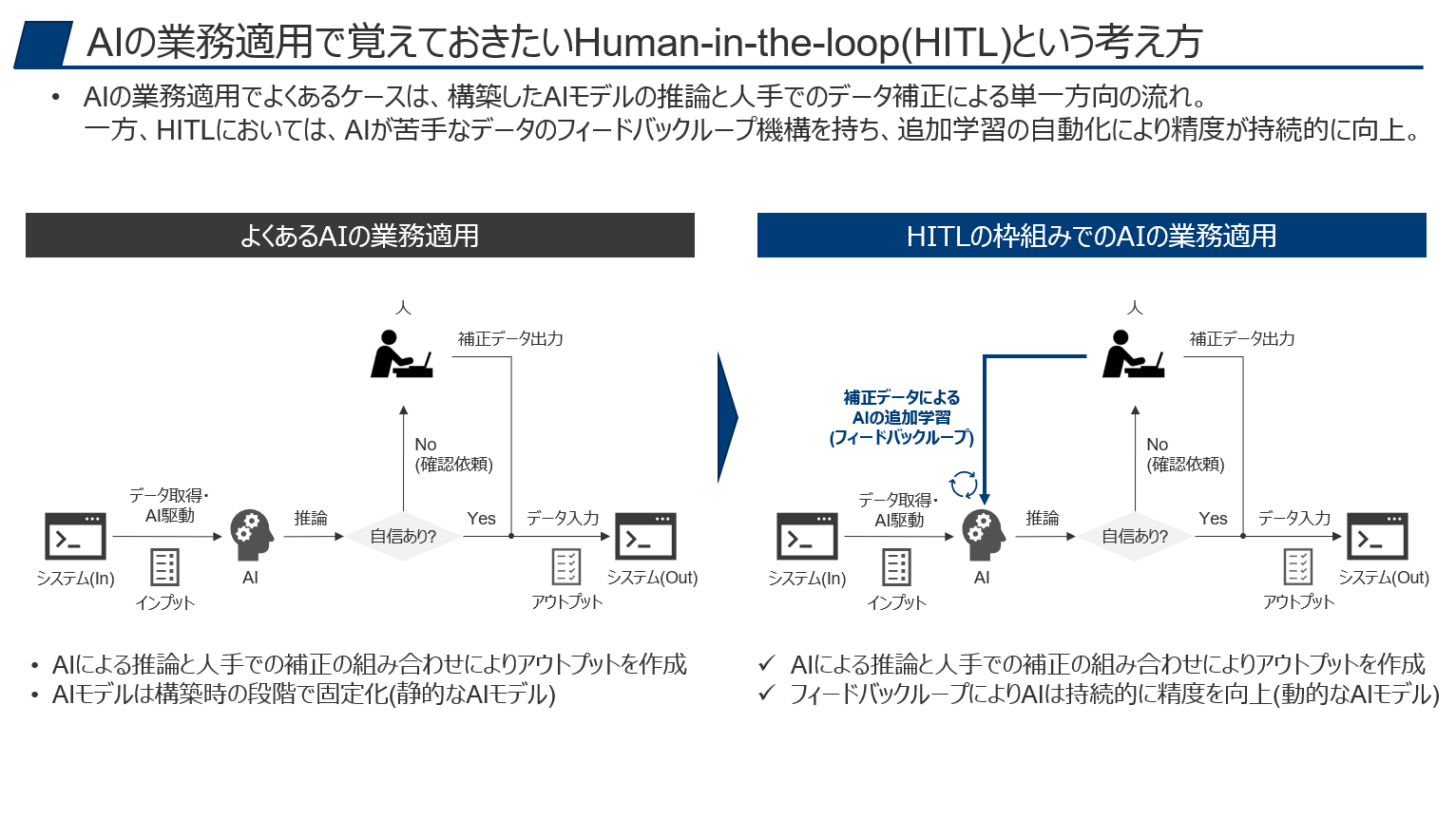
【通常のAIとHITLの違い】
| 通常のAI | HITL(Human-in-the-loop) | |
|---|---|---|
| フィードバック構造 | なし | あり |
| AIモデルの学習 | バッチ | 随時 |
| 精度 | 固定 | 持続的に向上 |
なぜHITLが重要なのか
ではなぜHITLが重要なのでしょうか?
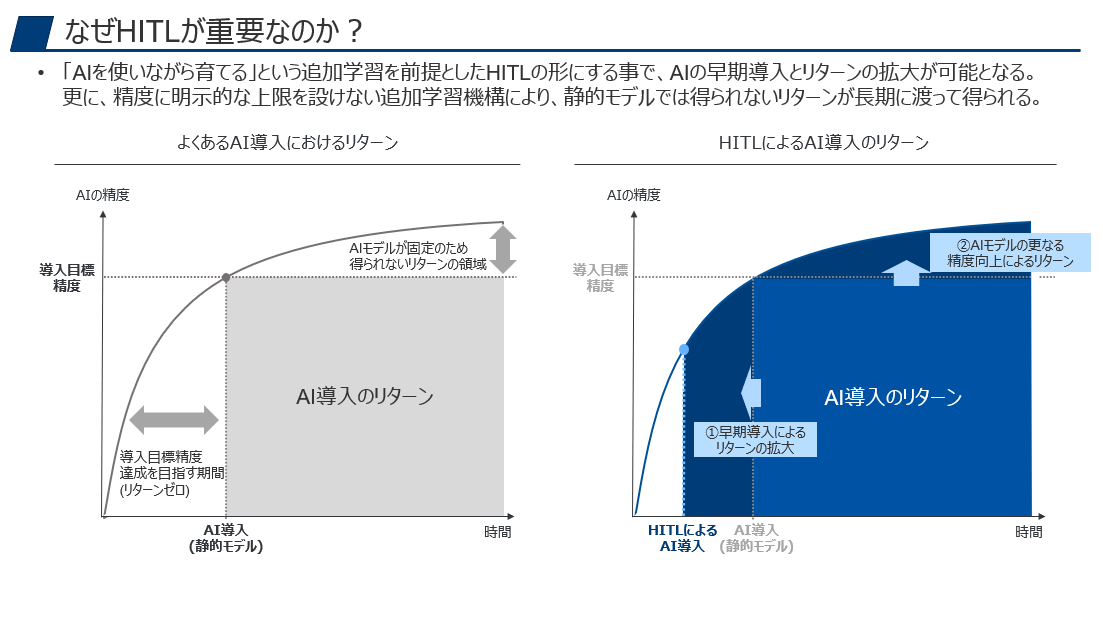
それは、AIを使いながら育てるというHITLの形にする事で、AIの早期導入を可能にしつつ、精度の継続向上により、AI導入のリターンを最大化できるためです。
例えば、ある精度をAI導入の目標値として設定して、AIモデルを構築しようとする場合、目標にした精度に到達するまではずっと訓練・準備期間となり、この間に得られるリターンはゼロになります。
この期間はデータの収集と訓練の試行錯誤を繰り返し、目標の精度を一心不乱に目指します。場合によっては、ここで目標の認識精度まで届かずに導入自体を見送るといったケースもあるでしょう。
実はこれは非常に勿体ない事で、なぜなら、精度が必ずしも高くない状態であっても既に業務上有用なケースは多く、重要な事はAIの精度がいくらかではなく、業務の役に立つかどうかという事だからです。
極端に言ってしまえば、精度3割のAIは、既に業務を3割カットする力を持っています。これは10人で対応していた業務であれば、7人で対応できるようになるという事です。
AIに出来る事は任せて、AIに出来ない事は人が対応する。そしてAIを使いながら育てて行く。このように、最初から完璧を求めず、利用しながらどんどん精度を上げていくというHITLの発想に切り替える事で、初期投資を抑えながらAIの導入時期を早め、リターンを大きくする事ができます。
このようにHITLは、静的なAIモデルと比較すると、投入までのリターンも効いてくるのですが、実は投入後のリターンにも大きな効果があります。
なぜなら、静的なAIモデルは導入時の精度が上限として固定されていますが、HITLでは継続学習の枠組みによってこの上限値を超えて行く可能性があるからです。
例えば、精度90%の段階で導入した静的なAIモデルはずっと90%のままですが、HITLの枠組みであれば90%で固定されるわけではないため、識別率が90%を超え、95%や98%に達する可能性があります。
つまり、HITLは静的なAIモデルの精度面での機会損失を最小化する枠組みであると考える事もできるでしょう。
目標の精度に達しない限り使わないというのも非常に勿体ないのですが、目標の精度に達したらそれ以上は目指さないというのも非常に勿体ない話です。HITLの枠組みであればこのような制約を取り払い、リターンを最大化する事ができます。
HITLの鍵となる推定信頼度の使い方とUI設計
「そうは言っても精度が低い状態のAIの結果を信用して良いのだろうか」「結局人手でチェックするのであれば労力は変わらないのでは?」と思われる方も少なくないようです。ここでポイントとなるのが、HITLの枠組みの中の「自信あり?」の分岐にあたる推定信頼度の使い方と、ユーザーに確認の負担を軽減するUI設計です。
それではまず、自分が業務ユーザーになったつもりで少し考えてみましょう。
「このAIは80%の精度で正解を返してくれます。どうぞ使って下さい」と言われたらどうでしょうか?
「80%って事は、20%間違うって事だよな。。えーっと、どう使えばいんだろう。。」と困惑してしまうのではないでしょうか。どの仕事を任せても2割ミスする部下に仕事を任せるのは当然不安でしょう。
先に答えを言ってしまうと、このように全体の精度で議論する事に実はあまり意味はありません。なぜなら、精度80%というのは簡単な問題も難しい問題も合わせた全ての正解率の平均値であるからです。AI導入の場面では全体の精度ではなく、推定信頼度を軸に議論する事が重要になります。
推定信頼度とは、要するに「AIが自分の推定結果にどれだけ自信があるかを0.0-1.0の範囲で数値化したもの」です。アルゴリズムの選択にもよりますが、基本的にAIのアルゴリズムは、この推定信頼度を出す事ができます。
例えば3クラス分類問題(A, B, C)を考えた場合、単純に、「このクラスはAである」と回答させるのではなく、「クラスAである確率が90%, クラスBである確率が7%, クラスCである確率が3%」といった具合です。
実は、全体の精度がそれほど高くないケースでも、推定信頼度に分解してみる事で、その見え方が大きく変わってきます。
以下、簡単な例を見てみましょう。
AIの精度としては80%なのですが、推定信頼度に分解して見てみると、推定信頼度0.9以上は精度100%, 0.8-0.9は精度97%, 0.7-0.8は精度95%であり、データの累積で見ると、78%のデータはこの推定信頼度0.7以上の区間に収まっています。一方で推定信頼度が0.6になると、精度が40%まで下がっている事がわかります。
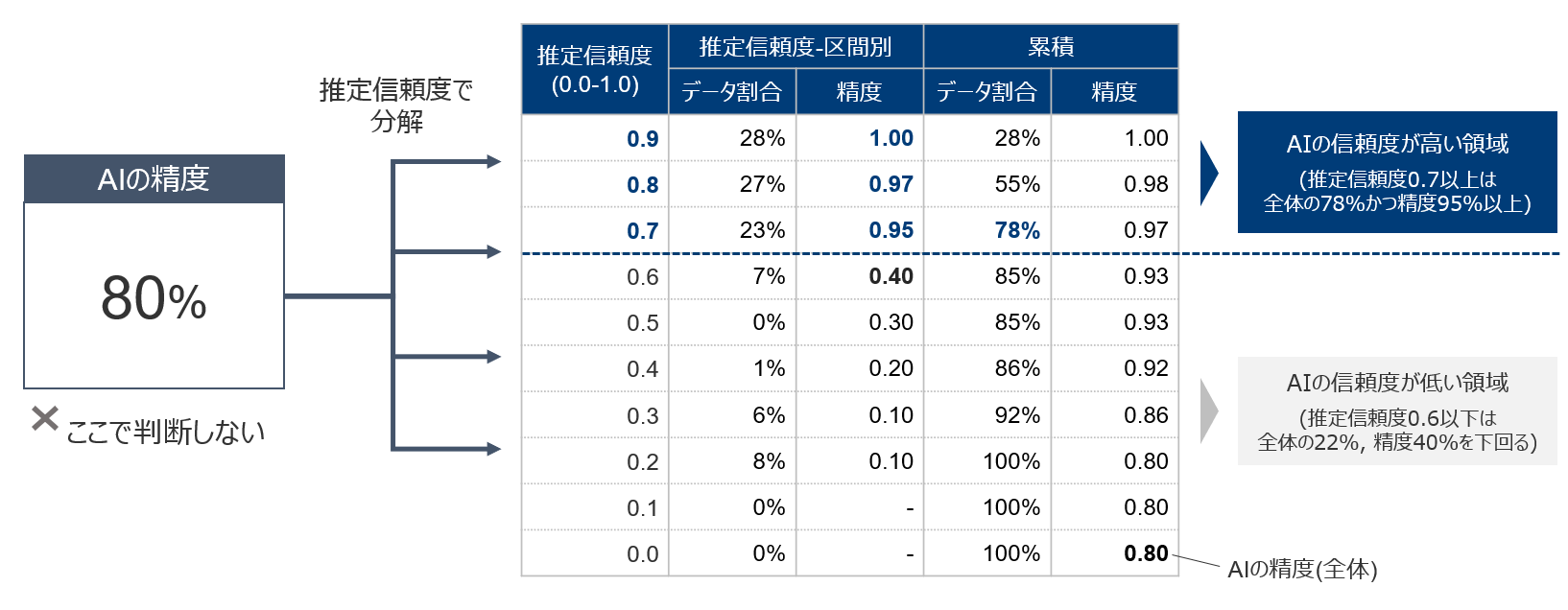
つまりこの例では、AIの信頼度が高い、信頼度0.7以上(全体の78%)はAIに任せる、又は簡単なチェックだけを実施し、信頼度0.6以下(全体の22%)は誤りである可能性が高いため、重点チェックとすれば良いでしょう。全体の正答率を80点としてひとまとめにして捉えるのではなく、このように推定信頼度に分解する事でAIの利用に強弱をつけられるようになります。
5教科平均60点の生徒がいた場合、ぱっと見普通の生徒に見えますが、教科別に見てみると、国語・数学・英語が100点で、理科と社会が0点のケースかもしれません。この場合は、国語・数学・英語を任せない手はないでしょう。
そして、HITLではユーザーの確認・補正における負担をどれだけ減らせるかという、データ確認と補正時のUI設計がもう一つ重要なポイントになってきます。そして、ここでも推定信頼度が活きてきます。
以下、文章の10クラス分類のケースで見てみましょう。
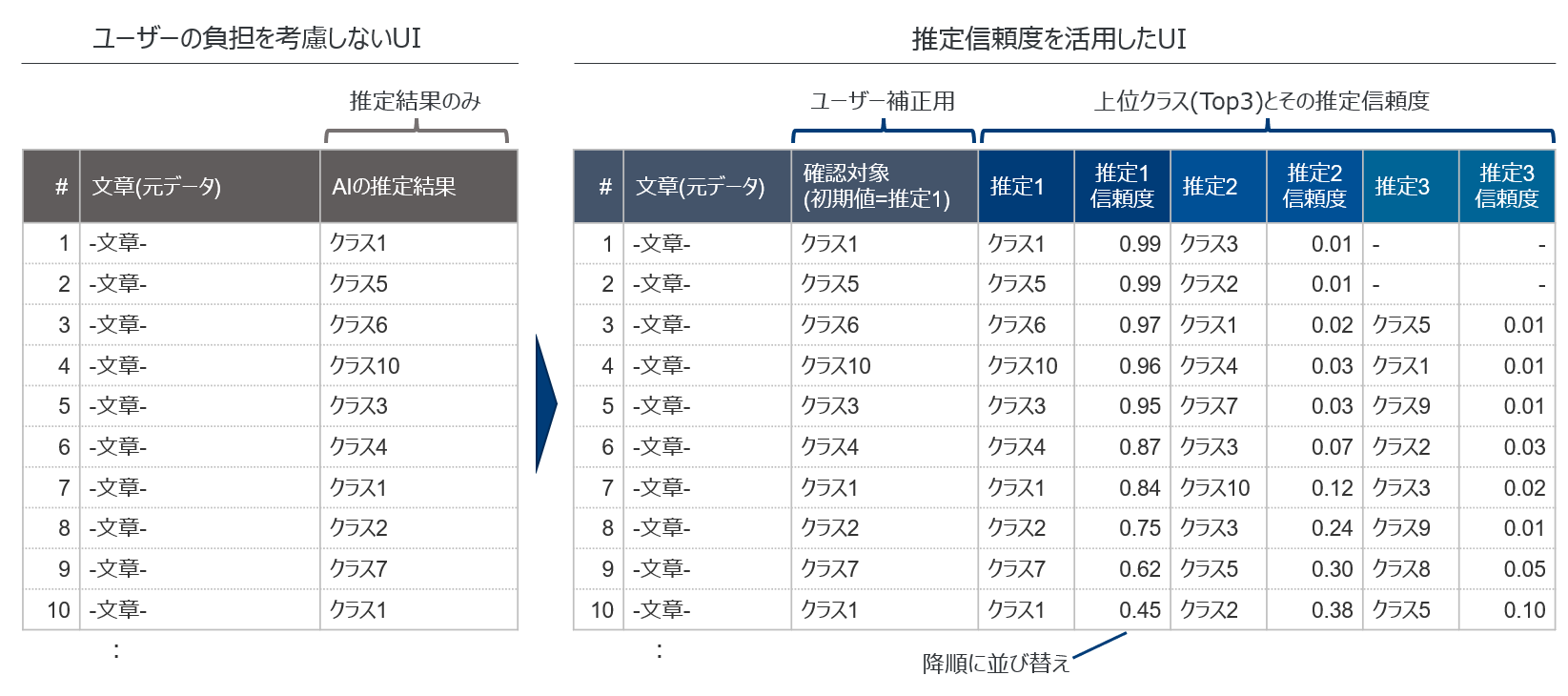
最悪なUI設計は左の例のように、単純にAIの推定結果だけを返す形です。これでは、AIの精度がどれだけ高かったとしても、1つ1つチェックしなければならないので、ほとんどAIを導入した意味がないに等しいでしょう。
一方、右側の例では推定信頼度を用いた結果の表示によってユーザーの確認・補正が容易となっています。まず、最も可能性が高いクラスの推定信頼度で降順に並べ替えているため、推定信頼度は高いところはざっと確認して、推定信頼度が低い所は重点的に確認といった強弱がつけられるようになります。部下に仕事を任せた場合で言うと、「こことここだけ少し不安なので見て頂けますか?」といったように返してもらう形ですね。
更に、推定結果の最上位クラスだけでなく上位クラス(Top3)とその信頼度も提示させています。実は、最上位クラスだけだと正解率80%であるものの、最上位とその次のクラスまでに含まれる確率だと95%を超え、Top3まで入れると99%といったケースも多くあります(上位何クラスまで提示するかはクラス別の精度を見て判断)。
このように最上位クラスの推定信頼度が低いケースにおいても、可能性の高い上位候補を提示してくれているため、ゼロベースで確認するより非常に楽になります。
ユーザーに結果を提示するUIに推定信頼度を活用する事により、大部分を占める推定信頼度の高い箇所はざっと確認し、少数の推定信頼度の低い箇所は提示された上位クラスを中心に確認・補正ができるため、ユーザーの負担を大きく軽減する事ができます。
そして、ユーザーによって補正された箇所はHITLにおいて貴重な追加学習データとなるため、次回は正解となる事でしょう。AIを使いながら育てるというHITLの枠組みにおいては、AIのモデル構築と同様に(場合によってはそれ以上に)、ユーザーの確認・補正作業を楽にするUI設計が重要になります。UIが良ければ、ユーザーもどんどん使ってくれるため、AIの成長も更に加速する事でしょう。
HITLに最適なAI×RPA
さて、HITLの枠組み自体はここまでで概ねイメージできたと思いますが、実際にHITLを業務へ適用を検討してみようとするとぶつかる壁があります。それは、**この全体処理をどうやって繋いで自動化するのか?**という事です。
絵で書くと簡単なのですが、実際の業務適用と考えると以下のように大きく4箇所の検討が必要になる事がわかります。
■HITL適用で検討が必要な4つのポイント
- AIモデルへ入力するデータの取得とAIの推論処理の駆動
- 人に判断を仰ぐデータの連携とUIを考慮した整形
- AIモデルと人の補正データの統合とシステム入力
- 人手によって補正されたデータの取得とAIの追加学習処理の駆動
つまり、AIはあくまで脳にあたるので、その前後作業のお膳立てが必要にあります。Pythonで完結できる範囲であれば良いものの、実際にはAPIがないシステムの操作やユーザーへの結果の提示、追加学習の自動実行処理など、Python単体では届かない、または管理が煩雑になるケースがあります。
ここにRPAを使う事で、脳であるAIに対して、RPAが手足としての威力を大きく発揮します。
■HITL適用におけるRPAの利用
- システムからデータを取得して、AIの推論処理をキック
- ユーザーが確認・補正しやすいUIでの結果連携
- AIとユーザーの出力結果を統合し、システムへ入力
- AIが学習可能な形式に追加学習データを変換し、AIの追加学習処理をキック
RPA経験者であれば「余裕だなこれ」というイメージがすぐに湧くでしょう。
このように、AIという「脳」と、RPAという「手足」を組み合わせる事でHITLの枠組みを簡単に構築し、自動化する事ができます。
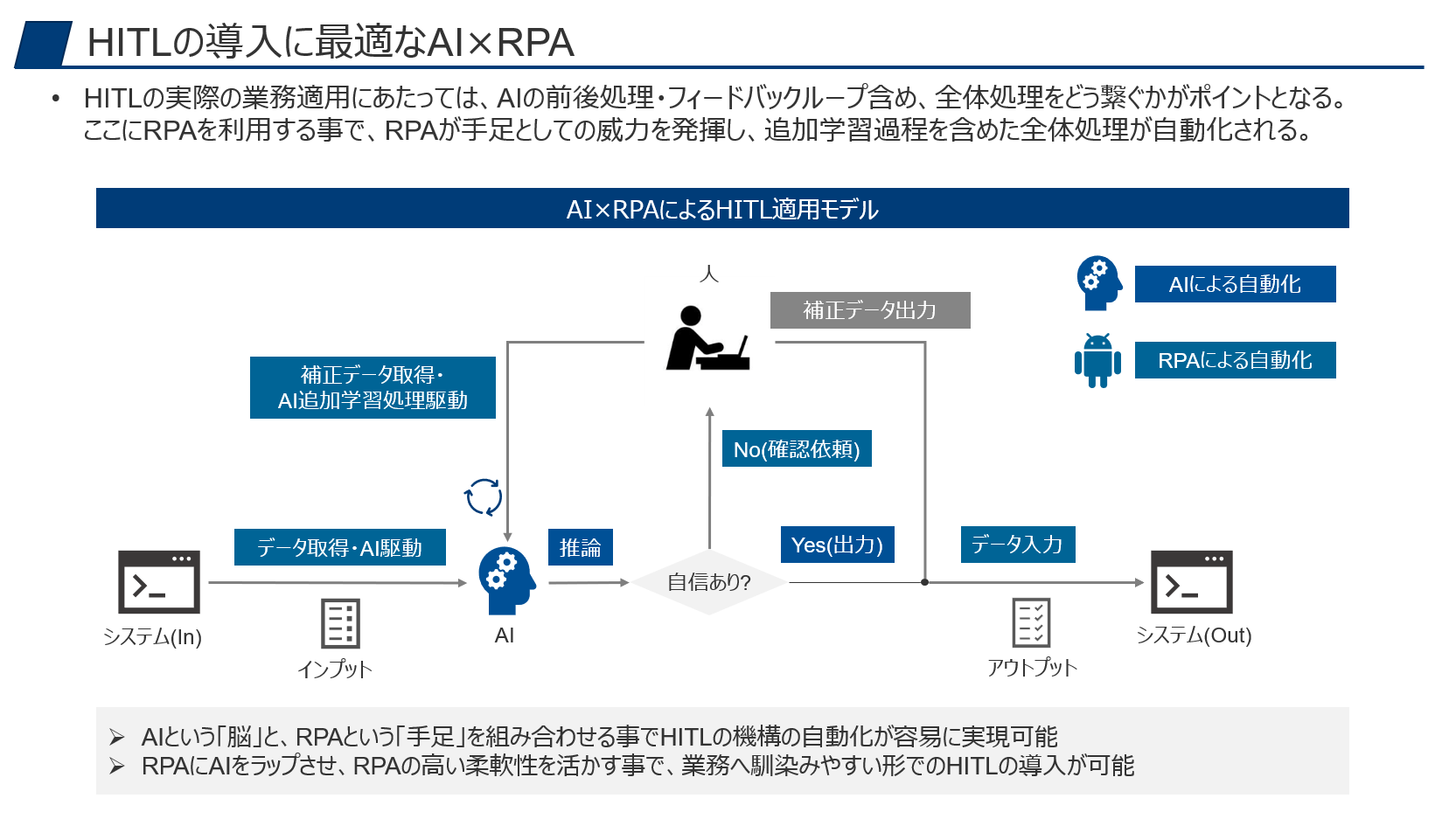
PythonはあくまでAIモデルに集中させて、前後処理はRPAにやらせる事で全体の見通しが良くなる上に、RPAに標準搭載されている自動実行のスケジューリングや実行管理(ログ出力, エラー検知)など管理統制面でもメリットが出てきます。また、AIモデルの前後作業をRPAでラップする形にする事で、業務への馴染みが良くなり、ユーザーとしてもごく自然にAIが業務で利用できる形になる(良い意味でAIを意識しなくて良い)でしょう。
実際に私がAIモデルを組んで、業務適用をしようとした際、「AIのモデルができたのは良いけど、そもそもAIの前と後ろのシステムにAPIないんだよな。。ユーザーに補正してもらった追加学習用データもどうやって取りに行こうか。。」と頭を悩ませた時期があったのですが、RPAを使った事でこのような課題が一気に解消し、AI単体でやっていた頃に比べ、AIにRPAという手足を付けられる有難さと、AIとRPAの相性の良さ(棲み分けの良さ)を身に染みて感じました。
実際の業務利用におけるユーザーからのフィードバックをもらった所、AIの精度の高さに驚いたという意見と同じくらい、データの入出力やグラフ作成までRPAがやってくれて非常に助かっているという意見をもらい、単体利用ではなく、AI×RPAの組み合わせの効果の高さと業務への馴染みの良さを感じました。
しばらく経った頃、「最近AIの精度が更に高くなってきて、もうほとんど修正も不要になりました!ありがとうございます」という有難いお言葉を頂きました。HITLの枠組みにより、その時既に私の手を離れたAIがユーザーの指示のもとで成長していたようです。
まとめ
いかがでしたでしょうか?
AIの実業務適用時に有効なHITLとその勘所、HITLにおけるAI×RPAの活用について解説しました。
AIの知見や機械学習のバックグラウンドがない方々とAI導入の話をすると、話を大きく捉えすぎてしまい、議論だけが長引いたり、全体の精度だけを見て導入か見送りかのゼロイチの議論によくなってしまいます。しかし、AIの精度が100%になる事はそもそもないので、基本的には人とAIの分担におけるグラデーションの議論であり、ここが本当の頭の使いどころ(腕の見せ所)になります。
AIだからと特別に考える必要はなく、これは新しい部下が入ってきた時と同じ話で、出来るところは任せて、出来ない所は教えてあげれば良いだけです。次第に成長してどんどん仕事を任せられるようになって行くでしょう。
HITLという考え方を1つの材料としてAIの導入を加速させ、AIが誰にとっても身近な存在となり、これまでAIに詳しくなかった人達からも様々なAI活用のアイディアが出てくる、組織として更に大きなループが回るきっかけの一助になれば幸いです。
<参考>
参考書籍
・ダブルハーベスト-勝ち続ける仕組みをつくるAI時代の戦略デザイン
・現場が輝くデジタルトランスフォーメーション-RPA×AIで日本を変える
Qiita記事
・【AI】Deep Metric Learning
・【AI】Deep Learning for Image Denoising
・【AI】Deep Convolutional Autoencoderベースの教師なし異常箇所検知
・【AI】Deep Learning for Image Inpainting
・AIによる自動応答機能付き「名言Bot」
・RPAは誰でも簡単に作れるという罠
・VBAが組める人ならRPAは簡単に作れるという罠
・UiPathのコーディングチェックツールを作ってみた【RPA】
・RPAへの理解がぐっと深まる、RPAがよくこける理由
・RPAのオススメ書籍
・RPAの開発に向いている人、向いていない人
・寿司打を自動化してみた
・RPAの推進に必須なRPAOpsという考え方
デモ
・AI World:DeepLearningによるAIのデモサイト
・UiPathCodingChecker:UiPathのxamlファイルからコードを分析