はじめに
AIによる自動応答機能付きの名言Botを作ってみました。
設定した時刻での名言の自動配信とお気に入り登録、お気に入りに登録した名言の通知機能もあります。
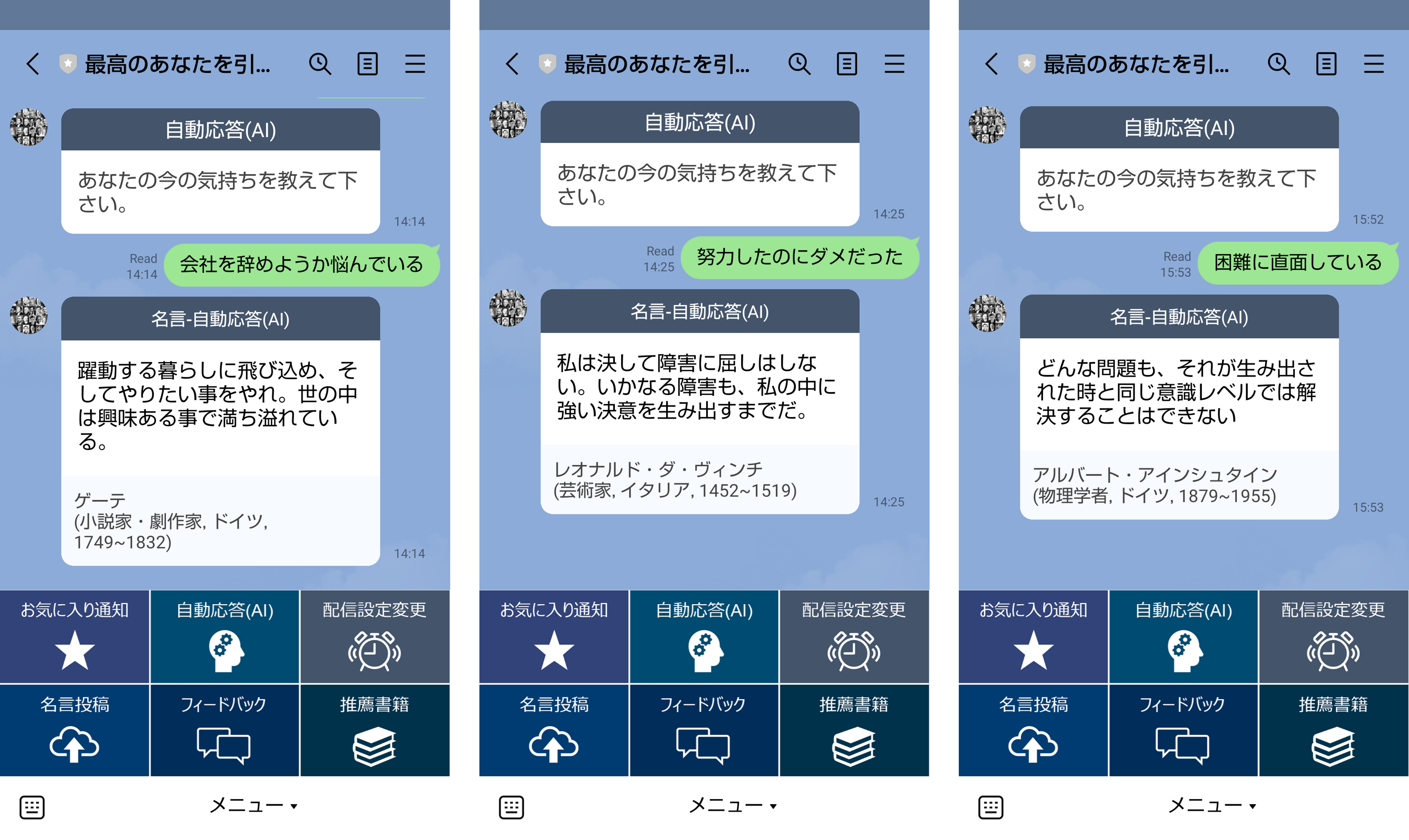
■AIによる自動応答
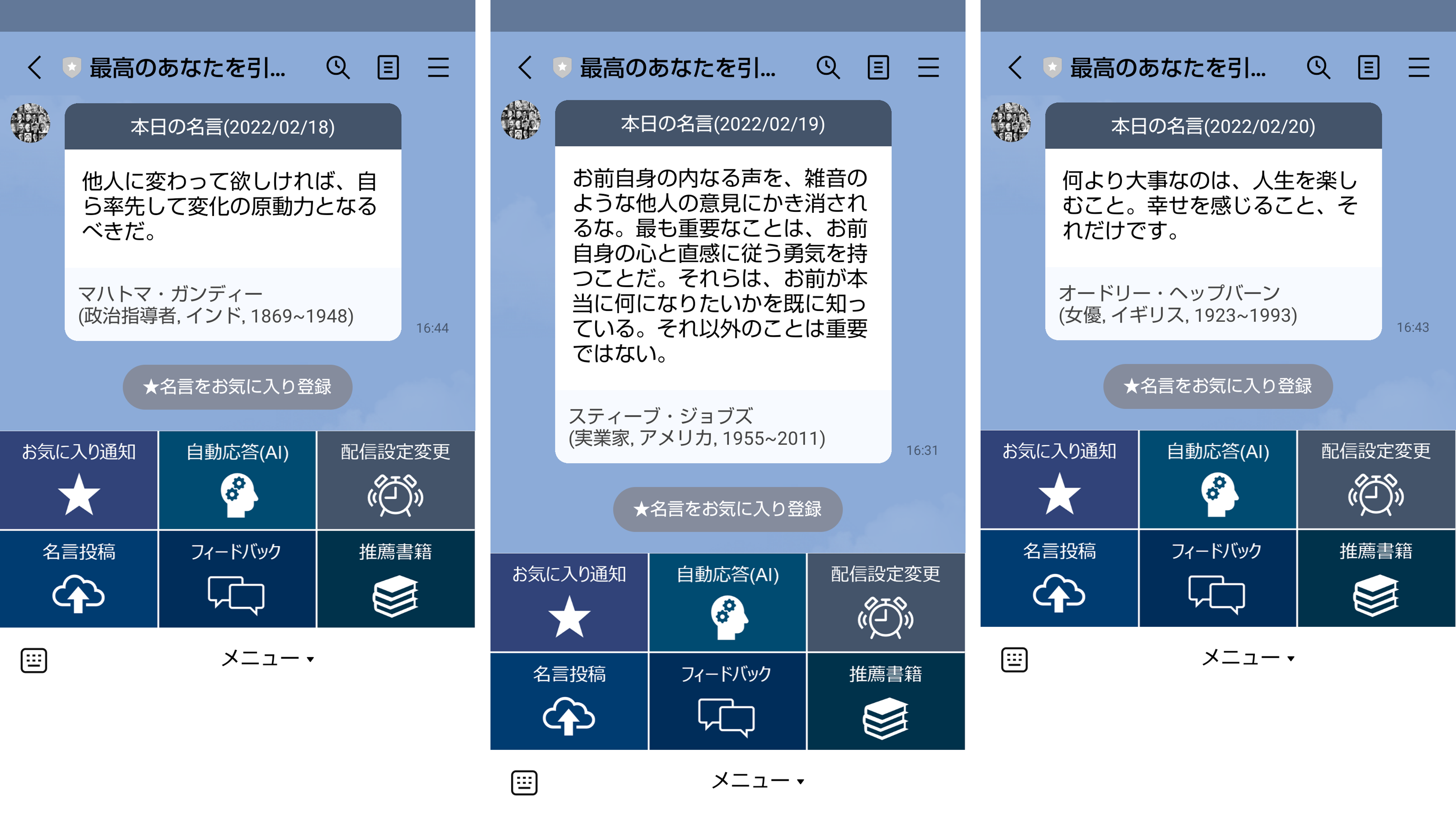
■名言の自動配信とお気に入り登録
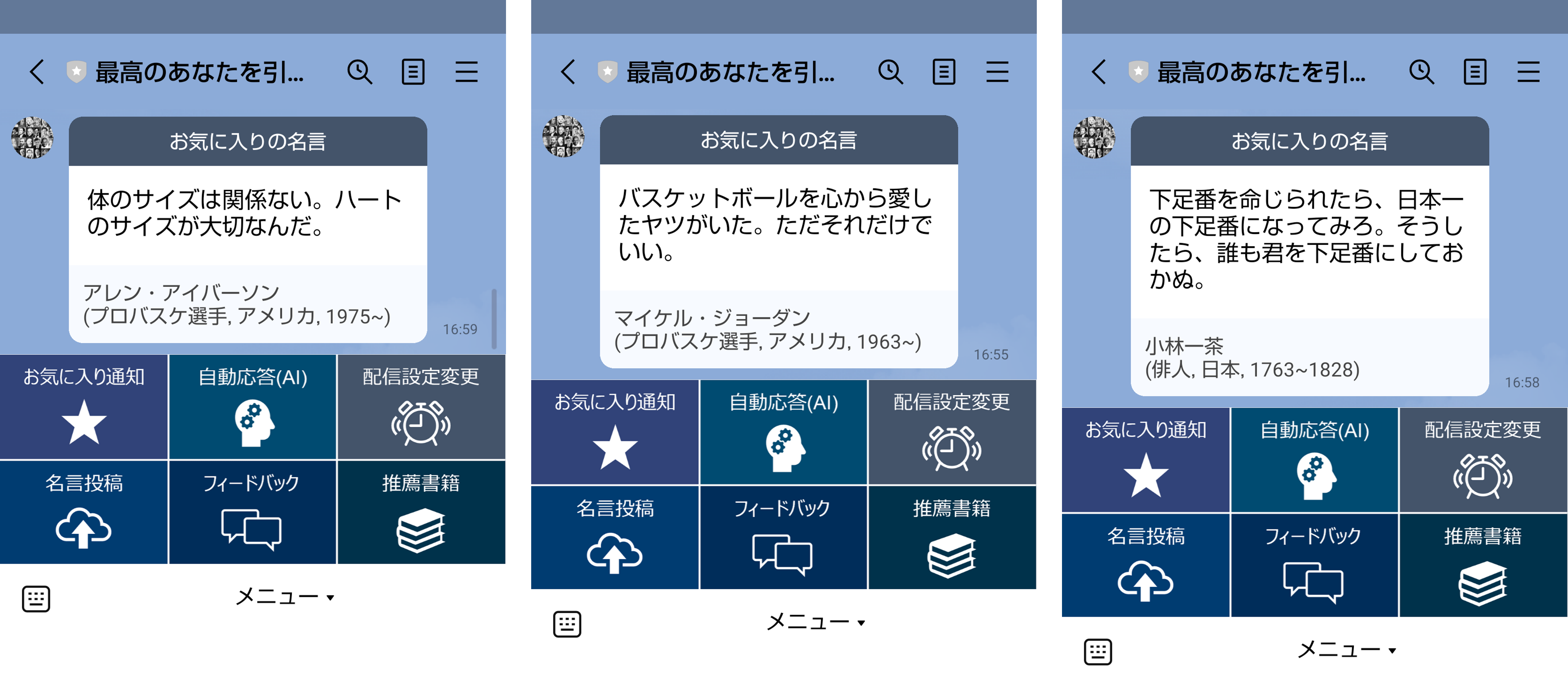
■お気に入りに登録した名言の通知
■利用方法
以下のLineの友達追加ボタンから誰でもすぐに利用できるので、良かったら遊んでみて下さい。 ※PCで閲覧中の方は、表示されたQRコードを読み取って下さい。
フィードバック機能もあるので、色々とフィードバックを頂けると嬉しいです。
利用環境
- Python
- AWS(Lambda, EventBridge, DynamoDB, ECR, API Gateway)
- Line(Messaging API)
- Docker
- NLP(BERT)
開発の背景
本Botを開発してみようと思った背景は、大きく以下の2点です。
- 日々のモチベーションの向上
- メタ認知力の強化
1. 日々のモチベーションの向上
知らないという人が大半である事を承知の上で、わかる人にはめちゃくちゃ刺さるのであえて書きますが、みなさんはパワプロの育成モードをやった事があるでしょうか?
パワプロの育成モードは、様々な練習メニューや試合などを通して、選手を育成して行くゲームなのですが、非常に重要なパラメータとして、選手の「やる気」が存在します。
ランダムに発生する様々なイベントで、このやる気は上がったり下がったりを繰り返すのですが、やる気の低い状態で練習に取り組んでも経験値はほぼ入らず、やる気がMAXの状態であれば大きな経験値を得る事ができます。
つまり、この育成モードで強い選手を育てられるかどうかは「いかにやる気が高い状態を保てるか」という事がポイントになってきます。育成初期の能力値が同じでも、やる気が低い状態が続いた場合と、やる気が高い状態を長く保てた場合では、育成終了時にとてつもない差が出ています。
ちなみに私がやっていたバージョンでは、裏技で常にやる気をMAXに保つ方法があり、その時の育成では、リアルに大谷のような選手が出来上がりました。
これはあくまでゲームでしたが、結局この「やる気(モチベーション)」をどれだけ高い状態で維持できるかは現実世界においても永遠のテーマではないかと思います。
むしろ現実世界のほうが死活問題で、同じ自分でも、モチベーションが高い状態で日々を過ごしたか、低い状態で日々を過ごしたかで、数年後にはとてつもない差が出るため、モチベーションの向上と維持を後押しする方法はないかなと考えていました。
モチベーションが大きく高まる瞬間の1つとして、尊敬する人や著名な方の講演や動画、本などに触れた直後があると思います。
この瞬間は、「自分もやるぞ」と意気込み、一時的にモチベーションがぐっと高まるのですが、しばらく時間が経つとモチベーションが元の状態に戻っている、という事を皆さんも経験した事があるのではないでしょうか。
つまり、あの状態を疑似的に毎日作れないかなと思い、モチベーションを高めてくれる、偉人達が残した名言に日々触れられる環境を作ってみたいなと思ったのが開発の背景の1つです。
2.メタ認知力の強化
テレビが市場に出た際に「一億総白痴化」という言葉が生まれましたが、スマートフォンを手にした現代社会に生きる我々は、更にその深刻度が増しているのではないかと以前から感じていました。
というのも、これだけ様々な情報が意識せずとも目に飛び込んでくる日々の中で、1日を振り返った時に、「どれだけ自分の頭を使って集中して思考が出来たのか?」「自分の思考を言語化したり、自己との対話で自己認識を高めたりといった事(メタ認知)がどれだけできたか?」という事を考えると、相当意識的にやろうとしないと、かなり難しくなっているなと感じたためです。
自分自身もそうですが、部下や後輩達と話していても、自分の思考がうまく言語化できなかったり、本人の事を聞いているのに本人が答えられない(あまり考えたことがない)というケースも少なくなく、「情報量が多くなった一方で、能動的な思考の機会が減り、思考力、特に自己認識力が落ちているんじゃないか?」と危惧するようになりました。
そんな中、我々とは生まれた時代も国も全く違う哲学者や思想家、現代に名を残すスポーツ選手やアーティスト、実業家などの言葉は、様々な示唆に富み、一度立ち止まって自分の頭で考える、メタ認知の機会として絶好ではないかと思いました。
過去や現代を生きる偉人達の言葉や思考に触れ、忙しい毎日の中で、少し根本的なところを自分の頭で考えるきっかけにしたいなと思ったのがもう一つの背景です。
機能一覧
現在の機能の一覧は以下の通りです。
- 名言の自動配信
- お気に入りの名言の通知
- 好きな名言のサービスへの投稿
- AIによる名言の自動応答
- サービスへのフィードバック
- 推薦書籍紹介
以下、各機能の内容を簡単に紹介して行きます。
1.名言の自動配信
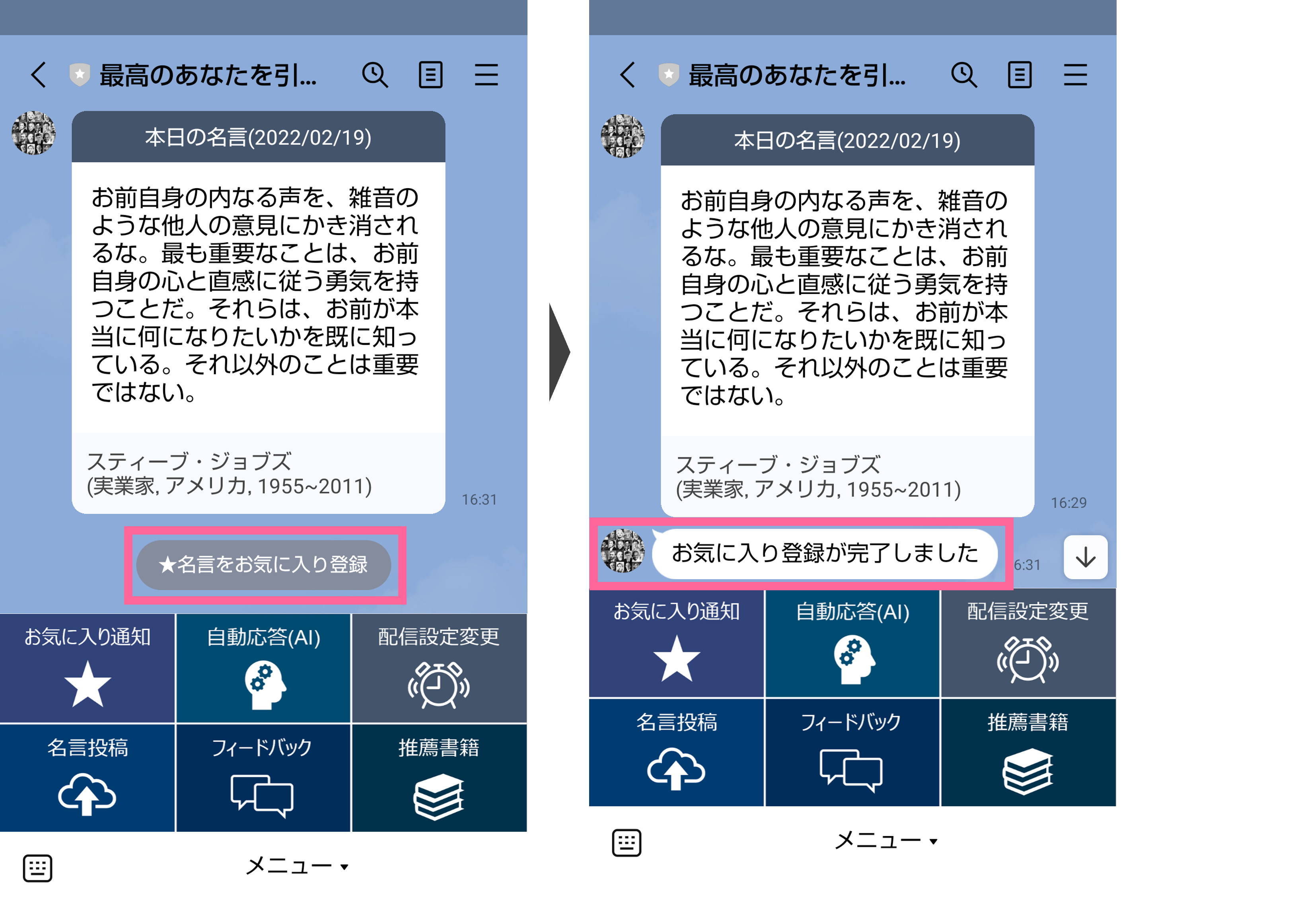
配信設定された時刻に1日1回、サービスに登録された名言がランダムに配信されます。
デフォルトの配信設定は毎朝6時ですが、メニューの「配信設定変更」ボタンから、配信日と配信時刻の設定をいつでも変更できます。
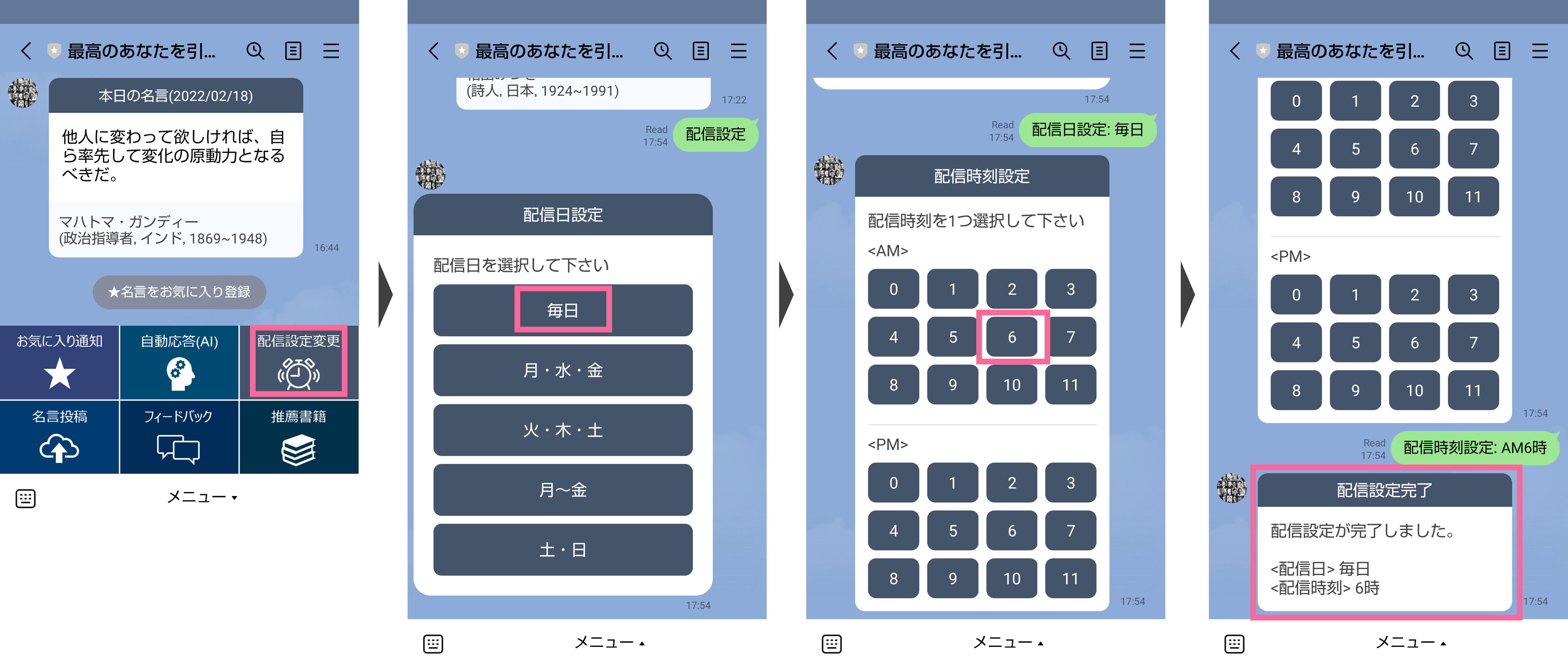
また、配信された名言の下のお気に入り登録ボタンから、随時、名言をお気に入りに登録する事ができます。週の最終配信日(毎日配信の場合は日曜)は、お気に入りに登録された名言の中からランダムに1つ選ばれたものが配信されます。
2.お気に入りの名言の通知
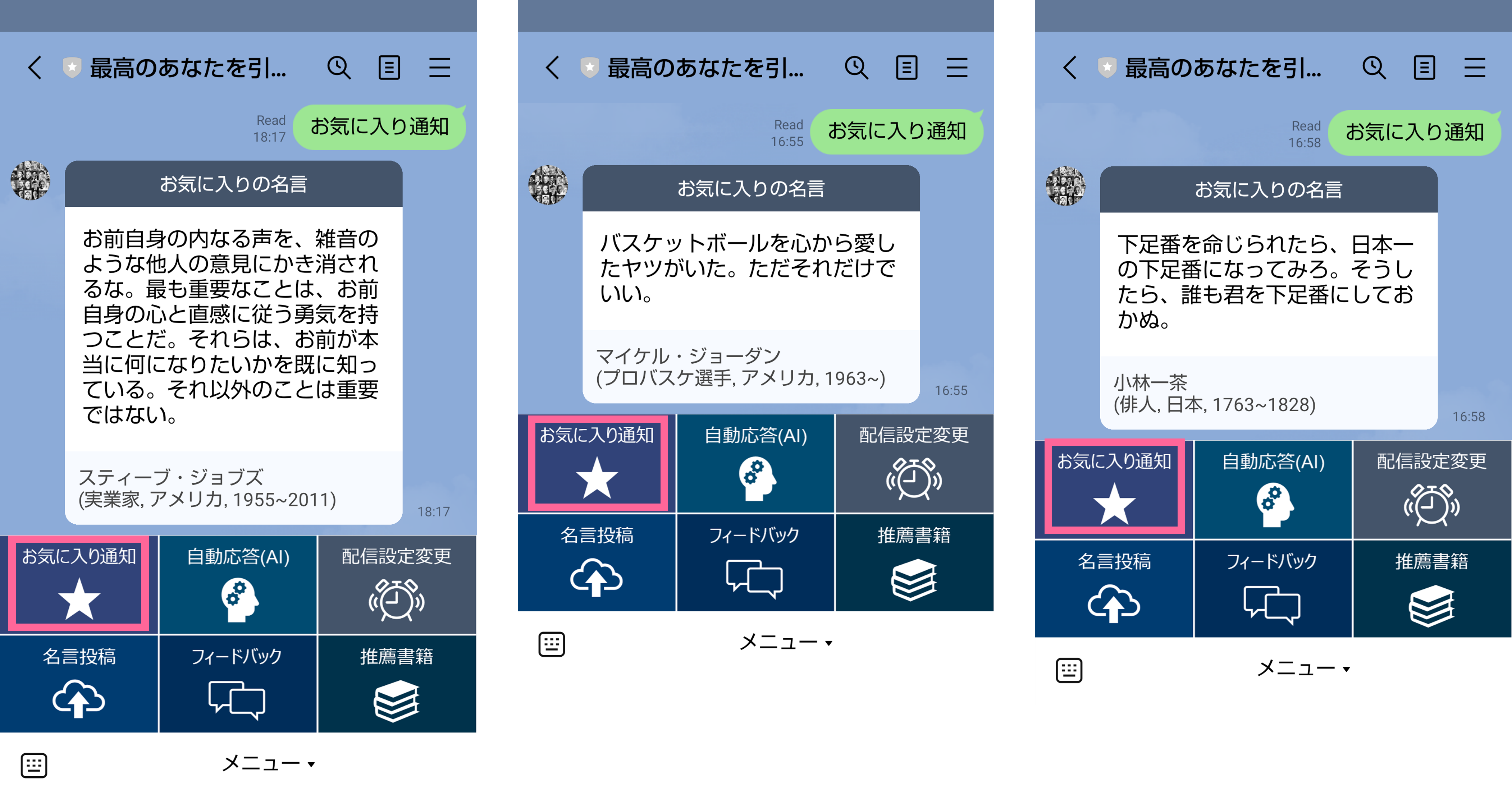
お気に入りに登録された名言は、メニューの「お気に入り通知」ボタンからいつでも通知できます。ボタンの押下毎に、お気に入りに登録された名言の中から、ランダムに1つ選び通知します。
3.好きな名言のサービスへの投稿
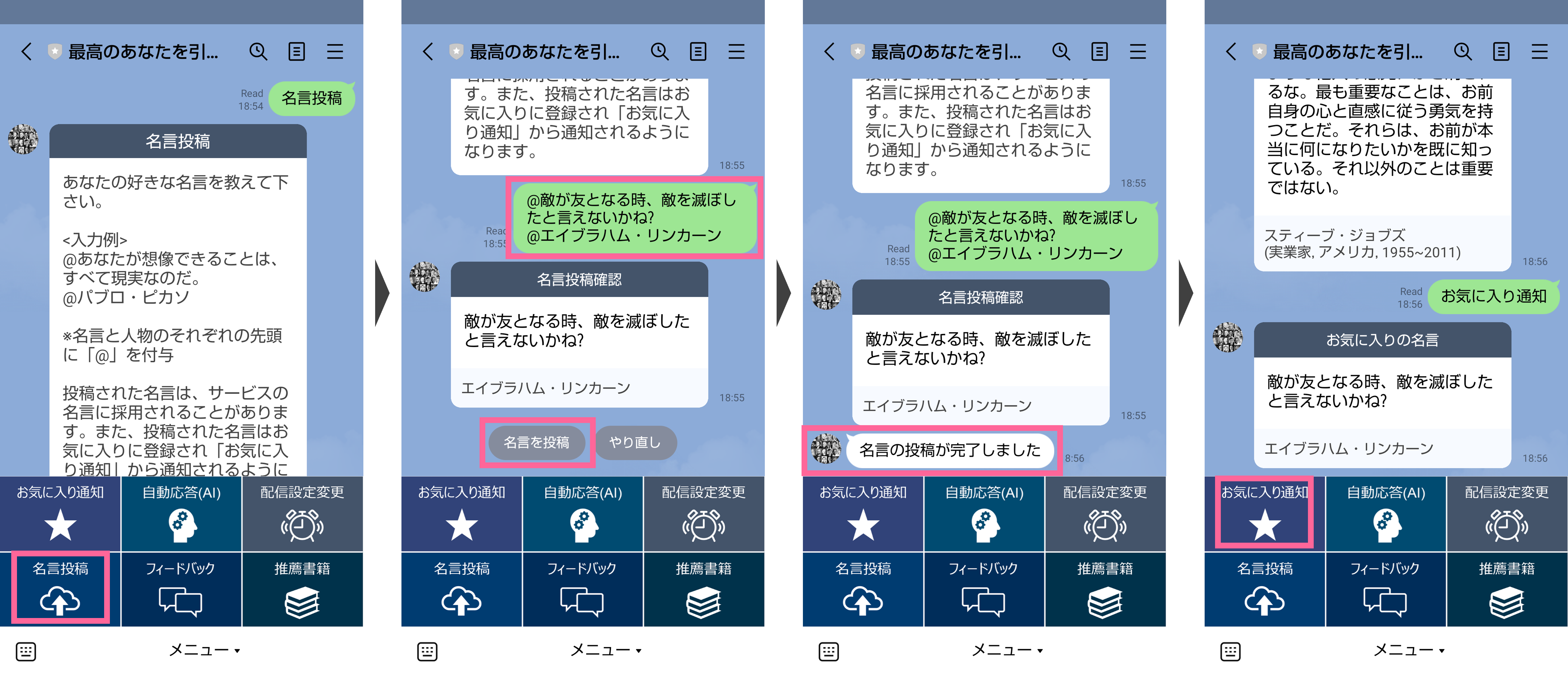
現在、200以上の名言をデータベースに登録していますが、良い名言があれば更に拡充させて行きたいと思っているため、名言の投稿機能を作りました。
投稿してもらった名言の中で、これはサービス利用者にも是非広めたいと感じたものは、サービスの配信データベースに登録させて頂きます(新規に採用した名言については、匿名でサービス利用者全体に通知予定)。
個人的に好きな名言や、好きな言葉のお気に入りへの登録機能も兼ねており、こちらから投稿した内容は、お気に入り通知ボタンから通知されるようになります。
投稿は、メニューの「名言投稿」ボタンから、名言と人物のそれぞれの先頭に「@」を付けて、メッセージを送信して下さい。
4.AIによる名言の自動応答
冒頭で紹介したように、テキストメッセージに対するAIでの自動応答機能を作りました。簡単に今の気持ちをメッセージで送れば、マッチする名言が返されます。
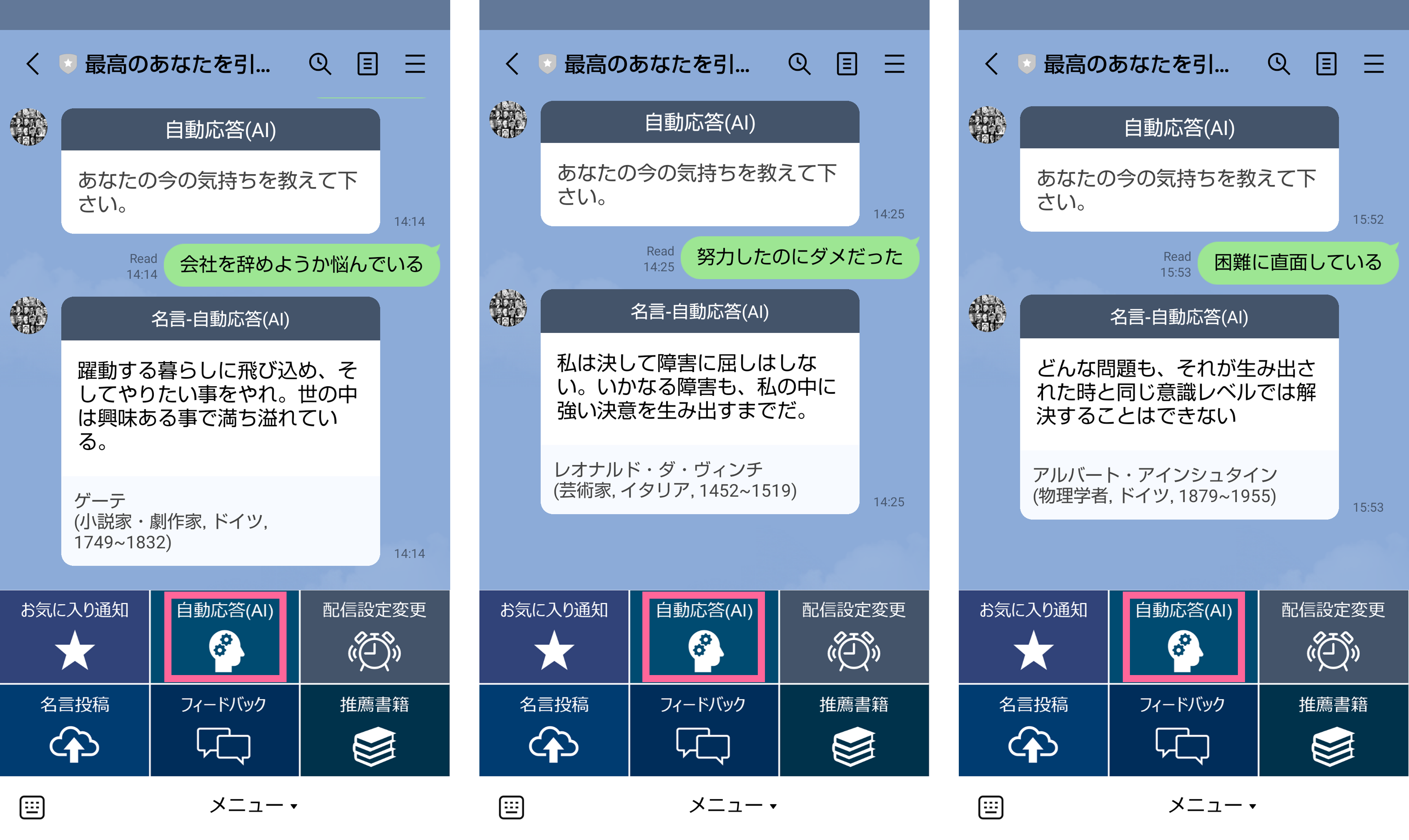
NLPにはBERTを使っていて、簡単な処理の流れは以下の通りです。
- LINEからメッセージを送付
- 送付されたテキストをBERTで文章ベクトルに変換
- 事前に準備したテキスト一覧(BERTで文章ベクトルに変換済)とNearest Neighborでマッチング
- 選ばれたテキストに紐付けてある名言の中から、1つ選んで配信
データがまだまだ不足しているという点と、異常検知の意味で、AIがよくわからないと判断したテキストに対しては、あえて無条件で、相田みつをの言葉の中から1つ返すようにしました。
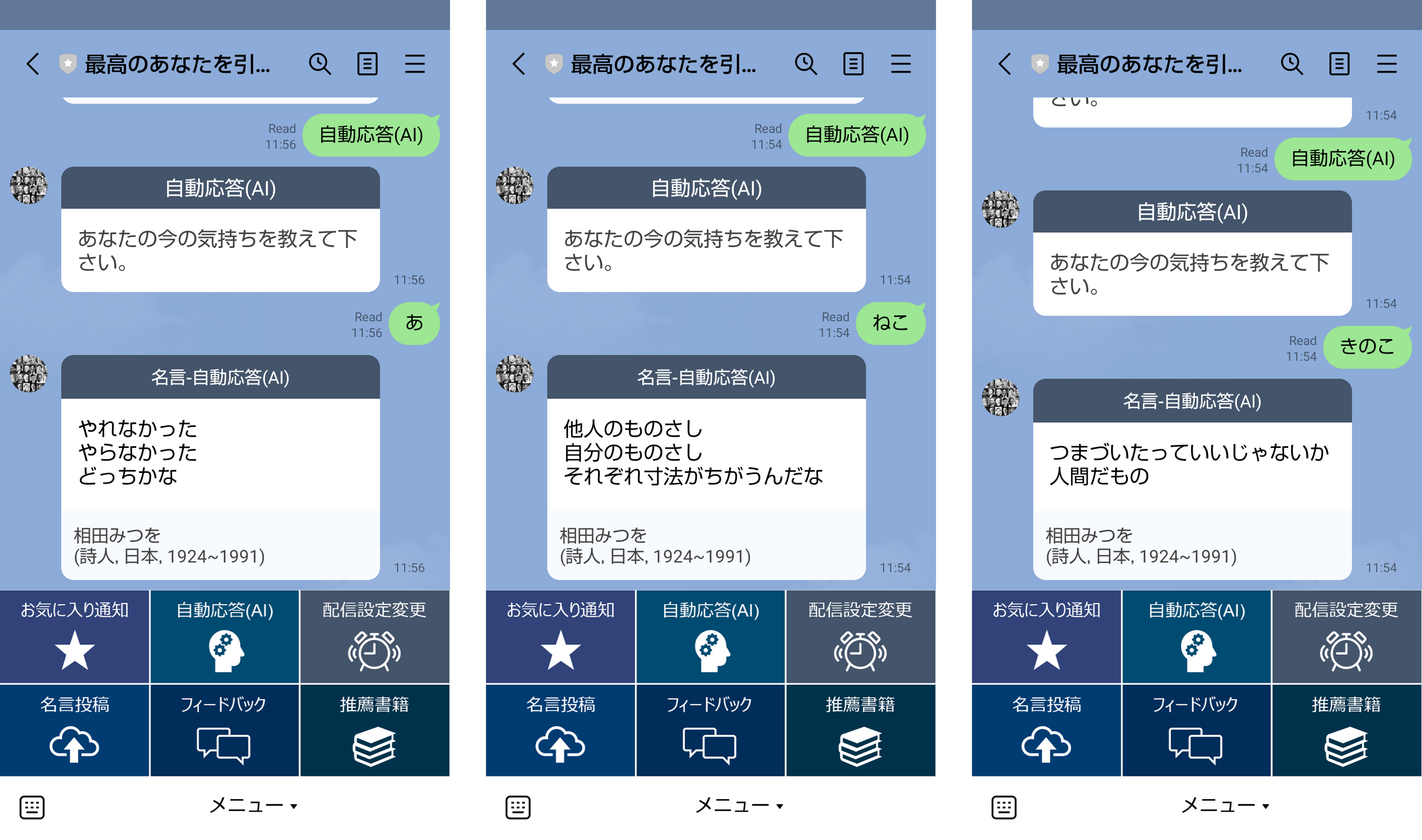
マッチングの際に、文章ベクトル間の距離に閾値を設定し、閾値を超えた場合は、未学習領域と見なしています。
長文だったり、込み入った文章にはまだ対応できていないので、追々強くして行きたいと思います。
以下、開発における備忘録です。
■テキストと名言のマッチング
最初は、1つ1つの名言にクラスかタグを振って、送付されたテキストのクラス分類で名言にマッチさせようと思っていました。
ただ、実際にやってみると、言葉と言葉の組み合わせは相当繊細で、例えば「夢」というクラスを作ったとしても、「大きな夢がある」というテキストと「夢なんか叶わない」というテキストに同じ名言を返すとしっくり来ないという事に気付きました。
じゃあ、もっとクラスを細分化すれば良いのでは?という事になりますが、一方で、クラスを細分化し出すと、どこでクラスを切るかという話にきりがなくなり、今後の拡張時にもひたすらクラスを切って行く作業になるため、クラス管理の観点でも現実的ではないなと思いました。
最終的には、どれだけしっくり来るものが返せるか、という事を目指す事になるので、想定される一般的なテキストのパターンと名言のセットを準備し、送付されたメッセージとのマッチングで返す、今の方式にしました。
とはいえ、これはこれでテキストのパターンと名言のセットの準備がかなり大変なので、フィードバック機能を元に、使いながら賢くしていくHITL(Human In The Loop)の方式にして行きたいと思います。
■AIモデルのデプロイ
AIモデルとデプロイしようとした時にぶち当たったのが容量問題です。
PyTorchとTransformerがやたらと重いので、そのままLambdaに上げる事が出来ず、EFSをマウントする形も検討しましたが、EFSを使う場合は、VPS含め色々と設定する必要があるので、このためだけにEFSを使うのは面倒だなと感じました。
結局、Lambdaのコンテナイメージを使うのが一番良さそうだなと思い、ECRにプッシュしたイメージをデプロイする形としました。
AIモデルを使う際は、デフォルトのLambdaの容量では足りず、メモリをある程度の割り当てておく必要があり、その分料金がかかるので、AIモデルのLambda関数だけ切り出して、AI以外の通常処理はメモリの少ないLambda関数で捌き、AIの処理が必要な時だけ、このLambda関数を呼び出す形としました。
現状の課題として、AIの処理自体は一瞬なものの、Dockerの起動に時間がかかり、初回の応答だけ、8秒程時間がかかってしまいます。
EventBridgeで常時イベントを発行してDockerを起動させておくというのも1つのようですが、単純に料金が跳ねるので避けたく。。サーバーレスで、大きなAIモデルをレスポンス早くデプロイする方法をご存知の方がいれば教えて頂きたいです(どうしようもなければ、サーバー立ててAPI作ろうと思います)。
5.サービスへのフィードバック
メニューの「フィードバック」ボタンから、サービスへのフィードバックを可能にしています。
先頭に「!」をつけて送付されたメッセージは、順次フィードバック用のDBに登録されるので、実際に使ってみて感じた点や、こういう機能が欲しいという事があれば、こちらから要望をもらえると嬉しいです。

6.推薦書籍紹介
これまで実際に読んだ本の中で、いわゆるテクニックやノウハウ系ではなく、思考力やメタ認知力を高めるのにとても役立ったなと感じた本を推薦書籍として紹介しています。
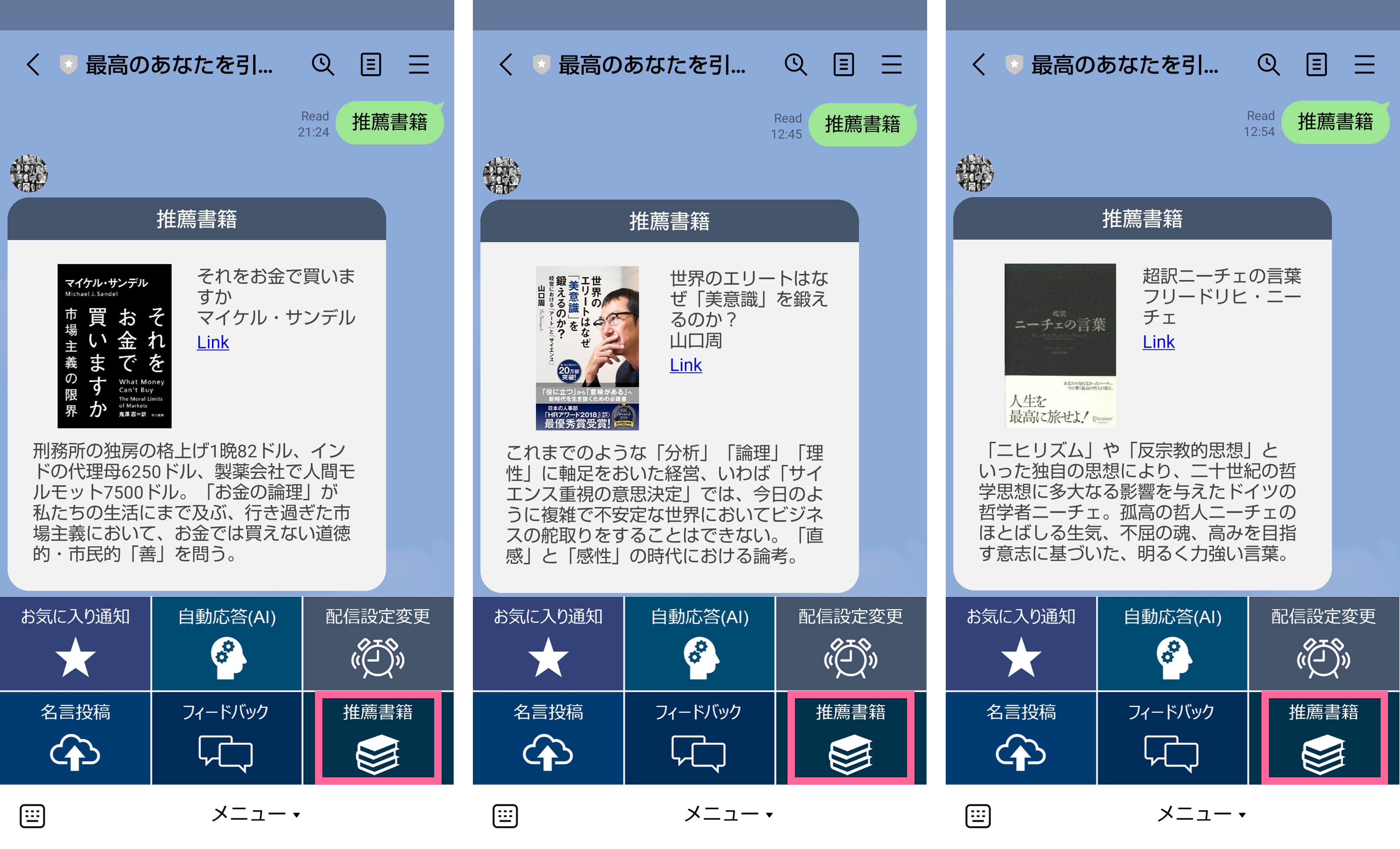
メニューの「推薦書籍」ボタンを押すと、データベースに登録している書籍の中から、ランダムに1冊選んで応答するので、面白そうだなと思った物があれば是非読んでみて下さい。
リベラルアーツ系でオススメの本があれば、こちらもフィードバック機能から教えてもらえると嬉しいです。
まとめ
年末に「これすぐできそうだな」と思い立って開発を開始し、AWSのおかげで、プロトタイプ作成まではすぐだったのですが、やはり、いわゆるチュートリアルやプロトタイプ作成と、実際のデプロイには大きな溝があるなと改めて感じました。
色々と作りこむ前に、まずはリリースが大事だと思いリリースしましたが、今回外した機能も色々とあるので、随時ブラッシュアップして行きたいと思います。
今はまだAIが1往復かつ、学習データも含め限定的なので、精度を上げつつも、行く行くは対話型にして、もっとピンポイントで返せるようにして行きたいと思います。
参考書籍
・BERTによる自然言語処理入門
Qiita投稿記事
・【AI】Deep Metric Learning
・【AI】Deep Learning for Image Denoising
・【AI】Deep Convolutional Autoencoderベースの教師なし異常箇所検知
・【AI】Deep Learning for Image Inpainting
・AIの実業務適用に必須なHITLという考え方と、HITLを加速させるAI×RPA
・寿司打を自動化してみた【RPA×OCR】
・ホテル暮らしはクラウドである
個人Blog(キャリア/コンサル/ビジネススキル)
・Business Core