はじめに
前回「【AI】Deep Metric Learning」でDeep Metric Learningを用いた異常検知について紹介しました。
こちらも教師なし学習の枠組みであり、学習時には正常データのみを用いて、正常データの特徴量空間を学習。そして、未知データに対して、正常データで学習した空間からの逸脱度を基準に異常検知を行いました。
入力した画像が「正常」か「異常」かを高精度で自動判定してくれるのは良いのですが、画像全体での異常検知なので、「異常はわかったけど、どこが異常なの?」と聞きたくなるのが正直な所です。「異常です」とブザーやサイレンを鳴らすだけでなく、「〇〇が異常です」と教えてくれるようにその異常箇所の検知(可視化)をやって行きたいと思います。
異常箇所検知には、Autoencoderベースのもの、GANを利用したもの、その組み合わせなど、様々な手法が提案されていますが、今回はAutoencoderベースのシンプルな手法を紹介し、手書き文字画像と工業製品・農作物画像での異常箇所検知をやって行きます。
Deep Convolutional Autoencoderによる教師なし異常箇所検知
Deep Convolutional Autoencoder(以降DCAE)は、以前デノイズの記事で説明したように、EncoderとDecoderで畳み込みニューラルネットワークが対になった構成です。
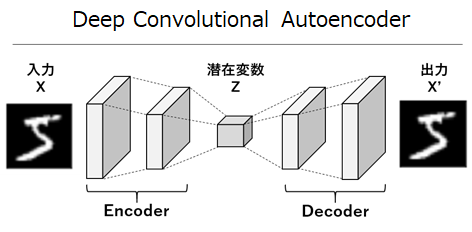
このDCAEにおいて、インプットとなる入力データを再構成できるように学習させることで、隠れ層において入力データを再現できる低次元の特徴を捉える事ができます(非線形次元削減)。
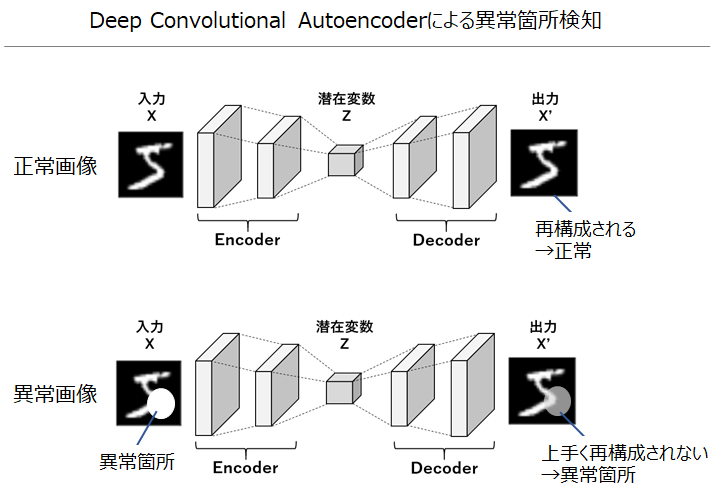
このように学習したDCAEは、学習データと同じパターンのデータは学習済みなので綺麗に再構成できますが、学習データにない新たなパターンのデータは上手く再構成できないという性質を持ちます。この性質を利用し、正常データのみを用いてDCAEを学習させ、未知画像をインプットとした際の再構成の誤差(インプットとの差分)を見る事で、上手く再構成できなかった箇所(=異常箇所)を可視化する事ができます。
デモ1:手書き文字データでの異常箇所検知
1つ目のデモとして、手書き文字データを用いて異常箇所検知をやって行きます。
正常な学習データとして、お馴染みのMNISTを用い、未知の異常判定対象データとしてMNIST-Cから「dotted line」「shot noise」「impulse noise」「zigzag」の4種類を使用します。正常データで学習したDCAEに対し、異常判定用データを入力し、異常箇所が可視化されるかを見て行きます。
 ## モデル
モデルの構築はGoogle Colaboratory上でKerasを使ってやって行きます。
モデルの概要は以下の通りです。
## モデル
モデルの構築はGoogle Colaboratory上でKerasを使ってやって行きます。
モデルの概要は以下の通りです。
 各種パラメータ
各種パラメータ
入力画像:32×32ピクセル
エポック数:50
バッチサイズ:128
各層のフィルタ数:32
カーネルサイズ:3×3
結果
入力画像とDCAEによる再構成画像、異常箇所のヒートマップ(入力画像と再構成画像の残差)、入力画像に異常箇所のヒートマップを重ねて異常箇所を可視化した結果(緑色が異常と判定された箇所)は以下の通りです。

学習時の正常データと同じパターンの異常なしデータは上手く再構成できているものの、異常データは上手く再構成ができておらず、再構成できなかった箇所が異常箇所として可視化されています。解像度の低い画像であるため、しばしば飛び値も見られ、パラメータ調整により更に精度の向上は可能ですが、このようなシンプルな構成でありながら、異常箇所の可視化においてその有効性が見て取れます。近年、説明可能なAI(Explianable AI)の重要性が問われている中、正常か異常かのゼロイチ判定の結果に比べ、異常箇所の可視化はその説明性が高いと言えるでしょう。
SSIM Deep Convolutional Autoencoderによる教師なし異常箇所検知
通常のDCAEはロス関数にMSE(最小二乗誤差)等のピクセルベースのロス関数を用いるため、全体的に画像がぼやけてしまうという欠点を持っています。
ピクセルベースのロス関数においては、1ピクセル毎にピンポイントで当てに行くより、解離が大きくならないよう平均的な値を返しておくほうがロスが小さくなるためです。
またMSEは人間の視覚特性とは異なる性質を持ち、この点を改善するために提案されたのが、ロスにSSIM(Structure similarity)を用いた、SSIM Deep Convolutional Autoenconder[1]です。
SSIMは、注目ピクセルだけではなく、注目ピクセルと周辺ピクセルの輝度やコントラストの相関を考慮した指標です(0-1の範囲を取り、2つの画像が完全一致の場合は1で、小さいほど相違度が高い)。
<定式化>
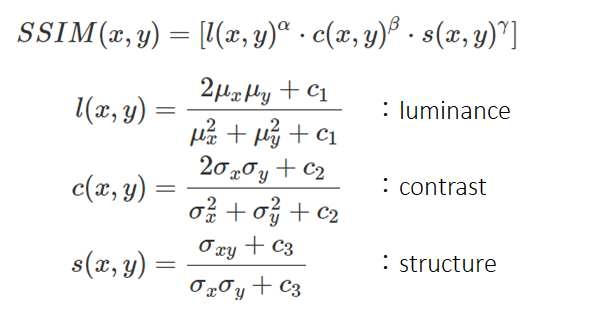
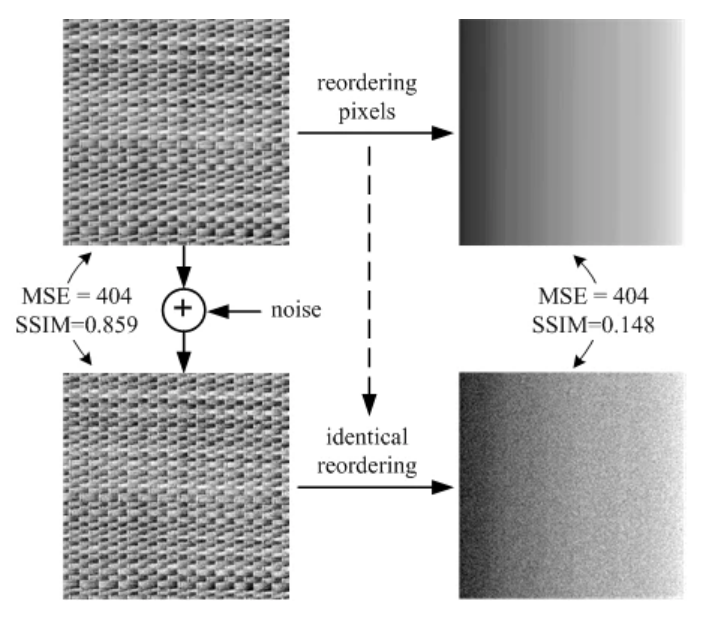
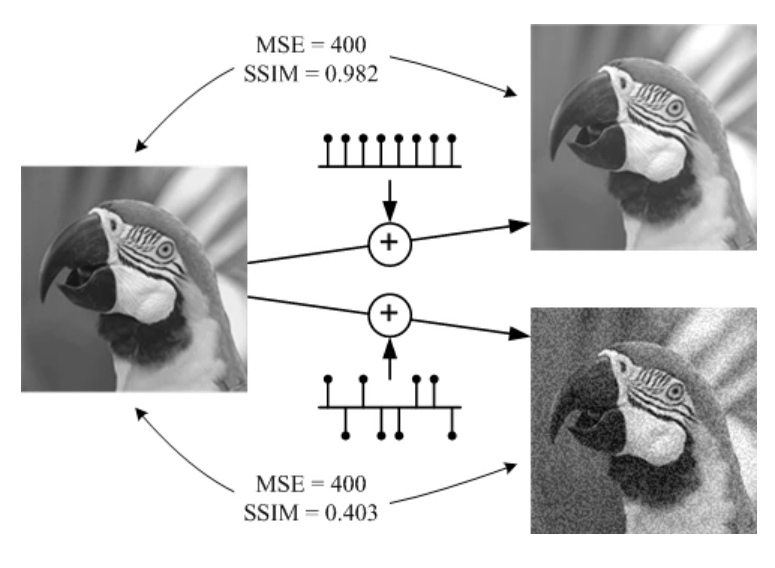
以下がMSEとSSIMの比較の例で、MSEはあくまでピクセル毎の比較であるため、テクスチャ構造を捉えておらず、1つ目の例においては、人間の目には左側の2枚の画像より右側の2枚の画像の差が大きく見えますが、MSE自体は全く同じ値となっています。
一方SSIMでは左側は近い画像、右側は大きく異なるというように人間の感覚に近い結果を返しています。
SSIM Deep Convolutional AutoencoderはDCAEと同じネットワーク構成でロスをSSIMに変えるだけで実装ができる使いやすさもその大きな利点となっています。
デモ2:工業製品・農作物データでの異常箇所検知
今度はMNISTより解像度の高い、MVTec(工業製品や農作物などの異常検知用データセット)を使用します。
学習データとして異常箇所のない正常データ、異常判定用データとして、欠損やペイント、破れ・ねじれなどが含まれるデータを利用し、異常箇所が可視化されるかを見て行きます。「bottle」「hazelnut」「grid」の3種類それぞれにおいて、SSIM Deep Convolutional AutoencoderとDCAEを学習させます。

モデル
モデルはデモ1とほぼ同じで、SSIM Deep Convolutional AutoencoderとDCAEの差分はロス関数のみで、同じネットワーク構成を用います。
各種パラメータ
入力画像:128×128ピクセル
エポック数:50
バッチサイズ:16
各層のフィルタ数:32
カーネルサイズ:3×3
結果
入力画像とそれぞれの再構成画像、異常箇所のヒートマップ、入力画像にヒートマップを重ねた結果は以下の通りです。

ネットワーク構成は同じであるものの、DCAEの再構成画像が少しぼやけているのに比べ、SSIM Deep Convolutional AutoencoderではロスにSSIMを用いた効果によりテクスチャ構造まで再構成されている事が見て取れます。
そして、こちらも上手く再構成されなかった箇所が異常箇所として可視化されています。
異常箇所の可視化もそうですが、面白い振る舞いが、「画像が復元されている箇所がある」という点です。gridの画像において顕著ですが、正常画像でのAutoconderの学習で、均一な網目の構造を学習しているため、初めて見るはずの破れやねじれのある網目に対し、その再構成で破れやねじれの箇所が復元されている様子が見て取れます。

非線形の次元削減により、正常データの本質的な構造を学習している一端が垣間見える、興味深い振る舞いを示しています。
まとめ
Deep Convolutional Autoencoderベースの教師なし異常箇所検知の手法と簡単なデモを紹介しました。異常箇所検知と同時に画像復元の振る舞いを見ることができ、概念的なわかりやすさとそのシンプルな構成も大きな魅力です。
元々はAE-Grad[2]もやるつもりでしたが、何故かKerasで思うような結果が出せなかったため、また新しい手法含めアップデートして行きたいと思います。
【元論文】
[1] Improving Unsupervised Defect Segmentation by Applying Structural Similarity to Autoencoders
[2] Iterative energy-based projection on a normal data manifold for anomaly localization
<参考>
Qiita記事
・【AI】Deep Metric Learning
・【AI】Deep Learning for Image Denoising
・【AI】Deep Learning for Image Inpainting
・RPAは誰でも簡単に作れるという罠
・VBAが組める人ならRPAは簡単に作れるという罠
・UiPathのコーディングチェックツールを作ってみた【RPA】
・RPAへの理解がぐっと深まる、RPAがよくこける理由
・RPAのオススメ書籍
・RPAの開発に向いている人、向いていない人
・寿司打を自動化してみた
・RPAの推進に必須なRPAOpsという考え方
デモ
・UiPathCodingChecker:UiPathのxamlファイルからコードを分析
・AI Demos:DeepLearningによる手書き文字認識・異常検知・画像のデノイズ
・寿司打自動化(YouTube):タイピングゲーム寿司打のRPA×OCRでの自動化