はじめに
機械学習の分野でDeep Learningがその地位を揺るがぬものにして久しくなりました。
今回はその性能と汎用性の高さから、様々な分野で応用が進んでいるDeep Metric Learningについて、簡単なまとめといくつかのデモを紹介していきたいと思います。
手書き文字認識と、手書き文字認識だけでは面白くないので異常検知もやります。
Deep Metric Learning
Metric Learningとは「距離学習」と言われる手法で、入力データの特徴量空間から、データの類似度を反映した特徴量空間への変換(写像)を学習する手法です。
一言で言うと、
- 同じクラスに属するデータは近く
- 異なるクラスに属するデータは遠く
なるような特徴量空間への変換を学習します。
クラス分類などにおいて、距離が近すぎて分類が困難なケースでも、同じクラスは距離が近く、違うクラスは距離が遠く」なるように特徴量空間を学習する事で、識別精度を向上させる事ができます。
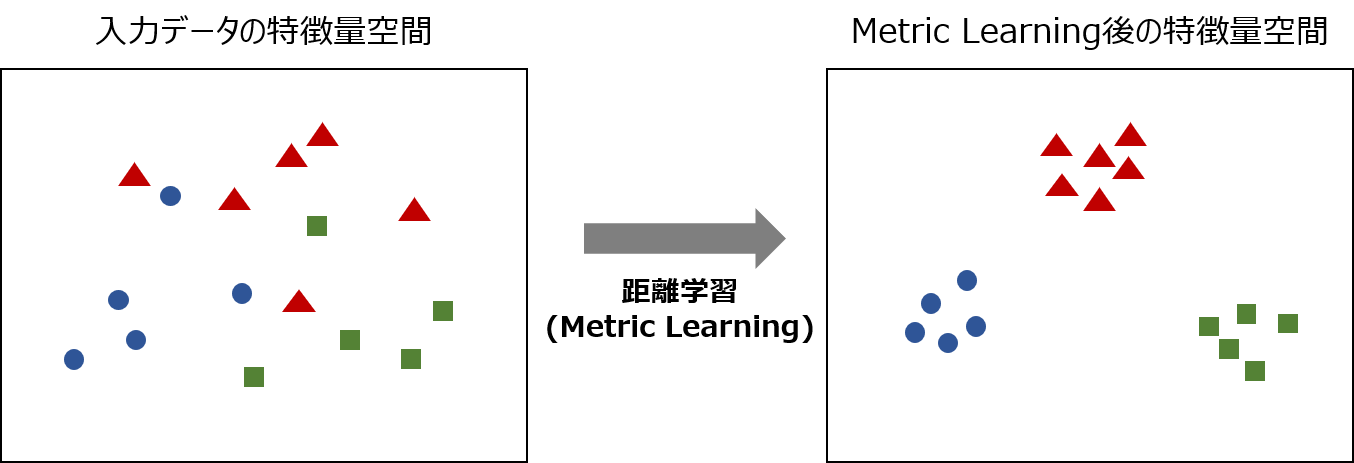
Metric Learning自体は古くからある手法ですが、Deep Metric Learningはこの変換をDeep Neural Networkによって非線形に設計する手法です。
Deep Metric Learningはデータ間の「距離」を学習する手法であるため汎用性が高く、その性能の高さからも応用分野は以下のように多岐に渡ります。
- 情報検索
- 画像分類
- 顔認証(生体認証)
- クラスタリング
- 可視化
- 異常検知
世界中のデータサイエンティストがその性能を競い合うコンペ「Kaggle」でも頻繁に登場する手法であり、今回はこの中で画像分類と異常検知をやって行きます。
デモ1. 手書き文字認識
お馴染みMNISTの手書き文字認識をDeep Metric Learningでやります。

データ:28×28ピクセルの0-9の手書き文字画像
学習データ:50,000枚
テストデータ:10,000枚
Deep Metric Learningの手法として、いくつかの手法が提案されていますが、
今回は学習の速さと性能の高さ、モデル自体がシンプルである事から、L2-constrained Softmax Lossを使って行きます。
L2-constrained Softmax Loss
L2-constrained Softmax Lossは、Deep Neural Networkの最終層の出力のL2ノルムが、ある定数$\alpha$になるように制約を加える手法であり、これは入力データを半径$\alpha$の超球面上に埋め込んでいる事と同義になります。
L2-constrained Softmax Lossの式は以下の通りです。
\text{minimize } -\frac{1}{M} \sum_{i=1}^{M} \log \frac{e^{W_{y_{i}}^{T} f\left(\mathbf{x}_{i}\right)+b_{y_{i}}}}{\sum_{j=1}^{C} e^{W_{j}^{T} f\left(\mathbf{x}_{i}\right)+b_{j}}}\\
\text { subject to } \quad\left\|f\left(\mathbf{x}_{i}\right)\right\|_{2}=\alpha, \forall i=1,2, \dots M\\
超球面状にデータを埋め込む制約を入れる事で、同一クラスのデータ同士のコサイン類似度は大きく、異なるクラスとのコサイン類似度は小さくなるよう学習する事ができます。
通常のSoftmax Lossでは、例えば顔写真の場合、真正面を向いているようなわかりやすい画像ではL2ノルムが大きくなり、横を向いていたり、うつむいていたりするような特徴量の取りにくい画像ではL2ノルムが小さくなるという性質があります。そのため、真正面を向いているようなわかりやすい画像に学習が引っ張られ、L2ノルムの小さい、要するに難しい画像は無視される傾向があります。

L2-constrained Softmax Lossは、データによらずL2ノルムを一定にする事で、全てのデータのLossへの影響を均一にし、この問題を克服しています。
L2-constrained Softmax Lossの実装自体は非常に簡単で、Deep Neural Networkの最終層の出力に、L2ノルムの正規化レイヤーと定数$\alpha$のスケーリングレイヤーを入れ、Softmax Lossを計算すれば実現できます。
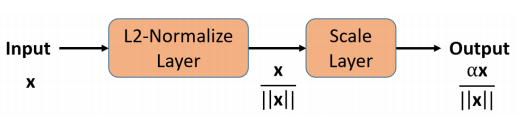
モデル
実装はGoogle Colaboratory上でKerasを使ってやって行きます。
以下の通り、Convolution層を3層重ね、FC層(全結合層)とSoftmaxの間にL2-constrained(Lambda層)を入れます。通常のConvolutional Neural Network(CNN)との違いは、このL2-constrainedのみです。
モデル概要

Kerasでのモデル出力

各種学習パラメータ
- エポック数:15
- バッチサイズ:128
- 超球面の半径$\alpha$:16
t-SNEでの可視化
Deep Metric Learningの効果を確認するために、入力の特徴量空間と変換後の特徴量空間をそれぞれt-SNEで2次元まで落として可視化してみます。
t-SNEは高次元空間におけるデータ同士の「近さ」が低次元空間においても保持される形で次元圧縮を行うアルゴリズムで、圧縮に教師ラベルは使用しないため、純粋に高次元空間においてデータがどの程度分離されているかがわかります。
1. 入力空間の可視化(784次元→2次元)
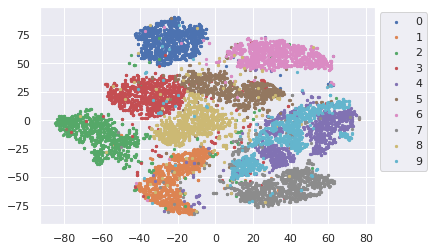
各点が1枚の画像に対応しており、同じ色は同じ数字のクラスに属するデータを表しています。入力空間でも概ねクラス毎に分離されてはいるものの、重なりやばらつきが多く見られます。
2. 通常のCNNでの最終層の可視化(64次元→2次元)

CNN自体が高い性能を誇っている通り、通常のCNNでも最終層ではかなり綺麗に分離されている(クラス毎にクラスタが形成されている)事がわかります。綺麗に分離されてはいるものの、よく見るとちょっとした飛び値がしばしば見られます。
3. L2-constrained Softmax Lossでの最終層の可視化(64次元→2次元)
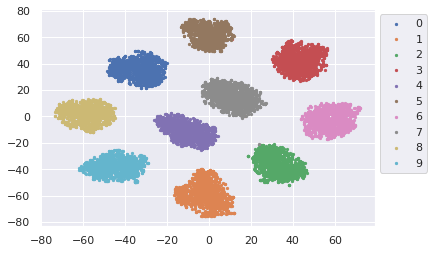
L2-constrained Softmax Lossでは、通常のCNNに比べ、クラスタが更に綺麗に分離されている事がわかります。L2ノルムを正規化しているお陰で、全てのデータが学習に寄与しており、飛び値もほとんど見られません。Deep Metric Learningが「距離学習」と言われる所以が見て取れます。
識別結果
テスト画像10,000枚に対する識別結果は以下の通り。
最終層の可視化での分離度の高さが見て取れたように、同様のCNNモデルにL2の正規化レイヤとスケールレイヤの制約を入れるだけで精度が向上している事がわかります。
accuracy, loss共になだらかな推移を見せ、最終的にどちらもCNN(L2ロスなし)より良い値となっています。
| 手法 | CNN(L2ロスなし) | L2-constrained Softmax Loss |
|---|---|---|
| 識別率 | 99.01 | 99.31 |
| 学習(accuracy) |  |
 |
| 学習(loss) |  |
 |
ちなみにL2-constrained Softmax Lossで識別に失敗した画像(69枚)は以下の通り。
・pred:L2-constrained Softmax Lossの予測値
・true:正解ラベル

わかるよその気持ち!と言ってあげたくなるものがけっこうありますね。
これは人間でも100点取るのは難しそうです。。
弱い所の学習データを増やせば精度は上がりそうですね。
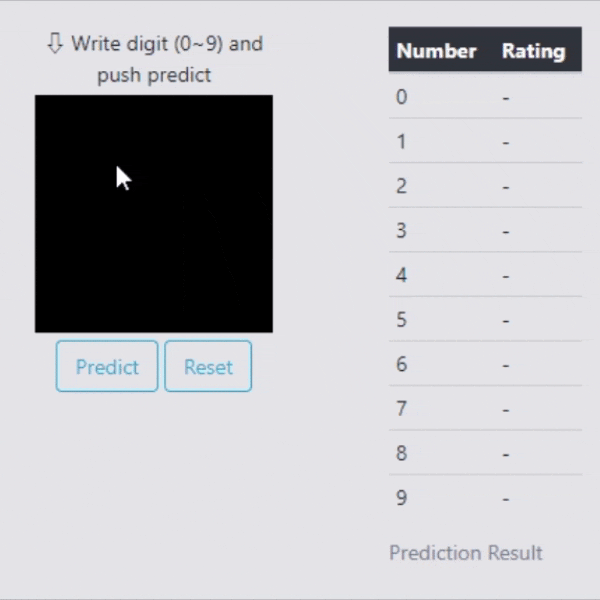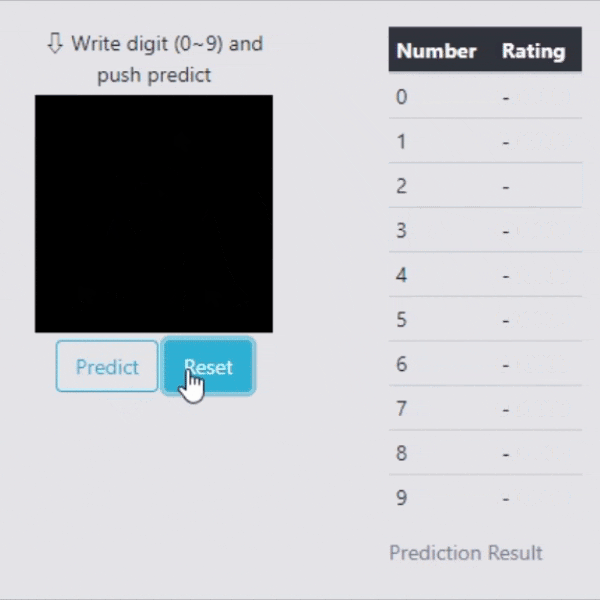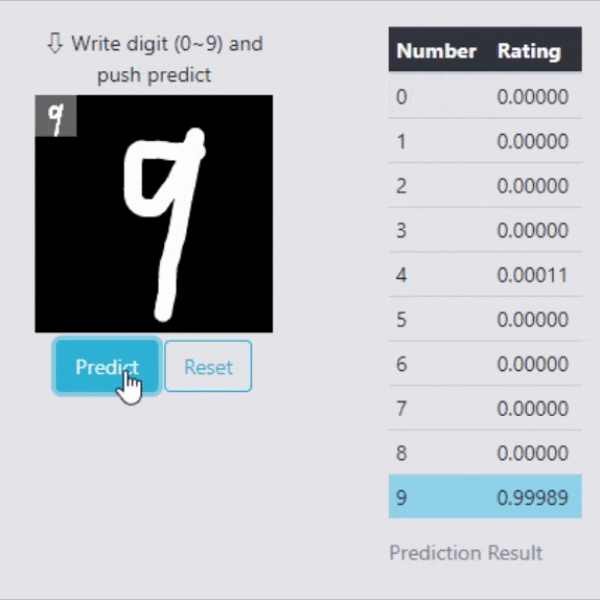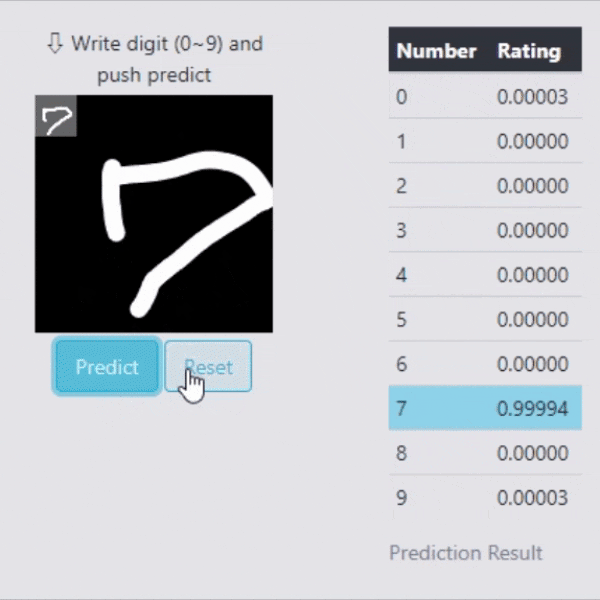
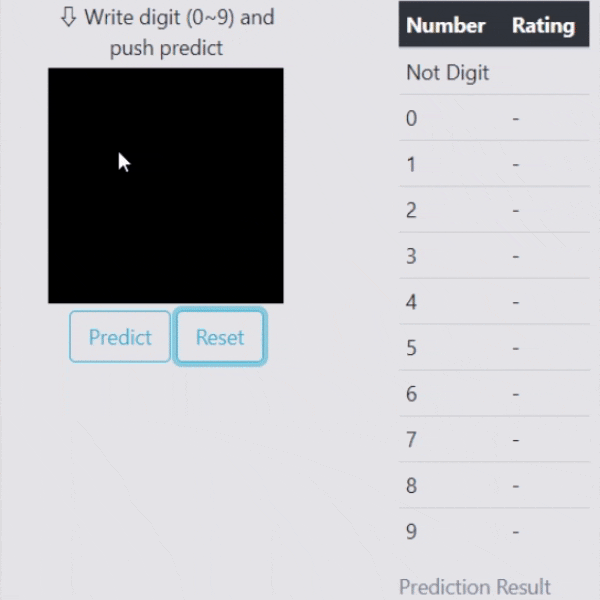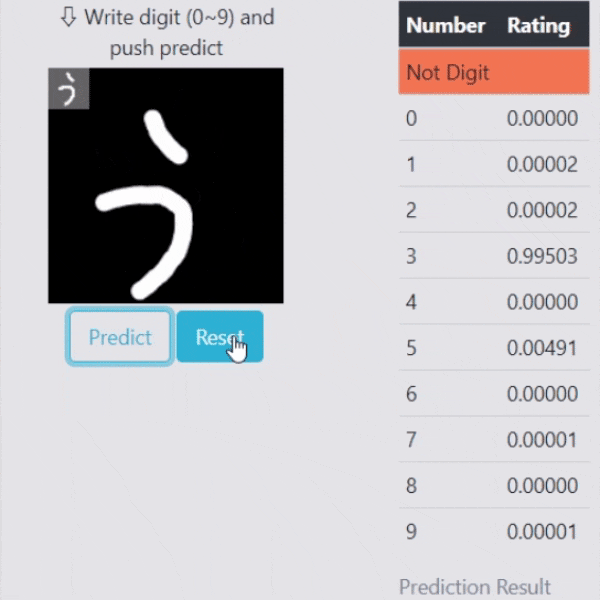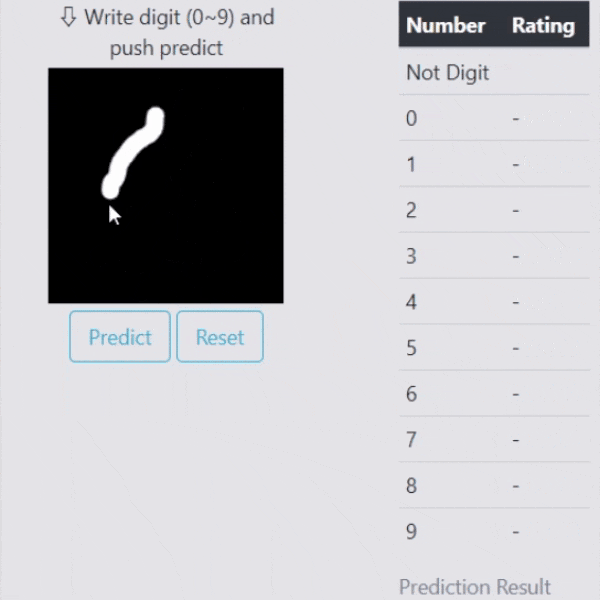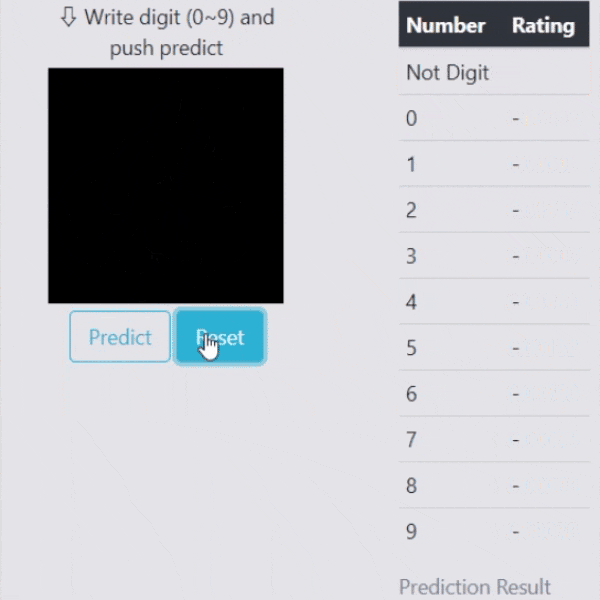
Flaskでのデモ(識別)
せっかくなので学習したモデルを使って、Flaskでリアルタイムで処理できるデモを作りました。
しっかりと識別してくれている事が確認できます。
そもそも99.3%の識別率なので、よほど変な数字でなければ大丈夫そうですね。
デモ2. 異常検知
識別はしっかりしてくれているものの、今の状態では明らかに数字でないものも以下のように強制的にどれかに割り当ててしまいます。
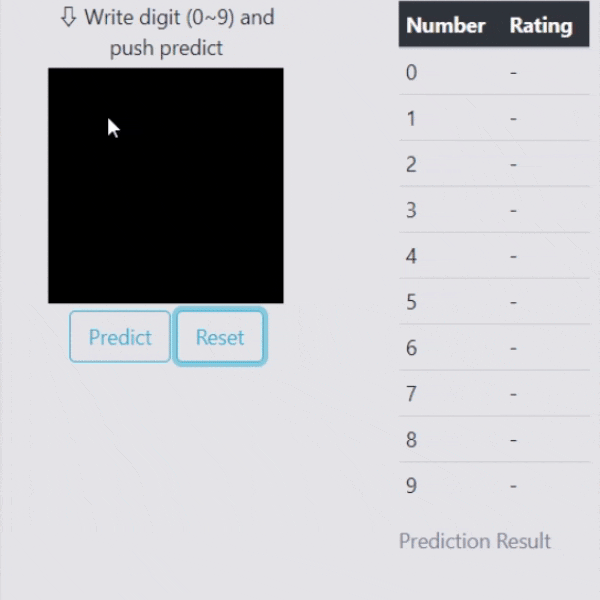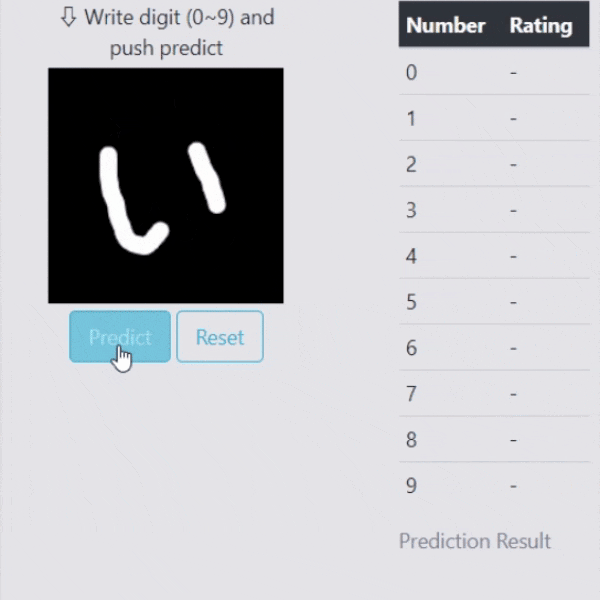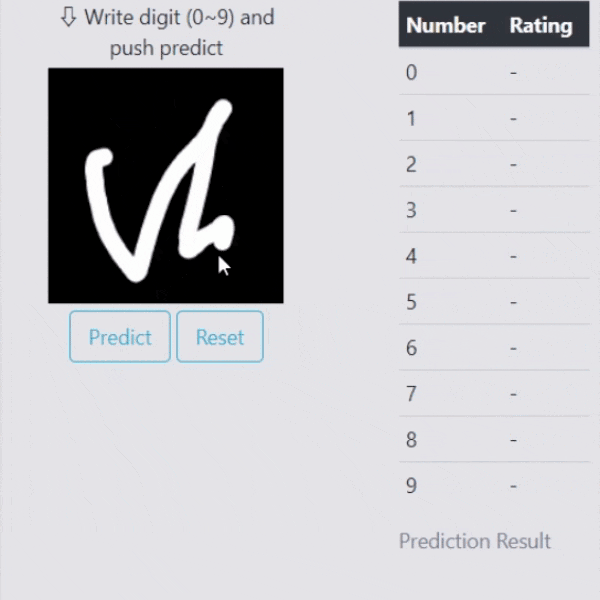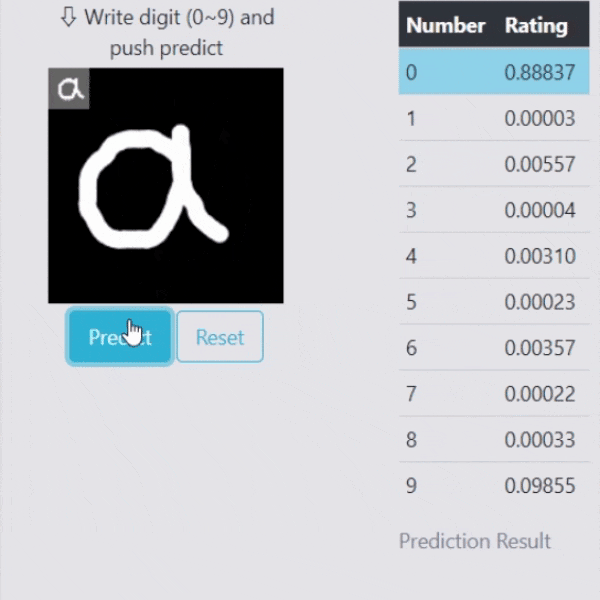
数字ではないものが入力された時は、どれか近いものを出力するのではなく、数字ではないとはじきたいですよね。異常検知を使って、これまでの識別能力は保ちつつも、数字以外をはじくようにしてみましょう。
Deep Metric Learningが異常検知にも応用できると最初に書いた通り、データの類似度を反映する形で学習した特徴量空間上で異常検知を行う事で、入力空間での異常検知に比べて高い精度が出せるようになります。Deep Metric Learning自体は異常検知を行う手法ではなく距離学習であるため、異常検知には別の手法が必要になります。今回は異常検知にLocal Outlier Factor(LOF)を使います。
Local Outlier Factor(LOF)
LOFは空間におけるデータの密度に着目した異常検知手法です。いわばk-nearest neighbor(kNN)の発展版のようなもので、kNNではクラスタ毎のデータのばらつきを考慮できないのに対し、LOFは自身から近傍 k 個のデータとの**局所密度 (Local density)**に注目する事で、データの分布を考慮した異常検知ができるようになります。
局所密度 = 1/近傍k個の点との距離の平均
式や詳細は割愛しますが、例えば以下の図のようなケースの場合、データAは近傍のクラスタからの距離が遠いので異常と判定したく、データBは近傍のクラスタと同等の分布の中にあるため正常と判定したくなります。ただし、k近傍からの距離という意味ではBの方が遠いため、kNNでは対応できません。一方LOFは、周辺のデータの密度に基づいて異常の閾値を決めるため、このようなケースにも対応する事ができます。

モデル
MNISTの識別で学習したモデルのL2-constrained層の出力にLOFをかけて異常検知を行います(Deep Neural Netの再学習は不要)。LOFが異常と判定した場合は、異常として出力し、正常と判定した場合は、これまで通りのSofmaxでの識別結果を出力します。
LOFはscikit-learnを使用し、以下のパラメータで学習します。
・n-neighbors:20
・contamination:0.001
・novelty:true
データ
異常検知の対象として以下の2種類のデータセットを使います。
| データセット | Fashion-MNIST | Cifar-10 |
|---|---|---|
| 概要 | シャツやバッグ、靴などのファッション系の画像データセット(10クラス) | 飛行機や車、犬などの自然画像のデータセット(10クラス) |
| 画像例 |  |
 |
いずれも数字のデータはなく、Fashion-MNISTは28×28ピクセルのグレースケール画像のためそのまま利用し、Cifar-10は32×32ピクセルのカラー画像のため、グレースケール化とリサイズを行って使用します。Deep Nerual Netの学習は手書き文字のMNISTだけで行っているため、Deep Neural Netから見るとどちらも未知画像になります。この2つのデータセットが最終層の特徴量空間のLOFで、異常として正しくはじかれるかテストしたいと思います。
識別結果
ベンチマークとして入力の特徴量空間でLOFかけた場合の異常検知を使用します。
入力の特徴量空間でLOF:ベンチマーク
| データ | 正常判定 | 異常判定 |
|---|---|---|
| MNIST | 0.99 | 0.01 |
| Fashion-MNIST | 0.70 | 0.30 |
| Cifar-10 | 0.16 | 0.84 |
MNISTは99%を正常と認識出来ているものの、正常の範囲を広く取りすぎており、Fashion-MNISTも70%が正常、Cifar-10も16%が正常として判定されてしまっています。
Deep Metric Learning(L2-constrained Softmax Loss)の最終層でLOF:今回手法
| データ | 正常判定 | 異常判定 |
|---|---|---|
| MNIST | 0.99 | 0.01 |
| Fashion-MNIST | 0.12 | 0.88 |
| Cifar-10 | 0.05 | 0.95 |
MNISTの正常判定の99%は保ちつつも、Fashion-MNISTも88%、Cifar-10は95%が異常として判定できるようになっています。
もう少し異常ではじきたい場合は、contamination(学習データにおける外れ値の割合)を大きくすれば良く、contaminationを0.01にした場合の結果が以下です。
| データ | 正常判定 | 異常判定 |
|---|---|---|
| MNIST | 0.96 | 0.04 |
| Fashion-MNIST | 0.02 | 0.98 |
| Cifar-10 | 0.00 | 1.00 |
MNISTのデータの4%が異常と判定されていますが、
Fashion-MNISTで98%、Cifar-10に至っては全ての画像を異常として判定出来るようになっています。
識別に失敗した画像で見た通り、MNISTにはそもそも識別困難なデータが含まれているので、異常検知の精度を考慮すると実用上はこちらの方が良さそうです。
Flaskでのデモ(識別+異常検知)
こちらもFlaskでリアルタイムで処理できるデモを作りました。数字以外の文字が来た時は異常(Not Digit)としてはじいており、数字についてはこれまで通り識別してくれている事が確認できます。
まとめ
Deep Metric Learningで距離学習を行う事で、識別精度の向上と合わせて異常検知への応用も容易となる事が簡単なデモで見て取れました。概念としてもわかりやすい上、特にL2-constrained Softmax LossはL2ノルムの制約を入れるだけなので非常に簡単に実装できるのが利点です。
今後もこのような形でなるべくデモを交えながら、色々な手法を紹介して行ければと思います。
■参考
デモ
・AI World:DeepLearningを使ったAIのデモサイト
Qiita記載記事
・Deep Learning for Image Denoising
・Deep Learning for Image Inpainting
・ホテル暮らしはクラウドである
・AIの実業務適用に必須なHITLという考え方と、HITLを加速させるAI×RPA
・RPAの推進に必須なRPAOpsという考え方
・VBAが組める人ならRPAは簡単に作れるという罠
個人ブログ(キャリア・コンサル)
・コンサルティングファームが優秀な人材をどんどん昇格させる本当の理由
・なぜ「コンサルタント」というキャリアはこれほど面白いのか
・キャリアアップのための転職の使い方 ~内部昇格と転職の歪み~
・コンサルタントになりたい人がコンサルファームに長くいてはいけない理由
・未経験からコンサルに転職する場合、必ず頭に入れておくべき1つの事