こんにちは。ミクシィ AI ロボット事業部でしゃべるロボットを作っているインコです。
この記事は ミクシィグループ Advent Calendar 2018 の5日目の記事です。
この記事の目的
この記事では2018年現在 DeepLearning における自然言語処理のデファクトスタンダードとなりつつある Transformer を作ることで、 Attention ベースのネットワークを理解することを目的とします。
機械翻訳などの Transformer, 自然言語理解の BERT やその他多くの現在 SoTA となっている自然言語処理のモデルは Attention ベースのモデルです。 Attention を理解することが今後の自然言語処理 x Deep Learning の必須になってくるのではないでしょうか。
歴史 - RNN から Attention へ
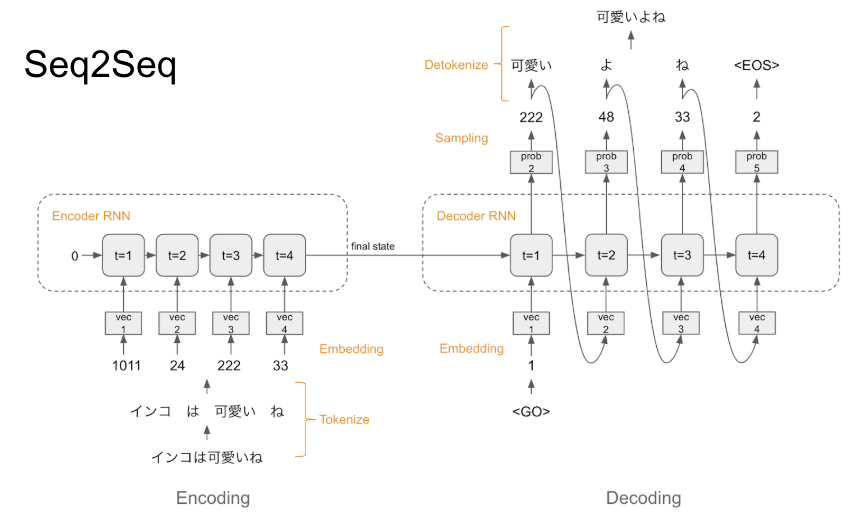
かつて 自然言語処理 x Deep Learning と言えば、 LSTM や GRU といった RNN (Recurrent Neural Network) でした。
参考: DeepLearning における会話モデル: Seq2Seq から VHRED まで
ところが2017年の6月、 Attention Is All You Need という強いタイトルの論文が Google から発表され、機械翻訳のスコアを既存の RNN モデル等から大きく引き上げます。
Attention は従来の RNN のモデル Seq2Seq などでも使われていました。(seq2seq で長い文の学習をうまくやるための Attention Mechanism について)
Transformer は文章などのシーケンスから別の文章などのシーケンスを予測するモデルとして発表されましたが、 Transformer の Encoder 部分を使ったモデルは文章分類などシーケンスからカテゴリを予測する問題等でも高い性能を出しており、特に最近発表された同じく Google の BERT (Bidirectional Encoder Representations from Transformers) は言語理解の様々なタスクのベンチマークである GLUE で圧倒的なスコアを達成しました。
このように Transformer やその基盤になっている Attention はその後広く使われるようになり、現在では「自然言語処理 x Deep Learning といえば Attention だよね」と言っても過言ではないくらいの存在となっています。
利点
Attention は RNN に比べて良い点が3つあります。
- 性能が良い
- 現在の SoTA の多くが Attention ベース
- 学習が速い
- RNN は時刻tの計算が終わるまで時刻t+1の計算をできません。このため GPU をフルに使えないことがあります。
- Transformer は推論時の Decoder を除いて、すべての時刻の計算を同時に行えるため GPU をフルに使いやすいです。
- 私の経験でも RNN の学習時は GPU 使用率が0-100%の間を行き来し平均60%程度ですが、 Attention ベースのモデルの場合 GPU 使用率は98%前後くらいにビッタリ張り付きます
- 構造がシンプル
- RNN を使わないため比較的構造が単純です
- 全結合と行列積くらい知っていれば理解できてしまいます
Transformer を知る
日本語の情報であれば Ryobot さんの 論文解説 Attention Is All You Need (Transformer) を読むのが一番です。
もしくは本家の論文 も大変読みやすいです。
Transformer を作る前にざっと目を通しておくことをおすすめします。
Transformer を作る
「作る」は「理解する」の近道です。
ここからは作ることで Transformer を理解していきましょう。
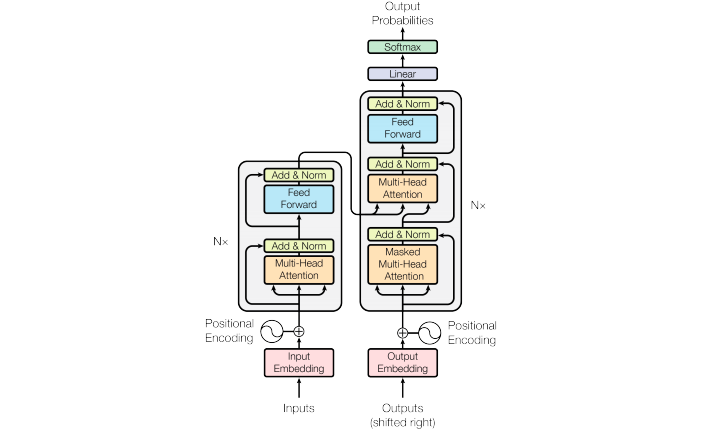
Transformer も BERT も、基本的な Attention の仕組みを理解できれば難しくはありません。
まずは(実用性はおいておいて)基本的な Attention を作っていきましょう。
基本的な Attention
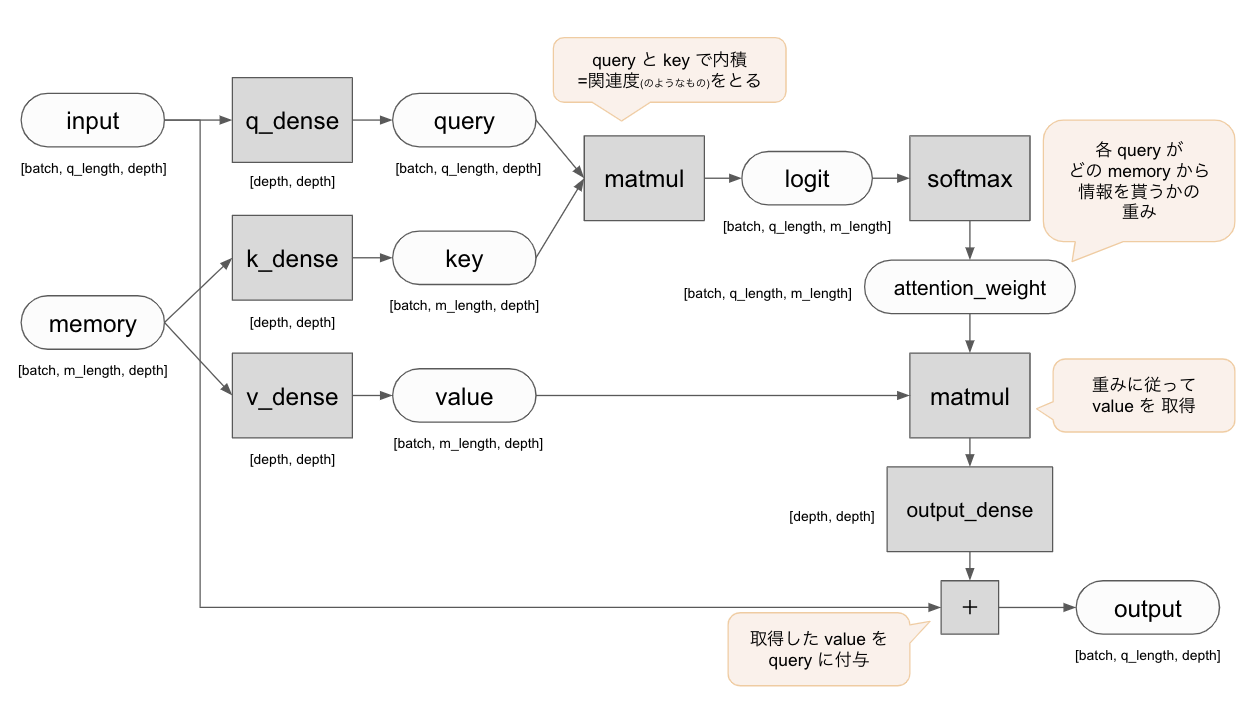
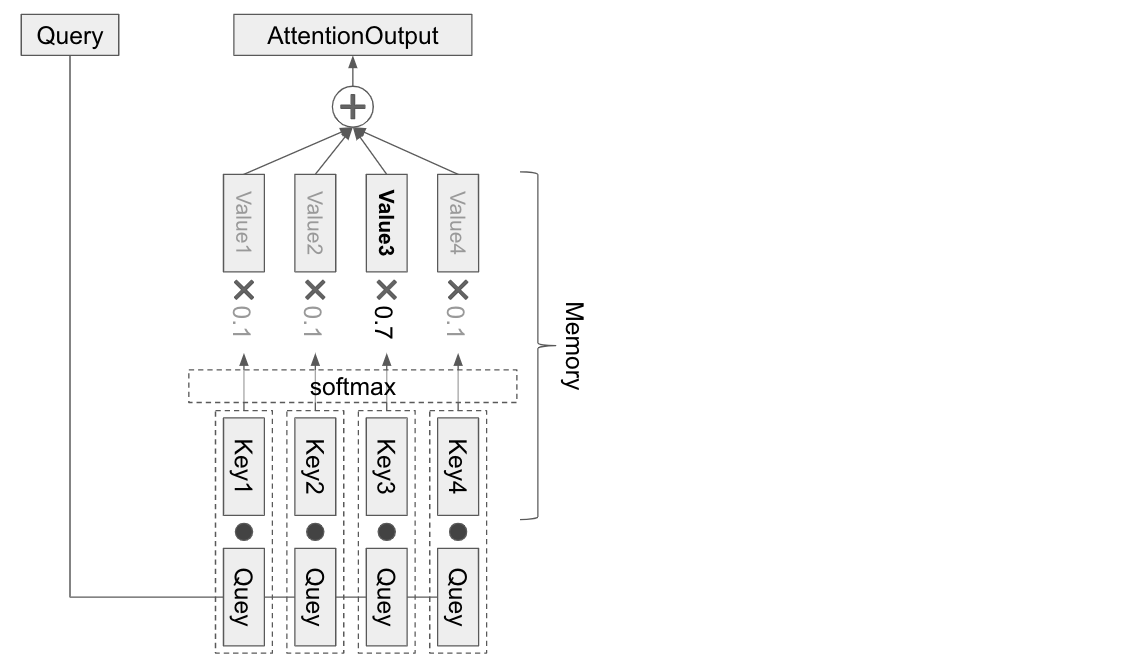
Attention の基本は query と memory(key, value) です。
Attention とは query によって memory から必要な情報を選択的に引っ張ってくることです。
memory から情報を引っ張ってくるときには、 query は key によって取得する memory を決定し、対応する value を取得します。
まずは基本的な Attention として下記のようなネットワークを作ってみましょう。
丸は Tensor, 四角はレイヤーもしくは処理を表しています。
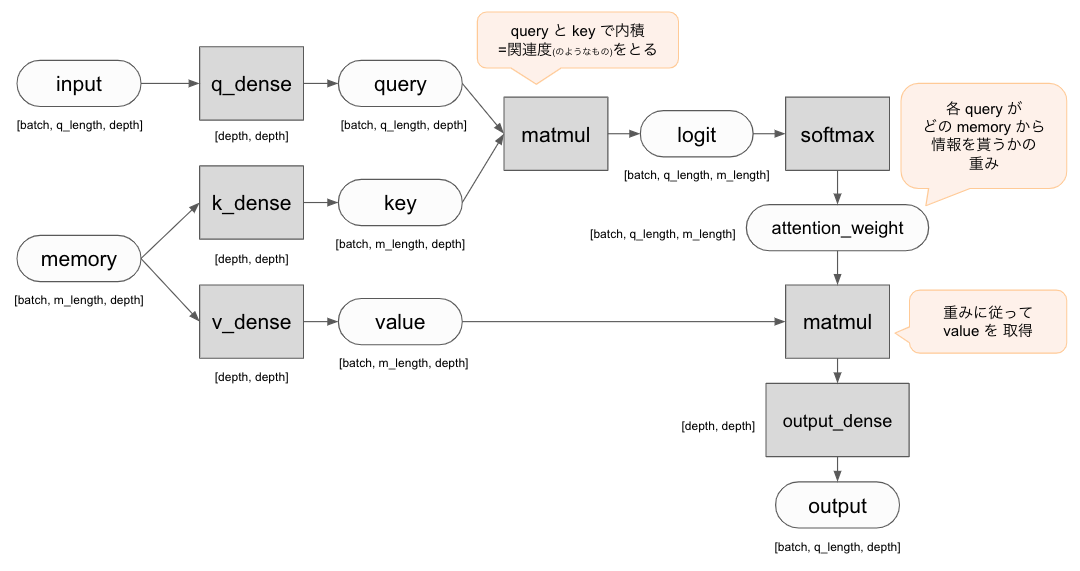
コードで書くと以下のようになります。
transformer/attention.py
class SimpleAttention(tf.keras.models.Model):
'''
Attention の説明をするための、 Multi-head ではない単純な Attention です
'''
def __init__(self, depth: int, *args, **kwargs):
'''
コンストラクタです。
:param depth: 隠れ層及び出力の次元
'''
super().__init__(*args, **kwargs)
self.depth = depth
self.q_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='q_dense_layer')
self.k_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='k_dense_layer')
self.v_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='v_dense_layer')
self.output_dense_layer = tf.keras.layers.Dense(depth, use_bias=False, name='output_dense_layer')
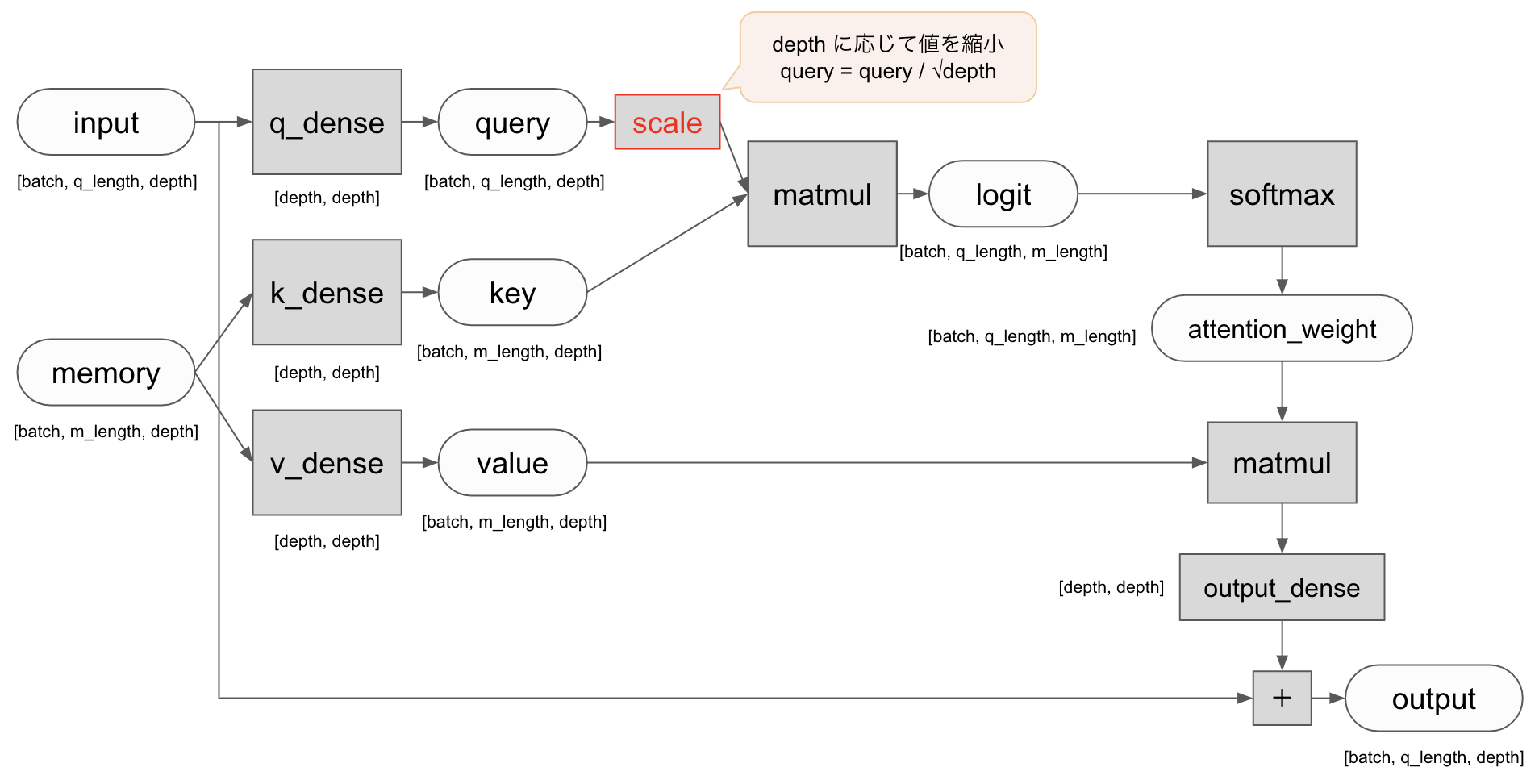
def call(self, input: tf.Tensor, memory: tf.Tensor) -> tf.Tensor:
'''
モデルの実行を行います。
:param input: query のテンソル
:param memory: query に情報を与える memory のテンソル
'''
q = self.q_dense_layer(input) # [batch_size, q_length, depth]
k = self.k_dense_layer(memory) # [batch_size, m_length, depth]
v = self.v_dense_layer(memory)
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, q_length, k_length]
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
# 重みに従って value から情報を引いてきます
attention_output = tf.matmul(attention_weight, v) # [batch_size, q_length, depth]
return self.output_dense_layer(attention_output)
細かく見ていきます。
input, memory
def call(self, input: tf.Tensor, memory: tf.Tensor) -> tf.Tensor:

入出力は input と memory です。
- input (query): 入力の時系列
- memory: 引いてくる情報の時系列
これらの Tensor の shape は [batch_size, q_length, depth] と [batch_size, m_length, depth] です。
length は文章中のトークンの長さ(例えば1文の中の最大単語数など)です。
depth は各単語を Embedding した次元数です。
バッチの中のデータ一つをとってくると、このようなデータが入っています。
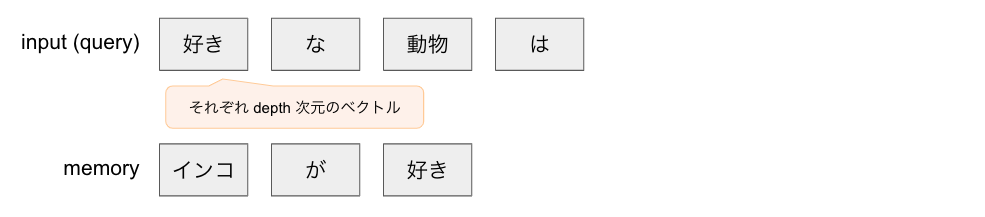
この図だと、 q_length=4, m_length=3 ですね。
それぞれのブロックは、「好き」などの元々は単語等であったトークンを depth 次元の分散表現に直したものです。
query, key, value を作る
q = self.q_dense_layer(input) # [batch_size, q_length, depth]
k = self.k_dense_layer(memory) # [batch_size, m_length, depth]
v = self.v_dense_layer(memory)

input は Dense レイヤーで変換されて query に、 memory は2つの Dense レイヤーでそれぞれ key, value に変換されます。
attention weight を計算する
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, q_length, k_length]
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
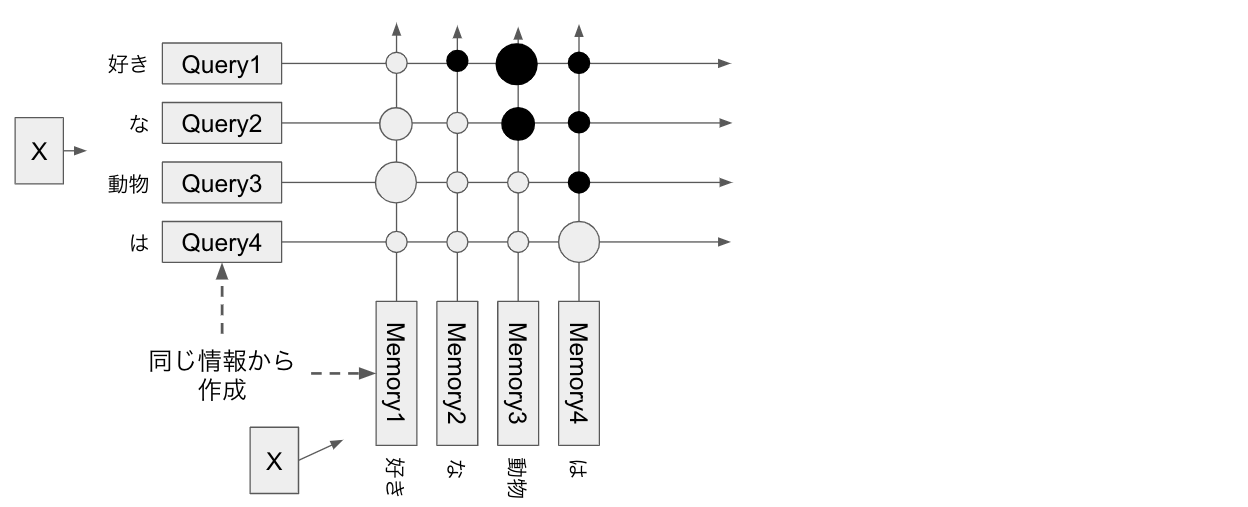
 query は、 memory のどこから情報を引いてくるかを決めるために key を使います。(key は memory を変換したものでしたね。)
例えば `動物` というクエリに対して「`インコ` が50%、 `が`が5%、 `好き` が45%かなー」などと計算します。

query は、 memory のどこから情報を引いてくるかを決めるために key を使います。(key は memory を変換したものでしたね。)
例えば `動物` というクエリに対して「`インコ` が50%、 `が`が5%、 `好き` が45%かなー」などと計算します。

この計算は具体的には、 query と key の行列積(matmul)をとることで計算されます。
行列積なので、 query と key のそれぞれのベクトルが似た方向を向いていれば値は大きくなりますね。大雑把に言うと query と key の近さを計算していると私は理解しています。(ただし query, memory ともにベクトルの長さはそれぞれバラバラなので実際にはそのように単純ではありません。)
行列積をとった後は softmax をかけることで、query ごとの weight の合計が1.0になるように正規化しています。
さて、これで attention_weight ができました。 shape は [batch_size, q_length, k_length] です。
[q_length, k_length] の部分を見ると下のような行列になっています。
| q_0 ← m_0 | q_0 ← m_1 | ... | q_0 ← m_M |
|---|---|---|---|
| q_1 ← m_0 | q_1 ← m_1 | ... | q_1 ← m_M |
| ... | ... | ... | ... |
| q_N ← m_0 | q_N ← m_1 | ... | q_N ← m_M |
q_i ← m_j は i 番目のquery が j 番目の memory から情報を引いてくる重みを表します。
Softmax をかけているので、各行の値は足すと1.0になります。
先程の図の query 「動物」を考えると、表の idx=2 行目が 0.5, 0.05, 0.45 になるということですね。
attention weight に従って value から情報を引き出す
# 重みに従って value から情報を引いてきます
attention_output = tf.matmul(attention_weight, v) # [batch_size, q_length, depth]
return self.output_dense_layer(attention_output)
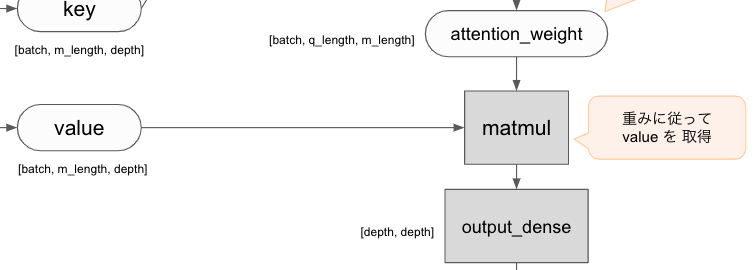
重みと value の行列積を取ることで、重みに従って value の情報を引いてきます。
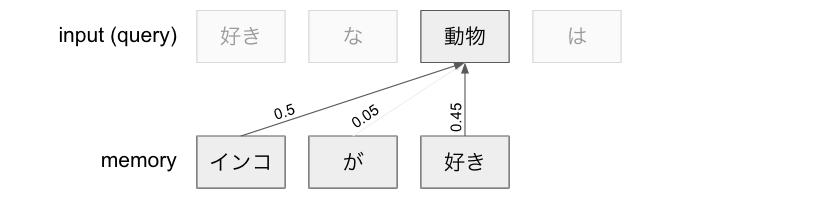
例えば上の図であれば、 動物 の query (つまり query[batch, 2, :]) の位置の値は value(インコ) * 0.5 + value(が) * 0.05 + value(好き) * 0.45 になります。
得られたベクトルを Dense で変換したものがこのレイヤー出力になります。
まとめ
- attention は query によって memory (=key, value) から情報を引き出す仕組み
- key, value は memory を変換してつくる
- query と key から attention weight を計算する
- attention weight に従って value から情報を引き出す
別の書き方をするとこんな感じになります。
Attention の使い方
Attention には大きく2つの使い方があります。
Self-Attention
input (query) と memory (key, value) すべてが同じ Tensor を使う Attention です。
attention_layer = SimpleAttention(depth=128)
x: tf.Tensor = ...
attention_output = attention_layer(input=x, memory=x)
Self-Attention は言語の文法構造であったり、照応関係(its が指してるのは Law だよねとか)を獲得するのにも使われているなどと論文では分析されています。
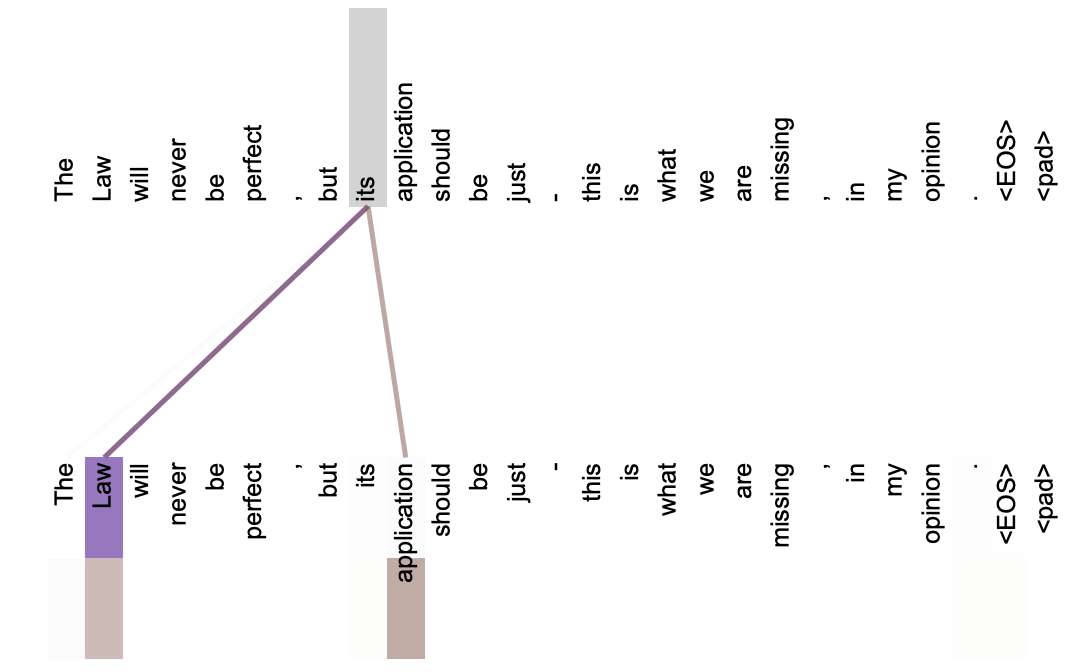
(上段が query. its という query が Law, application という memory から情報を引いていることがわかる)
Self-Attention は汎用に使える仕組みで、 Transformer の Encoder 部分、 Decoder 部分のどちらでも使われていますし、文章分類などでは後述する SourceTarget-Attention は必要なく Self-Attention のみで作ることができます。
SourceTarget-Attention
input (query) と memory (key, value) の2つが別の Tensor を使う Attention です。
attention_layer = SimpleAttention(depth=128)
x: tf.Tensor = ...
y: tf.Tensor = ...
attention_output = attention_layer(input=x, memory=y)
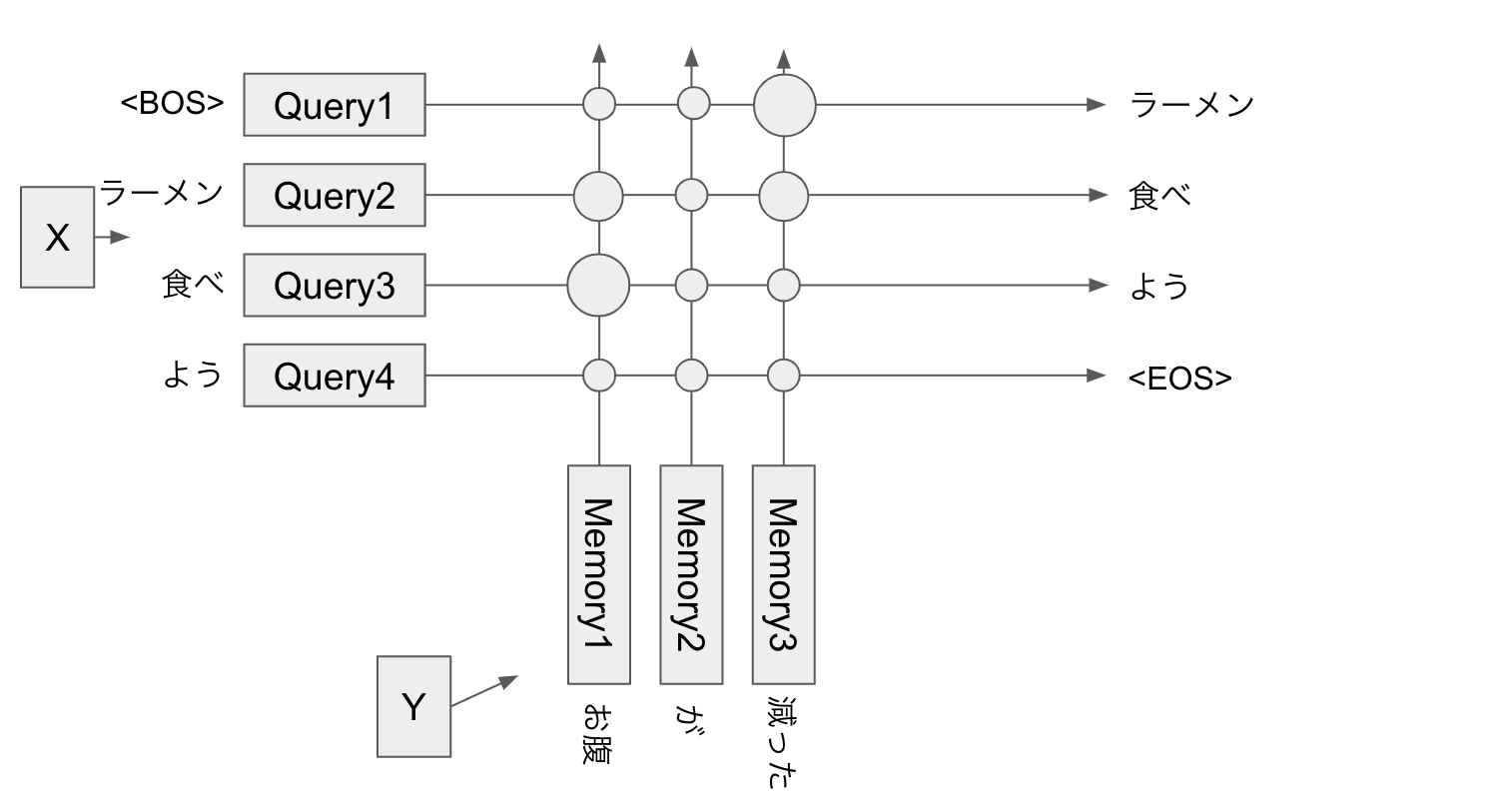
SourceTarget-Attention は Transformer では Decoder で使われます。
Decoder はある時刻 t のトークンを受け取って t+1 の時刻のトークンを予測します。
お腹 / が/ 減った → ラーメン / 食べ / よう という発話応答を学習する場合、
- memory 過去の発話
お腹 / が / 減った - input は
<BOS> / ラーメン / 食べ / よう(BOS は Begin of Sentence を表すトークン)
として、出力が input の1時刻あと、つまり ラーメン / 食べ / よう / <EOS> となるようにして学習します。(EOS: End Of Sentence)
生成時には、 query <BOS> は memory お腹 / が/ 減った から情報を取り出してきて ラーメン を生成します。次に生成された ラーメン query に加え、 query <BOS> / ラーメン は同じ memory から情報をとってきて ラーメン / 食べ を生成します。といった具合で1トークンずつ生成を行います。
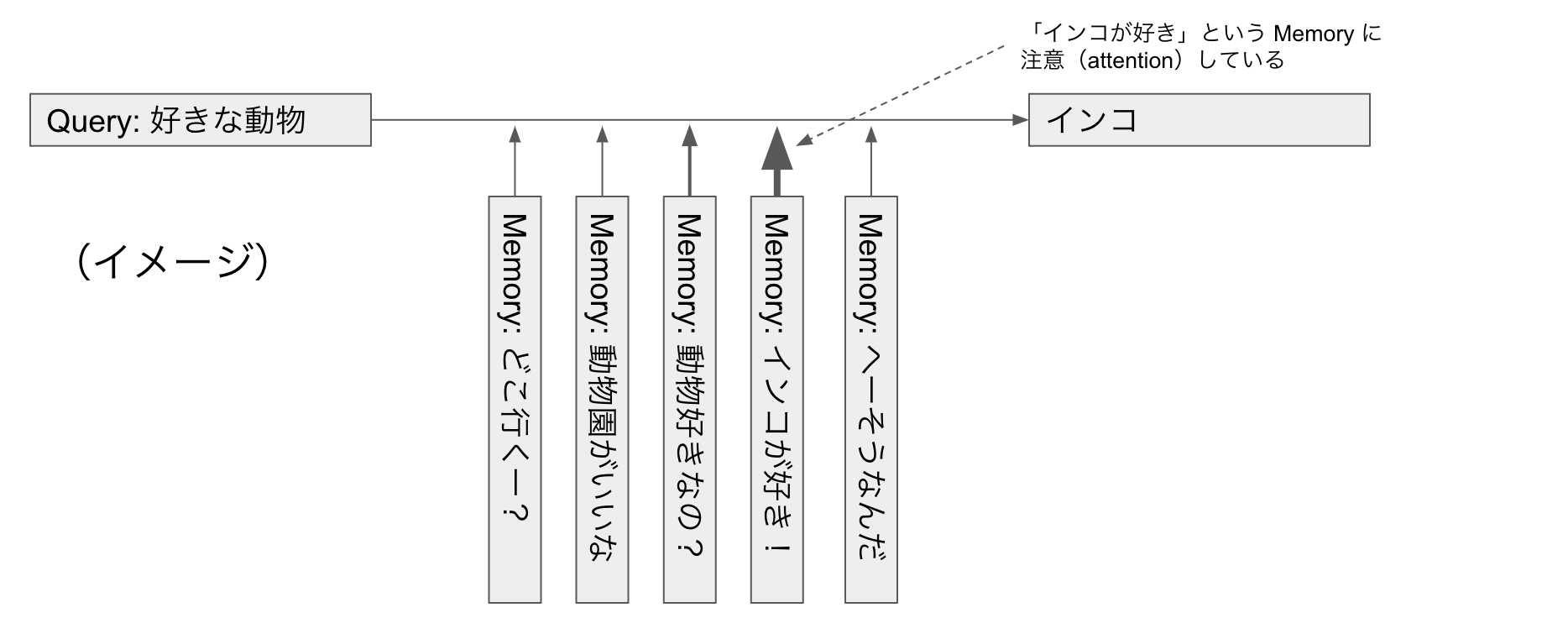
SourceTarget-Attention は Transformer ではこのように Decoder で使われていますが、 End-to-End Memory Network(日本語解説記事) ではもっとダイレクトに query を質問:「好きな動物」などとし、 memory は「どこ行くー?」「動物園がいいな」「動物好きなの?」「インコが好き!」「へーそうなんだ」といった文章列として、 query は一番関係ありそうな文(ここだと「インコが好き!」)から情報を引いてきて「インコ」と答えます。
Scaled Dot-production
ここから先のセクションでは基本の Attention に加えて、学習をうまく行うための Transformer に実装されているいろいろな仕組みを紹介していきます。
まずは Scaled Dot-production です。
Softmax 関数は、 logit の値が大きいと値がサチってしまい、 gradient が0に近くなってしまいます。
Softmax の logit は query と key の行列積です。従って、 query, key の次元(depth)が大きいほど logit は大きくなります。
そこで、 query の大きさを depth に従って小さくしてあげます。
attention\_weight = softmax \left( \frac{qk^T}{\sqrt{depth}} \right)
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
q *= depth ** -0.5 # scaled dot-product
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, q_length, k_length]
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
Mask
mask は特定の key に対して attention_weight を0にするために使います。
attention_weight は Softmax の出力なので、その入力である logit に対し、 mask したい要素は -∞ に値を書き換えてやります。
なぜ -∞ かというと、 $softmax_i = \frac{e^{x_i}}{\sum_j e^{x_j}}$ なので消したい $x_j$ が -∞ になると $e^{x_j} \to e^{- \infty} = 0$ になるからです。
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, head_num, q_length, k_length]
logit += tf.to_float(attention_mask) * input.dtype.min # mask は pad 部分などが1, 他は0
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
attention_mask は shape が [batch_size, q_length, m_length] で dtype が bool の Tensor です。0にしたい部分が True となっています。
これによって Mask が True の部分は input.dtype.min ≒ マイナス無限大な値になります。
attention_weight を0にしたい場合は次の2つがあります。
- PAD を無視したい
- Decoder の Self-Attention で未来の情報を参照できないようにしたい
PAD を無視したい
ニューラルネットに入力される文章(トークン列)の長さは batch によって様々です。
例えば key に入ってくる文章が
[
おはよう,
インコ / が / 好き,
お腹 / へった,
]
だとしましょう。それぞれ長さは [1, 3, 2] です。このままでは長さがバラバラで Tensor に変換できないので、 PAD を追加してあげます。
[
おはよう / <PAD> / <PAD>,
インコ / が / 好き,
お腹 / へった / <PAD>,
]
これで、このデータは 3 x 3 の Tensor になります。(実際は各トークンは Embedding されたベクトルなので、 3 x 3 x depth の Tensor になります)
さて、しかし attention_weight を計算するときには PAD は無視したいところです。
なぜなら PAD がいくつあるかはバッチの作り方(そのバッチ内の他の文の長さ)で異なってくるため、本来お互い干渉するべきではないバッチ内の他の文によって出力が変わってしまうためです。
(たとえば上の例のバッチの他のデータに「インコ / は / かわいい / ん / じゃ / あ / あ / あ / あ」など長いものがあれば上の例の PAD がたくさん増え、もし PAD を無視しないとそれによって計算結果が変わってしまいます。)
そこで、 PAD の部分にはマスクをしましょう。マスクは attention_weight に適用するものですので、 shape は [batch_size, q_length, m_length] になります。(後述する Multi-head Attention ではここに head の次元も加わります。)
例えば memory = おはよう / <PAD> / <PAD> に対する mask は次のようになります。
(仮に query の長さが4とします)
[[False, True, True],
[False, True, True],
[False, True, True],
[False, True, True]]
行が query の長さ、列が key の長さになっています。 key の idx=1,2 が Mask されていますね。
ではこれらの Mask はどうやって作るのか??というところは最後の全体像でコードを載せます。
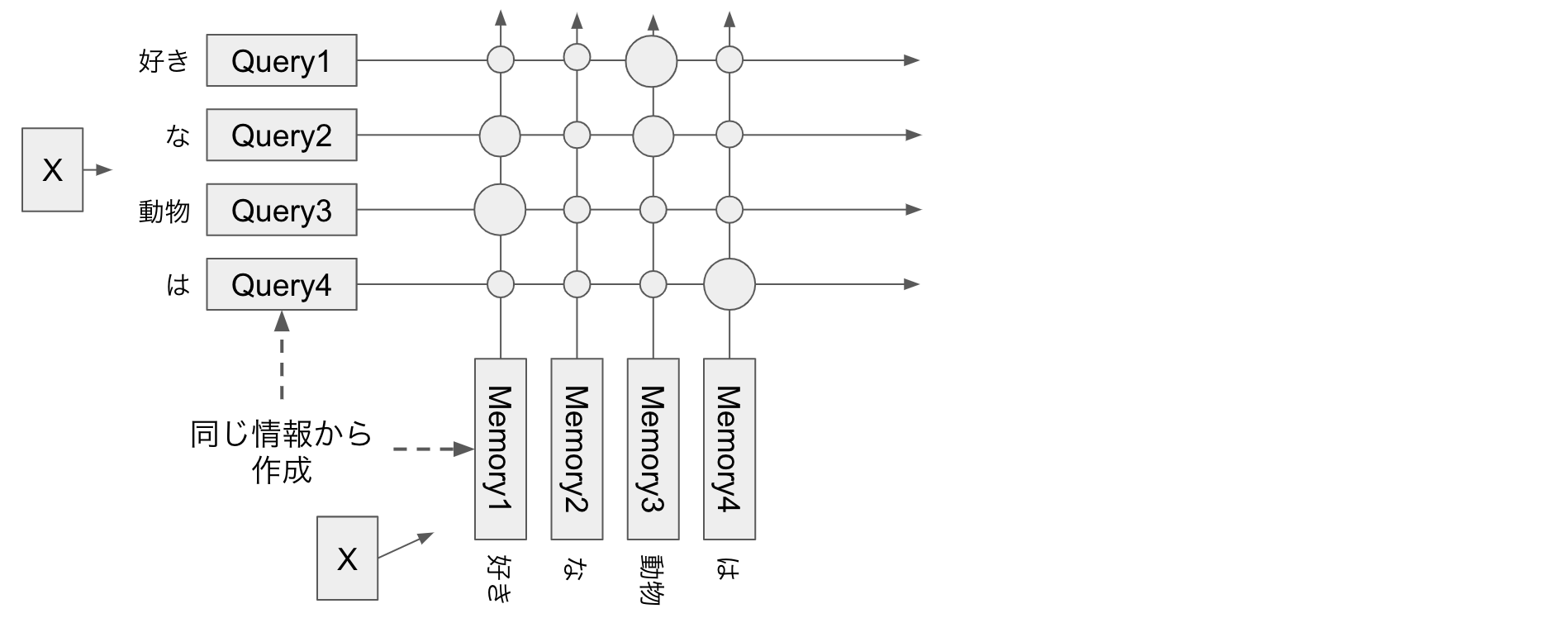
Decoder の Self-Attention で未来の情報を参照できないようにしたい
Decoder は推論時はある時刻tの入力からt+1を予測し、その予測を次の入力に回してさらにそのさきを予測します。(自己回帰。)
一方学習のときにはすべての時刻で同時に次の時刻のトークンを予測する学習を行います。
この時 Self-Attention で予測対象の未来の情報が得られてしまうと困ります。
上の図で、 query が「好き / な」までしかまだ生成されていないのに、 memory の未来の情報「動物」を参照できたら困りますね。(推論時には未来の情報は当然与えられないので)
なので、 query は自分の時刻より先の memory の情報を参照できなくする必要があります。
図で書くと上の黒丸のところを mask する必要があります。
つまりこの図の場合 mask は次のようになります。
[[False, True, True, True],
[False, False, True, True],
[False, False, False, True],
[False, False, False, False]]
Multi-head Attention
Multi-head Attention は、これまでのような Simple Attention をパラレルに並べるものです。
それぞれの attention を head と呼びます。
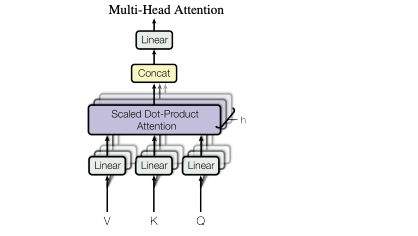
論文では一つの大きな Attention を行うよりも、小さな複数の head に分けて Attention を行うほうが性能が上がったと書かれています。
仕組みは単純で、 query, key, value をそれぞれ head_num 個に split してからそれぞれ attention を計算し、最後に concat するだけです。
この Multi-head Attention が RNN における LSTM, GRU セルのように Attention ベースのモデルの基本単位になってきます。
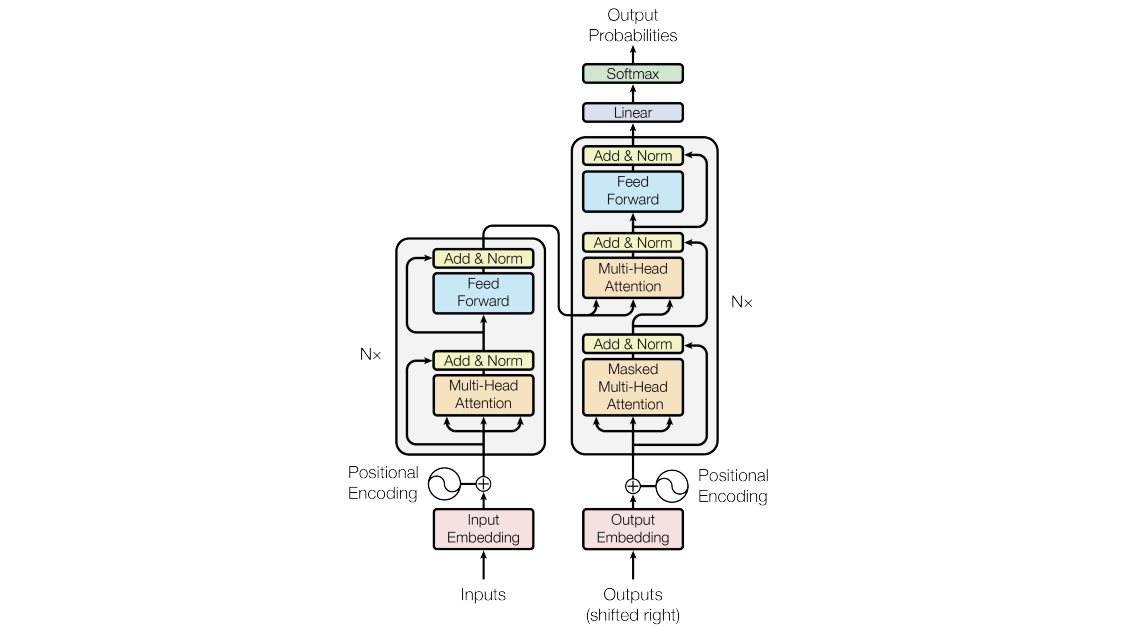
さて、これまでの Simple Attention, Scaled Dot-production, Mask, Multi-head Attention を合わせると以下のような Attention モジュールができます。
論文や本家実装では、この他に随所に Dropout を追加して汎化性能を上げているのでこれも追加します。
class MultiheadAttention(tf.keras.models.Model):
'''
Multi-head Attention のモデルです。
model = MultiheadAttention(
hidden_dim=512,
head_num=8,
dropout_rate=0.1,
)
model(query, memory, mask, training=True)
'''
def __init__(self, hidden_dim: int, head_num: int, dropout_rate: float, *args, **kwargs):
'''
コンストラクタです。
:param hidden_dim: 隠れ層及び出力の次元
head_num の倍数である必要があります。
:param head_num: ヘッドの数
:param dropout_rate: ドロップアウトする確率
'''
super().__init__(*args, **kwargs)
self.hidden_dim = hidden_dim
self.head_num = head_num
self.dropout_rate = dropout_rate
self.q_dense_layer = tf.keras.layers.Dense(hidden_dim, use_bias=False, name='q_dense_layer')
self.k_dense_layer = tf.keras.layers.Dense(hidden_dim, use_bias=False, name='k_dense_layer')
self.v_dense_layer = tf.keras.layers.Dense(hidden_dim, use_bias=False, name='v_dense_layer')
self.output_dense_layer = tf.keras.layers.Dense(hidden_dim, use_bias=False, name='output_dense_layer')
self.attention_dropout_layer = tf.keras.layers.Dropout(dropout_rate)
def call(
self,
input: tf.Tensor,
memory: tf.Tensor,
attention_mask: tf.Tensor,
training: bool,
) -> tf.Tensor:
'''
モデルの実行を行います。
:param input: query のテンソル
:param memory: query に情報を与える memory のテンソル
:param attention_mask: attention weight に適用される mask
shape = [batch_size, 1, q_length, k_length] のものです。
pad 等無視する部分が True となるようなものを指定してください。
:param training: 学習時か推論時かのフラグ
'''
q = self.q_dense_layer(input) # [batch_size, q_length, hidden_dim]
k = self.k_dense_layer(memory) # [batch_size, m_length, hidden_dim]
v = self.v_dense_layer(memory)
q = self._split_head(q) # [batch_size, head_num, q_length, hidden_dim/head_num]
k = self._split_head(k) # [batch_size, head_num, m_length, hidden_dim/head_num]
v = self._split_head(v) # [batch_size, head_num, m_length, hidden_dim/head_num]
depth = self.hidden_dim // self.head_num
q *= depth ** -0.5 # for scaled dot production
# ここで q と k の内積を取ることで、query と key の関連度のようなものを計算します。
logit = tf.matmul(q, k, transpose_b=True) # [batch_size, head_num, q_length, k_length]
logit += tf.to_float(attention_mask) * input.dtype.min # mask は pad 部分などが1, 他は0
# softmax を取ることで正規化します
attention_weight = tf.nn.softmax(logit, name='attention_weight')
attention_weight = self.attention_dropout_layer(attention_weight, training=training)
# 重みに従って value から情報を引いてきます
attention_output = tf.matmul(attention_weight, v) # [batch_size, head_num, q_length, hidden_dim/head_num]
attention_output = self._combine_head(attention_output) # [batch_size, q_length, hidden_dim]
return self.output_dense_layer(attention_output)
def _split_head(self, x: tf.Tensor) -> tf.Tensor:
'''
入力の tensor の hidden_dim の次元をいくつかのヘッドに分割します。
入力 shape: [batch_size, length, hidden_dim] の時
出力 shape: [batch_size, head_num, length, hidden_dim//head_num]
となります。
'''
with tf.name_scope('split_head'):
batch_size, length, hidden_dim = tf.unstack(tf.shape(x))
x = tf.reshape(x, [batch_size, length, self.head_num, self.hidden_dim // self.head_num])
return tf.transpose(x, [0, 2, 1, 3])
def _combine_head(self, x: tf.Tensor) -> tf.Tensor:
'''
入力の tensor の各ヘッドを結合します。 _split_head の逆変換です。
入力 shape: [batch_size, head_num, length, hidden_dim//head_num] の時
出力 shape: [batch_size, length, hidden_dim]
となります。
'''
with tf.name_scope('combine_head'):
batch_size, _, length, _ = tf.unstack(tf.shape(x))
x = tf.transpose(x, [0, 2, 1, 3])
return tf.reshape(x, [batch_size, length, self.hidden_dim])
また、 Multi-head Attention を継承して Self-Attention も作ります。
これは単に Multi-head Attention の memory に input を渡すだけです。
class SelfAttention(MultiheadAttention):
def call( # type: ignore
self,
input: tf.Tensor,
attention_mask: tf.Tensor,
training: bool,
) -> tf.Tensor:
return super().call(
input=input,
memory=input,
attention_mask=attention_mask,
training=training,
)
Hopping
Multi-head Attention を何度も繰り返し適用することで、より複雑な学習ができるようにします。

RNN とは違って、この各 Attention はそれぞれ独立した重みを持っています。
そのため何回 Hopping をするかは固定です。(これを可変にした Universal Transformer というモデルもあります。)
Position-wise Feedforward Network
各 Hopping の Attention のあとには FFN をはさみます。この FFN は全時刻で同じ変換がなされます。

FFN は2層で、第一層の次元は hidden_dim * 4 で ReLU, 第二層の次元は hidden_dim で Linear な activation function をもちます。
class FeedForwardNetwork(tf.keras.models.Model):
'''
Transformer 用の Position-wise Feedforward Neural Network です。
'''
def __init__(self, hidden_dim: int, dropout_rate: float, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.hidden_dim = hidden_dim
self.dropout_rate = dropout_rate
self.filter_dense_layer = tf.keras.layers.Dense(hidden_dim * 4, use_bias=True,
activation=tf.nn.relu, name='filter_layer')
self.output_dense_layer = tf.keras.layers.Dense(hidden_dim, use_bias=True, name='output_layer')
self.dropout_layer = tf.keras.layers.Dropout(dropout_rate)
def call(self, input: tf.Tensor, training: bool) -> tf.Tensor:
'''
FeedForwardNetwork を適用します。
:param input: shape = [batch_size, length, hidden_dim]
:return: shape = [batch_size, length, hidden_dim]
'''
tensor = self.filter_dense_layer(input)
tensor = self.dropout_layer(tensor, training=training)
return self.output_dense_layer(tensor)
LayerNormalization
画像処理系の Deep Learning では Batch Normalization が有名ですが、 Transformer では Layer Normalization を使います。
実は tf.keras には実装が無いので自前で作ります。
transformer/common_layer.py
class LayerNormalization(tf.keras.layers.Layer):
def build(self, input_shape: tf.TensorShape) -> None:
hidden_dim = input_shape[-1]
self.scale = self.add_weight('layer_norm_scale', shape=[hidden_dim],
initializer=tf.ones_initializer())
self.bias = self.add_weight('layer_norm_bias', [hidden_dim],
initializer=tf.zeros_initializer())
super().build(input_shape)
def call(self, x: tf.Tensor, epsilon: float = 1e-6) -> tf.Tensor:
mean = tf.reduce_mean(x, axis=[-1], keepdims=True)
variance = tf.reduce_mean(tf.square(x - mean), axis=[-1], keepdims=True)
norm_x = (x - mean) * tf.rsqrt(variance + epsilon)
return norm_x * self.scale + self.bias
ResidualNormalizationWrapper
Transformer はあちこちに Layer Normalization, Dropout, Residual Connection などの正則化をいれています。
これらを素で書いていくと辛いので、レイヤーを受け取ってそのレイヤーに対して各種 Normalization を施すラッパーを作ります。

(本家コード では PrePostProcessingWrapper という名前になっています)
class ResidualNormalizationWrapper(tf.keras.models.Model):
def __init__(self, layer: tf.keras.layers.Layer, dropout_rate: float, *args, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.layer = layer
self.layer_normalization = LayerNormalization()
self.dropout_layer = tf.keras.layers.Dropout(dropout_rate)
def call(self, input: tf.Tensor, training: bool, *args, **kwargs) -> tf.Tensor:
tensor = self.layer_normalization(input)
tensor = self.layer(tensor, training=training, *args, **kwargs)
tensor = self.dropout_layer(tensor, training=training)
return input + tensor
Positional Encoding
上記の仕組みだけでは、 Transformer は文章内のトークンの順序を学習に使うことができません。
つまり 私 / は / 君 / より / 賢い と 君 / は / 私 / より / 賢い は全く同じデータになってしまいます。
そこで、各トークンがどの位置にあるのかを表すための値、 Positional Encoding を各トークンを Embedding したものに足します。
この Positional Encoding は次のような数式で計算されます。
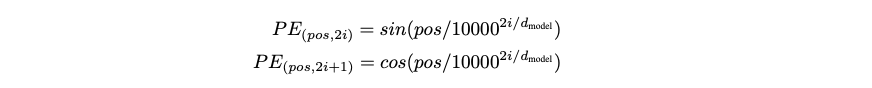
- pos: 時刻
- 2i, 2i+1: Embedding の何番目の次元か
このような数式を選んだ理由としては、この式が相対的な位置($PE_{pos+k}$)を $PE_{pos}$ の線形関数で表現可能(=ニューラルネットが学習しやすいはず)だからとのことです。
試しに偶数番目の次元について計算してみましょう。
u_i = \frac{1}{10000^{2i / d_{model}}} \\
PE_{p, 2i} = sin \left( pu_i \right) \\
PE_{p, 2i+1} = cos \left( pu_i \right) \\
として
PE_{p+k, 2i} = sin \left( (p+k)u_i \right) \\
= sin(pu_i) cos(ku_i) + cos(pu_i) sin(ku_i) \\
= PE_{p, 2i} cos(ku_i) + PE_{p, 2i+1} sin(ku_i)
となり、 $PE_{p, 2i}$ 及び $PE_{p, 2i+1}$ の線形和で表せることがわかりました。
実装は以下のようにしました。(本家のコードとは大きく違います)
cos(x) = sin(x + π/2) であることを使っています。
class AddPositionalEncoding(tf.keras.layers.Layer):
'''
入力テンソルに対し、位置の情報を付与して返すレイヤーです。
see: https://arxiv.org/pdf/1706.03762.pdf
PE_{pos, 2i} = sin(pos / 10000^{2i / d_model})
PE_{pos, 2i+1} = cos(pos / 10000^{2i / d_model})
'''
def call(self, inputs: tf.Tensor) -> tf.Tensor:
fl_type = inputs.dtype
batch_size, max_length, depth = tf.unstack(tf.shape(inputs))
depth_counter = tf.range(depth) // 2 * 2 # 0, 0, 2, 2, 4, ...
depth_matrix = tf.tile(tf.expand_dims(depth_counter, 0), [max_length, 1]) # [max_length, depth]
depth_matrix = tf.pow(10000.0, tf.cast(depth_matrix / depth, fl_type)) # [max_length, depth]
# cos(x) == sin(x + π/2)
phase = tf.cast(tf.range(depth) % 2, fl_type) * math.pi / 2 # 0, π/2, 0, π/2, ...
phase_matrix = tf.tile(tf.expand_dims(phase, 0), [max_length, 1]) # [max_length, depth]
pos_counter = tf.range(max_length)
pos_matrix = tf.cast(tf.tile(tf.expand_dims(pos_counter, 1), [1, depth]), fl_type) # [max_length, depth]
positional_encoding = tf.sin(pos_matrix / depth_matrix + phase_matrix)
# [batch_size, max_length, depth]
positional_encoding = tf.tile(tf.expand_dims(positional_encoding, 0), [batch_size, 1, 1])
return inputs + positional_encoding
本家の実装 は論文とは微妙に違います。論文では各時刻の PE は [sin, cos, sin, cos, ...] と交互に並ぶのですが、本家実装では [sin, sin, ..., cos, cos, ...] と並ぶ様になっています。ただ上の式変換でわかるように、要は sin に対応する cos の要素があればいいだけなのでこうしているものと思われます。
ちなみに Positional Encoding は必ずしもこの形である必要があるわけではなく BERT では Positional Encoding を変数にしてしまって学習で獲得するようにしています。
Token Embedding
文を単語などで分割した各トークンは数値(int)なのですが、 DeepLearning で扱うためにはこれを Embedded Vector にする必要があります。
tensorflow で言語処理をやったことがある人にはおなじみ tf.nn.embedding_lookup ですね。
本家のコードを覗いてみると、最後に embedding を隠れ層の次元(hidden_dim)に応じてスケールさせているようです。
以下のように実装してみます。
PAD_ID = 0
class TokenEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size: int, embedding_dim: int, dtype=tf.float32, *args, **kwargs):
super().__init__(*args, **kwargs)
self.vocab_size = vocab_size
self.embedding_dim = embedding_dim
self.dtype_ = dtype
def build(self, input_shape: tf.TensorShape) -> None:
self.lookup_table = self.add_variable(
name='token_embedding',
shape=[self.vocab_size, self.embedding_dim],
dtype=self.dtype_,
initializer=tf.random_normal_initializer(0., self.embedding_dim ** -0.5),
)
super().build(input_shape)
def call(self, input: tf.Tensor) -> tf.Tensor:
mask = tf.to_float(tf.not_equal(input, PAD_ID))
embedding = tf.nn.embedding_lookup(self.lookup_table, input)
embedding *= tf.expand_dims(mask, -1) # 元々 PAD だった部分を0にする
return embedding * self.embedding_dim ** 0.5
これで細かい部品は出揃いました!
Encoder
Transformer は大きく Encoder と Decoder からなります。
ここでは入力トークン列をエンコードする Encoder を作ります。
Encoder は Self-Attention によって入力をエンコードしていきます。
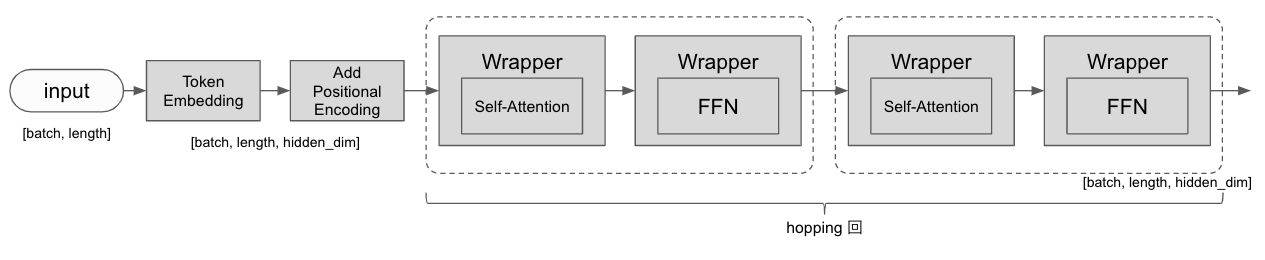
Wrapper は ResidualNormalizationWrapper です。
class Encoder(tf.keras.models.Model):
'''
トークン列をベクトル列にエンコードする Encoder です。
'''
def __init__(
self,
vocab_size: int,
hopping_num: int,
head_num: int,
hidden_dim: int,
dropout_rate: float,
max_length: int,
*args,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.hopping_num = hopping_num
self.head_num = head_num
self.hidden_dim = hidden_dim
self.dropout_rate = dropout_rate
self.token_embedding = TokenEmbedding(vocab_size, hidden_dim)
self.add_position_embedding = AddPositionalEncoding()
self.input_dropout_layer = tf.keras.layers.Dropout(dropout_rate)
self.attention_block_list: List[List[tf.keras.models.Model]] = []
for _ in range(hopping_num):
attention_layer = SelfAttention(hidden_dim, head_num, dropout_rate, name='self_attention')
ffn_layer = FeedForwardNetwork(hidden_dim, dropout_rate, name='ffn')
self.attention_block_list.append([
ResidualNormalizationWrapper(attention_layer, dropout_rate, name='self_attention_wrapper'),
ResidualNormalizationWrapper(ffn_layer, dropout_rate, name='ffn_wrapper'),
])
self.output_normalization = LayerNormalization()
def call(
self,
input: tf.Tensor,
self_attention_mask: tf.Tensor,
training: bool,
) -> tf.Tensor:
'''
モデルを実行します
:param input: shape = [batch_size, length]
:param training: 学習時は True
:return: shape = [batch_size, length, hidden_dim]
'''
# [batch_size, length, hidden_dim]
embedded_input = self.token_embedding(input)
embedded_input = self.add_position_embedding(embedded_input)
query = self.input_dropout_layer(embedded_input, training=training)
for i, layers in enumerate(self.attention_block_list):
attention_layer, ffn_layer = tuple(layers)
with tf.name_scope(f'hopping_{i}'):
query = attention_layer(query, attention_mask=self_attention_mask, training=training)
query = ffn_layer(query, training=training)
# [batch_size, length, hidden_dim]
return self.output_normalization(query)
(参考) Attention ベースの識別器
すこし横道にそれて、 Transformer ではなく Attention ベースの識別器の作り方の話です。
多くのタスクでは、問い合わせのカテゴリ分類であったり感情識別であったり、自然言語処理のタスクは文章生成ではなく文書識別です。
文書識別のタスクを行うには後述する Decoder は必要なく Encoder に一層 Dense Layer をかぶせるだけでできます。
詳しくは BERT の論文が参考になりますが以下のように作ります。
- Encoder への入力の最初(時刻0)の位置に
<CLS>というトークンを入れる-
<CLS> / ああ / 楽しい / ことが / あったのようなデータになります
-
- Encoder に入力し、
<CLS>の位置の出力のみを取り出します。 - これに Dense Layer をかぶせて識別したいクラスの数の次元に変換します
- あとは softmax をかけたり cross entropy を計算して loss にします
encoder_output = self.encoder_layer(...)
cls_vector = encoder_output[:, 0:, :] # cls は必ず文書の最初の位置にあるから `0`
classification_logit = self.dense_layer(cls_vector)
prob = tf.nn.sofrmax(classification_logit)
今回のネットワーク構造では識別器に複数の文を入れることはできませんが、 BERT ではそのへんの工夫もされているのでぜひ論文を読んでみてください。
Decoder
Encoder と同様に Decoder を作ります。
Decoder はまず入力に Self-Attention をかけてから、 SourceTarget-Attention で Encoder がエンコードした情報を取り込みます。
これによって、時刻 0〜t のトークン列を入力として時刻 1〜t+1 のトークン列(つまり1時刻未来)を出力します。

class Decoder(tf.keras.models.Model):
'''
エンコードされたベクトル列からトークン列を生成する Decoder です。
'''
def __init__(
self,
vocab_size: int,
hopping_num: int,
head_num: int,
hidden_dim: int,
dropout_rate: float,
max_length: int,
*args,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.hopping_num = hopping_num
self.head_num = head_num
self.hidden_dim = hidden_dim
self.dropout_rate = dropout_rate
self.token_embedding = TokenEmbedding(vocab_size, hidden_dim)
self.add_position_embedding = AddPositionalEncoding()
self.input_dropout_layer = tf.keras.layers.Dropout(dropout_rate)
self.attention_block_list: List[List[tf.keras.models.Model]] = []
for _ in range(hopping_num):
self_attention_layer = SelfAttention(hidden_dim, head_num, dropout_rate, name='self_attention')
enc_dec_attention_layer = MultiheadAttention(hidden_dim, head_num, dropout_rate, name='enc_dec_attention')
ffn_layer = FeedForwardNetwork(hidden_dim, dropout_rate, name='ffn')
self.attention_block_list.append([
ResidualNormalizationWrapper(self_attention_layer, dropout_rate, name='self_attention_wrapper'),
ResidualNormalizationWrapper(enc_dec_attention_layer, dropout_rate, name='enc_dec_attention_wrapper'),
ResidualNormalizationWrapper(ffn_layer, dropout_rate, name='ffn_wrapper'),
])
self.output_normalization = LayerNormalization()
# 注:本家ではここは TokenEmbedding の重みを転地したものを使っている
self.output_dense_layer = tf.keras.layers.Dense(vocab_size, use_bias=False)
def call(
self,
input: tf.Tensor,
encoder_output: tf.Tensor,
self_attention_mask: tf.Tensor,
enc_dec_attention_mask: tf.Tensor,
training: bool,
) -> tf.Tensor:
'''
モデルを実行します
:param input: shape = [batch_size, length]
:param training: 学習時は True
:return: shape = [batch_size, length, hidden_dim]
'''
# [batch_size, length, hidden_dim]
embedded_input = self.token_embedding(input)
embedded_input = self.add_position_embedding(embedded_input)
query = self.input_dropout_layer(embedded_input, training=training)
for i, layers in enumerate(self.attention_block_list):
self_attention_layer, enc_dec_attention_layer, ffn_layer = tuple(layers)
with tf.name_scope(f'hopping_{i}'):
query = self_attention_layer(query, attention_mask=self_attention_mask, training=training)
query = enc_dec_attention_layer(query, memory=encoder_output,
attention_mask=enc_dec_attention_mask, training=training)
query = ffn_layer(query, training=training)
query = self.output_normalization(query) # [batch_size, length, hidden_dim]
return self.output_dense_layer(query) # [batch_size, length, vocab_size]
全体像
最後に Encoder と Decoder をつなげると Transformer の出来上がりです!
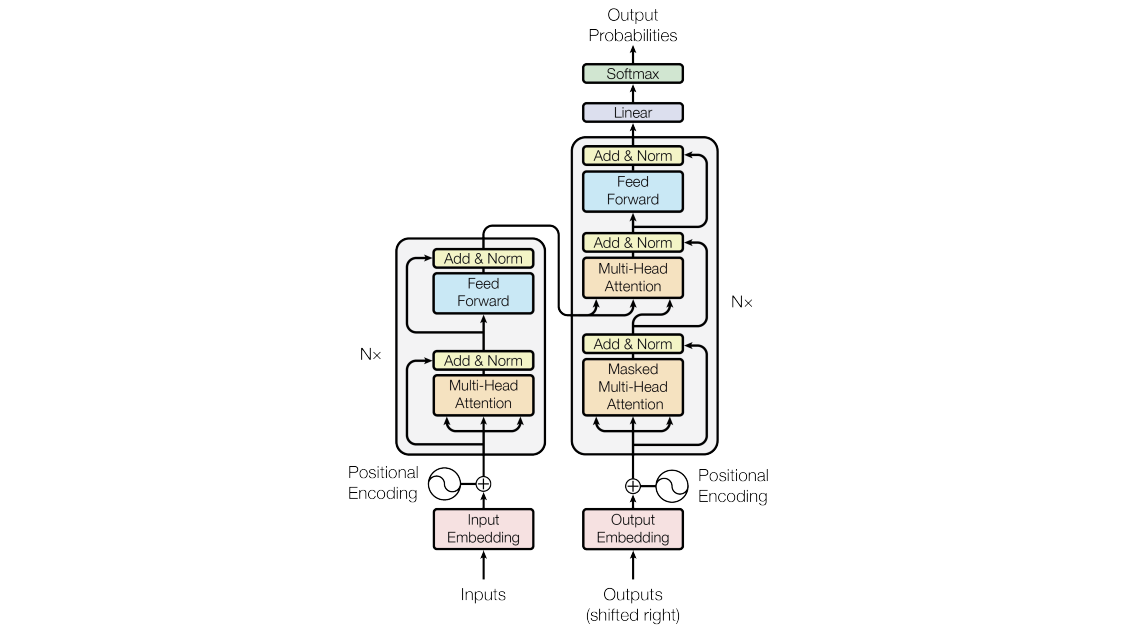
PAD_ID = 0
class Transformer(tf.keras.models.Model):
'''
Transformer モデルです。
'''
def __init__(
self,
vocab_size: int,
hopping_num: int = 4,
head_num: int = 8,
hidden_dim: int = 512,
dropout_rate: float = 0.1,
max_length: int = 200,
*args,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.vocab_size = vocab_size
self.hopping_num = hopping_num
self.head_num = head_num
self.hidden_dim = hidden_dim
self.dropout_rate = dropout_rate
self.max_length = max_length
self.encoder = Encoder(
vocab_size=vocab_size,
hopping_num=hopping_num,
head_num=head_num,
hidden_dim=hidden_dim,
dropout_rate=dropout_rate,
max_length=max_length,
)
self.decoder = Decoder(
vocab_size=vocab_size,
hopping_num=hopping_num,
head_num=head_num,
hidden_dim=hidden_dim,
dropout_rate=dropout_rate,
max_length=max_length,
)
def build_graph(self, name='transformer') -> None:
'''
学習/推論のためのグラフを構築します。
'''
with tf.name_scope(name):
self.is_training = tf.placeholder(dtype=tf.bool, name='is_training')
# [batch_size, max_length]
self.encoder_input = tf.placeholder(dtype=tf.int32, shape=[None, None], name='encoder_input')
# [batch_size]
self.decoder_input = tf.placeholder(dtype=tf.int32, shape=[None, None], name='decoder_input')
logit = self.call(
encoder_input=self.encoder_input,
decoder_input=self.decoder_input[:, :-1], # 入力は EOS を含めない
training=self.is_training,
)
decoder_target = self.decoder_input[:, 1:] # 出力は BOS を含めない
self.prediction = tf.nn.softmax(logit, name='prediction')
with tf.name_scope('metrics'):
xentropy, weights = padded_cross_entropy_loss(
logit, decoder_target, smoothing=0.05, vocab_size=self.vocab_size)
self.loss = tf.identity(tf.reduce_sum(xentropy) / tf.reduce_sum(weights), name='loss')
accuracies, weights = padded_accuracy(logit, decoder_target)
self.acc = tf.identity(tf.reduce_sum(accuracies) / tf.reduce_sum(weights), name='acc')
def call(self, encoder_input: tf.Tensor, decoder_input: tf.Tensor, training: bool) -> tf.Tensor:
enc_attention_mask = self._create_enc_attention_mask(encoder_input)
dec_self_attention_mask = self._create_dec_self_attention_mask(decoder_input)
encoder_output = self.encoder(
encoder_input,
self_attention_mask=enc_attention_mask,
training=training,
)
decoder_output = self.decoder(
decoder_input,
encoder_output,
self_attention_mask=dec_self_attention_mask,
enc_dec_attention_mask=enc_attention_mask,
training=training,
)
return decoder_output
def _create_enc_attention_mask(self, encoder_input: tf.Tensor):
with tf.name_scope('enc_attention_mask'):
batch_size, length = tf.unstack(tf.shape(encoder_input))
pad_array = tf.equal(encoder_input, PAD_ID) # [batch_size, m_length]
# shape broadcasting で [batch_size, head_num, (m|q)_length, m_length] になる
return tf.reshape(pad_array, [batch_size, 1, 1, length])
def _create_dec_self_attention_mask(self, decoder_input: tf.Tensor):
with tf.name_scope('dec_self_attention_mask'):
batch_size, length = tf.unstack(tf.shape(decoder_input))
pad_array = tf.equal(decoder_input, PAD_ID) # [batch_size, m_length]
pad_array = tf.reshape(pad_array, [batch_size, 1, 1, length])
autoregression_array = tf.logical_not(
tf.matrix_band_part(tf.ones([length, length], dtype=tf.bool), -1, 0)) # 下三角が False
autoregression_array = tf.reshape(autoregression_array, [1, 1, length, length])
return tf.logical_or(pad_array, autoregression_array)
Mask の節ででてきた各マスクはここで作成されます。
PAD の部分については、入力が PAD_ID と等しいかで計算を行い、未来の情報を取得できないようするのは tf.matrix_band_part を使用して下三角行列を取得しています。
また build_graph というメソッドでグラフモードでの学習用の loss などのノードもろもろを作成します。
padded_cross_entropy_loss, padded_accuracy は(時間がなかったので)本家のコードをほぼコピペさせていただきました。
PAD 部分は loss や accuracy の計算に入れないこと、 label smoothing と言って正解データを単純な one-hot ではなく、少しなまらせたものにするなどの工夫がされています。
今回のモデル等のコード全体は こちら
また、私は Tensorflow でのモデル構築を TDD (Test Driven Development) でやるのが大好きなので、テストのコードもあります。
Transformer を学習させる
ここからは作った Transformer を学習させます。
ここでは実験タスクとして、夏目漱石の小説の各文を入れて、その次の文を予測するタスクを学習させてみましょう。
データの準備
青空文庫から落としてきた夏目漱石の本の文章を使います。
文章から雑に非文部分を除き、文ごとに改行したものです。
(雑な処理で文を分けているので「」内で別れてしまっていたりいろいろてきとうです。)
https://github.com/halhorn/deep_dialog_tutorial/tree/master/data
トークナイザー
文章(str)はそのままでは Deep Learning モデルの入力にできません。
なので、下記のように文章を適当なトークンに区切り、更にそれを数値(ID)に変換していきます。
- 文章:
吾輩は猫である - トークナイズされた文章:
我輩 / は / 猫 / である - トークナイズされた ID:
1025 / 24 / 420 / 320
トークナイズ・ID変換をやる方法はいろいろありますが、 Google の Taku Kudo さんの作成された sentencepiece を今回は使います。
日本語解説記事 もあります。
SentencePiece は文章集合から学習させることで、文章をてきとうな大きさのトークンによしなに分割し、 ID に変換してくれます。 MeCab などでいわゆる単語に分けるよりも未知語が出にくく、スペースで単語が区切られているなどの言語的制約も無いので日本語のニューラルネット用トークナイザーとしてとても使いやすいです。
バッチ作成モジュール
学習用のバッチを作成します。
大雑把に以下のようなことをします。
- 文章をトークナイザーで ID 列に変換
- 決められた長さで切り詰める
- Decoder への入力データは前後に bos と eos を入れる
- バッチ内の各 ID 列の長さを最大のものに揃える(pad を挿入する)
- numpy の array にする
学習を行う
ここまで作った部品を組み合わせて学習を行います。
学習は jupyter でおこないます。
https://github.com/halhorn/deep_dialog_tutorial/blob/master/deepdialog/transformer/training.ipynb
# In[1]:
# カレントディレクトリをリポジトリ直下にするおまじない
import os
while os.getcwd().split('/')[-1] != 'deep_dialog_tutorial': os.chdir('..')
print('current dir:', os.getcwd())
# In[2]:
import tensorflow as tf
from deepdialog.transformer.transformer import Transformer
from deepdialog.transformer.preprocess.batch_generator import BatchGenerator
# # Create Data
# In[3]:
data_path = 'data/natsume.txt'
# In[4]:
batch_generator = BatchGenerator()
batch_generator.load(data_path)
# In[5]:
vocab_size = batch_generator.vocab_size
# # Create Model
# In[ ]:
graph = tf.Graph()
with graph.as_default():
transformer = Transformer(
vocab_size=vocab_size,
hopping_num=4,
head_num=8,
hidden_dim=512,
dropout_rate=0.1,
max_length=50,
)
transformer.build_graph()
# # Create Training Graph
# In[ ]:
save_dir = 'tmp/learning/transformer/'
log_dir = os.path.join(save_dir, 'log')
ckpt_path = os.path.join(save_dir, 'checkpoints/model.ckpt')
os.makedirs(log_dir, exist_ok=True)
# In[ ]:
with graph.as_default():
global_step = tf.train.get_or_create_global_step()
learning_rate = tf.placeholder(dtype=tf.float32, name='learning_rate')
optimizer = tf.train.AdamOptimizer(
learning_rate=learning_rate,
beta2=0.98,
)
optimize_op = optimizer.minimize(transformer.loss, global_step=global_step)
summary_op = tf.summary.merge([
tf.summary.scalar('train/loss', transformer.loss),
tf.summary.scalar('train/acc', transformer.acc),
tf.summary.scalar('train/learning_rate', learning_rate),
], name='train_summary')
summary_writer = tf.summary.FileWriter(log_dir, graph)
saver = tf.train.Saver()
# # Train
# In[ ]:
max_step = 100000
batch_size = 128
max_learning_rate = 0.0001
warmup_step = 4000
# In[ ]:
def get_learning_rate(step: int) -> float:
rate = min(step ** -0.5, step * warmup_step ** -1.5) / warmup_step ** -0.5
return max_learning_rate * rate
# In[ ]:
with graph.as_default():
sess = tf.Session()
sess.run(tf.global_variables_initializer())
step = 0
# In[ ]:
with graph.as_default():
for batch in batch_generator.get_batch(batch_size=batch_size):
feed = {
**batch,
learning_rate: get_learning_rate(step + 1),
}
_, loss, acc, step, summary = sess.run([optimize_op, transformer.loss, transformer.acc, global_step, summary_op], feed_dict=feed)
summary_writer.add_summary(summary, step)
if step % 100 == 0:
print(f'{step}: loss: {loss},\t acc: {acc}')
saver.save(sess, ckpt_path, global_step=step)
# In[ ]:
learning rate は論文にかかれているとおり最初0から初めて徐々に増やしていき(Warming-up)、4000ステップを境に減衰させるようにします。
まだ学習途中ですが、 accuray がどんどん上っていますね!
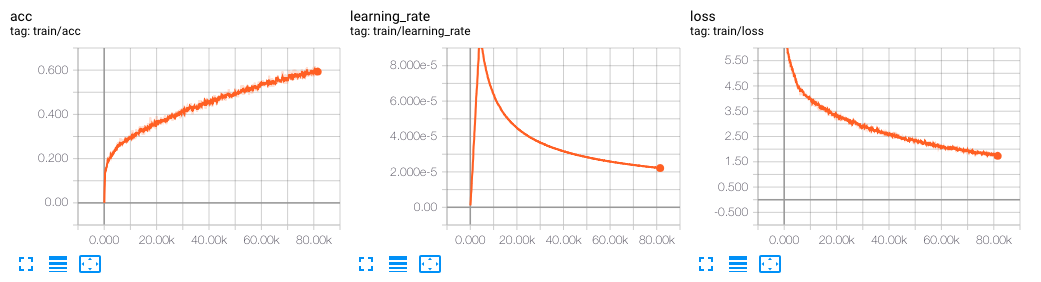
実用的な学習を行うには、 training の metrics を見るだけではなく汎化をしているかもなにかしらの方法で見る必要があります。
今回の次の文を生成するタスクや対話学習などでは、ある入力に対し正解の出力がまったくもって一意に決まらないので通常の training set + valiation set ではうまく評価できないことが多いです。
このようなタスクの汎化性能を見るのは人が目で見るしか今の所ないのではと思っており 1 epoch ごとに適当な入力から何が生成されるか Tensorboard に出す のがおすすめです。
今回作(れ|ら)なかった部分
- ビームサーチ・生成
- transformer.prediction の値をもとにビームサーチを行うことになります。(今回そこまでやる時間がありませんでした)
- これが graph mode で作るとクソ難解なコードになります。
- transformer.prediction の値をもとにビームサーチを行うことになります。(今回そこまでやる時間がありませんでした)
- 学習途中の汎化性能の評価
- 実用的な学習を行うには、 training の metrics を見るだけではなく汎化をしているかもなにかしらの方法で見る必要があります。
- 今回の次の文を生成するタスクや対話学習などでは、ある入力に対し正解の出力がまったくもって一意に決まらないので通常の training set + valiation set ではうまく評価できないことが多いです。
- このようなタスクの汎化性能を見るのは人が目で見るしか今の所ないのではと思っており 1 epoch ごとに適当な入力から何が生成されるか Tensorboard に出す のがおすすめです。
- Multi-head Attention のメモリのキャッシュ
- 自己回帰的に生成を行う場合に何度も同じ memory を変換するコストをなくすため、本家のコードではキャッシュの仕組みが実装されています。
参照
さいごに
ミクシィ AI ロボット事業部では DeepLearning で対話学習を行う R&D エンジニア及び実装・インフラまわりのエンジニアを募集しています。
雑談対話というなかなかビジネスの場では本気で取り組むことの難しい分野に挑戦できるのでぜひ話を聞きに来てください。