はじめに
TensorFlow で言語モデルや Seq2Seq 等を学習させている際に、学習の途中での生成結果を見たくなることがよく有ります。
特に会話学習等での生成の場合、正解が一意に定まらないので生成結果を人間が目でみて判断するのが一番良い場合があり、そのようなときには学習過程での生成結果の変遷を見ることはとても重要です。
そのようなときに使うのが tf.summary.text です。
この記事では tf.summary.text の使い方を紹介します。
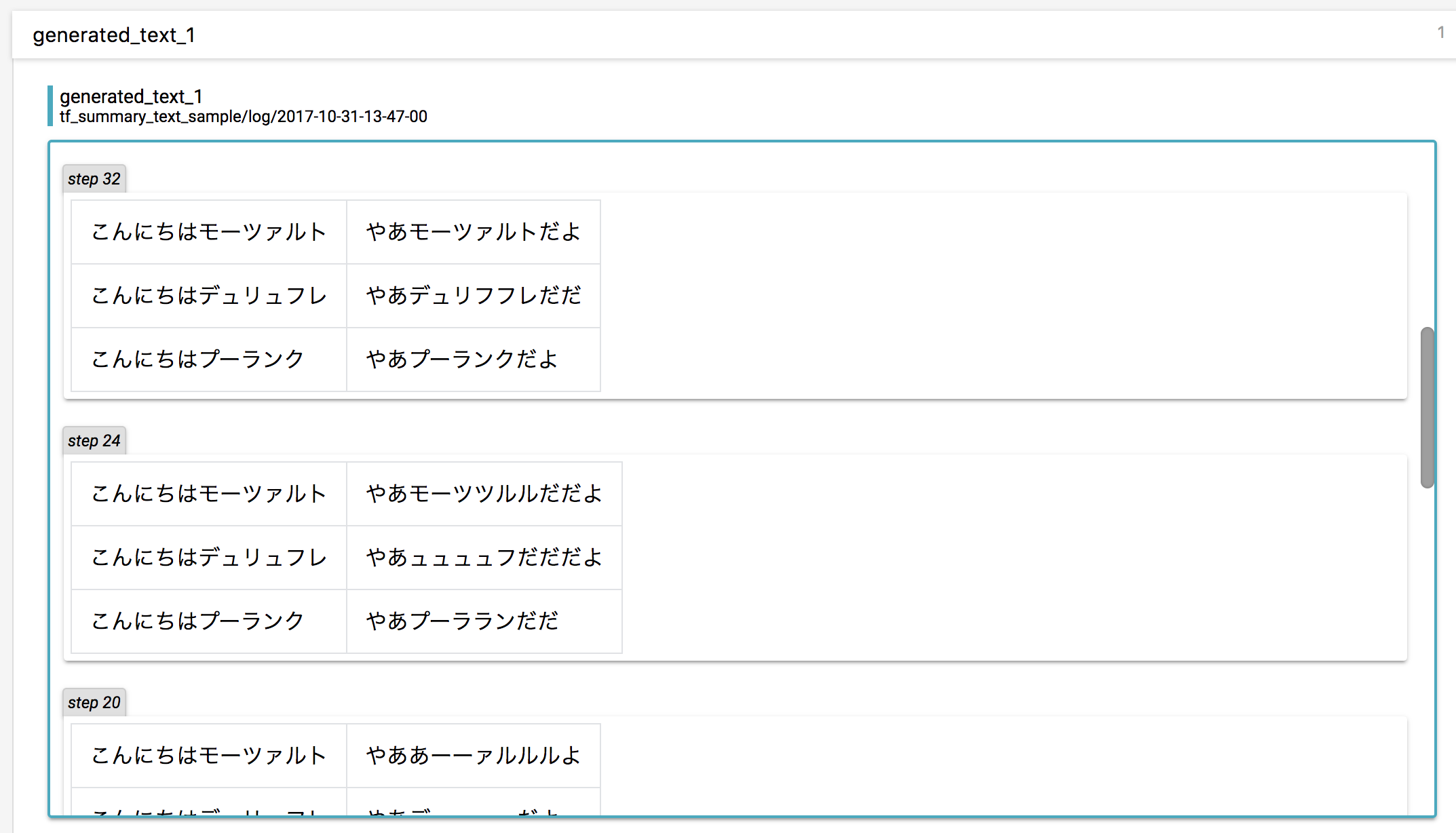
だんだん挨拶を覚えていく過程が見えますね。
(情報が少なく独自に調べた結果ですので、より良い使い方をご存知の方がいらっしゃったら教えてください)
使い方
モデル構築時
- tf.placeholder でテキストの入力を作る
- tf.summary.text に placeholder を渡してサマリーの op を作る
# 文字列のサマリー用の placeholder を作る
# テキストが1次元リストなら、shape=(None,) に。二次元なら shape=(None, None) に。
generated_text_ph = tf.placeholder(tf.string, shape=(None,), name='generated_text')
text_summary = tf.summary.text('generated_text', generated_text_ph)
text_summary_op = tf.summary.merge([text_summary])
学習時
- モデルが生成した id 列から、テキストに変換を行う
- サマリーの op を実行し、テキストを placeholder に流し込む
- 結果を summary_writer.add_summary する
generated_texts = ids2text(generated_ids)
# テキストの placeholder に流し込んでサマリを作る
# 上部でテキストを二次元にした場合、ここには [['インコ', 'かわいい'], ['オウム', 'かわいい'], ...] みたいに
# 二次元のテキストリストを渡せるよ
text_summary = sess.run(text_summary_op, feed_dict={generated_text_ph: generated_texts})
summary_writer.add_summary(text_summary, global_step=step)
サンプルコード
テストとして動くサンプルコードです。
import unittest
import tensorflow as tf
class TestTextSummary(unittest.TestCase):
def test_text_summary(self):
# モデル構築部分 ----------------------------------------------------------
inputs_ph, model_outputs = self.create_model()
# 文字列のサマリー用の placeholder を作る
# テキストが1次元リストなら、shape=(None,) に。二次元なら shape=(None, None) に。
generated_text_ph = tf.placeholder(tf.string, shape=(None,), name='generated_text')
text_summary = tf.summary.text('generated_text', generated_text_ph)
text_summary_op = tf.summary.merge([text_summary])
# 学習構築部分 ------------------------------------------------------------
data = ['インコかわいい', 'オウムかわいい', 'ヨウムかわいい']
sess = tf.Session()
sess.run(tf.global_variables_initializer())
summary_writer = tf.summary.FileWriter(logdir='tmp/test/text_summary_sample', graph=sess.graph)
for epoch in range(10):
# do training! but our super auto encoder is already perfect.
# for batch in batch_list:
# ...
generated_ids = sess.run(model_outputs, feed_dict={inputs_ph: self.text2ids(data)})
generated_texts = self.ids2text(generated_ids)
# テキストの placeholder に流し込んでサマリを作る
# 上部でテキストを二次元にした場合、ここには [['インコ', 'かわいい'], ['オウム', 'かわいい'], ...] みたいに
# 二次元のテキストリストを渡せるよ
text_summary = sess.run(text_summary_op, feed_dict={generated_text_ph: generated_texts})
summary_writer.add_summary(text_summary, global_step=epoch)
def create_model(self):
# super auto encoder!
inputs_ph = tf.placeholder(tf.int32, shape=(None, None))
model_outputs = inputs_ph
return inputs_ph, model_outputs
def text2ids(self, text_list):
return [[ord(c) for c in text] for text in text_list]
def ids2text(self, ids_list):
return [''.join([chr(i) for i in ids]) for ids in ids_list]
注: global_step=epoch の部分は本来は変数の update のたびに変わる global_step を渡すのを想定されていると思います。
結果
いつもの通り Tensorboard を立ち上げ、 TEXT タブを開くとこのようになります。
tensorboard --logdir tmp/test
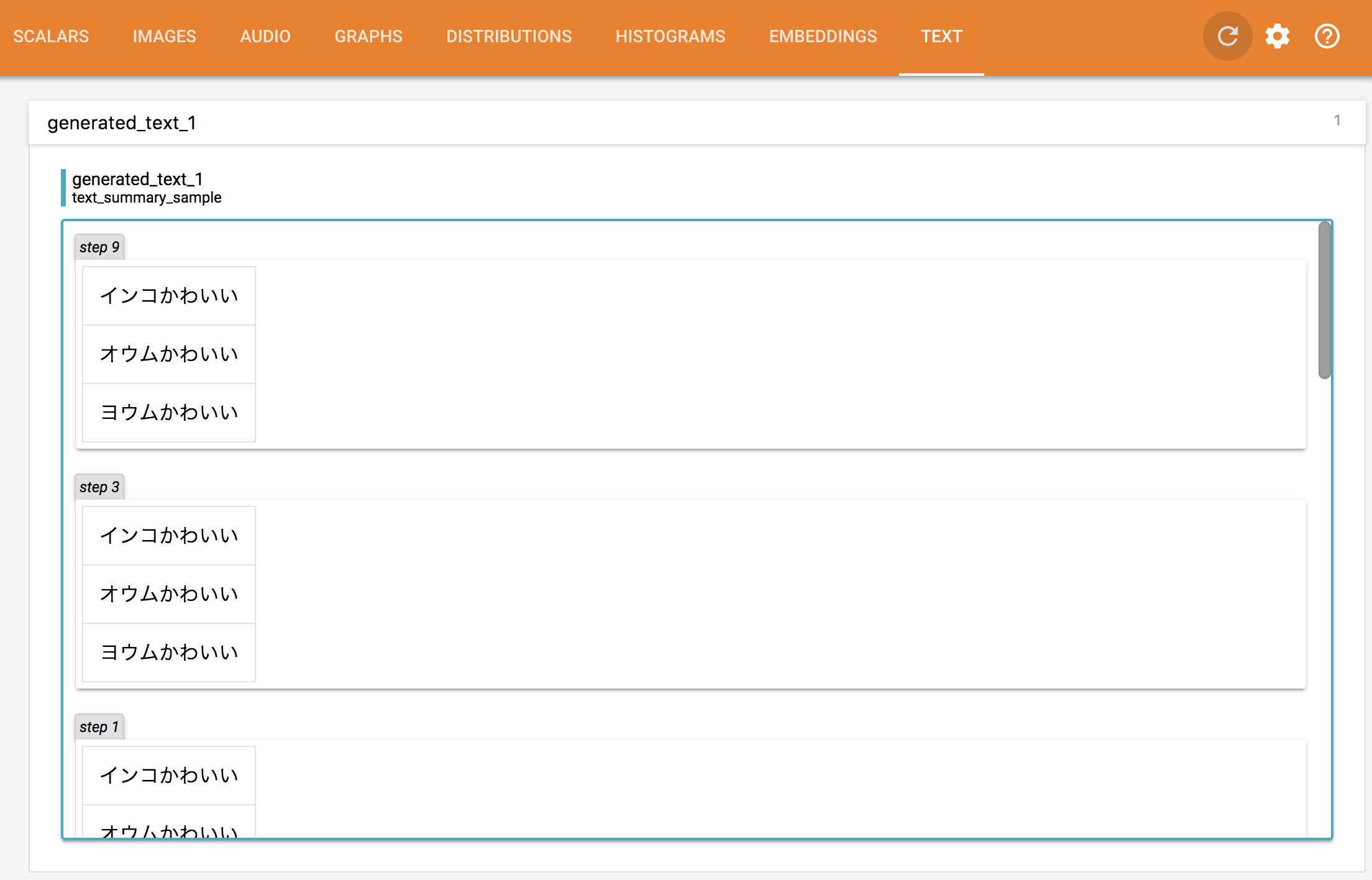
与えるテキストと、それを入力する placeholder をコメントに書かれたように二次元にしてやると、最初の画像のようにテーブルで結果が表示されるようにもできます。
Seq2Seq のような質問応答のモデルだとそのようにすると便利ですね。