2022/4/6(水)に行われたAWSセミナー「Pythonの基礎から学ぶ!サーバーレス開発はじめの一歩」で構築したサーバレスアーキテクチャ環境の復習。
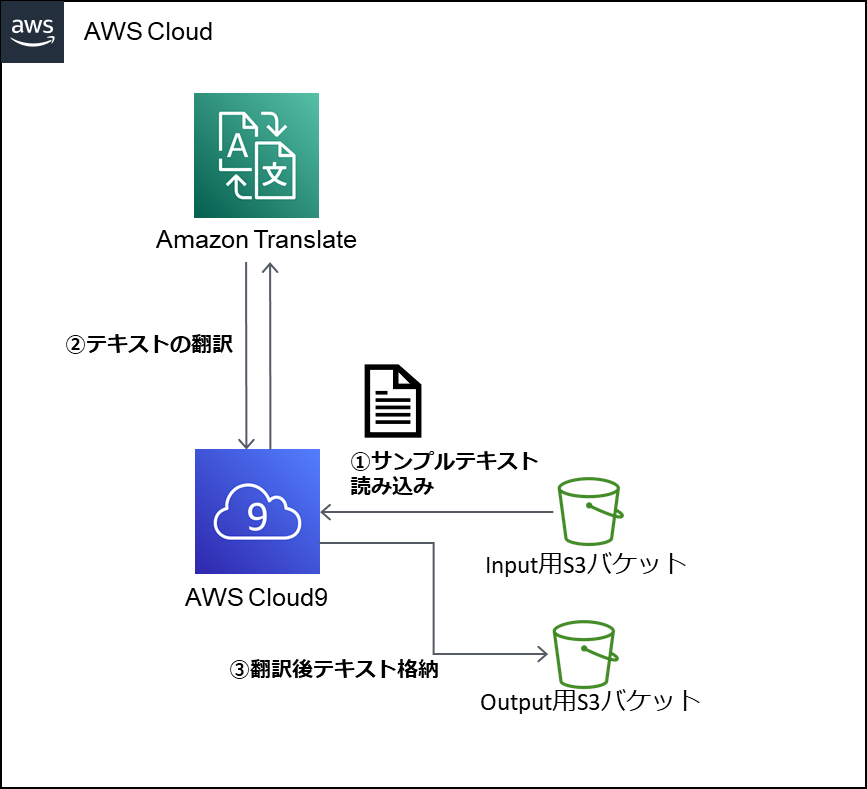
構成図
Amazon S3バケットに格納された英語のテキストを AWS Cloud9で読み取り、Amazon Translate で翻訳して S3バケットにアップロードする簡易アプリケーションをPyhonで開発する。
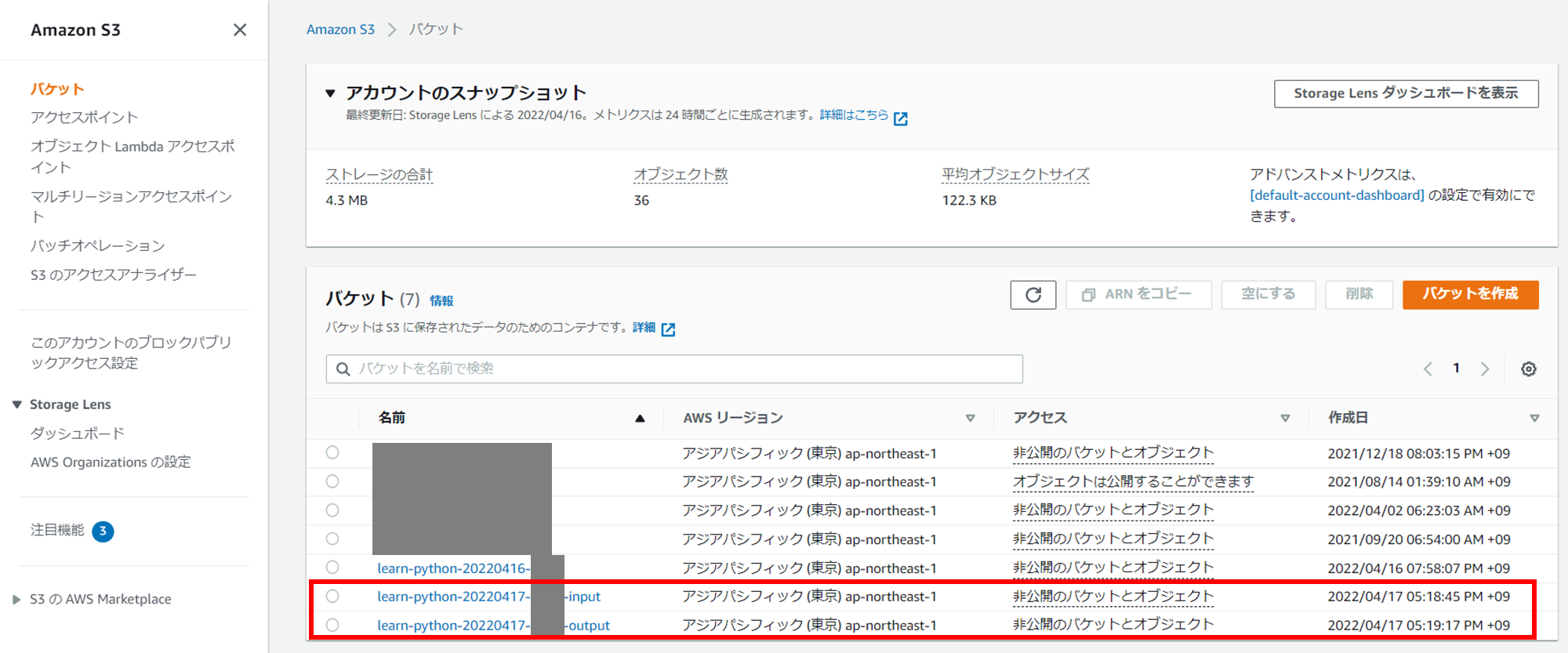
1. S3 バケットの準備
翻訳する前のファイルを入れる S3 バケットと、翻訳語のファイルを入れるS3 バケットを作成しておく。
- learn-python-YYYYMMDD-xxxxx-input
- learn-python-YYYYMMDD-xxxxx-output
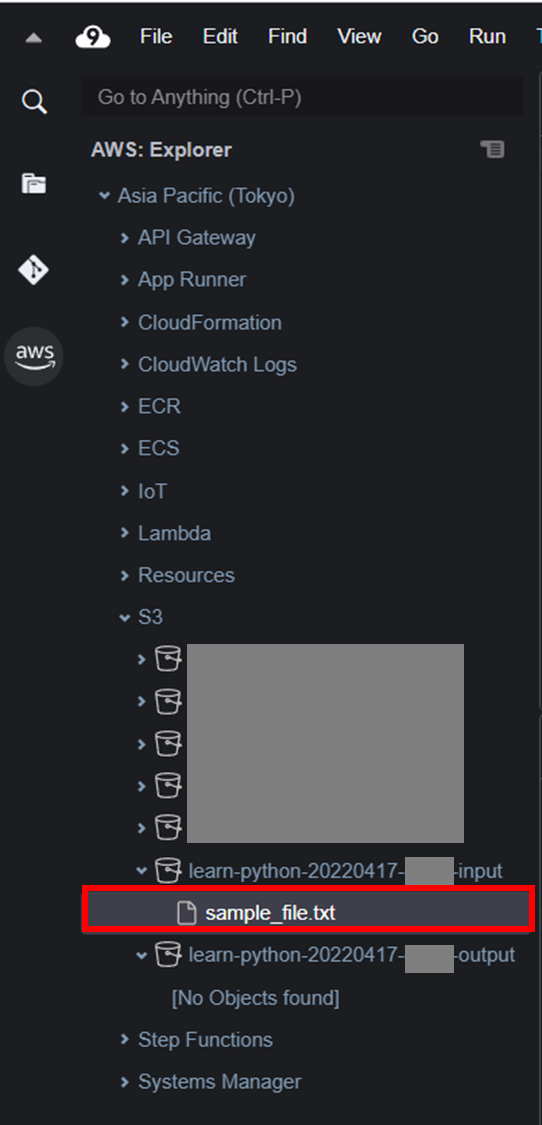
AWS Cloud9でPython基礎~Amazon S3を利用する 1-2.ファイルのアップロード を参考に、以下内容を入力して保存したsample_file.txt ファイルを、AWS ツールキットで S3 バケットlearn-python-YYYYMMDD-xxxxx-input にアップロードする。
I want to be able to use Python!
2. S3 にあるファイルの読み込み
S3 バケット learn-python-YYYYMMDD-xxxxx-input から sample_file.txt ファイルを読み込むPythonコードを書く。ファイルが多くなってきたのでフォルダを作成してPythonコードを格納する。
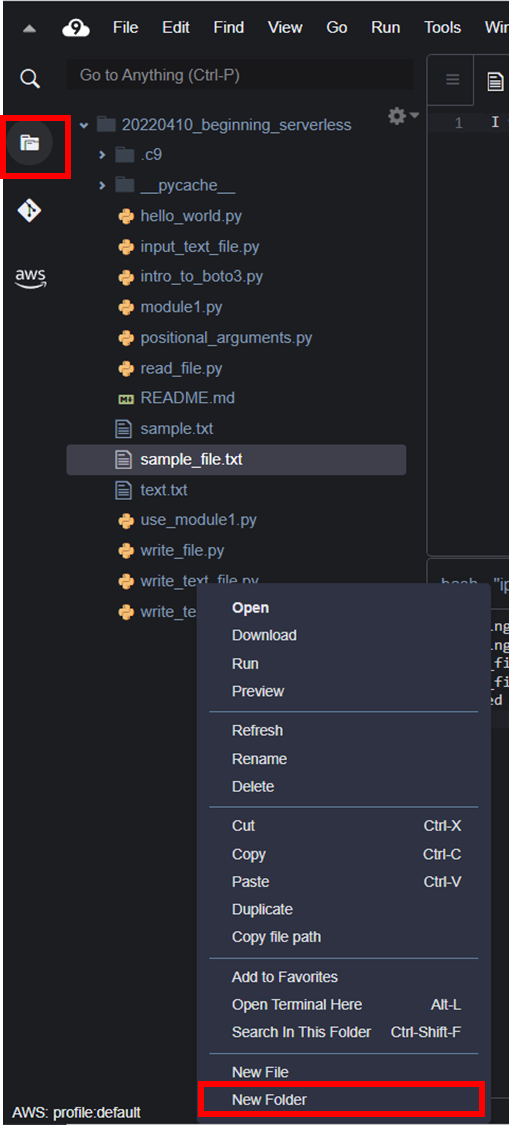
Cloud9 でAWSツールキットが開いていたら、フォルダマークをクリックしてディレクトリの表示に戻す。
何もないところで右クリックし、「New Folder」で新しいフォルダをtranslateと名前を付けて作成する。
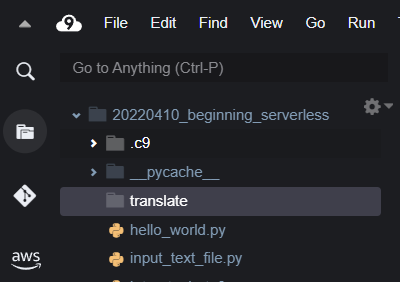
ファイルを読み込む index.py ファイルを、作成した translate フォルダに新しく作成する。
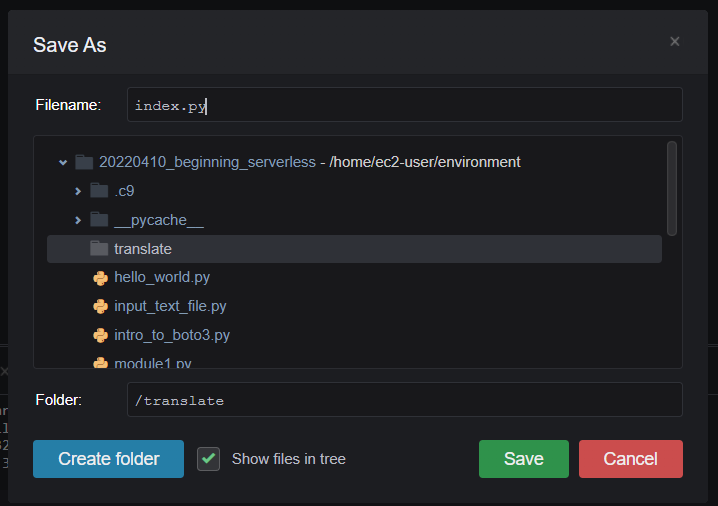
AWS Cloud9でPython基礎~Amazon S3を利用する 1-3.Boto3を使ってS3のファイルを読み込むで作成したread_file.pyを以下のように書き換える。
-
BucketとKeyを今回対象のバケット名とsample_file.txtに変える - print文を削除
- 変数
textにread_s3_file()の戻り値を格納する - 確認のため最後に読み込んだファイルの中身をprint文で表示する
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
text = read_s3_file()
print(text)
以下コマンドで実行する。
cd translate/ # translate フォルダに移動
python index.py
実行結果
I want to be able to use Python!
3. ファイルから読み込んだ文章の翻訳
AWS Cloud9でPython基礎 2-4-2.キーワード引数で作成したpositional_arguments.pyを参考に、index.pyを編集する。
-
index.pyにhonyaku()関数を追加 -
honyaku()関数を、ファイルから読み込んだ文字列が格納されている変数textを使って呼び出す
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
# positional_arguments.py から honyaku() 関数を貼りつけ
def honyaku(text, source_language_code, target_language_code):
client = boto3.client('translate')
response = client.translate_text(
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
print(response)
# honyaku() 関数ここまで
text = read_s3_file()
# キーワード引数を設定
source_language_code='en'
target_language_code='ja'
# honyaku()関数を、引数を使って呼び出し
honyaku(text, source_language_code, target_language_code)
編集したindex.pyの実行結果
{'TranslatedText': 'Pythonを使えるようになりたい!', 'SourceLanguageCode': 'en', 'TargetLanguageCode': 'ja', 'ResponseMetadata': {'RequestId': '295ac75c-1c16-4fd1-b0ef-45xxxxxxxxxx', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': '295ac75c-1c16-4fd1-b0ef-45xxxxxxxxxx', 'cache-control': 'no-cache', 'content-type': 'application/x-amz-json-1.1', 'content-length': '115', 'date': 'Sun, 17 Apr 2022 09:31:49 GMT'}, 'RetryAttempts': 0}}
翻訳されて、Pythonの辞書型で値が返ってきていることがわかる。
次に、ユーザー定義関数honyaku()を、'TranslatedText'の部分だけを返すように書き換える。
Pythonの辞書型で値が返ってきているので、AWS Cloud9でPython基礎 2-1-3.辞書型(dict)を参考に、辞書型の出力の中から key='TranslatedText'部の value だけ返すように書き換える。
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
def honyaku(text, source_language_code, target_language_code):
client = boto3.client('translate')
response = client.translate_text。
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
# ここで、辞書型の出力の中から key='TranslatedText'部の value だけ返すように書き換え
print(response['TranslatedText'])
text = read_s3_file()
source_language_code='en'
target_language_code='ja'
honyaku(text, source_language_code, target_language_code)
編集したindex.pyの実行結果
Pythonを使えるようになりたい!
S3 バケットから読みとったファイルの内容を、日本語に翻訳して返すことができた。
4. 翻訳した文章をS3 バケットへ書き込む
AWS Cloud9でPython基礎~Amazon S3を利用する 2-1.Boto3でS3にファイルを作成するで作成したwrite_file.pyを参考にindex.pyを書き換える。
- ユーザー定義の
honyaku()で戻り値を返すよう変更する - ユーザー定義の
honyaku()関数を呼び出す側でも戻り値を変数で受け取るようにする
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
def honyaku(text, source_language_code, target_language_code):
client = boto3.client('translate')
response = client.translate_text(
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
print(response['TranslatedText'])
# honyaku()関数で戻り値を返すようにreturn追加
return response['TranslatedText']
text = read_s3_file()
source_language_code='en'
target_language_code='ja'
# 翻訳済みの文章を変数translated_text に格納
translated_text = honyaku(text, source_language_code, target_language_code)
-
write_s3_file()関数を追記する
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
def honyaku(text, source_language_code, target_language_code):
client = boto3.client('translate')
response = client.translate_text(
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
print(response['TranslatedText'])
return response['TranslatedText']
# write_s3_file()関数を追加
def write_s3_file():
s3_client = boto3.client('s3')
output_text = 'This is uploaded.'.encode()
s3_client.put_object(
Bucket='<バケット名>',
Key='upload.txt',
Body=output_text,
)
# write_s3_file()関数ここまで
text = read_s3_file()
source_language_code='en'
target_language_code='ja'
translated_text = honyaku(text, source_language_code, target_language_code)
-
write_s3_file()がファイルを書き込むバケット名をlearn-python-YYYYMMDD-XXXXX-outputに変更する - 関数
write_s3_file()がS3バケットにファイルとして書き込む文字列を受け取れるようにパラメータを設定する - 設定したパラメータを
client.put_object()にバイトオブジェクトとして、キーワードBodyに渡す - 関数
write_s3_file()を呼び出す。このとき、変数translated_textを引数として渡す
import boto3
def read_s3_file():
s3_client = boto3.client('s3')
input_object = s3_client.get_object(
Bucket='learn-python-20220417-xxxxx-input',
Key='sample_file.txt',
)
input_object_byte = input_object['Body'].read()
input_object_text = input_object_byte.decode()
return input_object_text
def honyaku(text, source_language_code, target_language_code):
client = boto3.client('translate')
response = client.translate_text(
Text=text,
SourceLanguageCode=source_language_code,
TargetLanguageCode=target_language_code
)
print(response['TranslatedText'])
return response['TranslatedText']
# write_s3_file()関数を変更
# 関数`write_s3_file()`がS3バケットにファイルとして書き込む文字列を受け取れるようにパラメータ(output_text)を設定する
def write_s3_file(output_text):
s3_client = boto3.client('s3')
s3_client.put_object(
Bucket='learn-python-20220417-xxxxx-output',
Key='upload.txt',
# 設定したパラメータを`client.put_object()`にバイトオブジェクトとして、キーワード`Body`に渡す
Body=output_text.encode(),
)
# write_s3_file()関数ここまで
text = read_s3_file()
source_language_code='en'
target_language_code='ja'
translated_text = honyaku(text, source_language_code, target_language_code)
# 関数`write_s3_file()`を呼び出す。このとき、変数`translated_text`を引数として渡す
write_s3_file(translated_text)
実行結果
Pythonを使えるようになりたい!
左サイドバーのAWS ツールキットでS3バケットlearn-python-YYYYMMDD-xxxxx-outputにupload.txtがあることが確認できればOK。
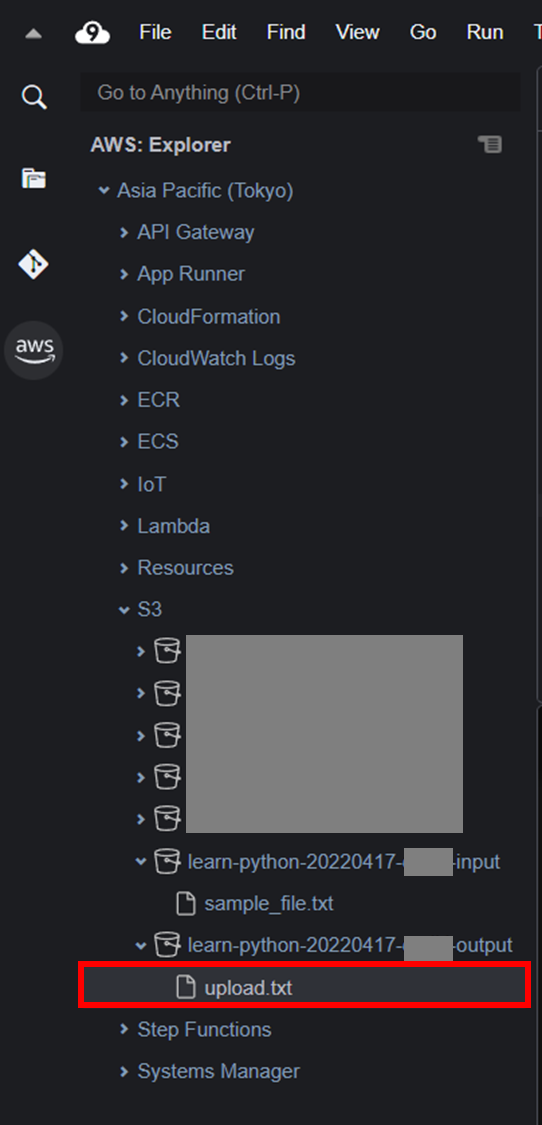
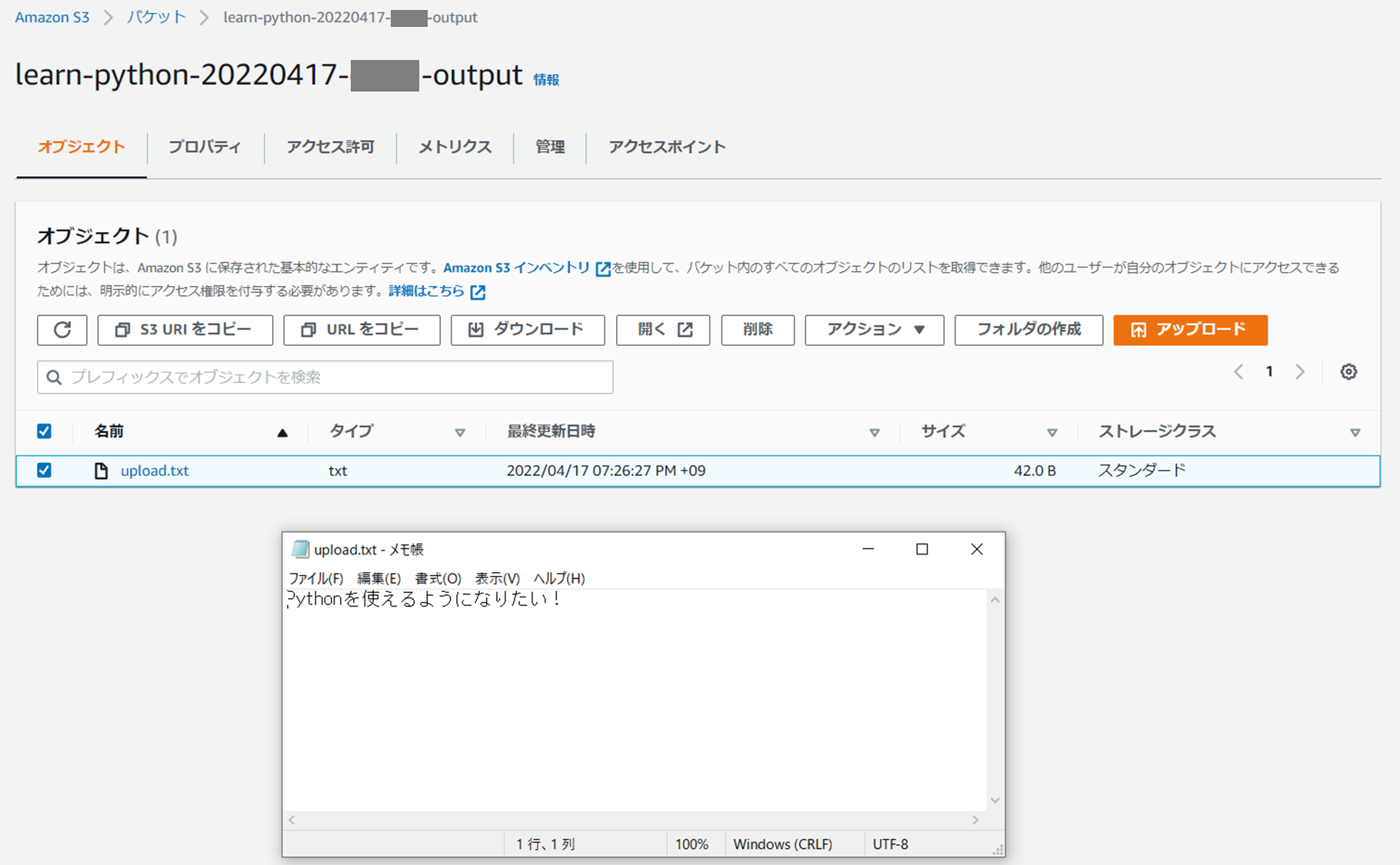
マネジメントコンソールでS3 バケットからupload.txtをダウンロードしてファイルの中身を確認すると、翻訳後の文章が記載されているのが確認できる。
参考
AWS Cloud9でPython基礎
AWS Cloud9でPython基礎~ファイルの読み書き
AWS LambdaでPython基礎
AWS Cloud9でPython基礎~Amazon S3を利用する
AWS Cloud9でPython基礎~Amazon S3とAmazon Translateを利用する
AWS LambdaでPython基礎~Amazon S3とAmazon Translateを利用する