0. はじめに --- グラフ探索の動機
現代ではコンピュータはとても身近なものになりました。コンピュータの用途としては
- シミュレーションなどの大規模計算を行う
- 人工知能をつくる
- アプリを開発する
などなど多様なものが考えられますが、「探索」もまた、コンピュータを用いるモチベーションとして、最も基本的かつ重要なものの一つだと思います。探索とは、与えられた対象の中から、目的に合うものを見つけ出したり、最良のものを見つけ出したり、条件を満たすものを列挙したりする営みです。
世の中における様々な問題は、探索によって、考えられる場合を調べ尽くすことによって原理的には解決できるものが多いです。例えば、現在地から目的地まで最速でたどり着く方法を求める問題は、原理的には、現在地から目的地へ到達する経路をすべて列挙することで解決できます1。将棋やオセロの必勝法を求める問題は、原理的には、考えられる局面と局面遷移をすべて調べ上げることで求めることができます2。
確かに実際上は、ありうる場合の数が膨大なために全探索手法の適用が困難なことも多いのですが、まずは「どうしたらすべての場合を調べつくせるか」を検討することは大変重要です。全探索アルゴリズムを考案することによって、解きたい問題の構造に対する深い理解を獲得し、結果的に高速なアルゴリズムの設計へと結ぶ付くことは珍しくないです。そして、考えられる選択肢をすべて調べ上げる方法として「問題をグラフを用いて定式化する」という手法がしばしば極めて有効です。
本記事ではグラフ上の探索、特に深さ優先探索について、色々な問題を解くことを通して慣れることを目指します。動的計画法などもそうですが「習うより慣れろ」の精神が大きな効果を生むテーマだと思います。
目次
前編
後編
- 4 章: グラフの様々な例題:本記事の特徴をなすメインパートです!!!
- 5 章: 発展的話題
- 6 章: おわりに
- 7 章: 参考文献
本記事の構成は上のようになっています。前編・後編と記事を 2 つに分けました。1 章でグラフという概念を導入し、2 章でグラフを計算機上でどのように扱うのがよいかについて述べています。3 章ではグラフ上の探索アルゴリズムについて一般的な話を書いています。これらについてすでに知っている方は 4 章から入っていただけたらと思います。そして、4 章が本記事の特徴をなすメインパートでグラフ探索に関する多数の例題を解いていきます。
といった多様な処理たちがほとんど同じようなコードを使い回すだけで解けることを示します!なお本記事では、ソースコード例に用いるプログラミング言語として C++ (11 以降) を用いておりますが、基本的にはプログラミング言語に依存しない部分についての解説を行っています。
【追記】
本記事は DFS メインですが、BFS に焦点を当てた記事も書きました。
1. グラフ
1-1. グラフとは
グラフ (graph) とは、例えば「新しいクラスで誰と誰が既に知り合いか」といったように、
- 考えられる物事たちの集合 (先例では、クラスのメンバーの集合)
- それらのメンバたちが互いにどう関係しているか (先例では、知り合い関係)
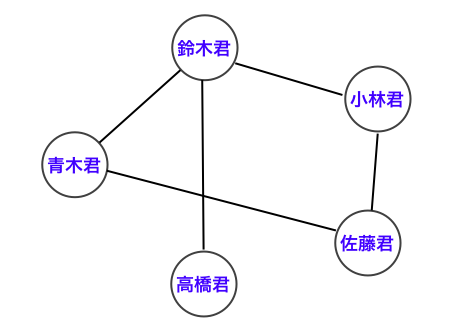
を表すものです。グラフは下図のように「丸」と「線」を用いて描画されることが多いです。対象物を丸で、対象物間の関係性を線で表します3。
念のために、グラフを数学的に定義してみます。グラフ $G$ は
- 頂点 (vertex) の有限集合 $V = (v_1, v_2, \dots, v_n)$
- 辺 (edge) の有限集合 $E = (e_1, e_2, \dots, e_m)$
の組として定義され、$G = (V, E)$ と表されます。各辺 $e \in E$ は 2 つの頂点 $v_i, v_j \in V$ の 組として定義され、$e = (v_i, v_j)$ のように表されます。上図の例では
- 頂点集合 $V = ${青木君, 鈴木君, 高橋君, 小林君, 佐藤君}
- 辺集合: $E = ${(青木君, 鈴木君), (鈴木君, 高橋君), (鈴木君, 小林君), (小林君, 佐藤君), (青木君, 佐藤君)}}
ということになります。また、頂点 $v_i$ と $v_j$ とが辺 $e$ によってつながれているとき、$v_i$ と $v_j$ は互いに隣接している (adjacent) といい、$v_i, v_j$ を $e$ の端点 (end) といいます。
1-2. 有向グラフと無向グラフ
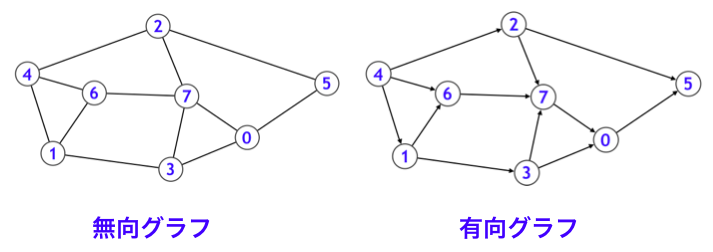
グラフ $G$ の各辺 $e = (v_i, v_j)$ について、向きを考えずに $(v_i, v_j)$ と $(v_j, v_i)$ とを同一視するとき、$G$ を無向グラフ (undirected graph) といい、$(v_i, v_j)$ と $(v_j, v_i)$ とを区別するとき、$G$ を有向グラフ (directed graph) といいます。
グラフを描画するときは、無向グラフでは辺を「線」で描くことが多く、有向グラフでは辺を「矢印」で描くことが多いです。無向・有向という概念のお気持ちとしては、例えば道路ネットワークをグラフでモデル化したとき、無向グラフの辺は双方に行き来可能で、有向グラフの辺は一方通行である、といったことを表すことができます。
ここでグラフに関するいくつかの用語を整理してみます。
-
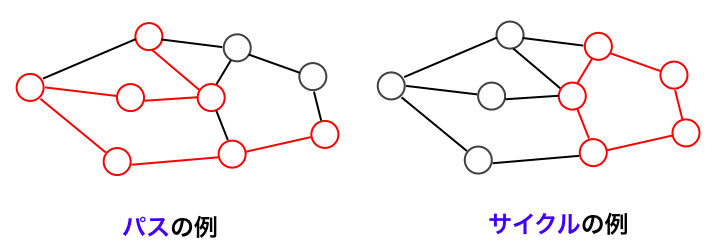
路: グラフ $G$ 上の二頂点 $u, v$ について、$u$ から $v$ へと隣接する頂点をたどっていくことで到達できるとき、その経路を $u-v$ 路とよびます。また $u$ を始点、$v$ を終点とよびます。
-
パス: 路のうち、同じ頂点を二度通らないものをパスとよびます。
-
サイクル (閉路): 路のうち、始点と終点が等しいものをサイクルとよびます。
-
連結: グラフ $G$ の任意の二頂点 $u, v \in V$ に対して、$u-v$ パスまたは $v-u$ パスが存在するとき、$G$ は連結であるといいます。
-
強連結: 有向グラフ $G$ の任意の二頂点 $u, v \in V$ に対して、$u-v$ パスも $v-u$ パスも存在するとき、$G$ は強連結であるといいます。
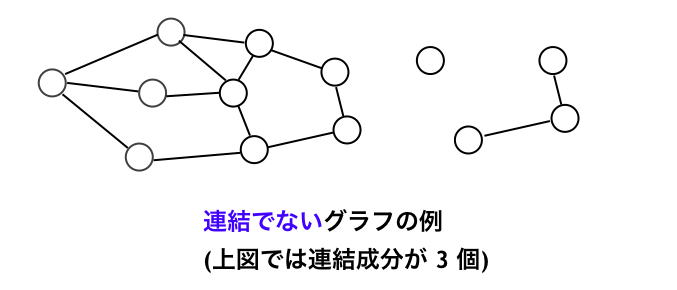
1-3. グラフの例
グラフは非常に強力な数理科学的ツールです。世の中の多くの問題は、グラフを用いてモデル化することで、グラフに関する問題として定式化することができます。すなわち様々な分野における問題が、グラフに関する問題として統一的に扱うことができるのです。ここでは対象物をグラフを用いて定式化する例をいくつか挙げます。
1-3-1. 日本の都道府県の隣接関係
グラフの導入として、もっちょさんが大変面白い記事を書いています (下図は下記記事より引用)。
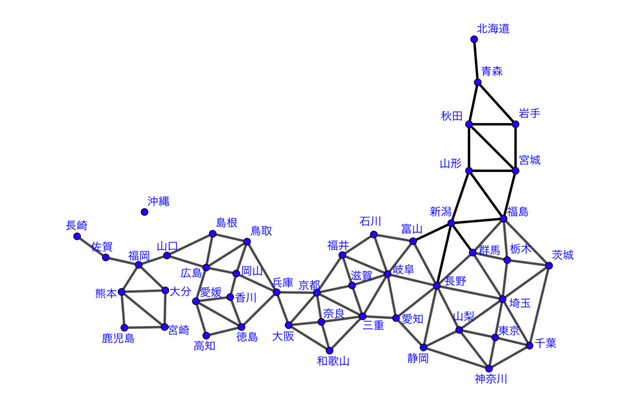
これは、日本の各都道府県を頂点とし、県境が隣接している都道府県同士を辺で結んだグラフとなっています。沖縄は孤立点となっていますね。もっちょさんのブログでも触れられていますが、実際の県の位置は関係なく「どのように繋がっているか」について様々な考察を与えることができるのがグラフを用いた定式化のメリットになります。典型的には
- 頂点を 2 つ抜き出したとき、その 2 点はどのくらい離れているか (いわゆる最短路問題です)
- 頂点を 2 つ抜き出したとき、その 2 点間はどのくらい丈夫に繋がっているか (ネットワークフロー理論につながります)
といった問題意識が沸き起こります。これらは本記事の範囲外ですが、グラフを学ぶことでこれらの問題意識に対して有意義な知見を獲得することができます。
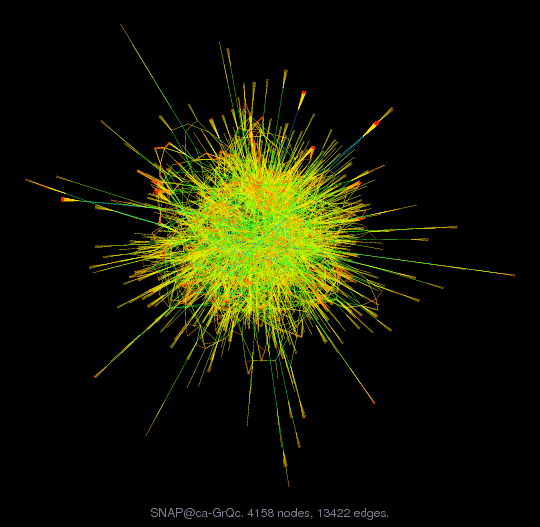
1-3-2. ソーシャルネットワーク
最初にグラフを導入したときに「クラスにおける知り合い関係」を例にとりましたが、より大規模な例として
- Twitter でのフォロー関係
- Facebook での友達関係
- 論文の共著者関係
などがあります。「僕の知り合いの知り合いの知り合いの...」とやっていくと、6 回くらいで世界中のほとんどの人に行き渡るという話を聞いたことのある方は多いかもしれません。ソーシャルネットワーク分析においては
- Facebook でお馴染みの「知り合いかも?」をレコメンドする
- コミュニティを検出する
- 影響力の高い人を検出したり、ネットワークの情報伝播力を解析したりする
といった問題意識が大変重要です。ソーシャルネットワークは典型的には下図 (このページより引用) のような形をしており、上にあげた「都道府県の隣接関係」や下にあげる「道路ネットワーク」とは根本的に異なる性質を有することが多いです。ソーシャルネットワークに特有の構造について関心のある方は、以下の記事たちが大変面白いです。
- 大規模ネットワークの性質と先端グラフアルゴリズム
- グラフ・ネットワーク分析で遊ぶ(3):中心性(PageRank, betweeness, closeness, etc.)
-
グラフ・ネットワーク分析で遊ぶ(4):コミュニティ検出(クラスタリング)
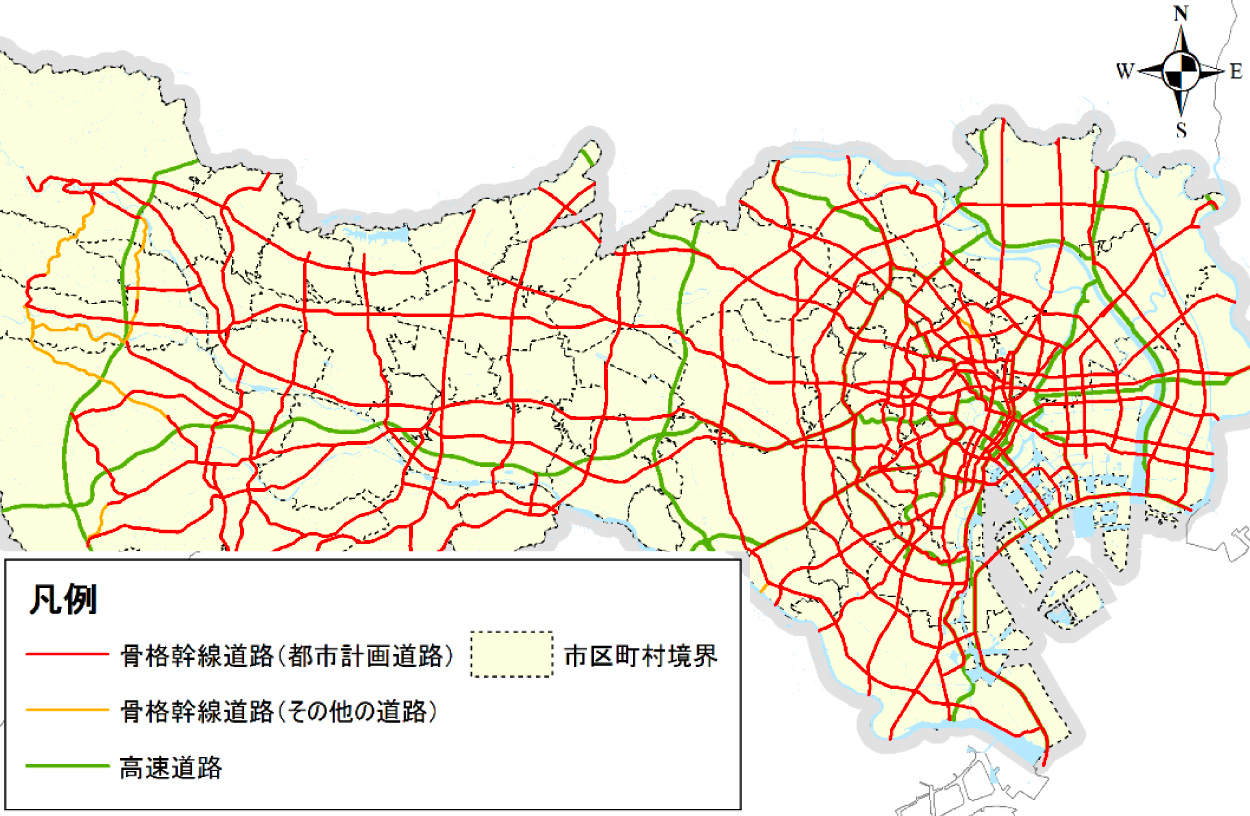
1-3-3. 交通ネットワーク
道路ネットワーク (頂点は交差点) や、鉄道路線図 (頂点は駅) なども、まさにグラフそのものです。下図はこのページより引用しています。
見た目からして、道路ネットワークはソーシャルネットワークとは大きく性質が異なります。道路ネットワークに特徴的な性質として、平面的であることが挙げられます。平面グラフに近い性質を持つことを活かしたアルゴリズムなどに関心のある方は以下の資料が大変面白いです。
1-3-4. ゲームの局面遷移
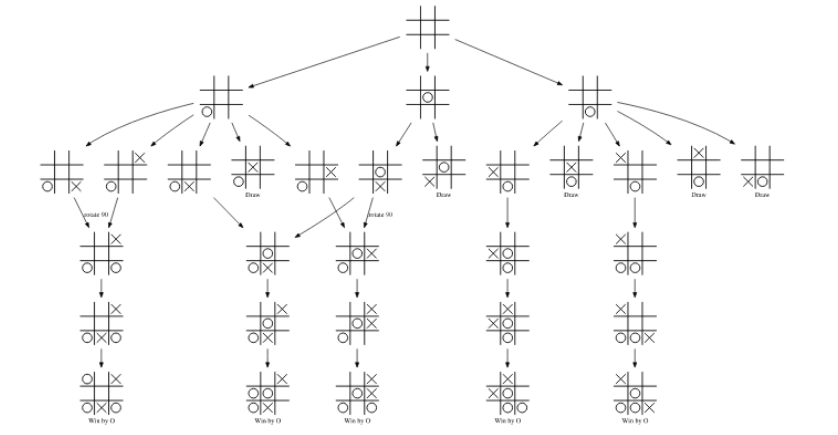
将棋やオセロといったゲームの解析も、グラフ探索の重要な例になっています。下図はマルバツゲームとしてありうる局面遷移を表したものです (このページから引用)。各局面が頂点、局面遷移が辺に対応する有向グラフです。
このようなグラフを探索することで、簡単なゲームであれば必勝法を解析したり、複雑なゲームであっても強い AI を作成したりできるようになります。ゲームの解析に関する話は以下の記事にまとめたので是非読んでいただけたらと思います。
1-3-5. タスクの依存関係
「このタスクが終わらなければ、このタスクを始められない」といったタスクの依存関係もグラフで表すことができます。似た例としては、
- 食物連鎖
- 家系図
- 組織図
- クラス図における継承関係
といったものもグラフで表すことができます。タスクの依存関係を整理したり、依存関係を制約条件として物事を最適化したりする場面において、グラフが有効に用いられることが多々あります。
2. 計算機上でのグラフの表し方
グラフ探索アルゴリズムを実装する前に、計算機上でグラフを表現するデータ構造について簡単に述べます。大きく分けて
- 隣接リスト表現 (adjacency-list representation)
- 隣接行列表現 (adjacency-matrix representation)
の 2 つがありますが、本記事では隣接リスト表現のみを取り上げます。多くのグラフアルゴリズムは、隣接リスト形式の方が効率良く実現できることが多いです。
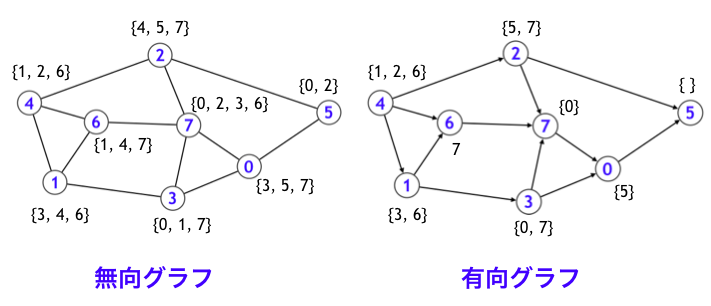
さて、まずグラフの頂点集合を一般性を失わず $V = (0, 1, \dots, N-1)$ とします (グラフの頂点数を $N$ とします)。そして、各頂点 $v \in V$ に対して、辺 $(v, v') \in E$ が存在するような頂点 $v'$ をリストアップします。この作業は無向グラフでも有向グラフでも同様に実施することができます。
これらの情報をそのまま格納します。隣接リスト表現は本来的には、各頂点 $v$ に対して隣接頂点たちを連結リスト構造で管理するのですが、C++ では可変長配列 std::vector を用いれば十分です。本記事ではグラフを以下のように表すことにします。
using Graph = vector<vector<int>>; // グラフ型
Graph G; // グラフ
G[v] が v の隣接頂点たちを可変長配列に格納したものを表します。上図の有向グラフの例の場合、以下のようになります。
G[0] = {5}
G[1] = {3, 6}
G[2] = {5, 7}
G[3] = {0, 7}
G[4] = {1, 2, 6}
G[5] = {}
G[6] = {7}
G[7] = {0}
また、本記事ではグラフを表すデータの入力は以下のように与えられることを想定します。$N$ はグラフの頂点数、$M$ は辺数を表します。また、各辺 $i = 0, 1, \dots, M-1$ は、頂点 $a_i$ と頂点 $b_i$ をつないでいることを表します。有向グラフの場合は $a_i$ から $b_i$ への辺があることを表し、無向グラフの場合は $a_i$ と $b_i$ とをつなぐ辺があることを表すものとします。
$N$ $M$
$a_0$ $b_0$
$a_1$ $b_1$
$\dots$
$a_{M-1}$ $b_{M-1}$
この形式のデータを受け取ってグラフを作る部分は例えば以下のように実装できるでしょう。
# include <iostream>
# include <vector>
using namespace std;
using Graph = vector<vector<int>>;
int main() {
// 頂点数と辺数
int N, M; cin >> N >> M;
// グラフ
Graph G(N);
for (int i = 0; i < M; ++i) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
// 無向グラフの場合は以下を追加
// G[b].push_back(a);
}
}
補足 1: 辺に重みがある場合
本記事では扱いませんが、グラフの辺に重みがあるケースもあります。例えば鉄道路線図上で二駅間の最短経路を求める問題では、駅間の移動時間についての情報が必要になります。そのような場合には、一例として以下のように辺を表す構造体を作ってあげる実装方法が考えられます。
# include <iostream>
# include <vector>
using namespace std;
struct Edge {
int to; // 辺の行き先
int weight; // 辺の重み
Edge(int t, int w) : to(t), weight(w) { }
};
using Graph = vector<vector<Edge>>;
int main() {
// 頂点数と辺数
int N, M; cin >> N >> M;
// グラフ
Graph G(N);
for (int i = 0; i < M; ++i) {
int from, to, weight;
cin >> from >> to >> weight;
G[from].push_back(Edge(to, weight));
}
}
補足 2: Boost Graph Library
グラフを C++ で扱えるクラスライブラリとして、
もよく知られています。本記事では、アルゴリズムを学びながら実際に実装して慣れるという観点からこれを用いず、自前実装を行います。
3. 深さ優先探索 (DFS) と幅優先探索 (BFS)
グラフ上の探索手法として代表的なものは、深さ優先探索 (depth-first search, DFS) と幅優先探索 (breadth-first search, BFS) とがあります。本記事では深さ優先探索の方をメインに扱いますが、最初にグラフ探索の一般的な考え方について紹介します。
3-1. グラフ探索の一般的なフレームワーク
まずは、グラフ上の頂点 $s \in V$ から出発して、$s$ から辺をたどって到達することのできる頂点をすべて探索する方法について、一般的なフレームワークを検討します。
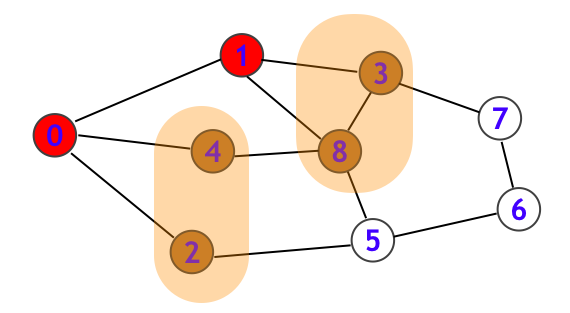
グラフ探索は、ネットサーフィンするときのことを思い浮かべるとわかりやすいかもしれません。下図のようなグラフを Web ページのリンク関係を表すものだと考えてみましょう。グラフ探索の始点 $s \in V$ は最初に開く Web ページであり、ここでは $s = 0$ とします。

このとき、まずは下図の頂点 0 に対応するページを一通り読みます。次に頂点 0 から辿れるリンクが 1, 2, 4 と 3 つあるとします。まずは 2 と 4 を保留にして 1 に対応するページを一通り読んだとします (下図のように読了済のノードは赤く示しています)。さて、この次にどのページを読むかについては人によって異なってくる部分だと思います:
- たった今読了した頂点 1 からそのまま辿れる頂点 (3 か 8) へと突き進む
- 一旦、保留にしていた頂点 2, 4 に対応するページを読んでおく
前者はとにかく辿れるリンクを猪突猛進に突き進む方針です。一方後者は「一旦保留にしていたページ」を一通り全部読み終わってから、より深いリンクへと足を踏み入れていく方針です。前者が深さ優先探索、後者が幅優先探索に対応します。
以上の話を、具体的なアルゴリズムに起こしてみましょう。以下の 2 つのデータを管理します:
- seen: その頂点を検知済みかどうかを表す配列
- todo: 検知したがまだ訪問済みでない頂点の集合 (保留中の頂点の集合)
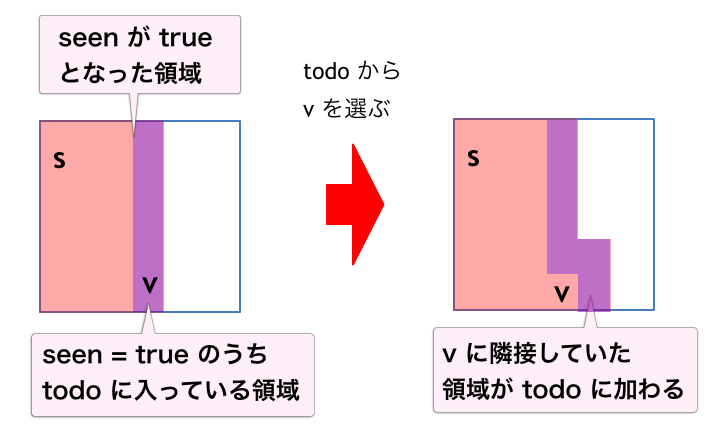
このときグラフ探索は、深さ優先であっても幅優先であっても、一般的に下のような疑似コードで記述することができます。なおここで、グラフの頂点 $v \in V$ に隣接している頂点集合を $T(v)$ と表しています。深さ優先か幅優先かの違いは、4 行目の保留頂点集合 todo から頂点 $v$ を取り出す作業を行うときに、どのようなポリシーに従って $v$ を選ぶかによって生じます。
- seen 全体を false に初期化して、todo を空にする
- seen[s] = true として、todo に s を追加する
- todo が空になるまで以下を繰り返す:
- todo から一つ頂点を取り出して v とする
- T(v) の各要素 w に対して、
- seen[w] = true であったならば、何もしない
- そうでなかったら、seen[w] = true として、todo に w を追加する
このアルゴリズムの動きとしては、下図のように seen が true な領域が徐々に広がっていき、最後には $s$ から行けるところ全体が true になるイメージです。
以下のグラフを例にとって、改めて $s = 0$ として詳細に追ってみます。まず一番最初に頂点 0 について seen[0] = true とした上で、todo に 0 を追加します。そして todo から 0 を取り出して頂点 0 に対応する Web ページを読んだ後、頂点 1, 2, 4 について存在を検知したので seen を true にした上で、todo に頂点 1, 2, 4 を追加します。次に todo から頂点 1 を取り出して読んだ後、頂点 3, 8 について存在を検知したので seen を true にした上で、todo に頂点 3, 8 を追加します。
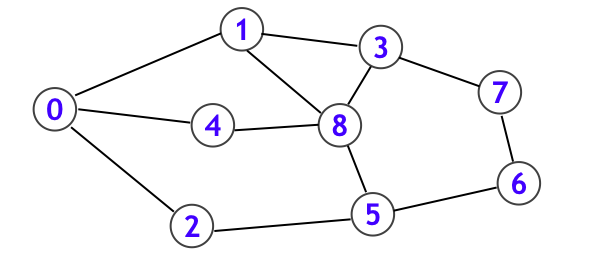
このとき、todo は {2, 4, 3, 8} となっていますが、ここで
- 最後に追加した {3, 8} を優先的に読む
- 最初に追加した {2, 4} を優先的に読む
という二通りの指針が生まれることになります。前者は LIFO (Last-In First-Out) ということで、保留頂点集合 todo をスタックにすることで実現することができます。また todo にスタックを用いたときのグラフ探索を深さ優先探索 (DFS) とよびます。後者は FIFO (First-In-First-Out) ということで、保留頂点集合 todo をキューにすることで実現することができ、このときのグラフ探索を幅優先探索 (BFS) とよびます。
3-2. 木の場合の探索順
DFS と BFS の動きについて、より詳細に見ていきたいと思います。ここでは一般のグラフよりわかりやすい木の場合を考えることで、両探索の違いを明らかにします。
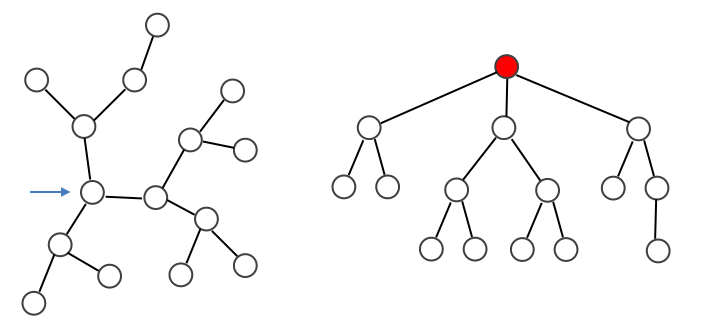
まず木とは、下図のように「サイクルを持たない」かつ「連結」であるようなグラフのことです。木に対し、特定の一つの頂点を特別扱いして根 (root) とよぶことがあります。そのような特定の根をもつ木のことを 根つき木 (rooted tree) とよびます。下図において、左側の木に対して矢印で指定したノードを根とすると右側に示したような根つき木になります。
木はグラフの一種ですので、前節で紹介した DFS・BFS ができます。このとき、根を探索の始点となる頂点とするのが自然でしょう。上図の右側の根つき木に対して、DFS・BFS を実施したときに、上記のアルゴリズムの 4 行目で todo 集合から取り出される頂点の順序 (ネットサーフィンでいえば Web ページを読む順序) を記入すると下図のようになります (5 行目以降で処理する $w$ の順序によって変わることにも注意します)。
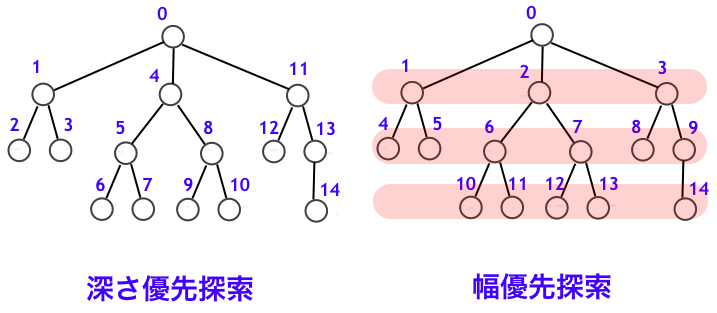
DFS が、根つき木の先端 (葉といいます) まで猪突猛進に突き進み、行き止まりになったら一歩戻って新たな分岐を試している様子がわかります。一方の BFS は、まずは根からの距離が 1 の頂点をすべて探索した後、根からの距離が 2 の頂点をすべて探索して、根からの距離が 3 の頂点をすべて探索して...といった具合に、根に近いところからこまめに探索していることがわかります。
3-3. DFS の再帰関数を用いた実装
ここまで DFS として
- seen: その頂点を検知済みかどうかを表す配列
- todo: 検知したがまだ訪問済みでない頂点の集合 (スタック)
というデータを用いた実装を行いました。しかしながら DFS は再帰関数と相性がよく、組込系でない限りは、しばしば再帰関数を用いて実装されます。そして 4 章で見るような複雑な処理を行う段階になると、再帰関数を用いることで、非再帰な実装よりも簡潔に実装できることが多いです。
再帰関数を用いた DFS の実装のテンプレを下に示します。とても簡潔に書けることがわかります。seen 配列についてはそのまま活用します。なお、ここではわかりやすさのために seen 配列をグローバル変数としていますが、実際は再帰関数の引数とするか、クラスのメンバ変数とするなどの工夫を行うとよいでしょう。
4 章で様々な例題を扱いますが、そのほとんどは、下記の実装にほんの少し手を加えるだけで解くことができます!!!
# include <iostream>
# include <vector>
using namespace std;
using Graph = vector<vector<int>>;
// 深さ優先探索
vector<bool> seen;
void dfs(const Graph &G, int v) {
seen[v] = true; // v を訪問済にする
// v から行ける各頂点 next_v について
for (auto next_v : G[v]) {
if (seen[next_v]) continue; // next_v が探索済だったらスルー
dfs(G, next_v); // 再帰的に探索
}
}
int main() {
// 頂点数と辺数
int N, M; cin >> N >> M;
// グラフ入力受取 (ここでは無向グラフを想定)
Graph G(N);
for (int i = 0; i < M; ++i) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
G[b].push_back(a);
}
// 頂点 0 をスタートとした探索
seen.assign(N, false); // 全頂点を「未訪問」に初期化
dfs(G, 0);
}
3-4. DFS の探索順序についての詳細
再帰関数を用いた DFS の実装を紹介したところで、再び DFS の探索順序について掘り下げてみましょう。この考察は、DFS を用いた応用的アルゴリズムである「トポロジカルソート」や「強連結成分分解」について学ぶときの理解の助けになります。
再び木の場合を考えます (一般のグラフの場合も、深さ優先探索木を考えることで結局は木の場合と同様になりますが、ここでは省略します)。木上の DFS は実は下図のようにグルッと一筆書きをするような動きをしています。
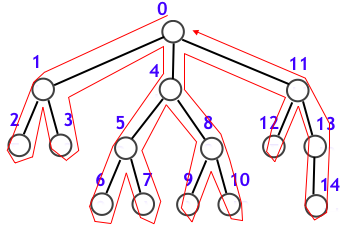
上図中の青い数値は「3-2. 木の場合の探索順」でも示したものですが、これは特に「根から初めて訪問した頂点の順序で順位をつけたもの」を意味していて行きがけ順といいます4。他の探索順として、下図のように「最後に訪問した頂点の順序で順位をつけたもの」を意味する帰りがけ順があります56。
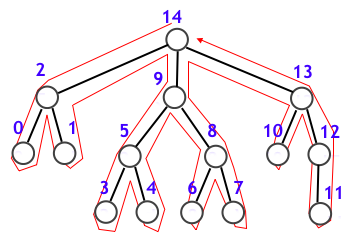
行きがけ順・帰りがけ順という概念を、再帰関数を用いた DFS コード上ではどのように対応するのかを確認しておきましょう。再帰関数のメイン部分だけを取り出すと以下のようになります。このとき
- 頂点 $v$ の行きがけ順: dfs 関数に入った直後の $v$ の順位
- 頂点 $v$ の帰りがけ順: dfs 関数から抜ける直前の $v$ の順位
ということになります。
void dfs(const Graph &G, int v) {
seen[v] = true; // v を訪問済にする
// v から行ける各頂点 next_v について
for (auto next_v : G[v]) {
if (seen[next_v]) continue; // next_v が探索済だったらスルー
dfs(G, next_v); // 再帰的に探索
}
}
このことを実際に確かめてみましょう。グラフインスタンスとしては、上図に対応する以下のものを用います。行きがけ順の順序をそのままグラフの頂点番号としています (すなわち、再帰関数を用いて行きがけ順を求めたとき、その順位と頂点番号とは一致するはずです)。
15 14
0 1
1 2
1 3
0 4
4 5
5 6
5 7
4 8
8 9
8 10
0 11
11 12
11 13
13 14
これに対して各頂点の行きがけ順・帰りがけ順を求める以下のコードを実行してみます:
# include <iostream>
# include <vector>
using namespace std;
using Graph = vector<vector<int>>;
vector<bool> seen;
vector<int> first_order; // 行きがけ順
vector<int> last_order; // 帰りがけ順
void dfs(const Graph &G, int v, int& first_ptr, int& last_ptr) {
// 行きがけ順をインクリメントしながらメモ
first_order[v] = first_ptr++;
seen[v] = true;
for (auto next_v : G[v]) {
if (seen[next_v]) continue;
dfs(G, next_v, first_ptr, last_ptr);
}
// 帰りがけ順をインクリメントしながらメモ
last_order[v] = last_ptr++;
}
int main() {
// 頂点数と辺数
int N, M; cin >> N >> M;
// グラフ入力受取 (ここでは無向グラフを想定)
Graph G(N);
for (int i = 0; i < M; ++i) {
int a, b;
cin >> a >> b;
G[a].push_back(b);
G[b].push_back(a);
}
// 頂点 0 をスタートとした探索
seen.assign(N, false); // 全頂点を「未訪問」に初期化
first_order.resize(N);
last_order.resize(N);
int first_ptr = 0, last_ptr = 0;
dfs(G, 0, first_ptr, last_ptr);
// 各頂点 v の行きがけ順、帰りがけ順を出力
for (int v = 0; v < N; ++v)
cout << v << ": " << first_order[v] << ", " << last_order[v] << endl;
}
結果は以下のようになりました。行きがけ順はきちんと頂点番号と一致しており、帰りがけ順も正しく求められていることがわかります。
0: 0, 14
1: 1, 2
2: 2, 0
3: 3, 1
4: 4, 9
5: 5, 5
6: 6, 3
7: 7, 4
8: 8, 8
9: 9, 6
10: 10, 7
11: 11, 13
12: 12, 10
13: 13, 12
14: 14, 11
タイムスタンプ
なお、行きがけ順と帰りがけ順とを統一する概念としてタイムスタンプ (time stamp) があります。これは各頂点 $v$ に対し、最初に発見した段階と、$v$ の子孫たちも含めて探索を終えた段階とを表すもので、下図では (前者)/(後者) で表しています。
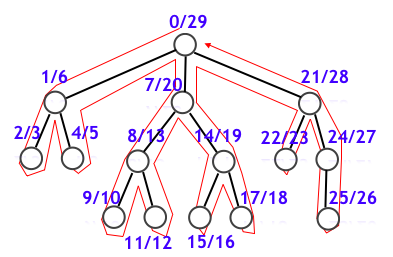
タイムスタンプを求めるのは上記の行きがけ順・帰りがけ順を求める実装をほんの少し変更するだけでよくて難しくないです。具体的には first_ptr と last_ptr を統一して一つの変数 ptr にしています。
void dfs(const Graph &G, int v, int& ptr) {
// 行きがけ順をインクリメントしながらメモ
first_order[v] = ptr++;
seen[v] = true;
for (auto next_v : G[v]) {
if (seen[next_v]) continue;
dfs(G, next_v, ptr);
}
// 帰りがけ順をインクリメントしながらメモ
last_order[v] = ptr++;
}
タイムスタンプは、強連結成分分解や、オイラーツアーを用いた木上クエリ処理について考えるときには重要な概念になります (いずれも蟻本上級編に載っています)。
3-5. DFS の計算量
DFS の計算時間についてです。ここでは頂点数 $N$、辺数 $M$ のグラフにおいて「まだ探索していない頂点があるうちは、探索していない頂点 $v$ を一つ選んで $v$ を始点とした DFS を実施することを繰り返す」という探索を実行することを想定します。
このとき、下の DFS 再帰関数の 5 行目の「for (auto next_v : G[v])」によって「グラフのすべての辺が調べ上げられている」ということがわかります。また 6 行目の「if (seen[next_v]) continue;」によって「すべての辺について調べられる回数は高々 1 回だけ」ということもわかります。したがって
- DFS 全体においてすべての頂点を一通り調べることになるので、それに要する時間が $O(N)$
- DFS 再帰関数においてすべての枝を一通り調べることになるので、それに要する時間が $O(M)$
ということで全体で $O(N + M)$ の計算時間がかかります。頂点数 $N$ についても辺数 $M$ についても線形時間となっています。これはグラフを入力として受け取るのと同等の計算時間で探索も行えることを意味しています。
void dfs(const Graph &G, int v) {
seen[v] = true; // v を訪問済にする
// v から行ける各頂点 next_v について
for (auto next_v : G[v]) {
if (seen[next_v]) continue; // next_v が探索済だったらスルー
dfs(G, next_v); // 再帰的に探索
}
}
-1. つづく
後編につづきます。
-
実際はそのような経路数は交差点数に対して指数的に増大するため、すべて列挙して解くことは難しく (ZDD などの列挙手法が近年注目を集めていますが)、より効率のよい方法が用いられます。 ↩
-
実際は、将棋やオセロの局面数は地球上に存在する原子の個数よりも多く、単純な全探索手法では解析不能ですし、他の効率よく解析できる手法も現在のところ知られていません。 ↩
-
図の例では例えば、新しいクラスに青木君、鈴木君、高橋君、小林君、佐藤君の 5 人がいて、「青木君と鈴木君」「鈴木君と高橋君」「鈴木君と小林君」「小林君と佐藤君」「青木君と佐藤君」はすでに知り合い同士であるといったことを表しています。 ↩
-
ここでは行きがけ順・帰りがけ順を 0-indexed で表示していますが 1-indexed で表示する文脈の方が多いかもしれません。 ↩
-
木の探索における行きがけ順・帰りがけ順という概念は、各社のコーディング面接で頻出のテーマでもありますね。 ↩
-
他に二分木の場合では「左側の子供の探索を終えた後・右側の子供の探索を開始する前」を表す通りがけ順があります。また BFS によって得られる探索順位をレベル順ということもあります。 ↩