この記事では Feature Store, 特に Feast について述べようとしていました。しかし、下調べに時間がかかりどう考えても本文の記述が間に合わないため、項目と画像のみが記述されています。そのうち追記されることでしょう。
要約
- Feature Store は機械学習モデルが利用する特徴量の提供を行う
- 機械学習モデルはストリームとバッチの両方のデータソースを扱い、学習時と推論時で求められるレイテンシに大きな違いがあるため、特別の考慮が必要
- Feature Store の実装はかなり複雑なため、導入には慎重になるべき
概要
Feature Store 自体の必要性について理解することは、機械学習で利用するデータについて深く理解することと同義です。機械学習において発生する Training/Serving Skew という課題について、データを利用するためのアーキテクチャから深追いしていきましょう。
本稿ではまず、 Treaning/Serving Skew のうち、スキーマの偏りについて着目します。スキーマの偏りは本番環境とオフライン環境、典型的には分析環境との差異が原因になるとされています。なぜこの2つの環境に差異が生じるのかを知るためには、サービス提供用のデータに求められる特性と、分析用のデータに求められる特性の違いについて知る必要があるため、これをまず確認します。
次に、本番環境と分析環境のデータの生成のために2つのコードを用意することで生じる課題について検討を行います。そもそも、なぜ2つのコードを用意したくなるのでしょうか。これに答えるためには、大容量データをリアルタイムに扱うためのアーキテクチャの進化の歴史を振り返る必要があります。
そして、機械学習を導入することで生じる本番環境と分析環境との差異について改めて検討します。ここまでを踏まえると、本番環境と分析環境の差異は古くから取り組まれている問題であることがわかります。では、なぜ機械学習で改めてこれに取り組まなければいけないのでしょうか。この疑問に答えることは、スキーマの偏りが発生するケースの具体的な理解を行うことや、 Feast の取り組みのモチベーションを理解することに等価です。
最後に、Feast がカバーする範囲とカバーできない範囲の確認と、TFDV を組み合わせることでどこまでカバーできるようになるかを確認して本稿を終えます。
Training/Serving Skew
ここでは機械学習を用いる上での典型的な課題である Training/Serving Skew を見ていきます。まずは定義を確認し、その後、典型的な4つのパターンについて確認しましょう。
Training/Serving Skew とは
機械学習を用いる場合、モデルの訓練と推論時で大きく要件が異なります。この非対称性から生じる様々な課題を総称して、Trainig/Serving Skew と呼びます。この文脈での Skew は「偏り」と訳されるようです。
訓練時と推論時の要件の違いについてもう少し詳細に見ていきましょう。MLOps: 機械学習における継続的デリバリーと自動化のパイプライン から典型的な機械学習のプロセスを表す図を引用します。

このプロセスはMLとOpsに別れます。MLの部分はよく「機械学習」について述べるときに扱われるワークフローです。ここでは何らかのデータソースからデータを取得し、前処理を行ってモデルを訓練させて評価を行います。これは典型的にはデータサイエンティストが担う部分でしょう。
Ops の部分では作成したモデルを使ってプロダクション環境に何らかのサービスを提供しています。ここも同様に何らかのデータソースからデータを取得し、前処理を行い、モデルに入力しています。プロダクション環境でも学習時と同様な処理を行わなければいけないことは本稿の重要なテーマとなります。
MLの部分のワークフローは遅延について寛容です。もともとモデルの訓練にはそれなりの時間がかかるため、データ取得時のレイテンシが大きくとも構いません。また、ここでは必要な制度を達成しなければ後工程に進めないために、複数のストレージから取得したデータを結合する、複雑な前処理を行うといったことが行われがちです。
一方、Ops の部分では違います。ユーザーからのリクエストに早く答えなければいけませんし、サービスの安定性も重要です。さまざまなストレージからデータを取得することは場合によっては不可能です。複雑な前処理も時間の制約や計算資源の制約から実行が著しく困難になる場合があります。
このように、訓練時と推論時では非機能要件が大きく違うなか、データに対して同じ処理をしなければいけません。この差異が様々な困難を引き起こします。
Training/Serving Skew の分類
訓練時と推論時の差異によって引き起こされる Training/Serving Skew の具体例とその分類を確認しましょう。Training/Serving Skew について述べている文章は数多くあります。TFX: A TensorFlow-Based Production-Scale Machine Learning PlatformやData Validation for Machine Learning がその例ですが、ここでは個人的に最もわかりやすかったTFDVのドキュメントの古い記述を紹介します。
このドキュメントでは、Training/Serving Skew を次の4つに分類しています。
- スキーマの偏り
- 特徴の偏り
- 分布の偏り
- Scoring/Serving Skew
スキーマの偏りは訓練用データと本番用データが同一のスキーマに従わないときに発生します。特徴量の偏りはモデルに与えられる特徴量の値が訓練時と本番環境とで異なることにより発生します。分布の偏りは特徴量の分布が本番環境のデータの分布と著しく異なるときに生じます。Scoring/Serving Skew は少し説明が厄介です。説明文を引用すると次のようになっています。
トップ10件の広告を提示するような広告システムを考えます。これらの10件の広告のうち、1つのみがユーザーにクリックされる可能性があります。10件の提示された標本データが次の日の訓練データに使われます。1件はポジティブで、9件はネガティブです。一方、本番環境ではそのモデルは100件の広告をスコア付するために使われます。他の90件の提示されなかった広告は、暗黙的に訓練データから取り除かれます。これは、下位にランク付けされたものについて誤予測するように、暗黙的なフィードバックループを引き起こします。下位にランク付けされたデータは訓練データに現れないからです。
Treaning/Serving Skew のなかで、もっとも基本的な過ちはスキーマの偏りです。スキーマの偏りは、データソースから取得したデータに対して、同一の処理が行われていないことを意味します。学習時と推論時では非機能要件が大きく異なっていたことを思い出しましょう。その結果、極端な場合、学習時には Jupyter notebook を用いて pandas で前処理を行っていて、本番環境では全く違う言語、たとえば Go や Java を用いたパイプラインが組まれている場合もあるでしょう。このような状況では同一の処理を行い続けていることを担保することは困難です。
このようにデータに対する同一の処理を行うことが困難な場合、Training/Serving Skew のうち最も基本的なものであるスキーマの偏りを引き起こします。これは学習時と推論時の差異に起因して引き起こされます。
分析用のデータとサービス提供用のデータの差異
学習時と推論時の差異が生じる原因に、要求されるデータがそもそも違うことが挙げられます。以前に非専門家向けに解説を書きましたが機械学習では過去のログを利用します。解説記事では過去1ヶ月に渡ってログを集計すると記しています。このようなログは一般的に、サービスが保持しているストレージとは別のストレージ、データレイクやデータウェアハウスに保管されているでしょう。
一方、Web サービスがユーザーからのリクエストを解決するために保持しているデータは、典型的にはその時点で最新のデータでしょう。古いデータを参照してしまい、ユーザーの操作結果とは異なるものをユーザーに提示してしまうことはできるだけ避けるのが望ましいと考えられます。
このデータに関する差異は機械学習が流行する以前から、分析用のデータとサービス提供用のデータの間の差異として知られていました。分析用のデータは、たとえば過去のログを集計しサービスの利用状況に基づいて経営判断を下すために用いられます。この処理を行うシステムは分析処理システムと呼ばれます。サービス提供用のデータはユーザーからのリクエストに対して素早く応答するために使われます。この処理を行うシステムはトランザクション処理システムと呼ばれます。
トランザクション処理システムと分析処理システムでは求められる性質が全く異なります。データ指向アプリケーションデザインの表3-1はその差異をまとめています。

このようにシステムへの要求が異なるため、トランザクション処理システムと分析処理システムでは異なるストレージを採用することは一般的です。MySQL や PostgreSQL などの RDB は前者に、BigQuery は後者に使われるのが典型的でしょう。ところが、分析処理システムで用いるデータもトランザクション処理システムで用いるデータも両方用いるタスクがあります。機械学習です。特に問題なのは学習ではなく推論です。
機械学習の推論では、通常サービスが保持していないデータを推論時に要求する場合があります。例に挙げた行動予測では、過去30日間の行動履歴を集計していましたが、そのようなデータは最新のデータではないためトランザクション処理システムは必ずしも保持していないでしょう。このため、ユーザーのリクエストに合わせて分析処理システムの保持するストレージから、データを素早く集計する必要が生じます。これは分析処理システムへの要求になかった事項です。
このように、機械学習の推論処理では、分析処理システムの保持するデータをトランザクションシステムに要求される速度で利用するという難題に挑む必要があります。これは、それぞれのシステムが利用するストレージの性質上、かんたんには解決できません。
大規模なデータを素早く扱う技術
これまでに機械学習では訓練時だけではなく、推論時にもデータの取り扱いについて困難があることを見てきました。推論時には更に、大規模なデータをリアルタイムに扱う必要が出てきます。大規模なデータをリアルタイムに扱う際には様々な事項に注意が必要です。それについて述べた文章には例えば次のものがあります。
この難題についてはさまざまな取り組みが行われてきました。ここではそれらの取り組みをざっと振り返ってみましょう。
問題設定
以降ではビッグデータを処理するための技術について述べていきます。対象にするサービスは Twitter のような大規模データをリアルタイムに扱う必要があり、なおかつ長期間保存したデータに対するバッチ処理もしなければいけないというサービスとします。また、トランザクション処理も分析処理も両方必要になるものとします。利用者の少なく、サービスに求められる安定性も高くないサービスは対象外とします。
ラムダアーキテクチャ
ラムダアーキテクチャはリアルタイム処理とバッチ処理の両方の処理のために2つのデータの経路を用意するアーキテクチャです。Microsoft のドキュメントビッグ データ アーキテクチャから図を引用します。
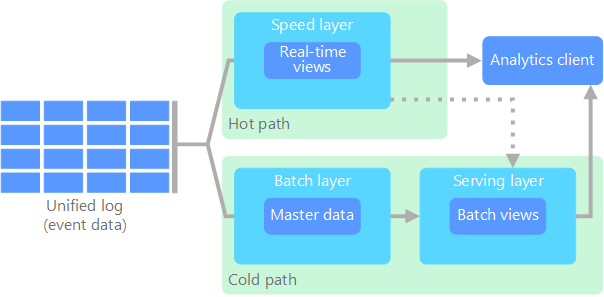
図中には2つの経路 (path) が記されています。それぞれの経路の特性は次のとおりです。
- ホットパス : リアルタイム処理を担当、厳密さよりも応答速度を重視
- コールドパス : バッチ処理、応答速度よりも厳密さを重視
クライアントはこの両方のパスからのデータを利用して、データ分析を行います。
ラムダアーキテクチャの欠点
ラムダアーキテクチャは2つのパスを持つため、実装が複雑になるという欠点があります。
ラムダアーキテクチャでは、コールドパスとホットパスという2つのデータパスがあるため、リアルタイム処理とバッチ処理で一貫した結果を得ようとする場合、両方のパスで同じ集計処理を実現する必要が発生します。ホットパスではストリーム処理が行われ、コールドパスではバッチ処理が行われるため、それぞれ全く別のコードベースになります。これをメンテナンスしていくことには困難がつきまといます。
別の文脈ですが、Rules of Machine Learning: Best Practices for ML Engineering や A brief introduction to Training/Serving Skew で述べられているように、2つの異なるコードベースを同一に保ち続けようとするのはあまり良い方法とは言えません。単一のコードで処理できることが理想です。
Dataflow
Dataflow (MilWheel) はデータを単一のパスで処理することで、リアルタイム処理とバッチ処理に一貫したロジックを適用します。Dataflow は基本的にストリーム処理が行われるのですが、ウィンドウを設けて時間を区切った集計が可能です。日次で行われるバッチ処理は24時間単位のウィンドウでデータを集計したものだとみなせるため、理論上はバッチ処理を撤廃することが可能です。
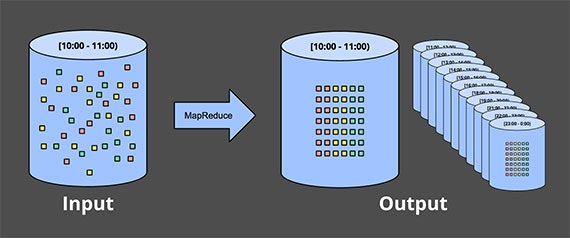
集計結果はアプリケーションに提供されます。また、生のログをデータレイクやデータウェアハウスに格納することで、長期間に渡る分析も可能になります。
Dataflow についてはより詳しく解説した記事が https://qiita.com/kimutansk/items/d6daca473440462634a0 にあります。ぜひ参照して下さい。
機械学習の導入によって発生する課題
ここでは、機械学習の導入によってデータパイプラインに新たな課題が発生することを確認します。その課題は、機械学習では分析用のデータとサービス提供用のデータを、異なる環境で使うことで発生します。
機械学習では分析用のデータもサービス提供用のデータも必要
機械学習では分析用のデータとサービス提供用のデータを両方要求する場合があることを、次の仮想的なケースを対象に確認しましょう。
- テーブルデータを対象にした教師あり学習
- ログインしているユーザーがBotかどうかを判定したい
- これまでのサービスの利用履歴と、現在の行動からユーザーがBotかどうかを判定する
また、データは次のように保存されているものとします。
- 現在の行動: ストリーム処理の対象となり、ログがデータレイクに保存されている
- これまでのサービスの利用履歴: 日次で集計され、データウェアハウスに保存されている
データサイエンティストがJupyter Notebook 上で機械学習モデルを作成するとします。ここで利用するのは過去のデータであり、データレイクやデータウェアハウスに格納されているデータを用いることになるでしょう。ワークフローは MLOps: 機械学習における継続的デリバリーと自動化のパイプライン の Lv. 0 のようになります。
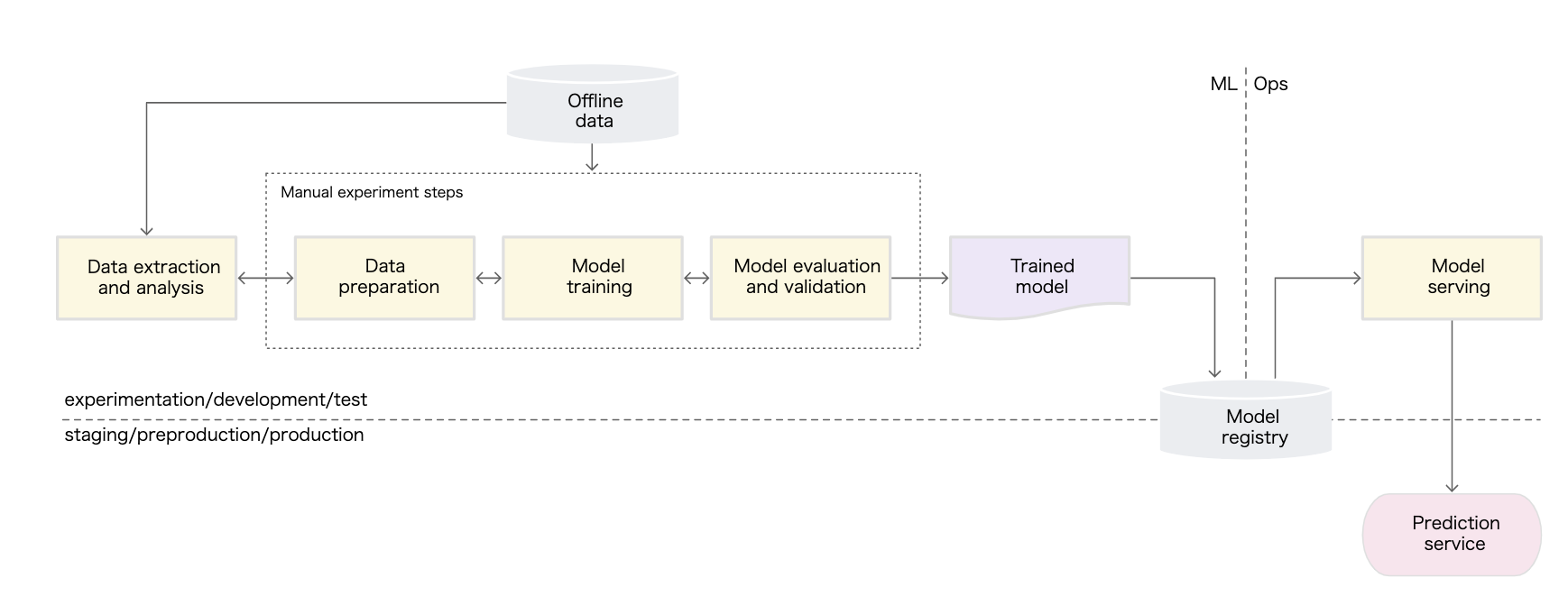
過去の利用履歴と過去の行動ログをもとに特徴量を作成し、実験環境で機械学習モデルを作成して評価します。さまざまな試行錯誤の結果、十分な性能を出すことのできるモデルが作成できたものとします。この次に行うのは、このモデルを本番環境にデプロイすることです。
ここで本番環境と実験環境の差異が問題を生み出します。本番環境では実験環境と異なり、これまで考慮してこなかったさまざまなことを考慮しなければいけなくなります。それには監視などのさまざまなものが含まれますが、ここではデータパイプラインに着目します。
実験環境と本番環境ではデータパイプラインの実装方法が大きく異なりえます。実験環境では BigQuery などのストレージからデータの取得が行われるでしょう。そこでは Jupyter Notebook を用いてバッチ処理が行われます。しかし、Twitter のようなハイトラフィックなアプリケーションを想定すると、本番環境ではストリーム処理が行われています。Jupyter Notebook に書かれたバッチ処理前提のコードを、本番環境で動くように書き換える必要が生じてしまいますが、これは容易ではありません。
また、機械学習モデルは一度でプロイして終わりではなく、継続的な改善が必要です。性能の向上のために、新たな特徴量をモデルに追加することは実験環境では容易です。ですが、本番環境においてその特徴量を使えるようにするためには、ストリーム処理への対応を、実験環境と本番環境で行われる処理に一貫性を保ちつつ行わなければいけません。
これは実験環境と本番環境の差異に起因するものであり、Treaning/Serving Skew の1つです。
TensorFlow Transform + Apache Beam
実験環境と本番環境とでデータの取得方法が一貫しないという課題に対する対策として、TensorFlow Transform と Apache Beam について見ていきます。
TensorFlow Transform は機械学習の前処理用のライブラリです。名前の通り、TensorFlow と一緒に用いることが想定されています。TensorFlow Transform は一連の前処理を計算グラフとして定義します。この計算グラフは TensorFlow のモデルで用いるものと同一です。
Apache Beam は分散処理基盤を抽象化された API を提供します。Apache Beam を用いると Apache Flink や 前述の Dataflow といった分散処理基盤に対して、共通の API で分散処理パイプラインを実装できます。また、テストやデバッグ用に Direct Runner という分散処理基盤を用いずにローカルでパイプラインを実行する仕組みも用意されています。言語は Java Python を用いることができます。
データの取得処理において TensorFlow Transform と Apache Beam を組み合わせることにより、実験環境と本番環境で同じコードを用いることが可能です。実験環境でのデータ取得処理を Apache Beam を用いて Jupyter Notebook 上で記述しておけば、同じコードを本番環境で利用できます。ただし、もちろん、Jupyter Notebook 上のコードをテストしたり、Jupyter Notebook 上のコードが十分にキレイに書かれている必要があります。
TensorFlow Transform と Apache Beam の組み合わせにより、実験環境と本番環境という異なる2つの環境に対して、統一的なプログラミングモデルを用いて、常にストリーム処理を前提に実装できます。これはラムダアーキテクチャの課題に対して Dataflow がバッチ処理とリアルタイム処理をストリーム処理に統一したことに類似しています。
TensorFlow Transform と Apache Beam を組み合わせた前処理の実装については、次の資料が詳しいです。
機械学習のためのデータ前処理: オプションと推奨事項 にある次の表は素晴らしいまとめになっています。

ストレージに関する実験環境と本番環境の差異
まだ残っている実験環境と本番環境の重大な差異に、ストレージに求められる非機能要件があります。機械学習モデルの本番適用において、これは重大な課題となることを見てきましょう。
実験環境ではデータの読み込みに膨大な時間がかかったとしても問題になりにくいです。機械学習用のモデルで使う特徴量は、実験的な取り組みの場合、分析用のデータレイクやデータウェアハウスから集計することがあるでしょう。この場合、集計に膨大な時間がかかったとしても問題になりません。分析用のストレージに対するクエリは本番環境の負荷を上げないためサービスの利用者に迷惑がかからず、分析者は大概の場合十分に長い時間待たされることを許容できるためです。
一方、本番環境ではデータの読み込みに膨大な時間がかかると問題になります。これまでにストリーム処理を検討してきたのは大規模なデータをリアルタイムに処理しなければいけないサービスやアプリケーションが、すでに実際に存在するためでした。機械学習を本番適用する場合、推論するためのデータの読み込みに時間がかかることは許容されません。
Feast が取り組む課題
ようやく Feast が取り組む課題について述べる準備ができました。問題について見ていきましょう。
まず、機械学習モデルは学習時と推論時で同じデータを要求することに注意が必要です。データレイクやデータウェアハウスに収められているデータをモデルの訓練に用いた場合、本番環境でのモデルの推論時に同じデータが必要になります。つまり、BigQuery のような読み込みに時間のかかるストレージから、リアルタイムにデータを読み込む必要が出てきます。
これは簡単な問題ではありません。この問題は機械学習モデルを本番環境にデプロイする場合、データウェアハウスに収められているデータを集計するパイプラインを新たに設計・構築する必要があることを示しています。しかし、データウェアハウスに収められているデータから計算される特徴量は、年間平均利用回数のような長期間に渡る集計を行うものも考えられます。これについてストリーム処理ですべて対応することは、概念上はできたとしても実際は対応が難しいでしょう。
データレイクやデータウェアハウスのような分析用のストレージを、本番環境でのストリーム処理において扱う。これが Feature Store の1つである Feast が取り組む課題です。
Feast がカバーする範囲としない範囲
Feast は Feature Store (特徴量ストア) と呼ばれるものの一つです。Feature Store は Netflix や Spotify などさまざまな企業が提唱しています。また、各クラウドサービスでもサービスとして提供されるようになってきており、AWS では Amazon Sagemaker Feature Store が提供されているほか、 GCP でも2021年中に提供される見込みです。一方、Feature Store と一口に言ってもそれが表すものはそれぞれバラバラです。ここでは Feast のドキュメントを参照し、Feast がカバーする範囲について見ていきましょう。
Feast がカバーする範囲
Feast がカバーするのは次の課題です。
- 機械学習モデルの一貫したデータへのアクセスの必要性
- 新しい特徴量の本番環境へのデプロイの困難さ
- ある時点で収集されたデータという機械学習モデルの要求
- プロジェクトを横断した特徴量の利用の困難さ
順に見ていきましょう。
機械学習モデルの一貫したデータへのアクセスの必要性については、機械学習モデルの訓練時と推論時で一貫した方法でデータを集計する必要があることを指しています。これまでに見てきたように、訓練時と推論時でモデルに提供されるデータが異なることはモデルの性能低下をもたらします。また、訓練用と推論用の2つのデータパイプラインで一貫した処理を行うように保守を続けることは困難な作業です。
新しい特徴量の本番環境へのデプロイの困難さも、訓練環境と本番環境の差異に起因するものです。データサイエンティストが新しい特徴量を思いついたとしても、それをエンジニアが本番環境で実装するのにはさまざまな苦労が伴い、簡単にはできません。
ある時点で収集されたデータという機械学習モデルの要求は、TFDV のドキュメントで特徴量の偏りとして紹介されているものです。データサイエンティストが過去データから将来予測を行うモデルを訓練させる際に、誤ってその時点では手に入らないデータを特徴量として使ってしまうことはありがちなミスです。
プロジェクトを横断した特徴量の利用の困難さは、あるチームが特徴量を実装した際に別のチームで利用可能にすることを要件に加えておらず、別のチームでは利用不能になってしまうことを指します。これは大規模な組織でないと発生しないかもしれませんが、ある機械学習タスクで有用な特徴量は別の機械学習タスクでも有用なことはあるので、覚えておいて損はないでしょう。
Feast がカバーしない範囲
Feast がカバーしない範囲には次があります。
- 特徴量エンジニアリング
- 特徴量の探索
- 特徴量の検証
特徴量エンジニアリングは、生データを加工して機械学習モデルにとって有用な特徴量を作り出すことを言います。生データが実行したイベントの配列や、過去に訪れたページの URL の配列だったりした場合に、そこから各イベントや URL の表示回数を集計することは特徴量エンジニアリングの一つです。このような加工処理はデータ分析基盤上で行ったり、モデル特有なものはモデルの前処理として実装することが想定されています。
Feastの実装
Feast は取り組む問題の難しさからか実装もかなり複雑です。ここでは Feast の実装について初出時から順を追い確認していきましょう。
ここで述べる内容については、 https://qiita.com/f6wbl6/items/a07493db66512ef22234 で触れられていますのでぜひ確認ください。
初出時
Feast の初出は次のブログ記事でした。
そこでの実装は次のようになっています。
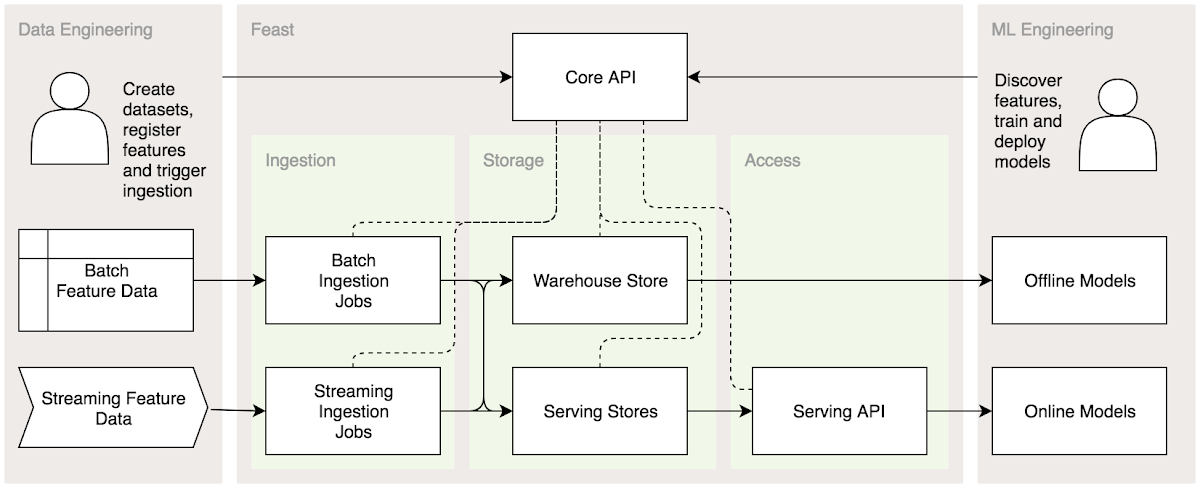
図の構成は次のようになっています。
- 左側: データエンジニアリング、特徴量を作成し Feast に投入する
- 中央: Feastそのもの、詳細は後述
- 右側: 機械学習エンジニアリング、モデルを作成し、Feast から得たデータを用いてモデルを訓練しデプロイする
左側のデータエンジニアリングにおいて、バッチ処理による特徴量とストリーム処理を行う特徴量が両方提供されている点に注意しましょう。ここから、ここまでに述べてきたような、リアルタイムなストリーム処理基盤と、大容量のバッチ処理基盤の両方を同時に扱えることを意味しています。
右側の機械学習エンジニアリングにおいて、もオフラインモデル (バッチ処理) とオンラインモデル (ストリーム処理) の両方が記されています。これらのモデルへの入力が単一のデータソースから提供されている点が特徴的です。機械学習で用いるデータを取得する処理について、バッチ処理時とオンライン処理時の一貫性を保つために Apache Beam を用いる点はこれまでに同じです。
図中の中央に描かれている Feast の中身に着目しましょう。Feast は3つのレイヤーで構成されています。
- Ingestion: データソースからデータを取得するレイヤーです。このレイヤーはバッチ処理とストリーム処理の両方に対応します。
- Storage: 取得したデータをキャッシュするレイヤーです。バッチ処理用の Warehouse Store と オンライン処理用の Serving Store に分かれます。それぞれのレイヤーは Ingestion レイヤーの両方の出力を利用できます (後述)
- Access: Feast が取得したデータを提供するレイヤーです。とくに、オンライン処理用には専用の API を提供します。
Storage には Warehouse Stora と Serving Store がありますが、Warehouse Store にも Serving Store にも Batch Ingestion Jobs と Streaming Ingestion Jobs の両方から線が伸びている点には注意が必要でしょう。この時点では詳細は記されていませんが、バッチ処理で得たデータをストリーム処理で提供するための機構がここに備わっていることが想定できます。
この時点では Feast は GCP 上に構築されていました。このことから、この時点の Feast は MilWheel (DataFlow) 上に構築され、ストリームデータの受け渡しには Cloud Pub/Sub が使われるような構成で歩いことが想定できます。
現状 (2021年1月時点)
Feast のブログ記事で2021年1月時点での Feast の実装について概要が記されているので確認していきましょう。
この時点での実装は次のようになっています。
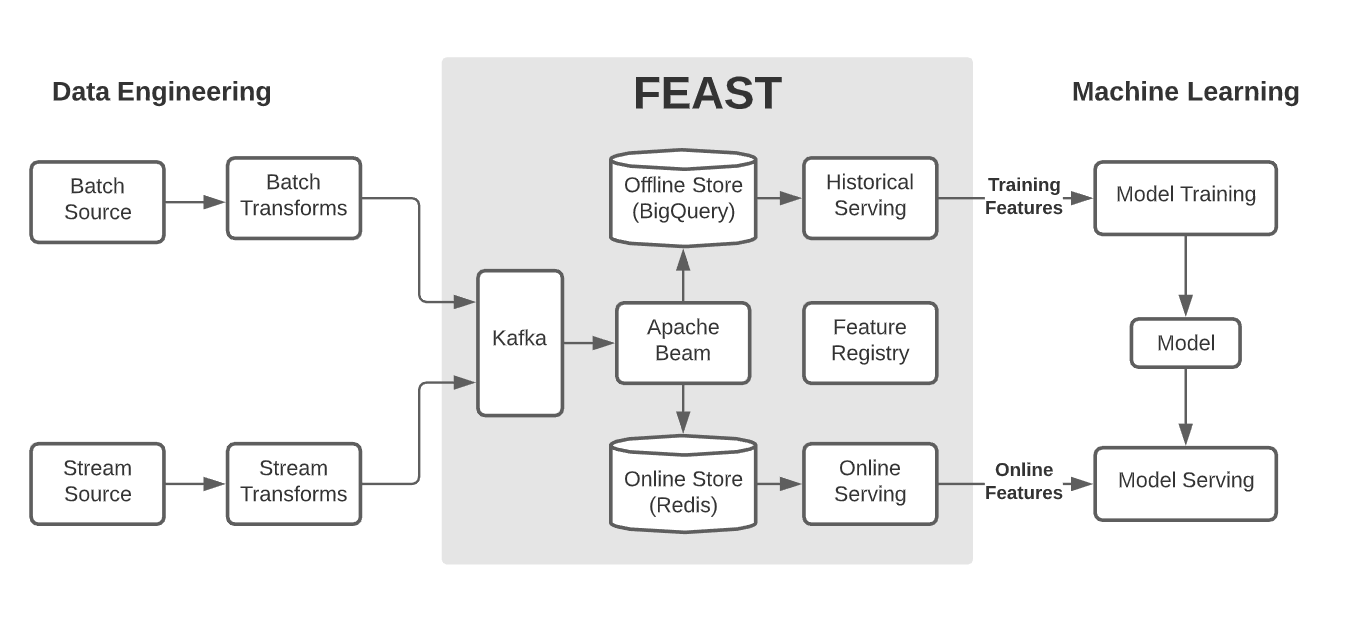
変更点として次が見て取れます。
- ストリーム処理基盤として Kafka を採用している
- Online Store として Redis を採用している
- Offline Store として BigQuery を採用している
Offline Store として BigQuery を採用していることから、この時点ではまだ GCP 上でのみ利用可能であることが伺えます。一方、ストリーム処理基盤として Kafka を採用していること、Online Store として Redis を利用していることから GCP への依存を減らしつつあることも伺えます。
また、Online Store の役割がよりはっきりしたと言えるでしょう。Online Store の実装として Redis を用いていることから、このレイヤーはストリーム処理基盤からの入力を透過的に提供するのではなく、ストリーム処理基盤とバッチ処理基盤からの入力をキャッシュしてストリーム処理として提供する役割を担うことがわかります。
現状について記述したこの図により、クラウドに依存しないことを目指すというプロダクトの方向性と、Feast のそれぞれのレイヤーの役割がよりはっきりしました。
この先
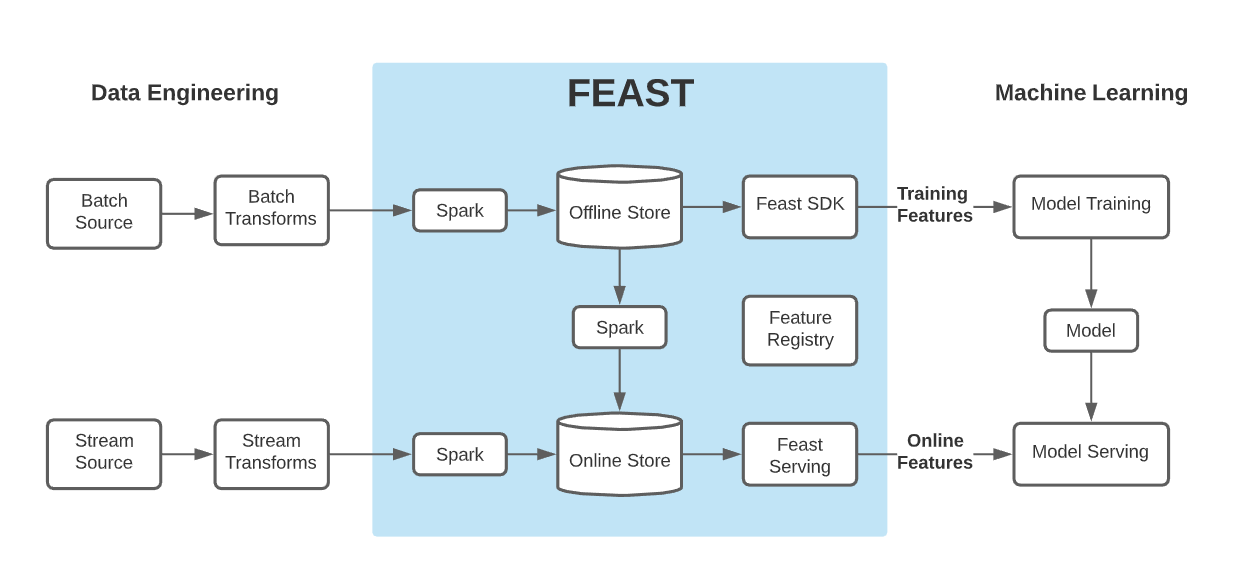
Spark を重用している。
Feast で解決できそうなもの/しないもの
TBD
解決できそうなもの
- 特徴量の素早いデプロイ/再利用
- など
解決しないもの
- データソース自体の管理
- 特徴量の分布の管理
TFDV と Feast の組み合わせ
サンプルコード
TFDV
TensorFlow Data Validation は特徴量のスキーマや統計量を参照して、値の分布自体を管理します。
改めて Training/Serving Skew
https://www.tensorflow.org/tfx/data_validation/get_started に "Data Validation" で実現すべきものについて書いてあるから読んで!
TFDV の機能
書く