この記事は?
この記事は、ドワンゴ Advent Calendar 2016の14日目の記事です。
この記事で書いている内容は?
Googleが出しているストリームデータ処理の資料を要約したものです。
つまり、「Googleが考えるストリームデータ処理とは?」ということになるかと。
趣味でストリームデータ処理について調べていたのでまとめてみます。
出来るだけよく出てくる固有の言葉を最初から使用せずに書いているつもりですが、
何かわかりにくい場所あればコメントいただけると。
「ストリーム処理」とだけ書くとストリーミング配信等とも微妙に混同しやすいため、
区別のために「ストリームデータ処理」と書いています。
基となっている情報は下記の5つです。
- MillWheel: Fault-Tolerant Stream Processing at Internet Scale
- The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing
- The Beam Model
- The world beyond batch: Streaming 101
- The world beyond batch: Streaming 102
ストリームデータ処理とは?
ストリームデータ処理という言葉は様々な用途に使用されています。
そのため、用途や実際のシステムの概ねの共通点である、下記の性質を持つ処理として定義しています。
- 無限に発生し続けるデータを処理
- 常に増大し続け、本質的には無限に発生するデータを処理します。
- これがしばしば「ストリームデータ」と呼ばれます。
- Googleであれば、下記のようなものが該当します。
- 検索エンジンに対して実行されている検索クエリの実行ログ
- 常に増大し続け、本質的には無限に発生するデータを処理します。
- 処理が永続的に継続
- 常に増大し続け、本質的には無限に発生するデータであるため、処理も永続的に実行されます。
- とはいえ、実際は上記のようなデータであっても一定の時間の区切りをすればバッチ処理でも処理は可能です。
- そのため、区別の意味でも永続的に継続するようなものをストリームデータ処理と呼びます。
- 常に増大し続け、本質的には無限に発生するデータであるため、処理も永続的に実行されます。
- 低遅延、近似値&不定期な結果出力
- ストリームデータ処理はバッチ処理に比べて遅延が小さくなります。
- ストリームデータ処理が生成する結果は以後に説明する性質の関係上、しばしば近似の値だったり、不定期な出力が行われます。
- バッチ処理の場合、基本は生成されるのは完全なデータで、出力されるのはバッチ処理が実行完了したタイミングと明確ですので、それとの対比になります。
まとめてみると長くなりましたが、「無限のデータを処理する実行エンジン」と考えておけばいいと思います。
どういう用途に使用されているのか?
あくまで例示になりますが、下記のような用途で使用されているようです。
- 課金処理
- (※GoogleではAdWordsの課金処理が当てはまると思われます。最近ではGCPの利用料課金とかもありそうですが。)
- ライブ費用見積
- (※こちらも同じく、GoogleではAdWords/GCPの費用見積もり等が当てはまるかと。)
- 不正検出
- (※あるアカウントに対する不正ログイン検知等)
- 不正検出結果復旧
- (※あるアカウントに対する不正ログイン検知して停止した後に復旧する処理等)
基本は「素早く応答を返す必要があるもの」「何かを検知して対応をするもの」のどちらかとなるようですね。
同じビッグデータ処理に属するバッチ処理とはどう違うのか?
ストリームデータ処理を考えるにあたり、バッチ処理と特徴を比較して差分を明確にします。
まずは、バッチ処理が必要としている前提を確認します。
- バッチ処理実行時に全てデータが揃っており、処理対象の範囲が明確でないといけない。
- バッチをまたいだ結果出力は基本的に対応しない。
1つ目の前提については、バッチ処理は下記のように元から完全にそろっているデータを整形するものだ、ということからわかると思います。
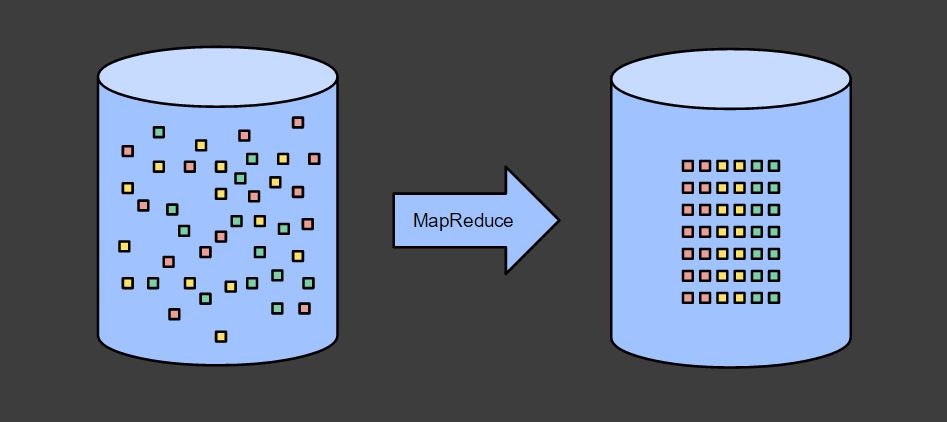
複数の結果を出力する場合には、下記のように複数回バッチ処理を実行します。
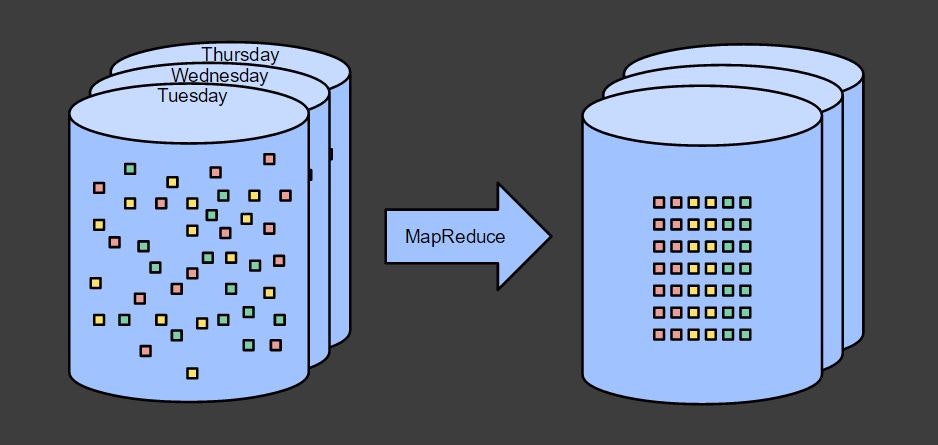
結果を時間ごとに区切る場合には、それを全て含むデータを基に、バッチ処理を実行します。
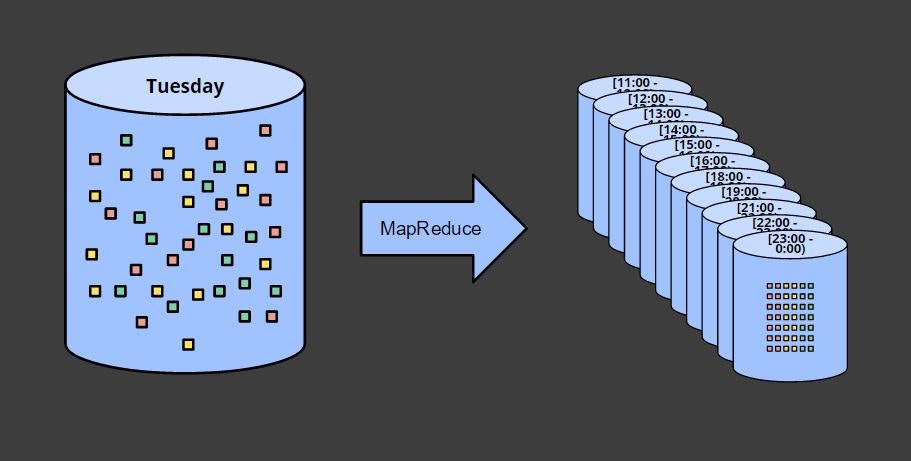
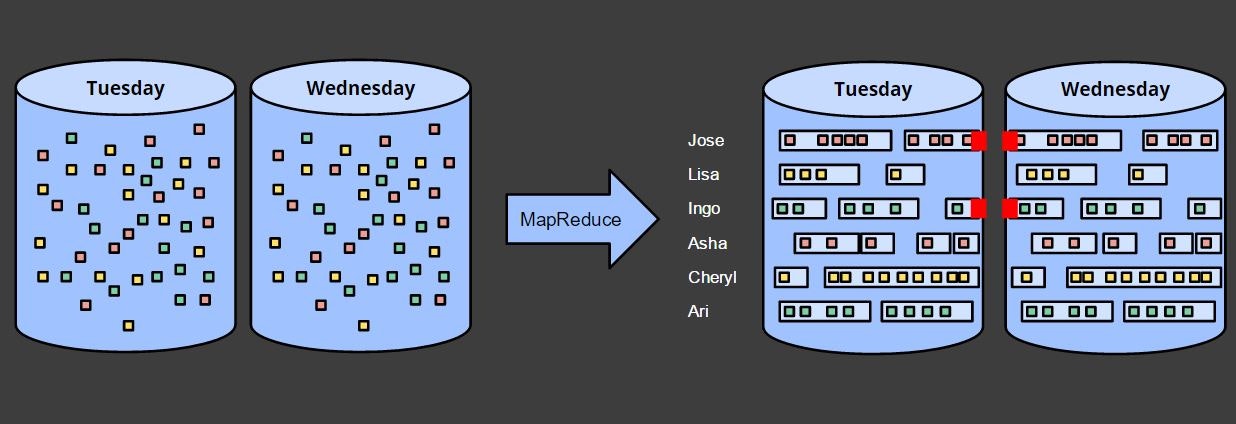
2つ目の前提については、下記のユーザのセッション(一定期間内に継続してアクセスがあった場合にさします)を出力する場合の図を見るとわかると思います。
火曜日、水曜日の別々に出力すると、日を跨いだセッションが区切られます。
水曜日の結果を火曜日とつなげたければ、火曜日の結果を読み込んで新たに結果を出力しなおせばできますが、実際にやろうとすると過去の結果を全て読み込んでつなげる必要が出てくるあたり、現実的ではありません。
ですが、ストリームデータ処理の場合は下記の通りこの前提を適用することはできません。
- バッチ処理実行時に全てデータが揃っており、処理対象の範囲が明確でないといけない。
- > 無限のデータであり、常時データは到着し続けるためデータが揃うということはない。
- バッチをまたいだ結果出力は基本的に対応しない。
- > そもそも無限のデータを処理つづけるもののため、前提自体が違う。
ただ、バッチ処理と同じく実行時に全てデータが揃っていれば、バッチ処理と同じことを実行することは可能です。
そのため、ストリームデータ処理はバッチ処理の機能的には上位互換にあたる、というのがこの比較の中で述べられています。
(※ただし、これはあくまで機能的にはということで、人間の理解のしやすさや管理のしやすさ、性能的な効率とかは当然別途比較する必要があるとは思います。)
どういう新たな困った点があるのか?
無限のデータを処理する場合、新たな困ったことが出てきます。
それは、「データが発生した順にシステムに到着するわけではないこと」(Out of order)です。
例えば、スマートフォンからデータを収集するようなストリームデータ処理を行う場合、電波が切れて、その後しばらくしてから電波が復旧した場合、「電波が切れたタイミングのデータ」が後から到着することになります。
上記のような事情があるため、ストリームデータ処理では下記の2つの時刻の概念が存在します。
- イベント時刻(EventTime)
- 実際にデータを生成することとなったイベントが発生した時刻
- 処理時刻(ProcessingTime)
- 実際にストリームデータを処理した時刻
それでなぜ困るの?
仮にデータの到着が遅れても、データ間に関わりが無ければ「結果が近似値である」ということはわかるものの、システムを構築する際に特に困ることはありません。
システムに到着し次第処理し続ければいいわけですので。
(※どのタイミングで全部到着したと判断すればいいのか、という問題は別個ありますが。)
ですが、先ほどバッチ処理の処理モデルの図に出てきたように、ストリームデータ処理では下記のようなウィンドウという概念が求められることがあります。
例えば不正検知であれば一件のアクセスだけで不正だと検知可能なケースは限られ、「短い時間内に大量のログイン失敗があった」というような前後のデータとの関連性で不正が検知されるのが主となるためです。
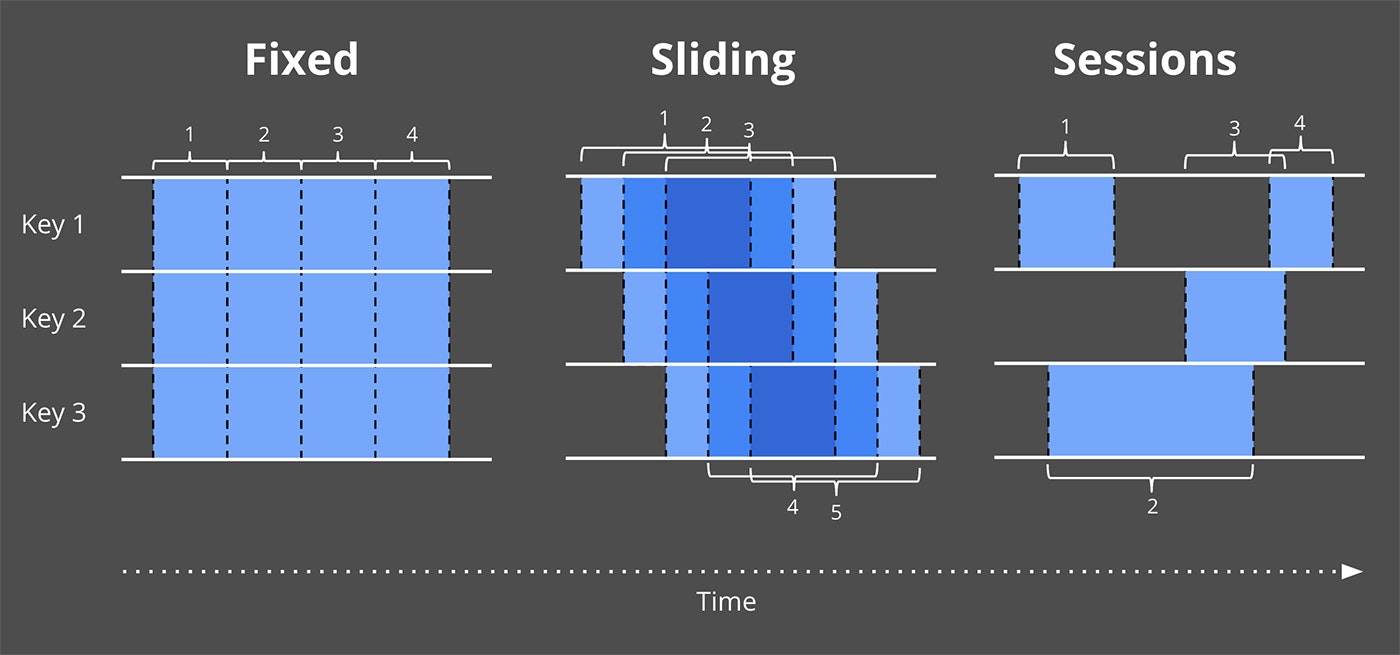
- 固定長ウィンドウ(Fixed)
- 1時間ごと、等の一定の時間ごとに区切った範囲のウィンドウ
- スライディングウィンドウ(Sliding)
- 毎分、過去5分間分の結果を集計して出力するといった範囲が移動するウィンドウ
- セッションウィンドウ(Sessions)
- 一定時間以内にアクセスが連続した場合にそのアクセスを紐づけるという長さが固定されないウィンドウ
ここで「データが発生した順にシステムに到着するわけではないこと」が大きな問題になってきます。
何故なら、「17:00~17:59の間に発生したデータに対する固定長ウィンドウの集計結果」を出力した後に「17:10に発生したデータ」が遅れて到着したらどうするのか、という問題が発生するためです。
それをどうやったら解消できるのか?
「データが発生した順にシステムに到着するわけではない」中で、ウィンドウの結果をどう出力するかについて、記事の中では下記の3つの対処を挙げています。
どのイベント時刻まで処理したかの区切り(Watermark)
Watermarkはイベント時刻ベースでどこまで処理が完了したかを示す概念になります。
イベント時刻と処理時刻が別に存在する場合、実際の処理時刻と、どこまでイベント時刻的に処理したかというのは下記の図のようにずれてきます。
そのため、Watermarkという概念が必要になります。
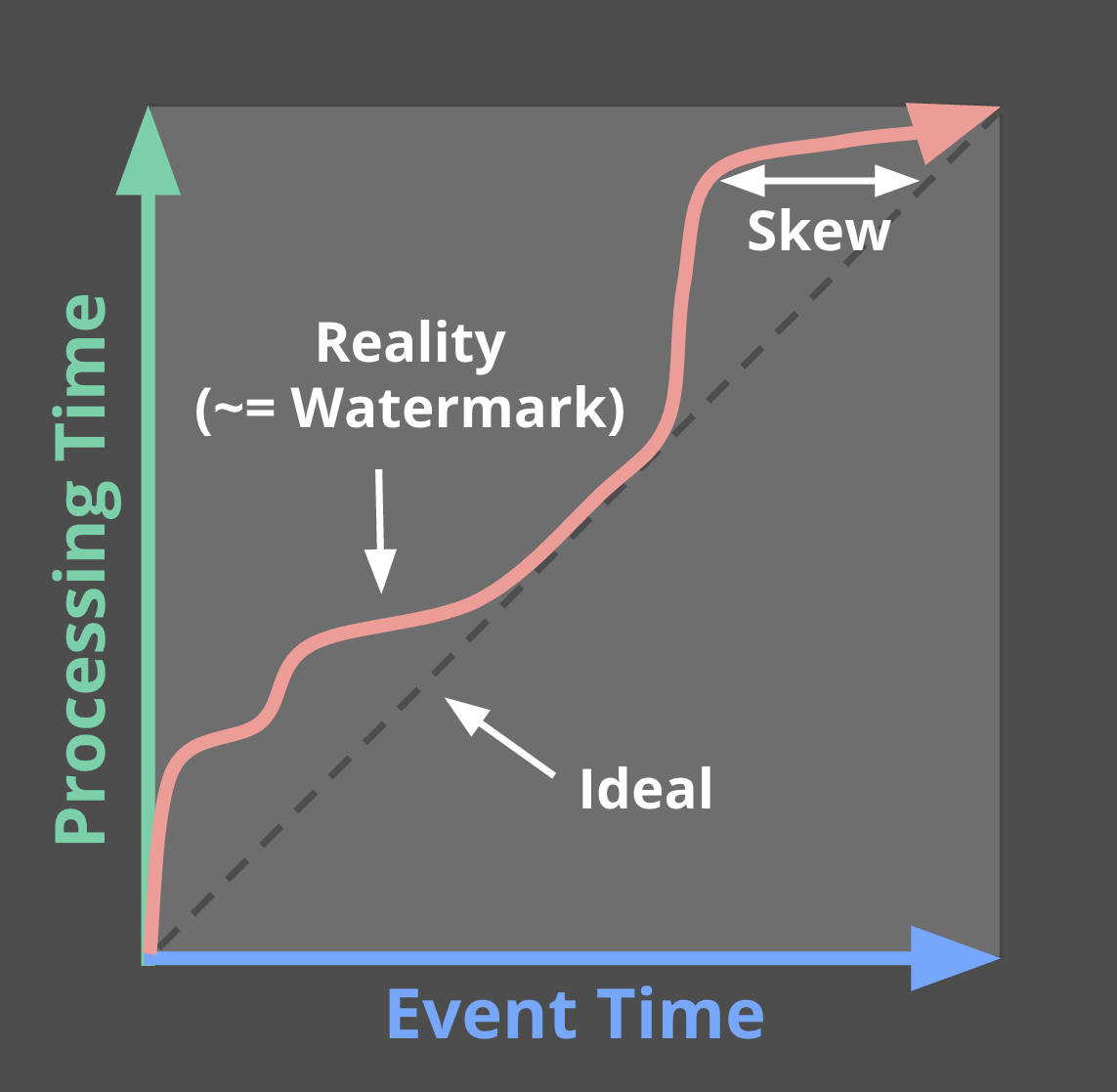
例として、WatermarkがXの値を取った場合、「イベント時刻がXより小さいデータは全て観測されている。」ことを示すわけですね。
つまりはWatermarkは無限のデータを観測している状態において、どこまで進んだかを示す"区切り"として動作します。
ただし、ここで注意しておくべきことは、Watermarkは決して完全なものにはなり得ないということです。
データが遅れて到着する以上、Watermarkは「多分このくらい遅れるだろう」という目算に過ぎないものとなってきます。
(※だったらそんなの必要ないだろという突込みがあるかもしれませんが、目算でもないと処理ができないという事情がありますので。)
集計結果をどのタイミングで出力するかを定義する機構(Trigger)
Triggerはウィンドウ集計結果をどのタイミングで出力するかを状況に応じて定義する機構になります。
Triggerを定義することによって、いつウィンドウ集計結果を出力するべきかについて実体化するべきかについて柔軟に定義が可能となります。
加えて、Trigger機構によってウィンドウ集計結果をデータが更新される毎に複数回出力するということも可能になってきます。
この機構によって、Watermarkが一定の場所に達したり、Watermarkより遅れたデータが到着した際に、その都度投機的な出力が行えるようになります。
例として、Watermarkが固定長ウィンドウの最後まで達した場合に集計結果を出力するという場合はClouddataflowでは下記のようなコードで記述が可能になっています。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) // 固定長ウィンドウを宣言
.triggering(AtWatermark())) // Watermarkが到着したタイミングで出力
.apply(Sum.integersPerKey());
加えて、遅れたデータが到着した場合に結果を再出力するような場合は下記のように記述が可能です。
PCollection<KV<String, Integer>> scores = input
.apply(Window.into(FixedWindows.of(Duration.standardMinutes(2))) // 固定長ウィンドウを宣言
.triggering(
AtWatermark()) // Watermarkが到着したタイミングで出力
.withLateFirings(AtCount(1)))) // 遅れデータが1件到着するごとに出力
.apply(Sum.integersPerKey());
集計結果出力時の累積計算方式(Accumulation)
Accumulationは同一ウィンドウ内で複数回集計結果が出力された場合の関係性や動作を定めるものです。
これは、集計結果の出力先システム、つまり、どう使用するかに依存してきます。
例えば出力先システムがそれまでの集計結果を足し合わせていくようなケースでは、1回ウィンドウで集計結果を出力したらその値は破棄し、次の出力は新たなデータの集計結果を出力すればOKです。
対して、出力先システムがユーザIDと時刻をキーにしたKey-Value Storeのようなデータ構造の場合は、1回ウィンドウで集計結果を出力した後もその値を保持しておき、次の出力は既存のデータと新たなデータをあわせた集計結果を出力する必要が出てきます。
上記のような集計結果出力時の切替の機構がAccumulationです。
全部に対応するのは無理なんじゃないの?
Watermark、Trigger、Accumulationの機構が導入されればストリームデータ処理は全て対応可能かというと、そんなことはありません。
何故なら、下記のような問題が発生してくるからです。
- Watermarkを実時刻からどれくらい遅らせて設定すればいいのか?
- 遅れを大きくすれば正確性は増しますが、遅延時間は大きくなります。
- Accumulationのためにウィンドウの集計結果をどれだけ保持すればいいのか?
- 保持する時間が長いほど、ストリームデータ処理を行うシステムのリソースが必要となります。
そのため、Googleはストリームデータ処理には下記の3要素のトレードオフがあるとしています。
- 完全性(Completeness)
- 低遅延(Low Latency)
- 低コスト(Low Cost)
この3要素を全てに満たすことは出来ず、全てのストリームデータ処理システムはこの3要素のバランスで構成されるというものです。
ここでのコストとは、ストリームデータ処理システムのリソースだけでなく、データを収集する経路などに対するコストも含まれると考えていいと思います。
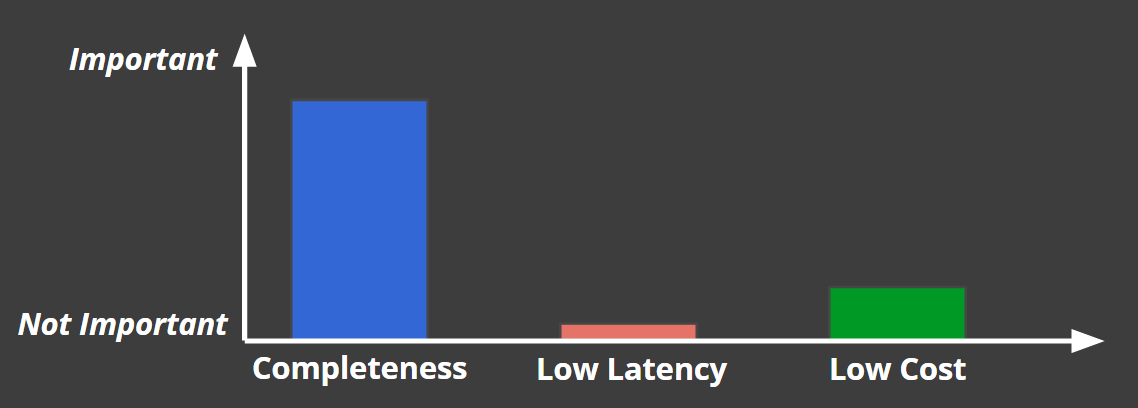
例えば、課金処理であれば、下記のように完全性重視で、遅延が多少発生したりコストがかかっても問題ないという判断になります。
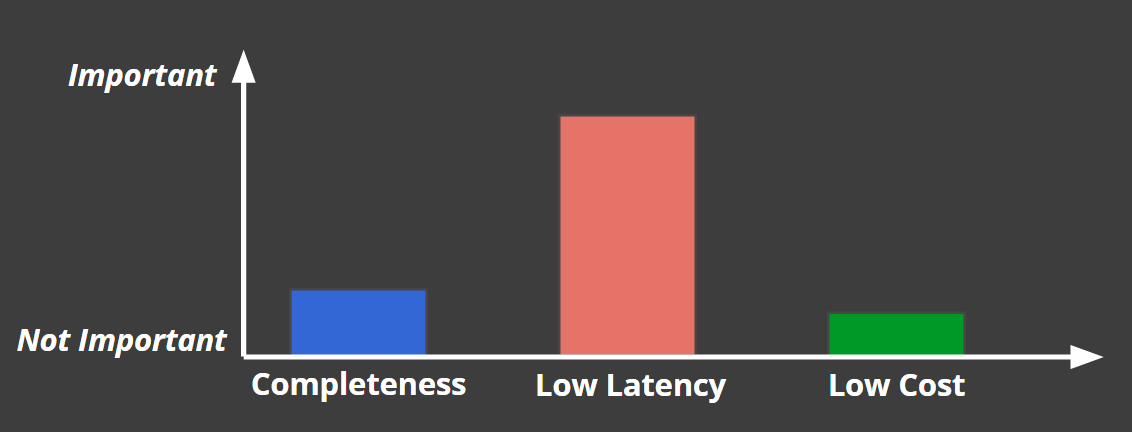
対して、不正検知システムでは低遅延が最優先で、その他の要素の優先度は下がります。
上記のような事情があるため、
実際に開発するシステムで何が求められるかを基に落としどころを見つける必要があるという形になってきます。
実際にどこで実行できるのか?
上記のストリームデータ処理システムは元々はGoogleのMillWheelを基にしたCloud Dataflowの上でのみ動かすことが可能でした。
ですが、今年の1月にCloud DataflowのAPIをベースとし、それを用いて書いたコードをCloud Dataflowだけでなく、複数の分散処理基盤上で動かすことを目指すApache Beamの提案がGoogleから行われ、現在はOSSとして開発がすすめられています。
初めはCloud Dataflowの他に、Apache Spark、Apache Flinkの上での実行が可能でしたが、その後実行可能な環境が追加され、現在は下記の環境で実行が可能になっています。
言ってしまうと、最近のJVM系ストリームデータ処理基盤上なら大体の環境で動作させることが可能です。
尚、これだけ見るとBeamが非常に万能に見えますが、当然デメリットもあります。
ですが、そこまで踏み込むと複雑になるので今回はここまでにとどめます。
ひとまずはCloud DataflowのAPIをベースとし、ストリームデータ処理(バッチ処理は機能的にストリームデータ処理に含まれるため、バッチ処理も)を様々な実行基盤上で動作させる機構が存在するとだけ見ればいいかと。
上記が現状の流れになるかと思います。
まとめ
いくつかの論文や記事を基に、Googleが提案するストリームデータ処理とは何かにまとめてみました。
バッチ処理とストリームデータ処理での違いや、そこから発生する新たな問題についてまとめました。
その上で、Googleはそれらを複数の基盤上で実行できるBeamというプロダクトを出してきていることを挙げました。
様々なプロダクトが登場し続ける分野ですが、今後も情報は追っていこうと思います。
それでは。