本記事はMLOps Advent Calendar 2020の18日目の記事です。
はじめに
機械学習モデルを含めたシステムを運用する際に、システムを取り巻く各種インフラを整えずにいるとやがて組織の負債になります。
以下の図はMLOpsに携わるエンジニアであればおよそ7000回は見たと思います。
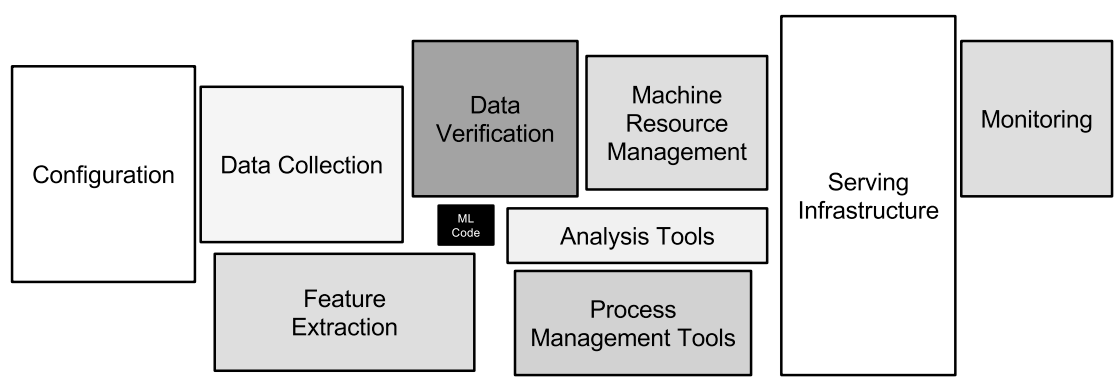
(参考文献[1]より)
最近ではこの図中のData Collection, Feature Extraction, Data Verificationの一部分を担うFeature Storeと呼ばれる特徴量管理のためのプラットフォームのマネージドサービスがクラウドベンダー各社からリリースされ始めています。
本記事ではFeature Storeを概説し、Feature StoreのOSSであるFeastを簡単に紹介します。
併せてこちらの記事もご覧ください。
Feature Store
その名の通り、MLモデルの特徴量を管理するためのものです。Feature Storeの概念自体は2017年にUberのブログ(Meet Michelangelo: Uber’s Machine Learning Platform)が初出とされています。
特徴量を管理とはなんぞや、ということでまずはFeature Storeのない世界を考えてみます。
Feature Storeのない世界
 (参考文献[2]より)
(参考文献[2]より)
様々なチームや環境でMLモデルを構築した際、上図のような状況が生まれることがままあります。
- StreamやTableなど様々なデータソースを参照
- データフォーマットが特徴量によって異なる
- モデルによって特徴量の作り方が異なる
- 学習時と推論時で参照する特徴量が異なる(データの一貫性がない)
この辺りを解決していこうというのがFeature Storeのモチベーションです。いずれも複数のMLモデルを運用している組織では直面したことのある問題ではないでしょうか?
Feature Storeのある世界
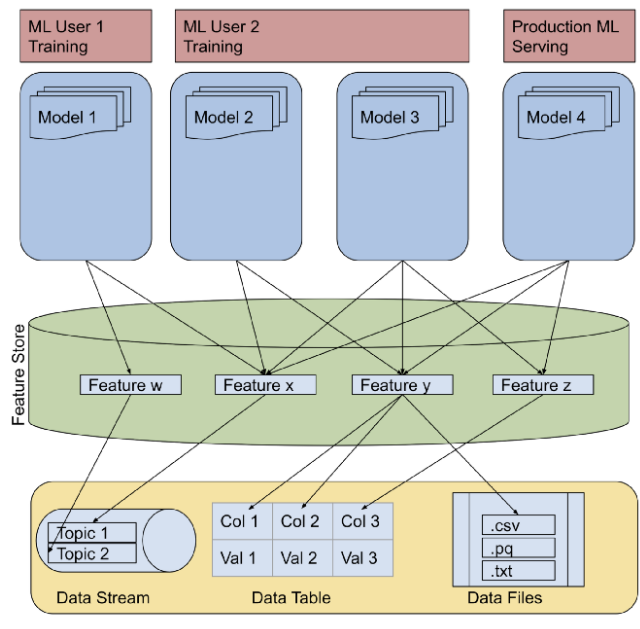 (参考文献[2]より)
(参考文献[2]より)
Feature Storeを導入することで先ほどの問題は以下のように解決されます。
- StreamやTableなど様々なデータソースを参照 → 様々なデータソースに対して共通IFで参照
- データフォーマットが特徴量によって異なる → 統一されたデータフォーマットで取得
- モデルによって特徴量の作り方が異なる → 一度作成した特徴量を再利用
- 学習時と推論時で参照する特徴量が異なる → 学習・推論で同じ特徴量を参照
要約すると「特徴量の一貫性を保証し、かつ再利用が可能なプラットフォーム」を提供するものがFeature Storeと言えるでしょう。
Feature Storeを提供するプロダクト
Feature Storeの概念は比較的新しいものですが、各社で自前のFeature Storeを構築し運用しているようです。
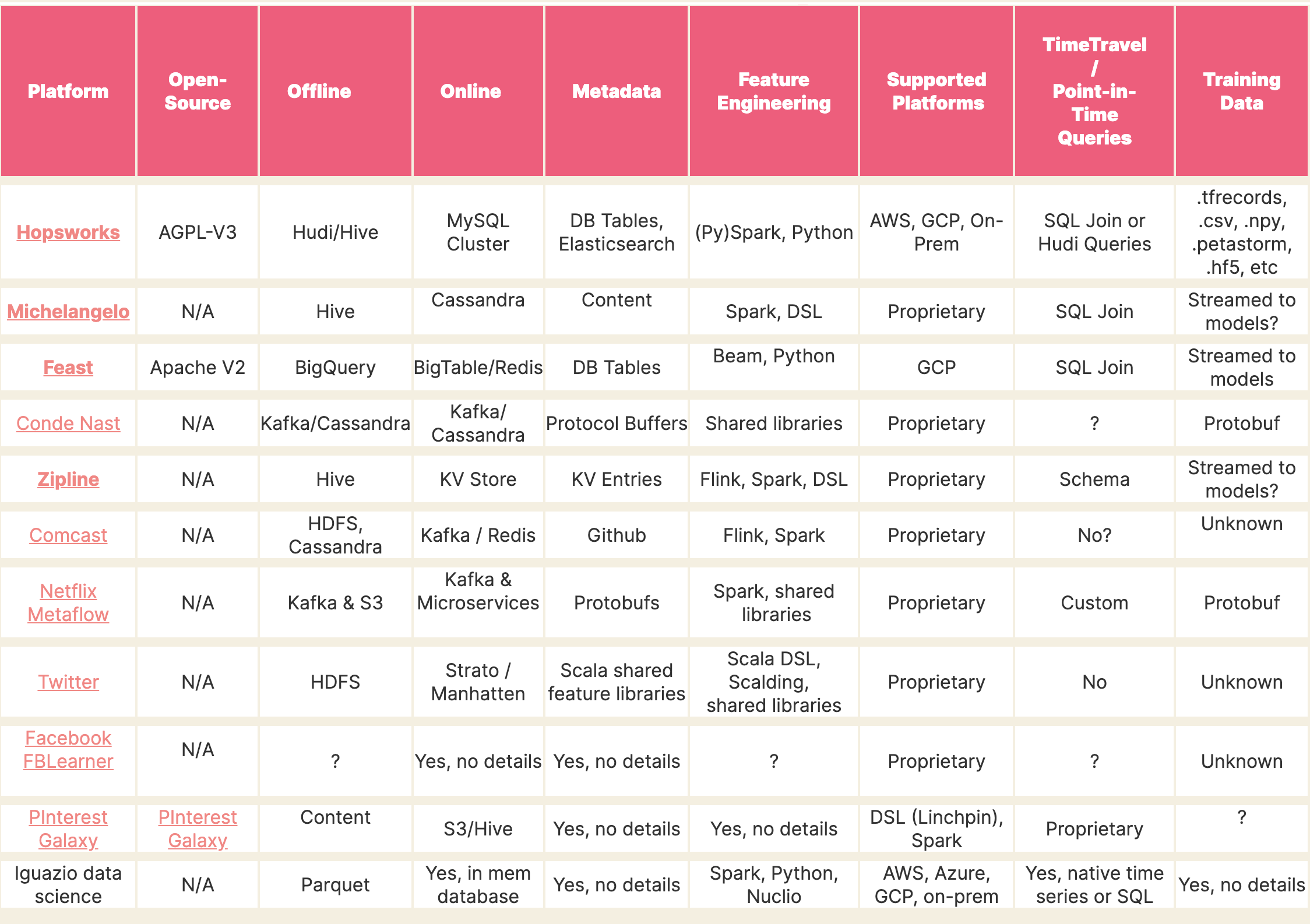
(参考文献[3]より)
最近ではAWS re:Inventにおいて、Feature StoreのマネージドサービスであるAmazon SageMaker Feature Storeが発表されました。
以下の記事では各種Feature Storeがまとめられているので、こちらも見てみることをお勧めします。
参考:機械学習向けのFeature StoreないしStorage Layer Software
Feast
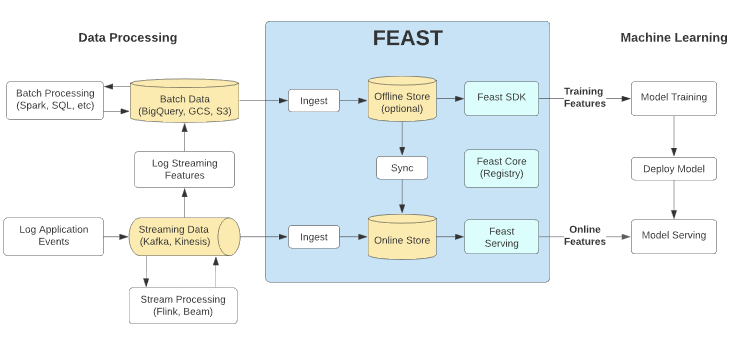
FeastはOSSとして公開されているFeature Storeで、インドネシア版UberであるGojekという会社とGoogle Cloudが共同で開発しています。
Google Cloud blogで「今年末までにAI PlatformにFeature Storeを導入する予定」と言及されていることからも、GCPで利用できるようになるマネージドFeature StoreはFeastをベースにするものと思われます。(今年はあと2週間で終わりますが…)
KubeflowでサポートするFeature StoreもFeastであることからも自然な流れですね。この記事の執筆時点(2020年12月)ではv0.8.2が最新版となっており、Kubeflowではαステータスのサポートとなっています。
以下ではFeastを試してみるための環境構築手順と使い方について見ていきます。
GitHub リポジトリ:https://github.com/feast-dev/feast
ドキュメント:https://docs.feast.dev
環境構築
ドキュメントには以下の環境でインストールする手順が記載されています。
- Kubernetes (with Helm)
- Amazon EKS (with Terraform)
ここでは手元のPCでさくっと試すためにKubernetesクラスタを立てるようなことはせず、ローカルで完結する手順を紹介します。
(Kubeflowから使うことを想定してKubeflowの実行環境を手元のMacbook Proに構築することを試みましたが、要求されるマシンリソースがノートPCで動かすレベルではないので断念)
基本的にはこちらの手順で進みます:https://github.com/feast-dev/feast#getting-started-with-docker-compose
実行環境
$ docker-compose version
docker-compose version 1.26.2, build eefe0d31
docker-py version: 4.2.2
CPython version: 3.7.7
OpenSSL version: OpenSSL 1.1.1g 21 Apr 2020
Docker立ち上げ
まずはリポジトリをcloneしてDocker立ち上げに必要なenvファイルをコピーします。
$ git clone https://github.com/feast-dev/feast.git
$ cd feast/infra/docker-compose
$ cp .env.sample .env
それではdocker-composeで立ち上げ…
$ docker-compose pull && docker-compose up -d
ようとすると、以下のエラーが。
ERROR: for jupyter failed to register layer: Error processing tar file(exit status 1): write /usr/share/texlive/texmf-dist/fonts/tfm/public/baskervaldx/Baskervaldx-Reg-lf-t1.tfm: no space left on device
ERROR: for jobservice failed to register layer: Error processing tar file(exit status 1): write /usr/share/texlive/texmf-dist/fonts/tfm/public/baskervaldx/Baskervaldx-Reg-lf-t1.tfm: no space left on device
ERROR: failed to register layer: Error processing tar file(exit status 1): write /usr/share/texlive/texmf-dist/fonts/tfm/public/baskervaldx/Baskervaldx-Reg-lf-t1.tfm: no space left on device
なぜtexlive配下に書き込もうとしているのかは謎ですが、要はDockerのゴミがたくさん残っていてメモリを逼迫していたことが原因だったため、一旦全てを無に帰すことに
# 容量の確認
$ docker system df
# 削除実行
$ docker system prune -a
上記のエラーでなくともコンテナの立ち上げに失敗した場合はコンテナ起動に使うための容量不足であることが多いので、エラーログをdocker-compose logsなどで確認してみることをお勧めします。
docker-compose.yml修正
無事コンテナが立ち上がると、http://localhost:8888 でjupyter notebookにアクセスできるようになります。
/minimal/minimal_ride_hailing.ipynbを開くと以下のようなノートブックが開かれます。
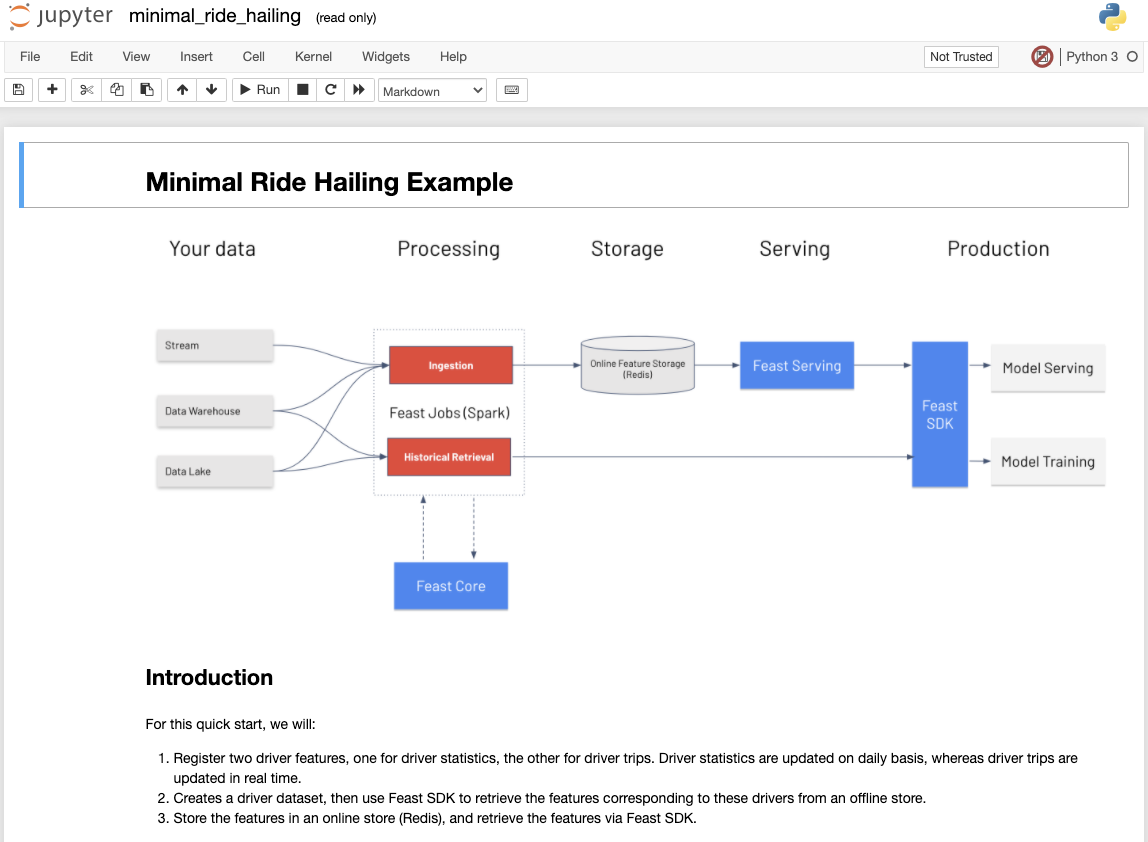
ノートブック名の隣にread-onlyとあるように、このノートブックはDockerイメージに含まれているため書き込んで保存することはできない状態なので、以下のようにマウントします。
# ノートブックがあるディレクトリをカレントにコピー
$ cp -r ../../examples/ ./
...
jupyter:
image: gcr.io/kf-feast/feast-jupyter:${FEAST_VERSION}
volumes:
- ${GCP_SERVICE_ACCOUNT}:/etc/gcloud/service-accounts/key.json
- $PWD:/home/jovyan/work # ここを/sharedから/home/jovyan/workに変更
depends_on:
- core
...
これで編集できるようになります。
実行
ここで実行するサンプルノートブックではタクシー配車サービスにおける特徴量の管理を想定しています。
具体的には以下の2つの特徴量を扱います。
- ドライバーの運行に関する統計情報(デイリー更新)
- ドライバーの運行状況(リアルタイム更新)
この2パターンの特徴量をFeastに登録し、利用するサンプルとなります。
Entityの登録
Entityは特徴量を管理する上でのプライマリキーになるものです。あるEntityに対して複数の特徴量が結びついているイメージです。
from feast import Client, Entity, ValueType
client = Client()
driver_id = Entity(name="driver_id", description="Driver identifier", value_type=ValueType.INT64)
Featureの登録
Feastで利用する特徴量を宣言します。以下では特徴量の名称と型のみを宣言しています。
from feast import Feature
# Daily updated features
acc_rate = Feature("acc_rate", ValueType.FLOAT)
conv_rate = Feature("conv_rate", ValueType.FLOAT)
avg_daily_trips = Feature("avg_daily_trips", ValueType.INT32)
# Real-time updated features
trips_today = Feature("trips_today", ValueType.INT32)
ここで宣言した特徴量をFeatureTableという単位でまとめて管理します。
FeatureTableはデータソースの場所や特徴量の付帯情報を定義するもので、データソースには**batch_sourceとstream_source**を指定することができます。
学習時にはbatch_sourceに指定したDWHを参照し、モデルサーブ時にはstream_sourceに指定したストリーミングデータソースを参照する、といったことができるようになっています。
stream_sourceはオプション設定なので、以下ではbatch_sourceのみを設定しています。
batch_sourceにはコンテナ内にあるParquet形式のファイルを指定しています。
import os
from feast import FeatureTable
from feast.data_source import FileSource
from feast.data_format import ParquetFormat
demo_data_location = os.path.join(os.getenv("FEAST_SPARK_STAGING_LOCATION", "file:///home/jovyan/"), "test_data")
# デイリー特徴量(を模したもの)
driver_statistics_source_uri = os.path.join(demo_data_location, "driver_statistics")
driver_statistics = FeatureTable(
name = "driver_statistics",
entities = ["driver_id"],
features = [
acc_rate,
conv_rate,
avg_daily_trips
],
batch_source=FileSource(
event_timestamp_column="datetime",
created_timestamp_column="created",
file_format=ParquetFormat(),
file_url=driver_statistics_source_uri,
date_partition_column="date"
)
# BigQueryからデータを取得する場合
# batch_source=BigQuerySource(
# table_ref="gcp_project:bq_dataset.bq_table",
# event_timestamp_column="datetime",
# created_timestamp_column="timestamp",
# field_mapping={
# "rating": "driver_rating"
# }
# )
)
# リアルタイム特徴量(を模したもの)
driver_trips_source_uri = os.path.join(demo_data_location, "driver_trips")
driver_trips = FeatureTable(
name = "driver_trips",
entities = ["driver_id"],
features = [
trips_today
],
batch_source=FileSource(
event_timestamp_column="datetime",
created_timestamp_column="created",
file_format=ParquetFormat(),
file_url=driver_trips_source_uri,
date_partition_column="date"
)
)
# EntityとFeatureTableをクライアントに登録
client.apply(driver_id)
client.apply(driver_statistics)
client.apply(driver_trips)
登録したEntityやFeatureTableは以下のようにyaml形式で出力して確認できます。
print(client.get_entity("driver_id").to_yaml())
"""
spec:
name: driver_id
valueType: INT64
description: Driver identifier
meta:
createdTimestamp: '2020-12-18T06:32:16Z'
lastUpdatedTimestamp: '2020-12-18T06:32:16Z'
"""
Featureの注入
先ほど登録したFeatureTableには参照先の情報しか入っていないので、具体的なデータを注入しておきます。
ここではEntityとそれに紐づくデイリー特徴量・リアルタイム特徴量を適当な乱数で生成します。
import pandas as pd
import numpy as np
from datetime import datetime
# Entity生成用
def generate_entities():
return np.random.choice(999999, size=100, replace=False)
# デイリー特徴量生成用
def generate_stats(entities):
df = pd.DataFrame(columns=["driver_id", "conv_rate", "acc_rate", "avg_daily_trips", "datetime", "created"])
df['driver_id'] = entities
df['conv_rate'] = np.random.random(size=100).astype(np.float32)
df['acc_rate'] = np.random.random(size=100).astype(np.float32)
df['avg_daily_trips'] = np.random.randint(0, 1000, size=100).astype(np.int32)
df['datetime'] = pd.to_datetime(
np.random.randint(
datetime(2020, 10, 10).timestamp(),
datetime(2020, 10, 20).timestamp(),
size=100),
unit="s"
)
df['created'] = pd.to_datetime(datetime.now())
return df
# リアルタイム特徴量生成用
def generate_trips(entities):
df = pd.DataFrame(columns=["driver_id", "trips_today", "datetime", "created"])
df['driver_id'] = entities
df['trips_today'] = np.random.randint(0, 1000, size=100).astype(np.int32)
df['datetime'] = pd.to_datetime(
np.random.randint(
datetime(2020, 10, 10).timestamp(),
datetime(2020, 10, 20).timestamp(),
size=100),
unit="s"
)
df['created'] = pd.to_datetime(datetime.now())
return df
entities = generate_entities()
stats_df = generate_stats(entities)
trips_df = generate_trips(entities)
print(trips_df.head())
"""
driver_id trips_today datetime created
0 272479 108 2020-10-12 20:03:13 2020-12-18 07:04:37.705060
1 284304 679 2020-10-13 12:03:42 2020-12-18 07:04:37.705060
2 276825 62 2020-10-19 15:43:17 2020-12-18 07:04:37.705060
3 770498 514 2020-10-15 14:02:06 2020-12-18 07:04:37.705060
4 730710 761 2020-10-10 15:21:53 2020-12-18 07:04:37.705060
"""
以下で生成した適当な特徴量をクライアント経由で注入します。
client.ingest(driver_statistics, stats_df)
client.ingest(driver_trips, trips_df)
"""
Removing temporary file(s)...
Data has been successfully ingested into FeatureTable batch source.
Removing temporary file(s)...
Data has been successfully ingested into FeatureTable batch source.
"""
実行後、マウントしたディレクトリにstagingというディレクトリが生成され、ここに上で作った適当な特徴量のファイルが作られます。
lsコマンドでファイルの実体を確認すると、この特徴量が日ごとに管理されていることがわかります。
$ ls ./staging/test_data/driver_statistics/
date=2020-10-10 date=2020-10-13 date=2020-10-16 date=2020-10-19
date=2020-10-11 date=2020-10-14 date=2020-10-17
date=2020-10-12 date=2020-10-15 date=2020-10-18
まだ試してはいないのですが、このデータソースにBigQueryを指定した場合client.ingestだけでBigQueryのテーブルの値が書き換わってしまうのだろうか…と思っています。
Featureの取得
Feastに登録されている特徴量を取得するにあたり、リアルタイムで更新されている特徴量について「どのタイミングの値を使うか」を意識する必要があります。
また、バッチで更新される特徴量については「データの鮮度が保証されているか」も考慮する必要のあるケースがあると思います。
Feastでは以下の条件で特徴量を取得します。
1. エンティティの主キーが一致する
2. 取得時に指定したタイムスタンプよりも前のタイムスタンプを持つもので、かつmax_ageが設定範囲内
3. 上記1,2が満たされている場合、取得時に指定したタイムスタンプに最も近いデータ
4. 上記の条件を満たさない場合、nullが入る
条件2のmax_ageはデータの鮮度を表すもので、例えばmax_age="30d"のように指定していた場合、30日間更新されていない特徴量にはnullが渡されることになります。
以下では適当なdriver_idとタイムスタンプを指定してFeatureを取得してみます。
# entitiesは「Featureの注入」セクションで作ったもの
sampled_entities = np.random.choice(entities, 10, replace=False)
# 適当なtimestampの付与
entities_with_timestamp = pd.DataFrame(columns=['driver_id', 'event_timestamp'])
entities_with_timestamp['driver_id'] = sampled_entities
entities_with_timestamp['event_timestamp'] = pd.to_datetime(np.random.randint(
datetime(2020, 10, 18).timestamp(),
datetime(2020, 10, 20).timestamp(),
size=10), unit='s')
entities_with_timestamp.head()
"""
driver_id event_timestamp
0 3990 2020-10-18 19:43:44
1 824802 2020-10-18 17:24:26
2 841948 2020-10-18 15:14:54
3 15337 2020-10-19 12:27:27
4 557987 2020-10-18 09:01:52
"""
Sparkで特徴量を取得します。feature_refsという引数に"{FeatureTable名}:{Feature名}"というフォーマットで取得する特徴量を指定します。
job = client.get_historical_features(
# 取得するEntityの指定
entity_source=entities_with_timestamp,
# 取得するFeatureの指定
feature_refs=[
"driver_statistics:avg_daily_trips",
"driver_statistics:conv_rate",
"driver_statistics:acc_rate",
"driver_trips:trips_today"
]
)
# ジョブが完了するとCOMPLETEDと表示される
job.get_status()
# ジョブの完了まで実行結果の取得はブロックされる
output_file_uri = job.get_output_file_uri()
print(output_file_uri)
"""
'file:///home/jovyan/work/historical_feature_output/a3a260a2-1f10-4142-b198-fde1571893d9'
"""
最後に出力したパスに取得結果が保存されているので、取得結果を見てみます。
from urllib.parse import urlparse
ret_df = pd.read_parquet(urlparse(output_file_uri).path)
ret_df.head()

NaNとなっている箇所がいくつかありますが、これは特徴量取得時に指定したタイムスタンプがFeastに保存されているタイムスタンプよりも古い時間を指定したことにより、nullが返されていることを表しています。
まとめ
この記事ではFeature Storeの一つであるFeastを試してみるための環境構築手順と特徴量の登録・取得方法を紹介しました。
Feastへの特徴量の登録は大まかに以下の手順で行いました。
- Entityの定義・登録
- FeatureTableの定義・登録
- (Featureの注入)
あらかじめ用意されているDWHをデータソースとして指定する場合はFeatureの注入は不要ですね。
今回はBigQueryのような静的なデータソースから特徴量を登録・取得する例を紹介しましたが、Cloud Pub/Subのようなストリーミングデータから特徴量を登録・取得する例も別途紹介できればと思います。
(MLOps Advent Calendar 2020の20日目の記事ではFeastとTensorflow Data Validation (TFDV)の組み合わせについて紹介されるようなので、そちらもご覧いただくといいかもしれません)
参考文献
[1] Hidden Technical Debt in Machine Learning Systems (Sculley et al. 2015)
[2] ML Feature Stores: A Casual Tour 1/3
[3] Feature Store for ML