1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。
前回投稿させていただいた【機械学習】決定木をscikit-learnと数学の両方から理解するでは決定木の詳細について記載しましたが、今回は、より実務やkaggle等のコンペでも使われるランダムフォレストについてまとめていきます。
いつものような数学の話は今回はあまり出てきませんが、何となく「決定木を組み合わせたのがランダムフォレスト」くらいの理解しかできていなかったので、自分自身でも整理し、「ランダムフォレストとは何なのか」「パラメータチューニングは何を行っていけばいいのか」ということを、背景を押さえながら理解できるようにすることが今回の目的です。
また、今回はオライリーのPythonではじめる機械学習を参考にさせていただきました。
※「数学から理解する」シリーズとして、いくつか記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】決定木をscikit-learnと数学の両方から理解する
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
[【機械学習】線形重回帰をscikit-learnと数学の両方から理解する]
(https://qiita.com/Hawaii/items/b84a0d669bcf5267e750)
[【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する]
(https://qiita.com/Hawaii/items/ee2a0687ca451fe213be)
[【機械学習】SVMをscikit-learnと数学の両方から理解する]
(https://qiita.com/Hawaii/items/4688a50cffb2140f297d)
[【機械学習】相関係数はなぜ-1から1の範囲を取るのか、数学から理解する]
(https://qiita.com/Hawaii/items/3f4e91cf9b86676c202f)
※その他技術的な内容やデータサイエンスについてもブログを書いていますので、
よろしければこちらもご覧下さい。
[データサイエンス はじめの一歩]
(https://hazimenoippo-hawaii.com/)
2.アンサンブル学習とランダムフォレスト
ランダムフォレストを理解するために、アンサンブル学習について触れていきます。
(1)アンサンブル学習とは
アンサンブル学習とは、複数の機械学習モデルを組み合わせることで、より強力なモデルを構築するやり方です。
機械学習のモデルには「ロジスティック回帰」「SVM」「決定木」等たくさんありますが、これらはそれぞれ単独でデータに対して予測を行います。
ただ、世間一般的にも、誰か1人の独断で答えを出すよりも、何人か集まって答えを導き出す、ある種の多数決がより良い結果を生むこともたくさんあると思います。
アンサンブル学習とはまさにこの考え方で、複数の機械学習モデルの判断結果から多数決で、最終的に判断を下す学習の仕方です。イメージは下記です。

(2)アンサンブル学習の種類
アンサンブル学習のやり方には主に2種類あり、「バギング」と「ブースティング」です。
ランダムフォレストはこの「バギング」をベースに予測を行います。
◆バギングとは
ブートストラップというやり方を用いて複数のモデルを並列的に学習させていく方法です。
→新しいデータが入ってきた場合、分類であれば多数決、回帰であれば平均で予測を行います。
<ブートストラップとは>
元データから一部のデータを復元抽出というやり方でサンプリングするやり方。
復元抽出は、1度取ったデータもまた元データに戻してサンプリングするため、同じデータが何回も選ばれるケースがあります。
◆ブースティングとは
複数のモデルを用意して、学習を直列に進めていくやり方。前で作ったモデルの結果を参考にしながら、次のモデルを構築していきます。
ブースティングを元にしているモデルにはアダブーストがあります(今回は触れません)。
(3)ランダムフォレストとは
ランダムフォレストとは、アンサンブル学習のバギングをベースに、少しずつ異なる決定木をたくさん集めたものです。
決定木単体では過学習しやすいという欠点があり、ランダムフォレストはこの問題に対応する方法の1つです。
バギングでも触れましたが元のデータからランダムに何グループかサンプリングしているため、各決定木はそれぞれのデータを過学習している状態で構築されます。
それぞれ異なった方向に過学習している決定木をたくさん作れば、その結果の平均を取ることで過学習の度合いを減らすことができる、という考え方です。
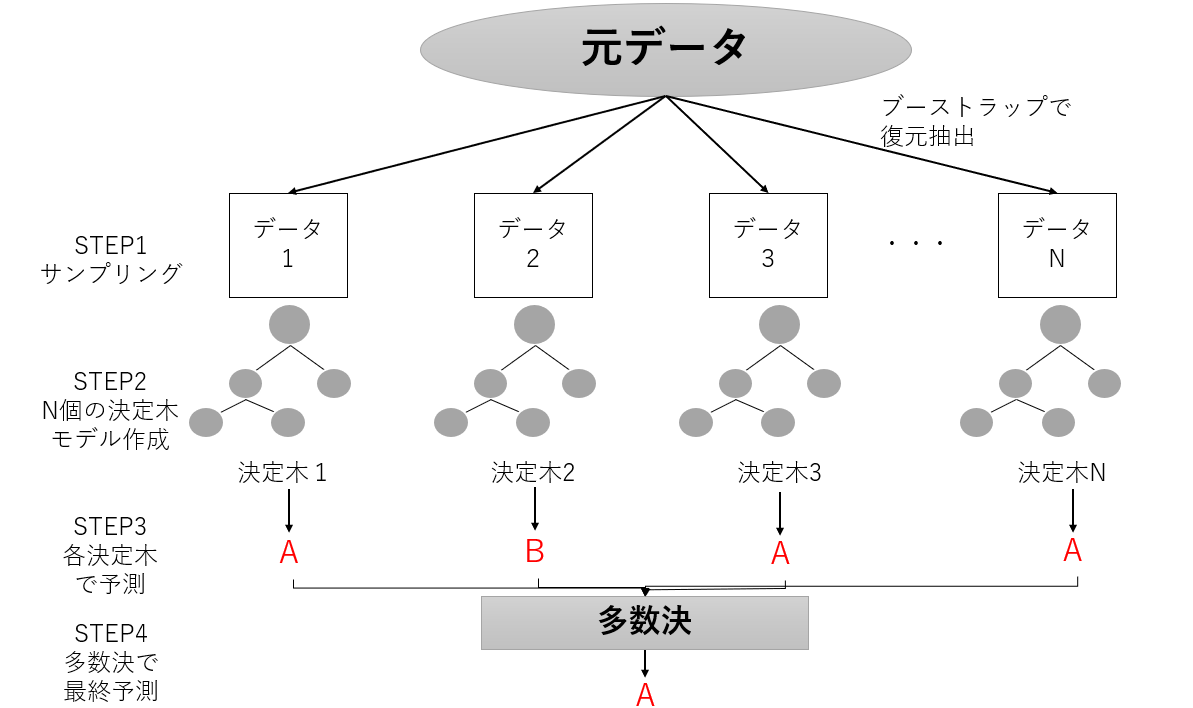
この考え方を図示してみます。
STEP1:元データからランダムにデータをブートストラップでサンプリングし、Nグループ分データグループを作ります
STEP2:Nグループそれぞれで決定木モデルを作成します。
STEP3:Nグループそれぞれの決定木モデルで予測を一旦行います。
STEP4:Nグループの多数決(回帰は平均)を取り、最終予測を行います。
(4)ランダムフォレストをscikit-learnで実装する場合のパラメータ
具体的なscikit-learnでの実装は次から行いますが、各パラメータをどのように設定していくのかを先に説明しておきます。
但し前提として、ランダムフォレストはそれほどパラメータチューニングを行わなくてもそれなりに良い精度が出せることで知られています(データの標準化といったスケールを変換する必要もありません)。
ですので今回は紹介にとどめ、次の実装ではデフォルト設定でモデル構築を行います。
ここでは、冒頭に紹介したPythonではじめる機械学習の87ページで「調整すべき重要なパラメータ」と触れられているn_estimators,max_featuresを紹介します。
◆n_estimators
いくつの決定木を用意するかを設定します。図示した「N個のデータ」のNをいくつにするかということです。
これは大きければ大きい方が良いです(たくさんの人から多数決を取れるというイメージ)が、増やしすぎると時間もメモリも食うので、このあたりとのバランスになるかと思います。
◆max_features
ここで初めて記載するのですが、STEP1のデータのサンプリングの際に、実はもう1つ行われていることがあります。それは「特徴量の選択」です。すべての特徴量がモデル構築に使われるわけではなく、各グループでの決定木構築の際に特徴量もランダムに振り分けられます。
この各グループの特徴量の個数をmax_featuresで設定します。
※max_featuresを「n_features」とすると全特徴量を選択することになります。
max_featuresを大きくすると、各決定木モデルは似たようなモデルになるはずで、逆に小さくすると各決定木モデルは大幅に異なるものができあがりますが、小さすぎるとデータにfitしない決定木ができてしまいます。
max_featuresは一般には、デフォルト値を使うと良いと”pythonではじめる機械学習”で述べられています。
3.scikit-learnでランダムフォレストを実装
それではここから、実際にscikit-learnでランダムフォレストを実装してみましょう。
(1)データセット
kaggleのKickstarter Projectsのデータセットを用います。
https://www.kaggle.com/kemical/kickstarter-projects
(2)必要なもののインポート、データ読み込み
(ⅰ)インポート
import pandas as pd#pandasのインポート
import datetime#元データの日付処理のためにインポート
from sklearn.model_selection import train_test_split#データ分割用
from sklearn.ensemble import RandomForestClassifier#ランダムフォレスト
(ⅱ)データ読み込み
df = pd.read_csv(r"C:~~\ks-projects-201801.csv")
(ⅲ)データ外観
下記より、(378661, 15)のデータセットであることが分かります。
df.shape
また、.headでデータをざっと確認しておきましょう。
df.head()
(3)データ成形
(ⅰ)募集日数
今回はあくまでランダムフォレストに主軸を置くので詳細は割愛しますが、クラウドファンディングの募集開始時期と終了時期がデータの中にありますので、これを「募集日数」に変換します。
df['deadline'] = pd.to_datetime(df["deadline"])
df["launched"] = pd.to_datetime(df["launched"])
df["days"] = (df["deadline"] - df["launched"]).dt.days
(ⅱ)目的変数について
こちらも詳細は割愛しますが、目的変数である「state」が成功("successful")と失敗("failed")以外にもカテゴリがありますが、今回は成功と失敗のみのデータにします。
df = df[(df["state"] == "successful") | (df["state"] == "failed")]
この上で、成功を1、失敗を0に置き換えます。
df["state"] = df["state"].replace("failed",0)
df["state"] = df["state"].replace("successful",1)
(ⅲ)不要な行の削除
モデル構築の前に、不要だと思われるidやname(これは本来は残しておくべきかもしれないですが今回は消します)、そしてクラウドファンディングをしてからでないとわからない変数を削除します。
df = df.drop(["ID","name","deadline","launched","backers","pledged","usd pledged","usd_pledged_real","usd_goal_real"], axis=1)
(ⅳ)カテゴリ変数処理
pd.get_dummiesでカテゴリ変数処理を行います。
df = pd.get_dummies(df,drop_first = True)
(4)いよいよ本題~データ分割と、ランダムフォレスト~
(ⅰ)データ分割
訓練データとテストデータにまずは分割します。
train_data = df.drop("state", axis=1)
y = df["state"].values
X = train_data.values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1234)
(ⅱ)ランダムフォレスト
clf = RandomForestClassifier(random_state=1234)
clf.fit(X_train, y_train)
print("score=", clf.score(X_test, y_test))
上記を実行すると、精度が約0.638になると思います。
基本的なモデルであれば、これで終了です!
4.結び
以上、いかがでしたでしょうか。
私の思いとして、「最初からものすごい複雑なコードなんて見せられても自分で解釈できないから、精度は一旦どうでもいいのでまずはscikit-learn等で基本的な一連の流れを実装してみる」ことは非常に重要だと思っています。
ただ、慣れてきたらそれらを裏ではどのように動かしているのか、背景から理解していくことも非常に重要だと感じています。
もっと学習を進めていったら、このランダムフォレストもより深い内容に更新していきたいと思います。
とっつきづらい内容も多いと思いますが、少しでも理解の深化の助けとなりましたら幸いです。