1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。
今回は、前処理でよく使われる「相関係数」について投稿していきたいと思います。
相関係数は-1から1の間を取ることは知っている人は多いと思いますが、「なぜ-1から1の間を取るのか」、説明できますでしょうか。
※私は最近までできませんでした。
この記事では、2で相関係数について簡単に紹介し、3で「理論はいいからまずはpythonで相関係数を可視化してみる」こと、4以降で「その背景を数学から理解する」2つを目的としています。
※私は文系私立出身なので、数学に長けていません。可能な範囲で数学が苦手な方にもわかりやすいように説明するよう心がけました。
※線形単回帰、ロジスティック回帰、SVMでも同様の記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
[【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する]
(https://qiita.com/Hawaii/items/ee2a0687ca451fe213be)
[【機械学習】SVMをscikit-learnと数学の両方から理解する]
(https://qiita.com/Hawaii/items/4688a50cffb2140f297d)
2.相関係数とは
相関係数とは2つの確率変数の間にある線形な関係の強弱を測る指標であり、−1以上1以下の実数に値をとります。
出典:[Wikipedia]
(https://ja.wikipedia.org/wiki/%E7%9B%B8%E9%96%A2%E4%BF%82%E6%95%B0)
ざっくり言いますと、「相関係数が正のときは、ある説明変数の値が大きくなれば、もう1つの説明変数も大きくなり、負の場合は、ある説明変数の値が小さくなれば、もう1つの説明変数は小さくなる」ということです。
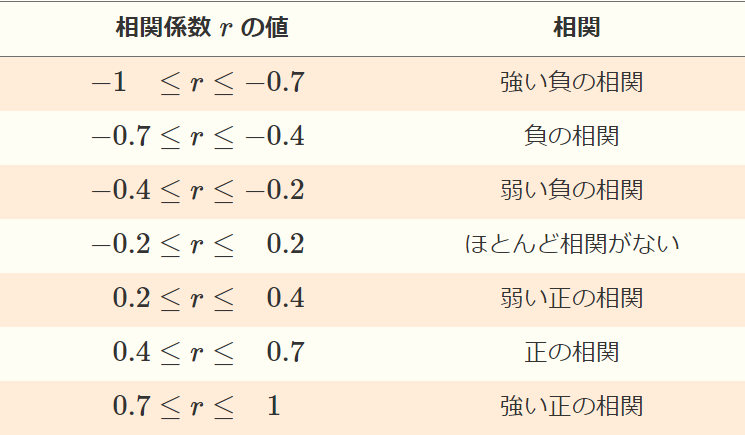
◆相関係数と相関の目安
あくまで目安ですが、一般的には下記のような目安が設定されています。
[出典]
(https://sci-pursuit.com/math/statistics/correlation-coefficient.html)
◆注意点
混乱しやすいですが、相関が弱いからといって、「2つの変数間は全く関係がない」というわけではないので注意してください。
先ほど、相関係数の定義に記載していますが相関係数はあくまで2つの変数間にある線形な関係の強弱を測る指標なので、線形以外の関係があった場合は相関係数では判別することができません。
具体例を見ていきましょう。下記の2つの変数は、明らかに二次曲線の様な関係がありそうですね。但し、この2つの変数の相関係数は-0.447のため、相関係数だけ機械的に数値で出すと比較的弱い相関と考えられ、本当は2つの変数間には関係がありそうなのに、見落としてしまう可能性があります。

このように、**「相関係数はあくまで線形の関係を測る指標であること」「本当の関係を見落とさないためには、変数間を可能な範囲で可視化すること」**が重要になります。
◆相関係数の使われどころ
機械学習において、相関係数は主に前処理で使われます。もう少し具体的には、目的変数に対してどの説明変数を使用していくかの検討(=特徴量選択)に使われます。
その中でも、使用シーンは主に2つです。
(1)目的変数と相関が高い項目を選び、説明変数に選ぶ
当然ですが、モデルを構築する際は目的変数に関係がある説明変数を選んでいく必要があります。(全く関係ない変数をモデルに入れても、精度が落ちる要因になります)
この、「関係がある」の1つの指標として相関係数を用います。
相関係数を出し、相関が強いと判断される変数を説明変数として選択します。
(2)説明変数どうしで相関が高い変数がある場合、片方を削除する
これは具体例を出したほうが分かりやすいと思います。架空の設定ですが、靴磨きの専門性を有するスタッフの技術力を測定するモデルを構築するとします。技術力を目的変数とし、説明変数の候補はたくさんありますが、その中の2つに**「勤続年数」と「スタッフID」**があったとします。
※かつ、「スタッフID」はスタッフになった順番に番号が加算されていくとします(例えば1人目は001、100人目は100という具合です)。

なんとなく予想がつくと思いますが、勤続年数が長い人ほど昔からいるのでスタッフIDは小さく、勤続年数が短い人ほど最近入ったのでスタッフIDが大きいという、強い負の相関が確実に出ます。
こういった際に、スタッフIDと勤続年数両方入れても計算コストもかかりますし、モデル構築に余計な影響が出る可能性があるので、どちらかを説明変数から削除します。
※私であれば、勤続年数の方が直感的に分かりやすいので、スタッフIDを削除します。
3.pythonで相関係数を出してみる
(1)必要なライブラリのインポート
相関係数を出すために必要な下記をインポートしておく。
import seaborn as sns
(2)データの準備
アヤメのデータを利用します。
df = sns.load_dataset("iris")
(3)相関係数の表示
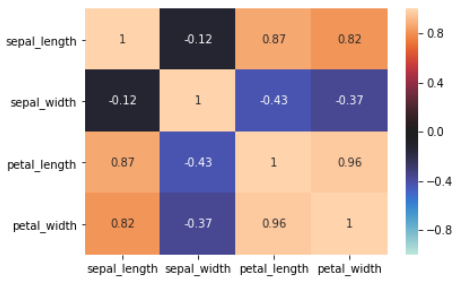
下記のように、ヒートマップとして出すことができます。
sns.heatmap(df.corr(), vmax=1, vmin=-1, center=0,annot=True)
相関係数自体はdf.corr()で算出し、それをヒートマップにします。こうすることで、数値を1つ1つ見ていくのではなく、直感的に相関の強い・弱いを確認することができます。
4.相関係数はなぜ-1から1の値を取るのか、数学から理解する
さて、いよいよ本題です。
今まで相関係数について私も疑問なく「-1から1の値を取るのだ」と思っていましたが、なぜ-1から1の値を取るのでしょうか。
結論から言いますと、相関係数は偏差ベクトルのなす角$θ$のcos$θ$と等しいからです。
この説明をしていきたいと思います。
(1)事前知識
◆cosθについて
ベクトルの内積について、下記が成り立つ。
※ここが難しく感じる方は、「そういうものなのだ」と思っていただければ大丈夫です。
x ・ y = ||x||||y||cosθ
※また、$cosθ$は-1から1の範囲を取る。
(2)相関係数の式
相関係数は、下記のように定義されます。
※$x$と$y$の共分散をそれぞれの標準偏差で割った形です。
イメージとしては、共分散は2つのデータの相関関係を数値で表したものですが、その値が大きいのか小さいのかよくわからないので、標準偏差で割って正規化する(=単位をそろえる)というイメージです。
r_{xy} := \frac{σ_{xy}}{σ_xσ_y}
(3)ベクトルの内積
(1)事前知識より、下記のように変換ができます。
x ・ y = ||x||||y||cosθ\\
\begin{align}
cosθ &= \frac{x y}{||x||||y||}\\
&= \frac{\frac{x ・ y}{N}}{\frac{||x||}{\sqrt{N}}\frac{||y||}{\sqrt{N}}}(※分母と分子をデータ数Nで割っている)
\end{align}
この式は、下記のように、$x$と$y$の共分散をそれぞれの標準偏差で割っていることを指す。
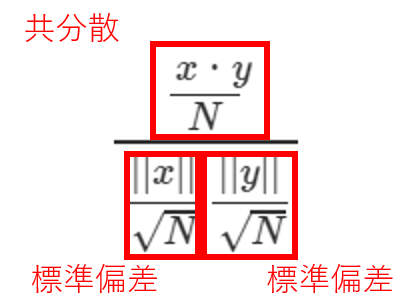
これにより、(2)に記載している通り標準偏差と同じ定義に変換できました。
つまり、$x$と$y$の相関係数は、$x$と$y$のなす角$θ$の$cosθ$と等しいといえることが分かります。
→かつ、事前知識にも載せた通り$cosθ$は-1から1の範囲を取るため、相関係数も-1から1の範囲を取るといえるのです。
(4)まとめ
ここまで記載したとおり、相関係数の定義はその2つの変数のなす角$cosθ$と同じになり、かつ$cosθ$は-1から1の範囲を取るため、相関係数も-1から1の範囲を取るのです。
5.まとめ
以上、いかがでしたでしょうか。
私の思いとして、「最初からものすごい複雑な説明をされても理解できず先に進めないので、理論は一旦どうでもいいからまずは機械学習のモデル構築をしてみる(そのために相関係数を出してみる)」ことは非常に重要だと思っています。
ただ、慣れてきたらその相関係数は本当はどのような意味を持っているのか、数学的な背景から理解していくことも非常に重要だと感じています。
少しでも理解の深化の助けとなりましたら幸いです。