はじめに
Firebase Realtime DBを実践投入するにあたって考えたことを読んで頂いてありがとうございます。 多くの方から「いいね」を頂いて、今回のこの記事を書くモチベーションになりました![]()
本当にありがとうございました!
さて、CloudFirestoreは、Firebase Realtime Databaseとは全く違うデータベースです。特にSubCollectionやQueryが導入されたことにより、リレーションシップの設計に関して大きく異なります。
この記事では、主にCloudFirestoreにおけるリレーションシップの設計方法から、アプリ・CloudFunctionsに至るまでを幅広く解説して行こうと思います。
次の記事ではデータベースの歴史を解説しています。
RDBの限界とNoSQLの登場
Cloud Firestoreでの開発について
私の経験上確実に断言できることがあります。
Cloud Firestoreだけでサービスを作ることは不可能ではない
でもしんどい。
開発には、他のSaaSを活用にするのがいいと思います。マイクロサービスをつくる観点から考えても機能を分離しておくことは大きなメリットがあります。
もし今から新規サービスを作ろうとして技術選定に困っている方にアドバイスするならば、私はCloud Firestoreを強くお勧めします。簡単に理由を並べると以下の点です。
- 既存のDBと比較して、今からNoSQLを始める学習コストを考慮しても開発速度が早い
- スケールするまでは無料で使える
- グロースさせるまでをFirebaseで完結できる
正直、ネイティブアプリからREST APIを使ってデータを取り扱うメリットはほぼ無いと考えています。完全私の予想ですが、次のような流れになるはずです。
- 通信プロトコルはgRPCが主流になる
- RESTはGraphQLに置き換わる
- RESTは外部サービスとの連携のために残る
完全に個人的な予想なのであまり期待しない方がいいかも知れませんが、僕はそう信じてこの記事を書きます。
Cloud Firestoreの構造
Cloud Firestore は、NoSQLデータベースです。さらに特徴的なのはデータ構造です。
図のようにPCのファイルシステムのような構造を持つことができます。

このあたりの説明は丁寧にドキュメントで説明されているのでこちらをご覧ください。
一般的なRDBでもなく、MongoDBのような構造でもなく、CloudFirestoreは独特の構造を持ちますので、雰囲気だけでも構造を理解してこの後を読み進めることをお勧めします。
CloudFirestoreのリレーションシップについて
さて、Cloud Firestoreでサービス開発において重要なのはCloudFirestoreのデータ構造をどう設計していくかです。もちろん__リレーションシップ__の設計が重要な鍵となります。Realtime Databaseでは、リレーションシップの方法はそう多くなく、__Fan out__によるリレーションシップを構築していく程度でしたが、Cloud Firestoreでは違います。Query SubCollection Referenceなどリレーションを行う方法が複数用意されているからです。
NoSQLのベストプラクティスは資料が本当に少なくて色々考えるのに苦労したんですが、僕が考えたベストプラクティスをみんな見てください。そして指摘があればください。
参考になりそうな資料を載せておきます。
DynamoDB のベストプラクティス
サーバーやインフラの性能に触れながら読めるのでとてもいい資料です。
NoSQLデータモデリング技法
Realtime Databaseを設計するなら必ず読んだ方がいい資料です。
残念ながらこれらより時代は進化してまして。
SubCollectionについて考慮された資料は公式のFirebaseがリリースしている情報をのぞいて皆無に近い状態です。
YouTube Firebaseをご参照ください。
CloudFirestore データベース設計
2018年のDevFestで登壇した資料をより深く解説します。🙏🏻
Firestore Database Design
リレーションシップの種類
Cloud Firestoreの複数の方法でリレーションシップ作ることが可能です。まずはその種類を紹介します。タイプ別に種類を図にしました。
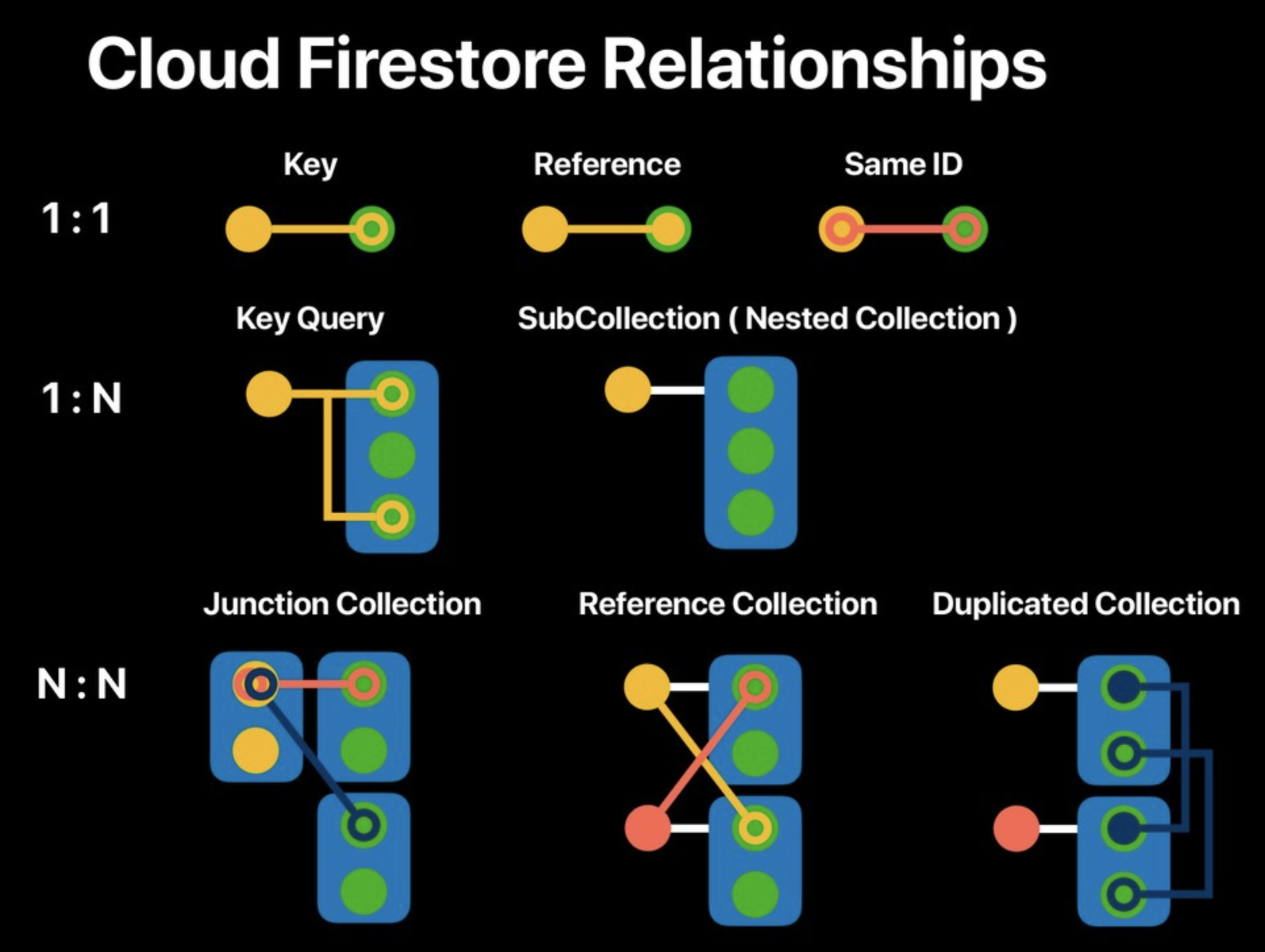
最終的にこの8パターン組み合わせになるのかなと考えています。
以降Swiftのコードが掲載されますなんとなく読めると思うのでご参考ください。
■ Key
 これはRDBでも使われる一般的なリレーション方法です。RDBで言うならテーブルに参照先のレコードのIDを持っている状態です。ここでは、`Item`が`userID`を保持していることから`Item`と`User`の関係を表しています。
これはRDBでも使われる一般的なリレーション方法です。RDBで言うならテーブルに参照先のレコードのIDを持っている状態です。ここでは、`Item`が`userID`を保持していることから`Item`と`User`の関係を表しています。
■ Reference

これはCloud Firestoreがもつ__Reference__型を使ったリレーション方法です。
__Key__との違いについて考えてみましょう。CloudFirestoreでは次のようにパスにJSONデータを持たせます。
// /user/:id
{
"name": "hoge",
"age": "25"
}
ユーザーの情報のマイグレーションしなければならない状態を想定しましょう。例えばageをStringで定義してしまったのでNumberに変更したい場合、今の構造では次のようにするしかなくなります。
// /user/:id
{
"name": "hoge",
"age": "25"
"age_number": 25
}
ちょっと残念ですよね。 ちなみにこれ__ベストプラクティス__です。色々考慮するとこのマイグレーションが一番コストかからずシンプルに移行できます。
ちょっと残念だから綺麗にしたい方はこうするのがオススメです。
// /version/1/user/:id
{
"name": "hoge",
"age": "25"
}
最初からパスにバージョン情報を持たせましょう。そうすると
// /version/2/user/:id
{
"name": "hoge",
"age": 25
}
バージョンの変更に合わせて、データをマイグレーションできます。増大したデータのマイグレーションにはコストもかかるので、モデルのバージョンをあげることは稀ですが可能です。
しかし、ここでリレーションに話を戻すと問題が出てきます。
ItemとUserの関係を表すuserIDはIDのみを保持しており、バージョン情報を持っていません。そこで登場するのがReferenceになります。Referenceは__パス__そのものを保持することが出来るようになります。
Referenceは多用できない
「Reference便利💪🏻」となったかも知れませんが、Referenceは多用できません。なぜでしょうか?ItemにReferenceを持たせるとどうなるかを考えてみましょう。
次の状態では、Itemはバージョン1のUserを参照しています。
// /version/1/item/:id
{
"userID": "user_ID" // :id
"userReference": "<Ref>", // /version/1/user/:id
}
もしUserのバージョンが更新さたらどうなるでしょうか?Itemは古いバージョンのReferenceを持っているためItemもマイグレーションが必要になります。
どうやら違うモデルを参照する場合は、__Key__のみを保持する方が良さそうです。
ではReferenceはいつ使うのか?
- 新しいモデルから古いモデルを参照する時
- ネストの深いモデルを参照する時
ではないかと考えています。
例えば次のように現行バージョンが旧バージョンを参照する場合や
// /version/2/item/:id
{
"userID": "user_ID" // :id
"oldItem": "<Ref>", // /version/1/item/:id
}
Keyでは表現しきれない階層の任意の情報を示したい場合
// /version/1/user/:id
{
"userID": "user_ID" // :id
"pinComment": "<Ref>", // /version/1/item/:item_id/comment/:comment_id
}
// /version/1/item/:item_id/comment/:comment_id
{
"userID": "user_ID" // :id
"oldItem": "<Ref>", // /version/1/item/:id
}
■ Same ID
 このリレーション方法は、CloudFirestoreのパス構造を使った方法です。セキュリティールールを効率的に与えることができるのでセキュアなデータを扱いたいときにオススメです。ユーザーにセキュアな情報を持たせたい場合を考えてみましょう。CloudFirestoreのセキュリティルールではフィールド単位でセキュリティをかけることができません。つまり高いセキュリティを持つドキュメントと公開可能なドキュメントは別々に保持する必要があります。例えばユーザーの情報のセキュリティを高く保つための構造は以下の二つの方法が考えられると思います。
このリレーション方法は、CloudFirestoreのパス構造を使った方法です。セキュリティールールを効率的に与えることができるのでセキュアなデータを扱いたいときにオススメです。ユーザーにセキュアな情報を持たせたい場合を考えてみましょう。CloudFirestoreのセキュリティルールではフィールド単位でセキュリティをかけることができません。つまり高いセキュリティを持つドキュメントと公開可能なドキュメントは別々に保持する必要があります。例えばユーザーの情報のセキュリティを高く保つための構造は以下の二つの方法が考えられると思います。
1. SubCollectionを利用した構造
/version/1/user/:user_id/secure/:id
UserのSubCollectionにセキュリティを高めたいデータを持ちます。
SubCollectionのセキュリティルールを設定しデータをセキュアに保ちます。
2. Same ID構造
/version/1/user/:user_id
/version/1/_user/:user_id
上ではUserと_Userの別のCollectionを定義しています。__Same ID__を利用してシンプルにセキュアな情報を保持できます。
Same IDを使ったソーシャル機能
/version/1/user/:user_id
/version/1/social/:user_id
UserとSocialを別のCollectionに定義しています。
Userに定義されるであろうデータ
{
"name": "1amageek",
"age": 31,
"gender": "male"
}
Socialに定義されるであろうデータ
{
"followerCount": 2000,
"followeeCount": 23
}
一見全てユーザーがもつべきデータに見えますが、UserとSocialには明確に分けるべき理由があります。
-
Userデータは自分以外から更新させたくない -
Socialデータは自分以外からの更新できるようにしたい
理由はそれだけではありません。Socialデータの方が圧倒的に更新頻度が多いはずです。
ここでUserデータの特性を考えてみましょう。このデータはどこで利用されるでしょうか。ソーシャル機能を作っているのであればユーザー検索は必須な機能となり得るでしょう。Cloud Firestoreの検索機能は非常に貧弱なのでAlgoliaやElasticSearchなどに検索機能を任せることが考えられます。
同時にAlgoliaやElasticSearchの更新にはCloud Functionsを利用することが想像できると思います。もしUserデータにSocialデータを含めていたらどうなるでしょうか。カウントがインクリメントされるだけでCloud Functionsがトリガーされることになりそうです。
■ Query

このリレーションの方法もRDBでも使われる一般的な方法です。RTDBとは違いwhereが利用できるようになってとても便利になりました。
■ Sub Collection
 Cloud Firestore最大の特徴がこの`SubCollection`です。この構造は他のデータベースには存在しません。
Cloud Firestore最大の特徴がこの`SubCollection`です。この構造は他のデータベースには存在しません。
QueryとSubCollectionの使い分け
ここでQueryとSubCollectionの使い分けについて考えてみましょう。
Cloud FirestoreのSubCollectionとQueryっていつ使うの問題
過去のこの様な記事をリリースしましたが、この問題の解答編になります。
| - | メリット | デメリット |
|---|---|---|
| Query | 横断的にQueryを行える | Readのセキュリティルールは必ず全員に公開する必要がある |
| SubCollection | セキュリティの設定が容易 | ネストしている親をまたいで検索は行えない |
| CollectionGroup | ネストしている親をまたいで検索を行える | 横断範囲が広くセキュリティの設定が難しい |
横断的にQueryを行えるの説明をしておきます。
Cloud Firestoreではドキュメントに強固なセキュリティルールを設定した場合にQueryを実行することができなくなります。
セキュリティルールとQueryの関係はこちらに記載されています。
https://firebase.google.com/docs/firestore/security/rules-query?hl=ja
つまりRoot Collectionに配置するドキュメントは緩やかなセキュリティルールを持っている必要があります。
2019年6月のアップデートでCloud FirestoreでCollectionGroupが利用可能になりました。
SubCollectionでも横断的にQueryを実行できるようになりました。
待ち焦がれたCollectionGroupがCloud Firestoreへやってきた。
データのインサートが多いCollectionはRootCollectionには配置しない
Collectionへのインサートには1秒間500回の制限があります。コンシューマー向けのサービスで瞬間的性能が必要なサービスを作るのであればSubCollectionを利用した方が良いでしょう。
例えば
- ECなどの売上を管理したい場合、
Transaction DocumentをRootCollectionに配置してしまうと1秒に500件以上の販売することができない。/user/:user_id/transactions/:transaction_idとしてCollectionGroupで計算する方が良さそうです。
セキュリティが使い方を分ける
2つのリレーション方法の使い分けはセキュリティに依存します。
サービスの全利用者に公開できる情報はRoot CollectionとしてQueryでリレーションするのが良さそうです。一定のセキュリティを保ちたい情報はSubCollectionにする方が良さそうです。
例えば
- ブログの記事などの公開情報はルートコレクションへ
- 決済情報などセキュアな情報はUserのSubCollectionへ
■ Junction Collection
 この方法もRDBで使われる中間テーブルをもつ方法です。
この方法もRDBで使われる中間テーブルをもつ方法です。
■ Reference Collection
 この方法はCloud FirestoreのSubCollectionを利用した方法です。
NoSQLで唯一Cloud Firestoreだけが出来る構成です。
この方法はCloud FirestoreのSubCollectionを利用した方法です。
NoSQLで唯一Cloud Firestoreだけが出来る構成です。
__Firebase Realtime Database__で、この方法を使うと構造上データが肥大化することになり使うことが出来ませんでした。Cloud Firestoreでは、DocumentとCollectionに分離された構造になっているため、その制約がなくなりました。
Junction CollectionとReference Collectionの使い分け
| - | メリット | デメリット |
|---|---|---|
| Junction Collection | 横断的にリレーションシップの検索を行える 状態を持てる |
Readのセキュリティルールは必ず全員に公開する必要がある |
| ReferenceCollection | リレーションシップを持っている状態を隠せる | ネストしている親をまたいで検索は行えない |
N:Nのリレーションシップにおいても、セキュリティルールに依存します。
例えば、招待機能の機能を考えてみましょう。
User AからUser Bに送られた招待状が未開封のままである。
これをJunction Collectionのデータにするならば下のようになります。
// Invitation
{
"fromID": "userA",
"toID": "userB",
"status": "isUnopened"
}
次に、この招待状を受け入れるとそれぞれフォロー関係が成り立つとしましょう。
これを構造で表すと下のようになります。
/user/userA/followers/userB
/user/userB/followers/userA
User AがUser Bをfollowersとして保持し、User BもUser Aをfollowersとして保持する。
FirestoreではWriteBatchを使って複数の書き込み先に同時に一度に書き込むことが可能なので、どの処理も簡単に行えます。
トランザクションと一括書き込み
Firestotre のバッチ処理とトランザクション処理
■ Duplicated Collection

この方法は、セキュリティを保ちつつデータを参照するデータを参照する方法です。
決済情報をもつデータ構成を考えてみましょう。
ShopのProductをUserが購入した情報をTransactionとして保持する。
TransactionはShopとUserのみが参照できる。
この要件を満足したい時、Transactionはどこに保持するのがいいでしょうか。
まず、Transactionには必ずセキュリティルールを設定するので、横断的なQueryは機能しなくなります、そのためルートコレクションに配置することは避けた方が良さそうです。
次に、セキュリティを担保するためにはSubCollection構造にするのが良さそうですが、ShopとUserのどちらに持たせるのがいいでしょうか?Userが持たせるとShopからは参照できませんし、Shopに持たせるとUserからは参照できません。
ということで双方に保持するようにしましょう。これも__WriteBatch__を利用することで簡単に実現可能です。ただしこの方法は、Transactionのように書き換え頻度が低いデータに限った方が良さそうです。
冗長化すべきデータの制限
次のデータ構造を考えてみましょう。 ユーザーの情報を冗長化してフォローに保存しています。
// /user/:user_id
{
"name": "hoge",
"location": [0, 0],
"age": "25"
}
// /user/:user_id/followers/:id
{
"name": "hoge",
"location": [0, 0],
"age": "25"
}
ユーザー情報は高頻度で更新されることが予想されます。ユーザーの情報が更新される度にフォロー先のデータを更新するのはとてもいい設計とは言えません。
私が実戦で利用しているデータ構造を8個ご紹介しましたが、他にもあらゆる構成が考えられます。見つけたらぜひ教えてください。
アプリで考慮すること
REST API
Cloud Firestoreは、SDKを利用することでDBに直接書き込みができます。一方でCloud Functionsを使うことでREST APIを設けCloud Functions経由でDBに書き込むことも可能です。
ではどちらを使えばいいのか考えてみましょう。
セキュリティについて
セキュリティ的にはREST APIでもSDKであっても大きな差はありません。ただSDKではセキュリティルールだけ考慮すればいいのに対して、REST APIではCloud Functionsの中で全てをAdminで動かすことになりますのでAPIのセキュリティには注意をする必要があります。
実装工数
プロトタイピングなどではSDKを利用する方が圧倒的に実装工数を低減できます。ただし、セキュリティルールを最低限にしてるものに限ります。個人的にはプロトタイピングの段階で強固なセキュリティルールは必要ないと思っているので、最低限のルールを記載して開発を進めるのがいいでしょう。
Callable Functions
FirebaseにはCallable functionsと呼ばれる専用のAPIが準備されています。このAPIにはAuth情報も含まれているのでREST APIを作るよりも安全に実装することが可能です。
REST APIを外部から呼ぶことがないようであればREST APIは利用せずCallable Functionsを利用することがいいでしょう。
Callable Functions vs SDK
Cloud Functionsに処理を任せることの最大のメリットはセキュリティルールをバイパスする事です。運用が開始され、セキュリティルールを強固にしていった時必ず権限の持たせ方に困ることがあります。例えば先ほどの紹介したDuplicated Collectionでは必ず相手の保護された領域に書き込みを行うことになります。となるとCloud Functionsを経由するのは必須となります。
また、SDKではセキュリティを考慮せず書き込みが行われる場合に活用するのがいいでしょう。やはりFirebaseの開発の醍醐味は開発の高速化にあると思いますので、あえてAPIを利用しなくていいのであれば可能な限りこちらを使うのが得策であると考えています。
Cloud Firestore Best Practice
Killswitch
Firebase Realtime Databaseと同様に、Cloud Firestoreは開発側の都合でサーバーを停止することはできません。必ずクライアントからの利用を制限する機能を設けましょう。
KillSwitch自体をCloud Firestoreに持たせる事も可能です。
例えば下の図のように強制アップデートが必要なバージョンやアプリが利用可能かを示すフラグを持たせることでハンドリングしましょう。

Data structure
SubCollection設計
■ 階層的なデータ構造を持たせる
Cloud Firestoreの設計で最も重要なのはSubCollectionの設計です。CollectionGroupの機能が追加されたことで、設計の柔軟性は飛躍的に向上しました。SubCollectionの設計はセキュリティや性能に大きく影響します。
参考になりそうな記事を書いてますので詳細はこちらをご覧ください。
Cloud FirestoreとFirebase Cloud Storageを使ってソーシャル機能を実装する方法
待ち焦がれたCollectionGroupがCloud Firestoreへやってきた。
■ 上位階層をドメインとして定義する
上位階層をドメインで切ることで、機能拡張や開発がやりやすくなります。
以下の例では公開ユーザーと非公開ユーザーをPathで分離しています。
公開するユーザー
/public/v1/users/:uid
/public/v1/posts/:post
非公開のユーザー
/private/v1/users/:uid
メッセージ機能
/message/v1/rooms/:room
/message/v1/rooms/:room/transcripts/:transcript
/message/v1/rooms/:room/members/:user
ドメインによる恩恵
どんなサービスを作る場合であっても、Userと呼ばれるデータを扱うと思うのでUserを例に上げて説明します。
例えば今、ECサービスを作っていると仮定しましょう。このECサービスでは次のようなとても簡単な要件があるとします。
- 買い物ができる機能
- 決済ができる機能
このときUserを次のように定義していたとしましょう。
/users/:user_id
買い物に必要なデータ、決済に必要なデータいろいろデータをUserに溜め込みそうですよね?
少し想像して欲しいのですが、この要件でサービスを作り終えました👏🏻👏🏻👏🏻👏🏻
そしてリリースしたとしましょう。
ここで次の要件を追加されました。
- お客さんとメッセージする機能
さてどうしますか?上位にUserのメッセージに必要なデータも保存しますか?いきなりデータをマイグレーションする必要が発生するかもしれません。
しかし、ドメインによって次のような設計になっていたらどうでしょう。
/payment/v1/users/:user_id
/public/v1/users/:user_id
/message/v1/users/:user_id
それぞれのドメインに属性の違うユーザーデータを管理することができ。開発でのコンフリクトも避けることができます。
また、セキュリティルールもドメインごとに管理できるため柔軟な設計にもつながります。
■ バージョン管理
CloudFirestoreでバージョンを管理する方法は複数考えられます。
Fieldにバージョンをいれる方法
class User {
version: string = '1'
name: string = '@1amageek'
}
CollectionIDに持つ方法
/message_v1/
DocumentIDに持つ方法
/message/v1/rooms/:room
上記の3つの方法はどれもデータベースの性能に大きな影響を与えません。つまり性能の差ではなく他の要件から手法を選定するのが良さそうです。
バージョン管理を考えたとき重要になるのはその__マイグレーション__や、__バージョンの並行運用__だと僕は考えています。それらの理由からSubCollectionに持つ方法を推奨しています。
実際サービスがリリースされた後どうしてもバージョンを上げなければならない事態に陥ったとしましょう。そのとき、単純に1だったバージョンを2にすれば対応が終わるわけではありません。少ないデータであればマイグレーション、すでに大きな運用データを持っているのであれば並行運用する必要があります。
そのとき必要なのは、開発サイドでデータモデルのバージョンをうまくコントロールできる仕組みです。次の要件を満足すればそれが可能だと考えています。
- バージョン別にデータを取得する
- バージョン別にデータの型違う場合も並行に運用できる
- バージョン別に同時に書き込むことができる
運用可能かを考える
Fieldにバージョンをいれる方法から見ていきましょう。
Fieldにバージョン管理に使うデータを入れた場合、DocumentのPathは一致するためQueryによってデータを取得することになりそうです。しかし、同じ名前で違う型になった場合の並行運用は難しそうです。
次のようなデータ構造にすればできなくはなさそうですが、Nestedな構造を対してないQueryも存在することからいい方法とは言えません。
class User {
v1: any = {
// v1 data
}
v2: any = {
// v2 data
}
v3: any = {
// v3 data
}
}
__CollectionIDに持つ方法__はどうでしょうか。
もちろんCollectionIDが違うので別々にデータを取得することは容易です。また、データ型が違ったとしてもDocumentを独立並行に運用することも可能です。同時に書き込むこともできるのでこの方法は問題は良さそうです。
__DocumentIDに持つ方法__はどうでしょうか。
こちらもただPathが違うだけなので、同じことができそうです。しかし上記で説明したドメインの概念をデータ構造に入れるとDocumentIDにバージョンを入れる方が相性が良さそうです。
CloudFirestoreのPathは次のようにCollectionとDocumentが順になります。
# path
/CollectionID/DocumentID/SubCollectionID/DocumentID
上記で説明しているドメインをCollectionIDにつける手法と合わせて
# path
/Domain/Version/CollectionID/DocumentID
僕はこの方法を推奨しています。
Model
Model設計
RDBを利用してきたエンジニアでばあるほど、NoSQLの設計には苦労します。僕の周りの人間も実際にそうです。NoSQLの設計には割り切りも必要ですし、テクニックを知っている必要がありますが、Cloud FirestoreへQueryが実装されたこともあり、ある程度RDBで利用されてきた考え方が通用します。まずは、SubCollectionについて考えるのではなくRoot CollectionにModelを配置し、プロトタイピングを行ってみましょう。データ取得の最適化が必要なポイントはそこで整理できますし、セキュリティルールを強固にする必要があるポイントも見えてくるはずです。
Model設計の制約
■ ModelはupdatedAt, createdAtを保持する
もはやアプリ開発系の慣例的な部分でもありますが、やはりこの情報は持っておくことはすごく重要です。
運用時にも役にたちますし、開発においてもソートで利用することは結構あります。
ServerTimestampを利用する場合、Write性能が劣化します。スループットが必要な場合はShardを準備する必要があります。
■ Model内のArrayを活用する
ここはFirebase Realtime Databaseと全く逆の考えになるの注意してください。Cloud Firestoreでは、Arrayの制御も追加されました。ArrayをQueryで利用することも可能なので積極的にArrayを利用しましょう。
Better Arrays in Cloud Firestore!
■ Model内にパーミッションを持たせる
public privateなどのパーミッションを持たせることで、セキュリティルールのハンドリングを簡単に行うことが可能になります。

Firebase Summit 2018のセッションでも詳しく解説されているのでこちらをご参照ください。
マイグレーション
スキーマレスなデータベースのマイグレーション
まず根本的な考え方として次のポリシーをお勧めします。
CloudFirestoreのマイグレーションで考えられるのは以下の3つのパターンです。
| パターン | 説明 |
|---|---|
| ADD | Documentへ新しいFieldを追加する |
| MOD | DocumentのFieldの型を変更する |
| DEL | DocumentのFieldを削除する |
それぞれについて考えて行きましょう。
ADD (Documentへ新しいFieldを追加する)
CloudFirestoreはスキーマレスなデータベースです。Fieldの追加については大きな問題はないと考えて大丈夫です。
クライアントサイドの開発を考えたとき__iOS__の開発ではCodableを利用してJSONをStructへMappingするはずです。クライアントサイドではこのMappingに影響が出ないことを確認すればFieldはどのタイミングでどれだけ追加されても問題ありません。
MOD (DocumentのFieldの型を変更する)
MODをする場合は、サービスの性質によって大きく影響が出ます。
Webサービスの場合デプロイしてしまえばほぼ全てのユーザーが新しいバージョンを利用することになるので大きな影響は出ることは少ないでしょう。
ネイティブでサービスを運営している場合は、複数のAppバージョンをユーザーが利用することになるため大きな問題が出ます。ほとんどの場合はAppがクラッシュすることになるはずです。
MODをする場合のストラテジー
- 強制アップデートの仕組みを入れて、マイグレーションスクリプトを実行する
- バージョニングをする
- MODを利用しない
■強制アップデート
このストラテジーは、全てのDocumentのFieldを変更するスクリプトを実行しマイグレーションを行います。
マイグレーションスクリプトを実行しスキーマを変更した場合、型をクライアントではAppがクラッシュすることになるので強制アップデートの仕組みが必要になります。
マイグレーションスクリプトによる運用はDocumentの量が少ない場合では成立しますが、Twitterのように毎日とんでもない数のデータがアップされるようなサービスでは利用することは不可能です。
■バージョニング
このストラテジーは、過去のDocumentとは別にバージョンの違うDocumentを準備し、新しいAppバージョンを利用するユーザーは新しいDocumentを利用させます。同時に2つのバージョンの並行運用が必要となるので別の問題が発生します。
例えば、投稿機能で考えてみましょう。
ダブルライト
古いユーザーが古いAppバージョンで投稿した場合、新しいユーザーはそれを見ることができません。CloudFunctionsなどで新しいバージョンに随時マイグレーションが必要です。このように二つのバージョンに書き込むことをダブルライトといいます。
並行運用
新しいAppバージョンに古いバージョンのスキーマも残しておき、データリードを両方からすることで新旧両方を利用することも可能です。
MODを利用しない
Fieldが増えたとしてもユーザーの体験に大きな影響が出ることはほとんどありません。MODは利用せずADDで十分だと思います。
DEL (DocumentのFieldを削除する)
特別な場合を除いて、Fieldを削除するのも避けた方が賢明と思います。
非公開にすべき情報を誤って公開してしまっていたなど、対処が必要な場合は強制アップデートまたはKillswitchを利用するのがいいと思います。
最後に
MENTAでFirebaseを学ぶ講座やってます!
https://menta.work/plan/913
Cloud FirestoreとCloud Storageをいい感じで連携できるライブラリ作りました。
iOSとTypeScriptで利用可能です。ぜひ試してみてください!!

https://github.com/1amageek/Ballcap-iOS
https://github.com/1amageek/ballcap.ts