Firebase Realtime DBを実践に投入する
Databaseと聞くと、これから利用しようとする**Firebase**がmBaaSであることを忘れてついREST(Client Server Model)で考えてしまいがちですが、大前提はMobile Platformなので、一度REST、RDBの考え方は捨ててみてください。
RDBの考え方を引き継いだままでは、Firebase Realtime DBの最善の設計はできないと考えています。
そして、RDBの考え方を引き継いだままFirebase Realtime DBを理解しようとすることが、導入の一つの障壁となっていると思っています。
ぜひ頭をリフレッシュしてFirebase Realtime DBの見方を変えてみてください。
この記事では、Firebase Realtime DBの導入するにあたっての考え方やテクニックを紹介します。少しでも導入の参考になれば嬉しいです。
※ この記事は2016年に書かれた記事で、現在はFirestoreの利用を推奨しています。
参考リンク
Firebase Realtime Databaseとはなんなのか?
- 既存のDBをFirebase Realtime DBへマイグレーション時に考えたこと
- Firebase Cloud Functionsを使ってFacebook AccountKitをFirebase Authと連携する
🔖 RDBとFirebase Realtime DBの考え方の違い
構造の違い
まず、RDBとFirebase Realtime DBではどのくらいデータ構造に差があるのかを明確にしましょう。
GroupとUserの簡単なDBを考えます。複数のGroupとUserがありUserは複数のGroupに所属することが可能です。
ここで考えるDBの状態は以下の通りです。
[DBの状態]
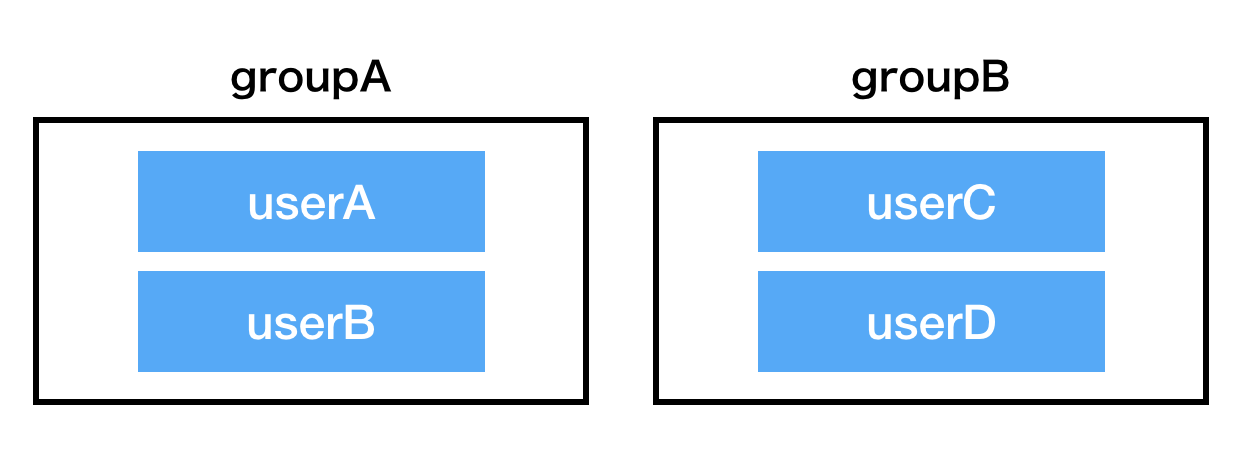
groupAにuserA,userBが参加
groupBにuserC,userDが参加
■ RDB
まず、RDBの場合は以下のようになります。見慣れた構造だと思いますので特に説明はしません。
Group table
| group_id | name |
|---|---|
| 0 | groupA |
| 1 | groupB |
User table
| user_id | name | group_id |
|---|---|---|
| 0 | userA | 0 |
| 1 | userB | 0 |
| 2 | userC | 1 |
| 3 | userD | 1 |
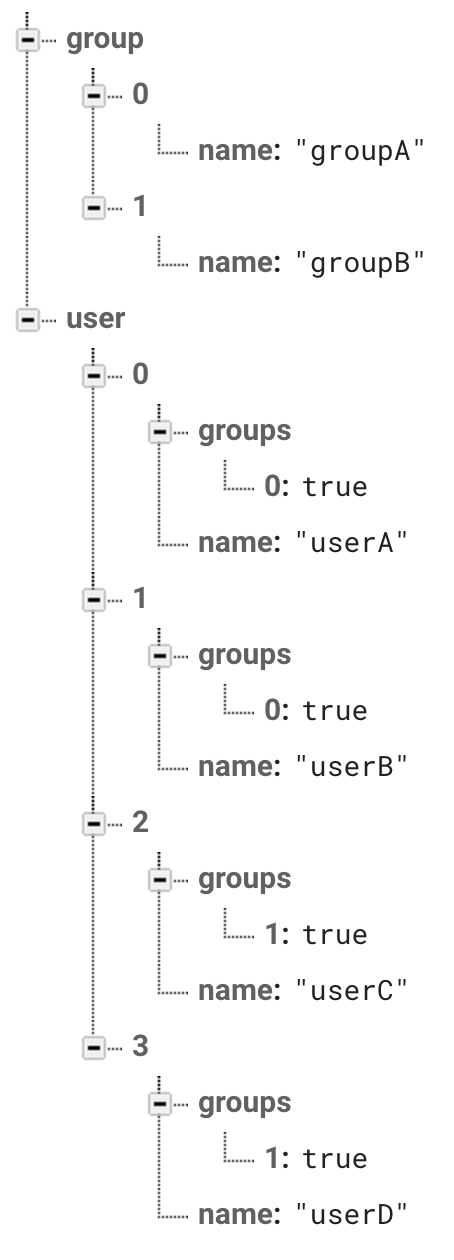
■ Firebase Realtime DB
Firebase Realtime DBでRDBの構造を単純に表現すると下のようになります。
※{key: true}のような構造が出てきますが、ここでは一旦Firebase Realtime DBのリレーションはこうすると理解して読み進めてください。
ここで性能について考えます。次の条件を考えてみましょう。
- 'Group'に所属する'User'を取得したい場合
- 'User'が所属する'Group'を取得したい場合
RDBの場合は、User tableを操作すればUser Groupいずれもすぐに取得できそうです。
Firebase Realtime DBの場合、そう簡単にはいきません。
なぜならFirebase Realtime DBはネストした構造に連続でアクセスすることが苦手だからです。
Groupに所属するUserを抽出したい場合を考えてください。
上の構造では、UserはGroupの情報を保持していますが、Groupはname以外を保持していません。
つまり、この構造ではUserの持つgroupsプロパティ以下、全てにアクセスしない限りあるGroupに所属するUserを取得することができません。
この性能劣化の問題を解決するために、この下のような構造にします。
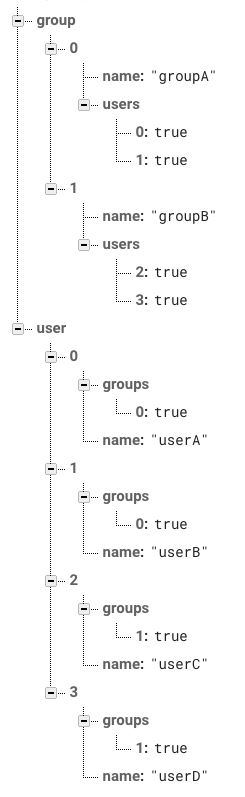
このように各モデルが相互で参照を持つ構造は、Firebase Realtime DBでのModel設計の定石です。
RDBの正規化の考え方からすると非常に冗長に見えるかもしれませんが、Firebaseでは、この割り切った考え方こそが重要になってきます。
Firebase Realtime DBではリレーションをする場合、{key: true}の形にします。ここで出てくるtrueの意味に関しては私も完全に理解できていません。ソート順では利用されるようですが、falseにする機会に出会ったことがないので慣例的にtrueとしています。keyに関しては、この記事を読み進めるにあたって理解が深まると思います。keyはFirebaseにおいて非常に大きな意味を持っています。
Firebaseのリレーションに関しては以下を参照してください。
Queryの違い
次に、RDBとFirebase Realtime DBのデータの取得について考えます。
groupAに所属するUserのnameを抽出したい場合を考えてください。
■ RDB
RDBの場合では、次のQueryになります。一般的なので特に説明しません。
select name from user where group_id = 0
結果
| name |
|---|
| userA |
| userB |
■ Firebase Realtime DB(iOS)
Firebase Realtime DBでは次のようになります。
// FirebaseのDBの参照を定義(root)
let ref: FIRDatabaseReference = FIRDatabase.database().reference()
// rootからgroupAの下にあるusersを取得する
ref.child("group").child("0").child("users").observeSingleEvent(of: .value, with: { (snapshot) in
// 複数のユーザーのkeyが取得できる
// ユーザーのkeyから順次ユーザーを取得する
for (_, child) in snapshot.children.enumerated() {
// ユーザーのkey
let key: String = (child as AnyObject).key
// ユーザーのキーからユーザーの情報を取得する
ref.child("user").child(key).observeSingleEvent(of: .value, with: { (snapshot) in
print(snapshot.value["name"])
})
}
})
// 結果
// userA
// userB
RDBから比べると、回りくどく非効率に見えるかもしれませんが、Mobile Appでは非常に効率的な手段です。
なぜこれがMobile Appにおいて効率的なのかは後の章で説明します。
- [NoSQL(Not Only SQL)データベースとは] (https://academy.datastax.com/what-is-nosql-jp)
- CAP定理を見直す。“CAPの3つから2つを選ぶ”という説明はミスリーディングだった
- Cloudの技術的特徴について
🔖 Mobile Appの性質
Firebaseを効率よく利用するためには、Mobile Appの性質を考慮する必要があります。数年前まではWeb Appの開発が勢力的行われていましたがユーザーのニーズは明らかにMobile Appになりました。
Mobile AppはWeb Appでは要求事項が異なるためWeb Appの仕様をそのまま引きずって開発するのは得策ではありません。
※ この記事でいうWeb Appとはデスクトップで操作するウェブアプリケーションのことを指しています。またMobile AppとはiOSやAndroidのネイティヴアプリケーションを指しています。
Mobile Appで考慮すべきこと
- ネットワークは不安定
- リソースに制限がある
- 表示領域に制限がある
- 開発サイクルが速い(エンジニアに開発速度を要求される)
■ ネットワークは不安定
Mobile Appは、オフラインになることを想定して設計されなければなりません。
■ リソースに制限がある
2016年10月時点でiPhone7 plusが3GBのメモリを搭載していますが、複数のAppを同時に立ち上げるの当然となった現在では、少し重さが緩和されるだけであって十分ではありません。
Mobile Appでは、メモリやストレージが制限されていることを想定して設計されなければなりません。
■ 表示領域に制限がある
見た目としてMobile AppとWeb Appに大きな差が出るのは、表示領域です。例えば、動線やコンテンツが多数盛り込まれた楽天のようなのページをMobileで再現するとなると、混沌としたAppになることは容易に想像がつきます。
Mobile Appでは、多くの情報を整理して効率的にユーザーに伝えることを想定して設計されなければなりません。
■ 開発サイクルが速い
iOS SDK, Android NDKは毎年更新され、さらに顧客のニーズも常に変化していくため、開発速度を早めることは、最善のUXをユーザーへ提供するのであれば必須です。
Mobile Appでは、要件が変化することを想定して設計されなければなりません。
🔖 Firebase realtime DBの特徴
Mobile Appの性質と照らし合わせるため、Firebase realtime DBの特徴を説明します。
- Realtime・AutoSync
- Offline
- Schemaless
- Multi platform
■ Realtime・AutoSync
Firebaseはデータの変化があると、それをリアルタイムに他のデバイスに同期します。また、この同期はリアルタイムに行われます。これは開発者が、データベースを監視するコードを数行書くだけで、RESTで実装していたGET POSTの処理を一切不要にすることを意味します。
■ Offline
Firebaseは、Mobileがオフラインでも利用可能です。Firebaseには、オフラインからオンラインになった時に、データの差分を同期する仕組みがあります。これは、ほとんどの通信でネットワークエラーのハンドリングを考慮しなくていいことを意味します。※トランザクションが必要な部分には必要です。
■ Schemaless
すべての Firebase Realtime DB データは JSON オブジェクトとして保存されます。
これは、DBの仕様を柔軟に変更できることを意味します。
■ Multi platform
Firebaseは、Objective-C Java Javascriptの複数の言語でSDKが提供されています。
🔖 FirebaseをMobile Appのソリューションにする
Firebaseを使うことで、Mobile Appが抱える課題を緩和することが可能です。
| 性質 | ソリューション |
|---|---|
| ネットワークは不安定 | Realtime・AutoSync Offline |
| リソースに制限がある | Realtime・AutoSync |
| 表示領域に制限がある | Realtime・AutoSync |
| 開発速度が速い | Realtime・AutoSync Schemaless |
🤔 ネットワークは不安定
オフラインでも動作するFirebaseは、ネットワークが不安定であるMobile Appにとって大きな意味を持ちます。
REST APIでもネットワークが復旧した際に、GETをすることは簡単ですが、POSTをキューイングして不整合なく処理しようとするならば、そのための実装は大きなものになるはずです。
🤔 リソース・表示領域に制限がある
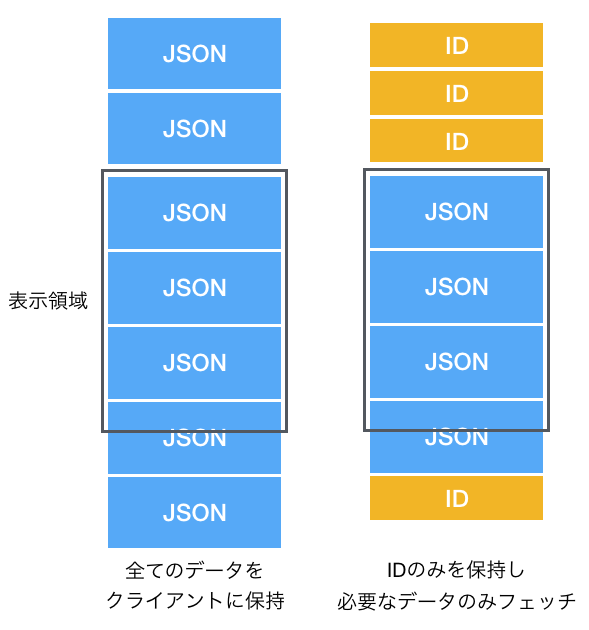
Mobile Appにおいて、リソースを最小限に止めるためには、表示領域に表示する以外のデータは保持しないことです。
Twitterを例にすると、現在のTwitterクライアントでは、iPhone6の表示領域に約3~4ツイートしか表示しません。

リソースを最小限にするならばこの数ツイート以外は保持するべきではありません。しかし、これは現在のMobile Appの開発では誤った考え方です。その理由は、ユーザー体験を阻害するからです。保持するデータが極端に少ない場合、次のツイートの取得するたびに、ユーザーを待たせることになります。
通常Mobile Appでは、表示領域以外のデータを保持しています。保持するデータの数はサービスの性質に依存しますが、起動時に、数十個保持することがほとんどです。
では、Google Photoのように大量のデータを持つ場合はどうでしょうか、当然全てのデータをクライアントに持たせることは最適解ではありません。必要な情報のみを保持し、表示領域に入る前にデータをフェッチすることが現状では最適です。
Firebaseのデータ参照方法を思い出してください。Firebaseはkeyから連続でデータを読み込むことを推奨しています。
// FirebaseのDBの参照を定義(root)
let ref: FIRDatabaseReference = FIRDatabase.database().reference()
// rootからgroupAの下にあるusersを取得する
ref.child("group").child("0").child("users").observeSingleEvent(of: .value, with: { (snapshot) in
// 複数のユーザーのkeyが取得できる
// ユーザーのkeyから順次ユーザーを取得する
for (_, child) in snapshot.children.enumerated() {
// ユーザーのkey
let key: String = (child as AnyObject).key
// ユーザーのキーからユーザーの情報を取得する
ref.child("user").child(key).observeSingleEvent(of: .value, with: { (snapshot) in
print(snapshot.value["name"])
})
}
})
RDBやRESTを使った場合では、通信のオーバーヘッドや、DBの制約からこの方法を使用することが最適ではないことは、容易に想像できるかと思います。
またFirebase Realtime DBには、クエリで取得するデータを制限できるようになっています。クエリで取得するデータを制限方法に関してはこちらをご参照ください。
🤔 開発速度が速い
ここでは、導入フェイズ・開発フェイズ・運用フェイズに分けてFirebaseの実開発について説明します。
いずれの場面でもSeverlessで開発を進めることができるため、開発は非常にスピーディになります。
■ 導入フェイズ
Firebaseの導入コストは、ほとんどかかりません、初期の調査や、試験的な運用に必要な部分は十分に無料枠でまかなえます。
また、既存システムからの移行に関しても十分なソリューションが準備されています。
既存システムをすでに運用している場合、まず最初に困るのは、ユーザー情報の移行です。Firebaseでは、カスタム認証システムと呼ばれる仕組みを持っており、既存システムに大きな変更を加えることなくFirebaseを利用することができるようになっています。
■ 開発フェイズ
開発フェイズで一番困ったのは、上で述べているようにREST RDBを用いたシステムの頭から考えを方切り替えることでした。また後に記述しますが、Firebaseでデータスキーマを考えることは、RDBの正規化を考えるのとはアプローチが違うので、そこにも悩まされましたが、制約を設けて設計することで、RDBよりも設計はスムーズに進みます。
Firebaseには、コンソールが準備されています。コンソールを使っての開発はデバッグ時に非常に役に立ちます。サンプルデータの準備を手動でも即入力でき、リアルタイムに結果を確認できることは、開発において非常に有利だと考えています。
■ 運用フェイズ
運用では、現2016年10月時点でFirebaseが不安定であることを考慮し、Firebaseが停止した場合、バックアップシステムに切り替えができるようにしています。
運用においては、Realtime DBよりも、Analytics, Remote config, Notificationsの機能が強力で開発者を幸せにしています。
Analytics, Remote config, Notificationsの連携の記事は別途ご紹介します。
Firebase Realtime DB Best Practice(beta)
Killswitch
Firebaseは開発者が意図的に停止することはできません。
Firebaseの運用を考えるのならばFirebaseへのKillswitch(アクセスを制御できる機能)をクライアントにを準備するべきです。
停止だけでなくメンテナンスにおいても同じ問題は発生します。
Model
Firebase Realtime DBはスキーマレスです。スキーマがないことは開発の幅を広げますが、バグをうみやすくします。いずれのDBにおいても、概念を抽象化し設計を行うべきです。その意味でModelは重要な役割を持つと考えています。そこで、Firebase Realtime DBに適したModel設計を考案しました。以下の制約を設けることでスムーズに設計が進むと思います。
この制約をよりブラッシュアップさせたいので、たくさんの方の意見を頂ければ幸いです。
Model設計の制約
- Modelは並列に構成する
- Model名は単数形の名詞にする
- ModelのKeyはSortできるキーをセットする
- Modelは
_updatedAt_createdAtを保持する - Model内に配列を保持しない
- Model内のプロパティに
AccessKeyを含める
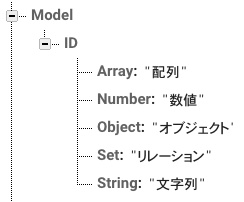
モデルの略図
■ Modelは並列に構成する
設計を簡略化して考えるため、隠れたModelを作るべきではありません。
Modelをネストして作ることもFirebase Realtime DBであれば可能ですが、大きなメリットを持ちません。
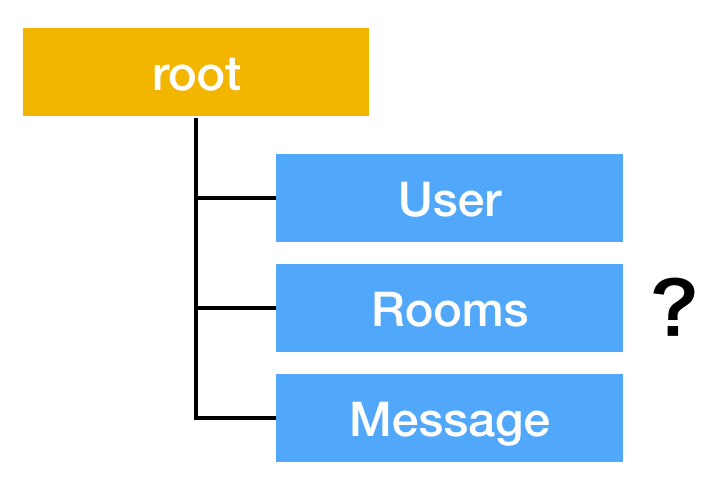
モデルの中にモデルがある構成の例
簡単な例としてチャットアプリをあげます。このチャットアプリではUser Room MessageのModelが存在するとします。
推奨しません
room: {
roomID1: {
messages: {
messageID1: {
text: "hello!",
_createdAt: 123456780,
_updatedAt: 123456780,
},
messageID2: {
text: "hi!!",
_createdAt: 123456780,
_updatedAt: 123456780,
}
}
},
roomID2: {
}
}
推奨
room: {
roomID1: {
messages: {
messageID1: true,
messageID2: true
}
},
roomID2: {
}
},
message: {
messageID1: {
text: "hello!",
_createdAt: 123456780,
_updatedAt: 123456780,
},
messageID2: {
text: "hi!!",
_createdAt: 123456780,
_updatedAt: 123456780,
}
}
Modelをネストしなければ実現できないこともあります。
- データを
keyでなくvalueでソートする場合 -
valueにデータのインデックス作成する場合
例えば、シューティングゲームのScoreをUserごとに管理したい場合は以下のように設計すべきです。
以下のようにすることで、スコア順にデータをソートすることができます。
user: {
userID1: {
histories: {
historyID1: {
score: 112,
_createdAt: 123456780,
_updatedAt: 123456780,
},
historyID2: {
score: 312,
_createdAt: 123456780,
_updatedAt: 123456780,
}
}
},
userID2: {
}
}
ただし、Firebase Realtime DBにはRDBのように複合的なクエリを実行できる仕様ではないため、もし既存のシステムがクエリを実行することによって成り立っているのであれば、根本的にFirebaseの導入を見直した方がいいでしょう。
■ Model名は単数形の名詞にする
FirebaseではModelをクライアント・サーバーで分け隔てなく、統一管理をすることが望ましいため統一しましょう。
■ ModelのKeyはSortできるキーをセットする
Firebaseの性能はKeyで決まります。Keyはデータのユニークを担保しているだけではありません。時系列を含み作成された順番を保っています。任意でKeyをセットする場合は辞書順になることを意識することをお勧めします。
■ Modelは_updatedAt _createdAtを保持する
「いつ発生した」は、あらゆる問題を解決するための重要ないとぐちです。
時系列で問題を追えるようにしておくことをお勧めします。
■ Model内に配列を保持しない
前述しましたが、Firebaseの性能はKeyで決まります。データを配列で管理することにメリットはありません。
有名なブログ記事があるので是非ご覧ください。
■ Model内のプロパティにAccessKeyを含める
Firebaseにはデータアクセス制御をするRuleと呼ばれるセキュリティが存在します。Modelが誰からアクセスを許可するのかを明示することは、データのセキュリティを向上させます。
双方向なリレーションを行うことが推奨されているため、意識しなくてもAccessKeyを付与していることがほとんどですが、誰からアクセスされるべきデータなのか意識して設計することをお勧めします。
{
user: {
userID0: {
activities: {
activityID0: true,
activityID1: true
}
}
},
activity: {
activityID0: {
userID: userID0 // activityID0にアクセスするためのAccessKey
content: "hello",
_createdAt: 012345678,
_updatedAt: 012345678,
}
}
}
Rule
{
"rules": {
"user": {
"$user_id": {
".read": "auth != null && auth.uid == $user_id", // 認証後、ログインユーザーと一致している場合データを読むことができる
".write": "auth != null && auth.uid == $user_id" // 認証後、ログインユーザーと一致している場合データを書き込むことができる
}
},
"activity": {
"$activity_id": {
".read": "root.child('user/'+ auth.uid +'/activities/'+$activity_id).exists()" // Userのactivitiesの中に$activity_idを保持していればデータを読むことができる
".read": "data.child('user_id').val() == auth.uid" // このデータのuser_idがログインユーザーのIDと一致していればデータを読むことができる。
}
}
}
}
Firebaseにおいての上記の設計思想からModelを管理できるLibraryを作りました。
https://github.com/1amageek/Salada RealtimeDatabase用
https://github.com/1amageek/Pring CloudFirestore用
Firebaseについてさらに詳しく知りたい方は次をご覧ください。