こんにちは、Stamp Incの村本です。
NoSQLの過去と未来についてまとめます。
普段はFirebaseの技術コンサルティングをやってます。
RDBの歴史
__NoSQL__の必要性を語るためにまず、__RDB__の登場の経緯、歴史から見ていこうと思う。__RDB__の登場は1970年代まで遡る。
RDBの登場
RDB(リレーショナルデータベース)が登場する以前のデータベース市場では、階層型と呼ばれるモデルに基づいた製品が主流だった。当時はIBMが開発した__Information Management System(IMS)__が利用されていた。
IMSが使われた最も有名なシステムが、1961年から始まったNASAのアポロ計画です。最終製品を構成する部品の階層関係を表したリストをBOM(Bill of Materials)と呼び、製造業ではどのような製品を作るかを問わず、このBOMが設計図と並ぶ重要な情報です(BOMは日本語では「部品表」と呼びます)。IMSはロケットの膨大な部品群を管理するという難解な課題に優れた解を与えたデータベースでした。
RDBを生み出したのはIBMのエンジニア
40代半ばのエンジニアE.F.コッドが書いた「A Relational Model of Data for Large Shared Data Banks」
リレーショナルデータベースの考案者 E. F. CODD
A Relational Model of Data for Large Shared Data Banks
[論文] https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
[参考] エドガー・コッドの「リレーショナル・データ・モデル論」
[参考] https://www.cc.u-tokai.ac.jp/text/2005/Access-intro.pdf
その後、外部のエンジニアたちによって多くのRDBが開発される。
| 年代 | DB | 主要な開発元 |
|---|---|---|
| 1974年 | Ingres | カリフォルニア大学 |
| 1979年 | Oracle Database | Oracle |
| 1983年 | DB2 | IBM |
| 1987年 | Sybase SQL Server | Sybase |
| 1989年 | MS SQL Server | Microsoft |
| 1989年 | PostgreSQL | カリフォルニア大学 |
| 1995年 | MySQL | MySQL AB |
RDBよりも先に生まれたACIDの概念
ACIDは__1983年__にアンドレアス・ロイターとテオ・ヘルダーによって提唱されが、この概念はジム・グレイよって1970年代後半に定義された。また、__1973年__に__IMS__はACID トランザクションをサポートしている。
| 年代 | できごと |
|---|---|
| 1973年 | __IMS__はACID トランザクションをサポート |
| 1979年 | ジム・グレイがACIDの概念を定義 |
| 1983年 | アンドレアス・ロイターとテオ・ヘルダーがACIDを提唱 |
データの整合性を重要視してきた歴史
RDBがトランザクションを重要視しているのには理由がある。開発当初は世界中の人間がアクセスするインターネットはなく、マシンの性能もムーアの法則の初期で限界を意識してなかったはずだ。
システムがデータベースに求めたのはスケール性能ではなく、厳密な一貫性だったと言える。
| 年代 | できごと |
|---|---|
| 1961年 | 最初のパケット通信の論文 |
| 1969年 | ARPANETで初のパケット送信 |
| 1980年 | イーサネットの規格公開 |
| 1982年 | TCP/IP標準化 |
| 1982年 | Simple Mail Transfer Protocol (SMTP) |
| 1983年 | Domain Name System (DNS) |
事実世界のインターネット人口が増えたのは1990年代からだ。
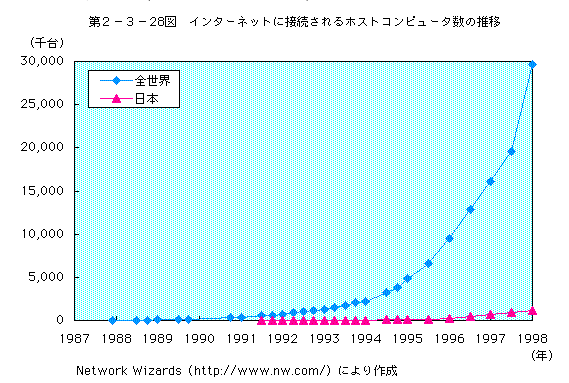
[引用] http://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h10/html/98wp2-3-1f.html
[引用] http://www.soumu.go.jp/johotsusintokei/whitepaper/ja/h29/html/nc144210.html
__NoSQL__の登場
1990年に入るとインターネットの利用人口が急激に増加することになる。
この頃からトランザクションに最適化されて設計されたDBでは性能劣化が始まり、システムはデータベースに対しスケール性能を必要とし始める。
多くの開発者は、単一の強力なサーバーでリレーショナル・データベースを実行するのではなく、リレーショナル・データベース管理システム (RDBMS) のパーティショニング (シャーディング) を試み、(サーバーの「クラスター」内で) 分散システムとして実行しました。しかし、リレーショナル・データベースには 1 次書き込みサーバー・ノードと読み取り専用のレプリカとの間のデータの平行性に問題があり、アクセス・スピードに悩まされ、異なるノードに格納されているテーブル間の結合操作を効果的に実行できないことがわかりました。

1998年Carlo StrozziによってSQLのない軽量なDBを推進する運動として"NOSQL"という言葉が使われる。
NotOnlySQL
2000年代半ばに2つの企業がデータの保管と検索のための新たなモデルを相次いで発表する。
__Google__は2006年「A Distributed Storage System for Structured Data」でカラム指向データベース・システムである「BigTable」の妥当性を示し、__Amazon__は2007年「Dynamo」で分散キーバリュー・ストレージ・システムを提示した。
そして、2009年にサンフランシスコで開かれたミートアップで「NoSQL」がハッシュタグとして使われ、次々生まれることになるRDBでないデータベースは「NoSQL」と呼ばれることになる。
Bigtable: A Distributed Storage System for Structured Data
Dynamo: Amazon’s Highly Available Key-value Store
NoSQLを次のレベルに引き上げたCassandra(カサンドラ)
__Facebook__によって開発されたNoSQLのデータベースCassandra。
Facebookは2008年7月に__Cassandra__をオープンソースソフトウェアとして公開し、2009年3月から__Apache Incubator__プロジェクトとなる。DynamoDBのような高い可用性とスケーラビリティを保持している。
Facebookのデータチームを率いるJeff HammerbacherはCassandraをAmazon DynamoDBのようなインフラストラクチャ上で動作するBigTableデータモデルであると表現している。
調節可能な整合性レベルと結果整合性
CassandraはDynamoと同じく、基本的には結果整合性を前提としているが__整合性レベルの調節が可能__だ。これにより開発者はスケーラビリティとのトレードオフを実現できるようになっている。
書き込み性能に最適化
AmazonのDynamoが__B-tree__を採用しているのに対し、CassandraはGoogleのBigTableをモデルとして作られたHBaseと同じく__LSM Tree__を採用している。
Cassandraが採用したCAP定理はAP
__HBase__はCAP定理のCPを採用し、__Cassandra__はAPを採用している。
一貫性を強く意識して作られてきたデータベースの歴史の中で一貫性を捨てたことには大きな意味がある。正確には捨てた訳でなくEventual Consistency(結果整合性)の概念を取り入れている。
Eventual Consistencyまでの一貫性図解大全
分散合意プロトコルPaxos
インターネット人口の増加に伴い世界的にデータベースを分散化させるニーズが出始める。そこで重要になったのが地理的に分散化したデータベースでも一貫性を保つ手法だ。__Paxosプロトコル__は1990年に登場し命名されたが、論文として出版されたのは1998年。
[参考] https://ja.wikipedia.org/wiki/Paxos%E3%82%A2%E3%83%AB%E3%82%B4%E3%83%AA%E3%82%BA%E3%83%A0
導入が進まないNoSQL
TwitterがCassandraの導入を検討するが断念
Cassandra導入の検討
TwitterはMySQL+memcachedで運用を行っていたが、運用コストの増加によりほかのデータベースを検討を始める。
2010年のmyNoSQLには次のようなインタビューがある。
Cassandra @ Twitter: An Interview with Ryan King
We have a system in place based on shared mysql + memcache but its quickly becoming prohibitively costly (in terms of manpower) to operate. We need a system that can grow in a more automated fashion and be highly available.
私たちはShardingされたMySQL + memcachedをベースとしたシステムを運用しています。しかしそれは急速に受け入れがたいほど運用コストが(おもに人的コストが)かかるようになってしまいました。もっと高可用で自動化された方法で成長可能なシステムが必要です。
GoogleでMySQLエンジニアリングチームを率いたのち、現在はFacebookに在籍しているMark Callaghan氏が2010年にポストしたブログは次のように始まる。
A few years ago MySQL+memcached and PostgreSQL+memcached were the only choices for high-scale applications. That has changed with the arrival of NoSQL.
数年前まで、MySQL+memcachedやPostgreSQL+memcachedの組み合わせは、スケーラブルなアプリケーションのための唯一の選択肢だった。しかしその状況はNoSQLの登場で変わった。
Facebook在籍中のMark Callaghanの動画
[YouTube] MySQL vs something else Evaluating alternative databases
戦略的理由で導入を断念
NoSQLデータベースであるCassandraへ移行しようとしたが作業を中止し、引き続きMySQLでの運用を継続すると、2010年7月9日のTwitter Engineering Blogで公表する。
For now, we're not working on using Cassandra as a store for Tweets. This is a change in strategy. Instead we're going to continue to maintain our existing Mysql-based storage.
We believe that this isn't the time to make large scale migration to a new technology.
ツイートの保存先としてCassandraを使うための作業を中止した。これは戦略の変更だ。私たちは既存のMySQLベースのストレージを利用し続けることにする。
いまは新しい技術への大規模な移行をする時期ではないと確信している。
Twitterは2010年10月時点で位置情報のデータストレージ、トップツイートなどのリアルタイム分析、データマイニング処理などの多くの用途でCassandraを活用しており。あくまでもツイートのストレージとしてのCassandra利用を断念しただけなので誤解なく。
| 日付 | ブログ |
|---|---|
| 2010年2月23日 | Cassandra @ Twitter: An Interview with Ryan King |
| 2010年3月2日 | Plays well with others |
| 2010年7月10日 | Cassandra at Twitter Today |
NoSQLが解決したRDBの特性
RDBのボトルネックは二つ
- 一貫性を担保するためストレージを共有する構成を取る必要があること
- SQLが強力で柔軟なため複雑な処理を実行できてしまうこと
RDBの柔軟なQueryはNoSQLと比べて大きなアドバンテージである一方、障害点になり得ることを忘れてはならない。事実現在RDBに高負荷を与えているのは高度に組み上げられたSubQueryだ。NoSQLではQueryに頼らない設計をせざるを得ない。NoSQLでは__Client Side Join__を推奨しており__JOIN__をClient側で行う。これによりデータベースの負荷を分散している。
ただし、これはRDBでも同じ設計・開発方針を行うことは可能だ。ここで述べたいのはQueryだけに頼った設計では限界があることを開発者は意識すべきだと言うことだ。アプリケーションエンジニアとインフラエンジニアが別れてる開発現場においてはアプリケーションエンジニアの設計によってインフラエンジニアが悲しい思いをすることになる。
データモデルの限界
- RDBは構造化データを表現しにくい
RDBは静的なテーブルの構造で、システムを運用する中で動的に変更することは想定していないことが一般的。テーブル定義やテーブル間のリレーションを変更することは大規模なマイグレーションが必要になる。
現在はMySQLはJSONに対応したことで、ドキュメントDBのように柔軟な設計を作ることも可能になった。
技術発展と共にNoSQLとRDBの境界線は不鮮明に
次々とNoSQLを発表するGoogle
2011年スケーラビリティと一貫性を両立した分散データストアMegastoreを発表。
Google Cloud Platform(GCP)では、Cloud Datastoreというデータストアを利用することができ、Cloud Datastoreは、内部的にMegastoreを用いて実装されている。
Megastore: Providing Scalable, Highly Available Storage for Interactive Services
2012年に設計が論文として公開されたSpanner。2017年からはGoogle Cloud Platform上で提供されている。
トランザクションに対する最も厳格な同時実行制御(外部整合)をクライアントに保証している。
Spanner: Google's Globally Distributed Database
[参考] Spanner, TrueTime & The CAP Theorem
分散データベースであるCloud SpannerはNoSQLと似た特徴を持っていながらGoogleではRDBとして位置付けられている。

データベースにおける整合性の定義
| 用語 | 定義 |
|---|---|
| 整合性 | データベース システムにおける整合性は、あらゆるデータベース トランザクションが、影響されるデータを、許可された方法でのみ変更しなければならないという要件を指します。データベースに書き込まれるデータは、定義されたすべてのルールに従って有効でなければなりません。 |
| 直列化可能性 | 直列化可能性は、異なるトランザクションの一部が並列に複数のオブジェクトを読み書きする可能性がある、トランザクション分離プロパティです。トランザクションの挙動が、トランザクションが順次実行された場合と同じになることを保証します。ただし、その順序は、トランザクションが実際に実行された順序と違っても問題ないとされます。 |
| 線形化可能性 | 線形化可能性は、レジスタ(個々のオブジェクト)の読み書きの順序を保証します。オペレーションをトランザクションとしてグループ化しないので、競合のマテリアライズのような対策を講じなければ、書き込みスキューのような問題を防げません。 |
| 強整合性 | すべてのアクセスがすべての並列プロセス(またはノード、プロセッサなど)によって、同じ順序で(順次実行されるように)見えます。レプリケートされたオブジェクトが線形化可能である場合、レプリケーション プロトコルは強整合性を示すという定義もあります。 |
| 結果整合性 | 結果整合性は、データベースへの書き込みを停止してしばらく待つと、最終的に、すべての読み取り要求に対して同じ値が返されることを意味します。 |
| 外部整合性 | トランザクションの commit が認識される順序は順次実行順序と整合します。外部整合性は、線形化可能性と直列化可能性のどちらよりも強いプロパティです。 |