SubCollectionいつ使うの問題
Cloud Firestoreがリリースされて数日経ちました。SaladaをFirestoreに対応させるため、仕様の深いところまで検証しているところです。そんな中でぶち当たった問題について記載します。
TL;DR
- Queryに依存するアプリを作ると拡張性を失う。
- QueryはElasticSearchに任せる。
- SubCollectionの使い所は限定的。
SubCollectionとは
FirestoreはCollectionとDocumentとDataで構成されます。
Collectionは複数のDocumentを持つことができ、
DocumentはDataとCollectionを持つことができます。Documentが持つCollectionのことをSubCollectionと言います。

なぜSubCollectionが必要だったのか
Firebase Realtime Databaseでは深いネストの上位ノードでデータを取得すると、そのノード以下全てを取得してしまう課題がありました。
例えばv1でデータを取得するとfollowerもuserも全部取得しちゃう。通信がえげつないことになる訳です。

そこで登場したのがFirestoreのSubCollectionの考え方。DocumentをDataとCollectionに分ける事でDataだけを取得するようになりました。めでたしめでたし。
ところが、機能が拡張された事でFirebaseの考え方が少し変化しました。
__WHERE__がなくとも
Firebase Realtime Databaseには柔軟なQueryがありませんでしたがFirestoreではwhereを利用できるようになりました。しかしWhereがなくとも多彩な機能を表現できます。
ここでフォロー機能について考えて見ましょう。
Firebaseでフォロー機能を実現するにはおおよそ3つの方法があります。勝手に名前をつけましたが、ちゃんとした名前があったら誰か教えてください。
- 男は黙って冗長型
- ネスト参照型
- リレーションシップ参照型
男は黙って冗長型
これは、Firebase Castでも紹介されている。強力な方法です。
user_0がuser_1をフォローしている状態を表すためにfollowersにuser_1ごと入れ込んじゃう。

| メリット | デメリット |
|---|---|
| 読出し高速 | データ量増加 複数のノードに同時に書き込む |
user_0を取得したタイミングでuser_1の情報も取得することになるのでもちろん読出しは高速になります。しかしこれも最初のうちでデータが増加するに連れてuser_0は肥大化していきます。そして複数のノードに対して変更を加えないといけない未来が待っています。
例えばuser_0,user_1,user_2,user_3が相互フォローしている状態だとしましょう。user_0がnameを更新しました。すると4つのノードに対して更新をする必要があります。
また、複数のノードを更新する際にトランザクションをしていたとしたらデータベースの性能をとんでもなく悪化させているはずです。
どうやらこの方法でフォロー機能を実現するのはやめた方が良さそうです。
ネスト参照型
冗長化の課題を解決したネスト参照型。これもFirebase Castで紹介されています。
user_0がuser_1をフォローしている状態を表すためにfollowersにuser_1の参照だけを置く。

| メリット | デメリット |
|---|---|
| データがスッキリ | 読み込み遅い、上位ノードでデータ量の取得量が増加していく |
FirebaseではClient Side Joinが基本です。user_0からuser_1を取得するためにはまずfollowersからuser_1を取得して改めてそのkeyを持ってuser_1を取得するため、2度通信する必要があります。
Client Side Joinについてはこちらから
https://qiita.com/1amageek/items/afc1c0ceb15ffc2372fd
どうやら良さそうですが、やはり問題があります。followersが10000件を超えた場合を考えてください。上記で述べているようにFirebase Realtime Databaseの課題にぶち当たります。user_0以下のデータを取得しようとすると膨大な量のデータをサーバーから受け取ることになり、性能が悪化していきます。
実際、数千件程度では対して悪化はしませんので、そんなに大きくない規模のシステムならこれでも大丈夫です。
リレーションシップ参照型
データ量重くなる問題を解消したリレーションシップ参照型。userノードに膨れ上がるデータを置いて置くのはやめて別のノードを準備するのがこの方法です。

| メリット | デメリット |
|---|---|
| データがスッキリ | 読み込み遅い |
フォロワーが増えていたっとしてもuser_0のデータ量は増えません。どうやらこの方法が良さそうです。
アプリの機能について考える
では次に、簡単な写真アプリについて考えて見ましょう。
このアプリの仕様はとってもシンプルでユーザーが写真をFirebaseにアップロードできるアプリです。そして写真を見ることができるのはアップロードしたユーザーだけです。
UserとPhotoというモデルでアプリを作って見ましょう。もちろん__リレーションシップ参照型__を使ったほうが良さそうです。
シンプルでいいアプリになりそうですがもう少し機能を追加したいので複数のユーザーで写真を共有できるグループ機能を追加しましょう。
GroupというModelを追加して複数ユーザーで写真が見えるようにしましょう。

良さそうですね。
Firestoreならもっと簡単にできるよね?
Firestoreでこのアプリを作るならどうすればいいでしょうか。Firestoreでも3つの方法があります。
- Query型
- Collection値型
- Collection参照型
Query型
FirestoreにはQueryがあります。Firebase Realtime Databaseでは1:Nのリレーションシップを使ってあらゆるデータ構造を表現するしかなかったのに対し、N:Nのデータ構造を持つことが可能になったことを意味しています。
例えば上記のフォロー機能に関して考えると以下のようにして表現できます。

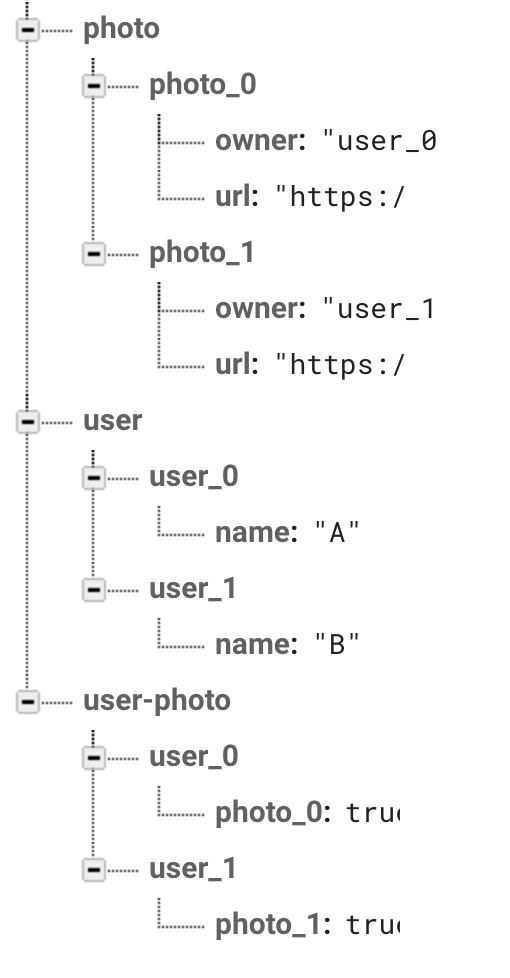
また、アプリの話に戻すと__リレーションシップ参照型__にしなくともQueryを使ってowner == user_0を取得すればUserが保持しているPhotoを簡単に取得することができるようになりました。
しかし、グループ機能を追加しようと思うとこの方法には問題があることがわかります。なぜならPhotoはownerを保持していますがgroupを保持していません。
やはり__WHERE__に頼る開発よりもデータ構造を持たせた方が柔軟なアプリが構築できそうです。
Collection値型
Userが所持している写真なのであればUserのSubCollectionとしてPhotoを扱う方法です。
FirestoreになってDataとCollectionが分離させたため、Userの下にPhotoを入れてもデータ量が増加する問題もありません。グループ機能について考えて見ましょう。GroupがPhotoのデータを取得するためには/user/user_0/photo/photo_0のようにuser_0, photo_0の二つの情報が必要になりました。Collection値型では、Keyではなくパスで管理した方が良さそうです。
Collection参照型
ネスト参照型のFirestoreバージョンがCollection参照型です。ネスト参照型の問題は取得するデータ量が増加することでしたが、Firestoreではその問題もありません。
グループ機能について考えて見ましょう。Collection値型に比べ、Photoのデータを参照として保持し、/photo/photo_0としてアクセスできることから考えることが減りそうです。
__Collection値型__と__Collection参照型__は大差ない
Keyで参照を保持するかパスで保持するかの違いのように見えます。あえてパスを持たせるくらいならCollection参照型にしておきましょう。でも値型には何かメリットがありそうです。値型のQueryをかけることにあります。
ここでアプリの機能を追加しましょう。見たい写真の月を入力するとその月の写真が表示されるフィルター機能を追加することにします。
自分の写真にフィルター機能を追加する
Collection値型はUserがPhotoを保持しているのでQueryが適応できそうです。
Collection参照型もPhotoはownerを保持しているのでQueryが適応できそうです。
グループの写真にフィルター機能を追加する
Collection値型のGroupにはPhotoのパスを保持しているだけなので実現できません。
Collection参照型もPhotoはownerを保持しているだけなので実現できません。
つまりQueryを適応できるデータ構造を作るのならばデータ構造を冗長型に移行する必要があります。これは現実的でしょうか?
残念ながら現実的な解ではなさそうです。上記にも記載がある通り、複数のノードを同時に更新する必要がありスケーラブルではないからです。
__Query__を諦めましょう。え!?っと思った方もいるかも知れませんが大丈夫です。どうせ書くならもっと柔軟にQueryを書けた方がいいですよね? ElasticSearchを使いましょう。
ただし、これはPhotoが他のユーザーから参照される場合の話です。他から参照されないのであればCollection値型の方にすべきでしょう。
アプリにするならば、Collection参照型かリレーションシップ参照型が良さそうです。
Collection参照型とリレーションシップ参照型は実は全く同じことをしています。
ここで大きな問題に直面しました。SubCollectionとQueryいつ使うの問題です。困った。
困った方はこちらへ
Cloud Firestoreを実践投入するにあたって考えたこと
Cloud FirestoreのQueryの使いどころを書いております。